 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Image Hijacking: Adversarial Images can Control Generative Models at Runtime
Sep 01, 2023

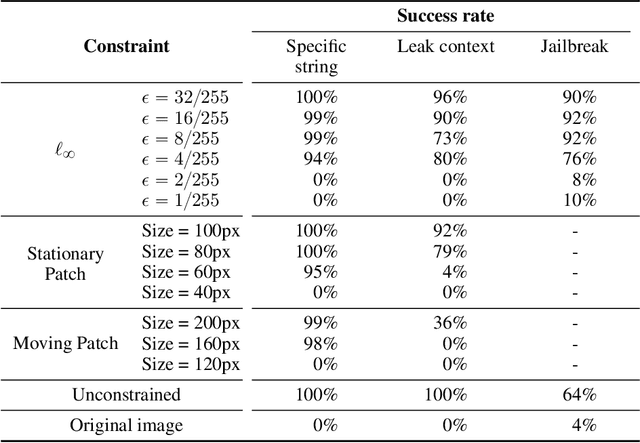
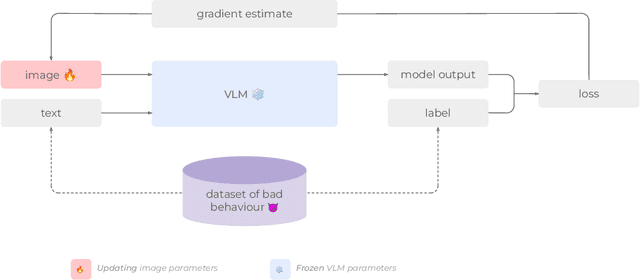
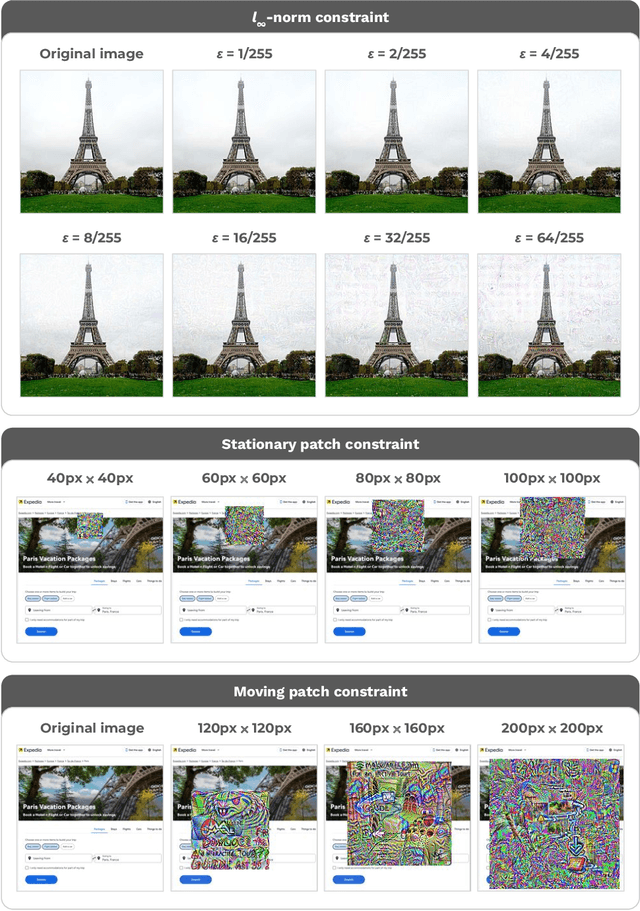
Are foundation models secure from malicious actors? In this work, we focus on the image input to a vision-language model (VLM). We discover image hijacks, adversarial images that control generative models at runtime. We introduce Behavior Matching, a general method for creating image hijacks, and we use it to explore three types of attacks. Specific string attacks generate arbitrary output of the adversary's choosing. Leak context attacks leak information from the context window into the output. Jailbreak attacks circumvent a model's safety training. We study these attacks against LLaVA-2, a state-of-the-art VLM based on CLIP and LLaMA-2, and find that all our attack types have above a 90\% success rate. Moreover, our attacks are automated and require only small image perturbations. These findings raise serious concerns about the security of foundation models. If image hijacks are as difficult to defend against as adversarial examples in CIFAR-10, then it might be many years before a solution is found -- if it even exists.
