 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Position and Orientation-Aware One-Shot Learning for Medical Action Recognition from Signal Data
Sep 27, 2023