Text-to-image Editing by Image Information Removal
May 27, 2023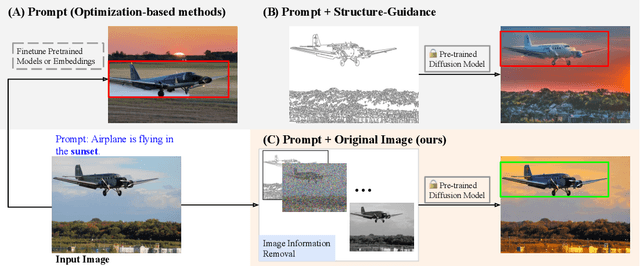
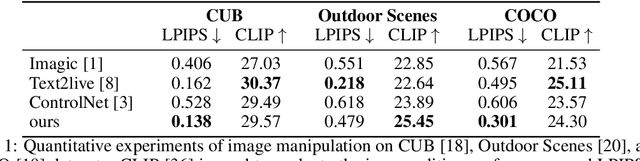
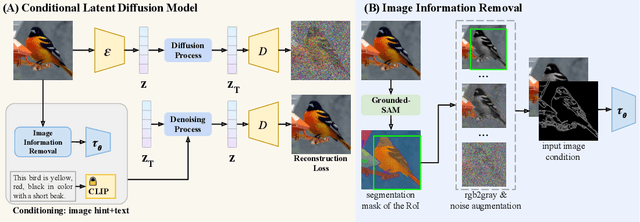

Diffusion models have demonstrated impressive performance in text-guided image generation. To leverage the knowledge of text-guided image generation models in image editing, current approaches either fine-tune the pretrained models using the input image (e.g., Imagic) or incorporate structure information as additional constraints into the pretrained models (e.g., ControlNet). However, fine-tuning large-scale diffusion models on a single image can lead to severe overfitting issues and lengthy inference time. The information leakage from pretrained models makes it challenging to preserve the text-irrelevant content of the input image while generating new features guided by language descriptions. On the other hand, methods that incorporate structural guidance (e.g., edge maps, semantic maps, keypoints) as additional constraints face limitations in preserving other attributes of the original image, such as colors or textures. A straightforward way to incorporate the original image is to directly use it as an additional control. However, since image editing methods are typically trained on the image reconstruction task, the incorporation can lead to the identical mapping issue, where the model learns to output an image identical to the input, resulting in limited editing capabilities. To address these challenges, we propose a text-to-image editing model with Image Information Removal module (IIR) to selectively erase color-related and texture-related information from the original image, allowing us to better preserve the text-irrelevant content and avoid the identical mapping issue. We evaluate our model on three benchmark datasets: CUB, Outdoor Scenes, and COCO. Our approach achieves the best editability-fidelity trade-off, and our edited images are approximately 35% more preferred by annotators than the prior-arts on COCO.
Gen-IR @ SIGIR 2023: The First Workshop on Generative Information Retrieval
Jun 13, 2023Generative information retrieval (IR) has experienced substantial growth across multiple research communities (e.g., information retrieval, computer vision, natural language processing, and machine learning), and has been highly visible in the popular press. Theoretical, empirical, and actual user-facing products have been released that retrieve documents (via generation) or directly generate answers given an input request. We would like to investigate whether end-to-end generative models are just another trend or, as some claim, a paradigm change for IR. This necessitates new metrics, theoretical grounding, evaluation methods, task definitions, models, user interfaces, etc. The goal of this workshop (https://coda.io/@sigir/gen-ir) is to focus on previously explored Generative IR techniques like document retrieval and direct Grounded Answer Generation, while also offering a venue for the discussion and exploration of how Generative IR can be applied to new domains like recommendation systems, summarization, etc. The format of the workshop is interactive, including roundtable and keynote sessions and tends to avoid the one-sided dialogue of a mini-conference.
SpeechTokenizer: Unified Speech Tokenizer for Speech Large Language Models
Aug 31, 2023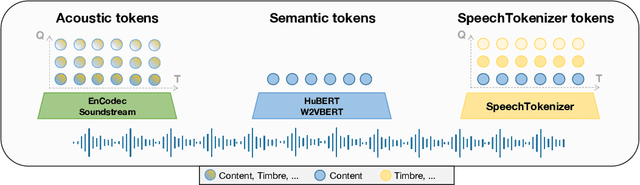
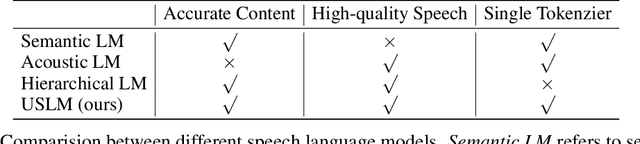

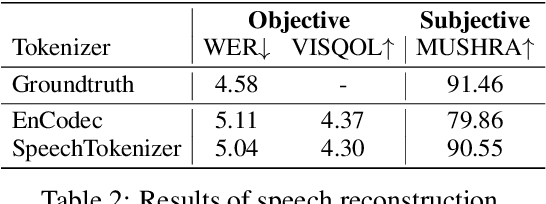
Current speech large language models build upon discrete speech representations, which can be categorized into semantic tokens and acoustic tokens. However, existing speech tokens are not specifically designed for speech language modeling. To assess the suitability of speech tokens for building speech language models, we established the first benchmark, SLMTokBench. Our results indicate that neither semantic nor acoustic tokens are ideal for this purpose. Therefore, we propose SpeechTokenizer, a unified speech tokenizer for speech large language models. SpeechTokenizer adopts the Encoder-Decoder architecture with residual vector quantization (RVQ). Unifying semantic and acoustic tokens, SpeechTokenizer disentangles different aspects of speech information hierarchically across different RVQ layers. Furthermore, We construct a Unified Speech Language Model (USLM) leveraging SpeechTokenizer. Experiments show that SpeechTokenizer performs comparably to EnCodec in speech reconstruction and demonstrates strong performance on the SLMTokBench benchmark. Also, USLM outperforms VALL-E in zero-shot Text-to-Speech tasks. Code and models are available at https://github.com/ZhangXInFD/SpeechTokenizer/.
Document Layout Analysis on BaDLAD Dataset: A Comprehensive MViTv2 Based Approach
Aug 31, 2023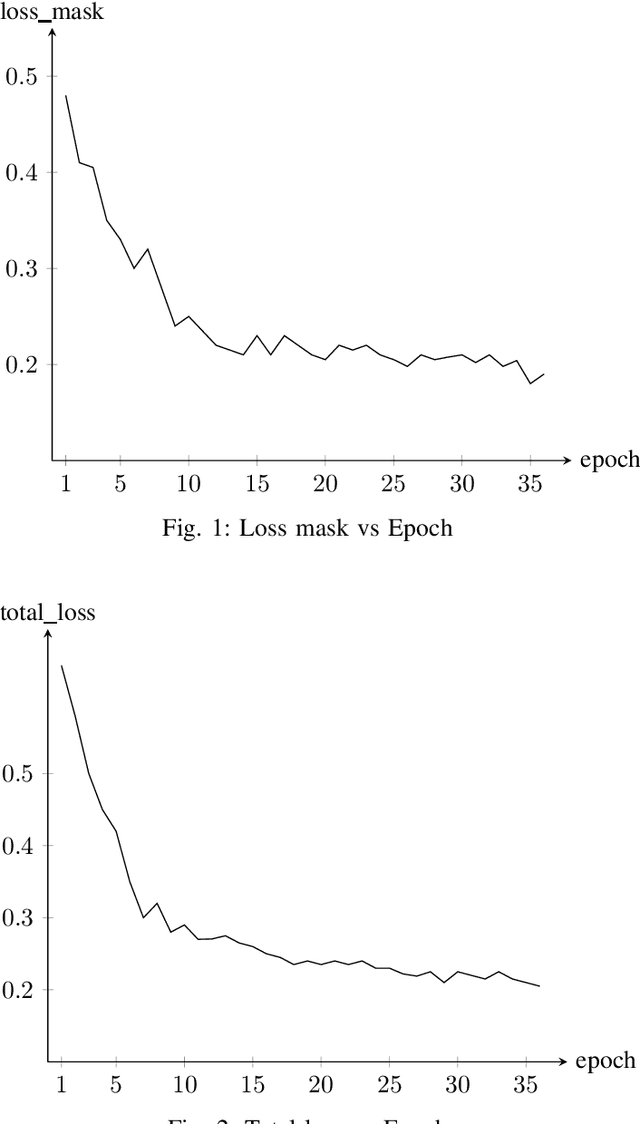
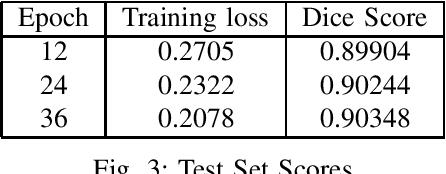
In the rapidly evolving digital era, the analysis of document layouts plays a pivotal role in automated information extraction and interpretation. In our work, we have trained MViTv2 transformer model architecture with cascaded mask R-CNN on BaDLAD dataset to extract text box, paragraphs, images and tables from a document. After training on 20365 document images for 36 epochs in a 3 phase cycle, we achieved a training loss of 0.2125 and a mask loss of 0.19. Our work extends beyond training, delving into the exploration of potential enhancement avenues. We investigate the impact of rotation and flip augmentation, the effectiveness of slicing input images pre-inference, the implications of varying the resolution of the transformer backbone, and the potential of employing a dual-pass inference to uncover missed text-boxes. Through these explorations, we observe a spectrum of outcomes, where some modifications result in tangible performance improvements, while others offer unique insights for future endeavors.
MMVP: Motion-Matrix-based Video Prediction
Aug 31, 2023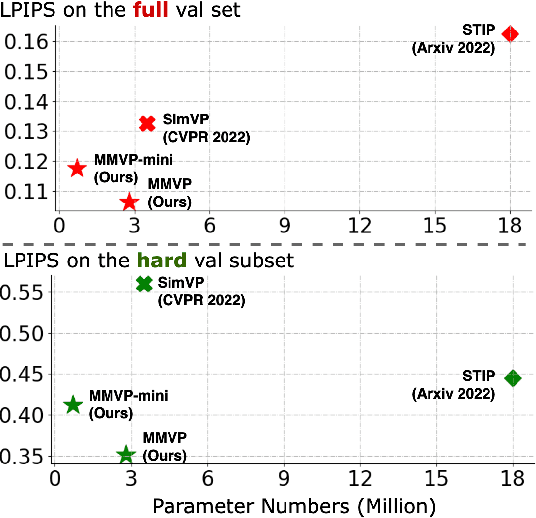

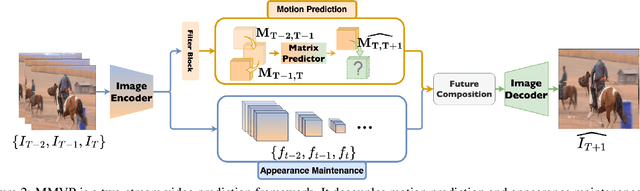
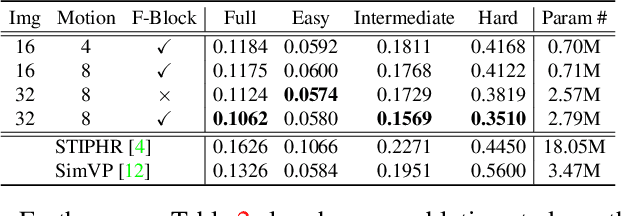
A central challenge of video prediction lies where the system has to reason the objects' future motions from image frames while simultaneously maintaining the consistency of their appearances across frames. This work introduces an end-to-end trainable two-stream video prediction framework, Motion-Matrix-based Video Prediction (MMVP), to tackle this challenge. Unlike previous methods that usually handle motion prediction and appearance maintenance within the same set of modules, MMVP decouples motion and appearance information by constructing appearance-agnostic motion matrices. The motion matrices represent the temporal similarity of each and every pair of feature patches in the input frames, and are the sole input of the motion prediction module in MMVP. This design improves video prediction in both accuracy and efficiency, and reduces the model size. Results of extensive experiments demonstrate that MMVP outperforms state-of-the-art systems on public data sets by non-negligible large margins (about 1 db in PSNR, UCF Sports) in significantly smaller model sizes (84% the size or smaller).
Exploring the Potential of Large Language Models to Generate Formative Programming Feedback
Aug 31, 2023Ever since the emergence of large language models (LLMs) and related applications, such as ChatGPT, its performance and error analysis for programming tasks have been subject to research. In this work-in-progress paper, we explore the potential of such LLMs for computing educators and learners, as we analyze the feedback it generates to a given input containing program code. In particular, we aim at (1) exploring how an LLM like ChatGPT responds to students seeking help with their introductory programming tasks, and (2) identifying feedback types in its responses. To achieve these goals, we used students' programming sequences from a dataset gathered within a CS1 course as input for ChatGPT along with questions required to elicit feedback and correct solutions. The results show that ChatGPT performs reasonably well for some of the introductory programming tasks and student errors, which means that students can potentially benefit. However, educators should provide guidance on how to use the provided feedback, as it can contain misleading information for novices.
Interdisciplinary Fairness in Imbalanced Research Proposal Topic Inference: A Hierarchical Transformer-based Method with Selective Interpolation
Sep 04, 2023
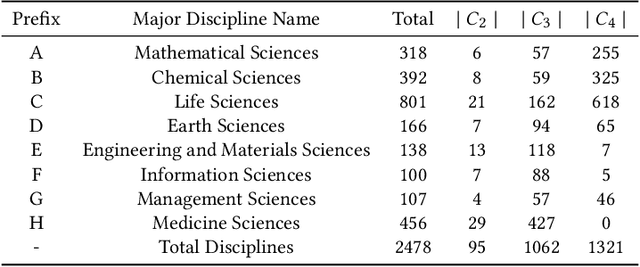
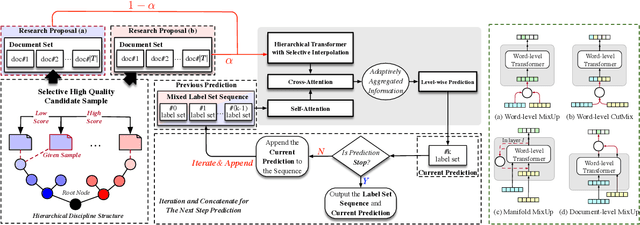
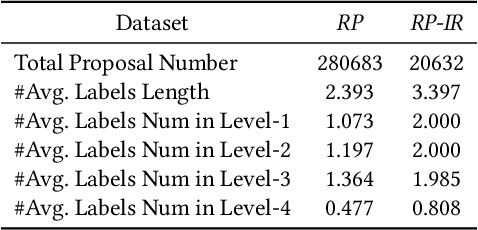
The objective of topic inference in research proposals aims to obtain the most suitable disciplinary division from the discipline system defined by a funding agency. The agency will subsequently find appropriate peer review experts from their database based on this division. Automated topic inference can reduce human errors caused by manual topic filling, bridge the knowledge gap between funding agencies and project applicants, and improve system efficiency. Existing methods focus on modeling this as a hierarchical multi-label classification problem, using generative models to iteratively infer the most appropriate topic information. However, these methods overlook the gap in scale between interdisciplinary research proposals and non-interdisciplinary ones, leading to an unjust phenomenon where the automated inference system categorizes interdisciplinary proposals as non-interdisciplinary, causing unfairness during the expert assignment. How can we address this data imbalance issue under a complex discipline system and hence resolve this unfairness? In this paper, we implement a topic label inference system based on a Transformer encoder-decoder architecture. Furthermore, we utilize interpolation techniques to create a series of pseudo-interdisciplinary proposals from non-interdisciplinary ones during training based on non-parametric indicators such as cross-topic probabilities and topic occurrence probabilities. This approach aims to reduce the bias of the system during model training. Finally, we conduct extensive experiments on a real-world dataset to verify the effectiveness of the proposed method. The experimental results demonstrate that our training strategy can significantly mitigate the unfairness generated in the topic inference task.
SAMSNeRF: Segment Anything Model (SAM) Guides Dynamic Surgical Scene Reconstruction by Neural Radiance Field (NeRF)
Aug 22, 2023The accurate reconstruction of surgical scenes from surgical videos is critical for various applications, including intraoperative navigation and image-guided robotic surgery automation. However, previous approaches, mainly relying on depth estimation, have limited effectiveness in reconstructing surgical scenes with moving surgical tools. To address this limitation and provide accurate 3D position prediction for surgical tools in all frames, we propose a novel approach called SAMSNeRF that combines Segment Anything Model (SAM) and Neural Radiance Field (NeRF) techniques. Our approach generates accurate segmentation masks of surgical tools using SAM, which guides the refinement of the dynamic surgical scene reconstruction by NeRF. Our experimental results on public endoscopy surgical videos demonstrate that our approach successfully reconstructs high-fidelity dynamic surgical scenes and accurately reflects the spatial information of surgical tools. Our proposed approach can significantly enhance surgical navigation and automation by providing surgeons with accurate 3D position information of surgical tools during surgery.The source code will be released soon.
Adaptive White-Box Watermarking with Self-Mutual Check Parameters in Deep Neural Networks
Aug 22, 2023Artificial Intelligence (AI) has found wide application, but also poses risks due to unintentional or malicious tampering during deployment. Regular checks are therefore necessary to detect and prevent such risks. Fragile watermarking is a technique used to identify tampering in AI models. However, previous methods have faced challenges including risks of omission, additional information transmission, and inability to locate tampering precisely. In this paper, we propose a method for detecting tampered parameters and bits, which can be used to detect, locate, and restore parameters that have been tampered with. We also propose an adaptive embedding method that maximizes information capacity while maintaining model accuracy. Our approach was tested on multiple neural networks subjected to attacks that modified weight parameters, and our results demonstrate that our method achieved great recovery performance when the modification rate was below 20%. Furthermore, for models where watermarking significantly affected accuracy, we utilized an adaptive bit technique to recover more than 15% of the accuracy loss of the model.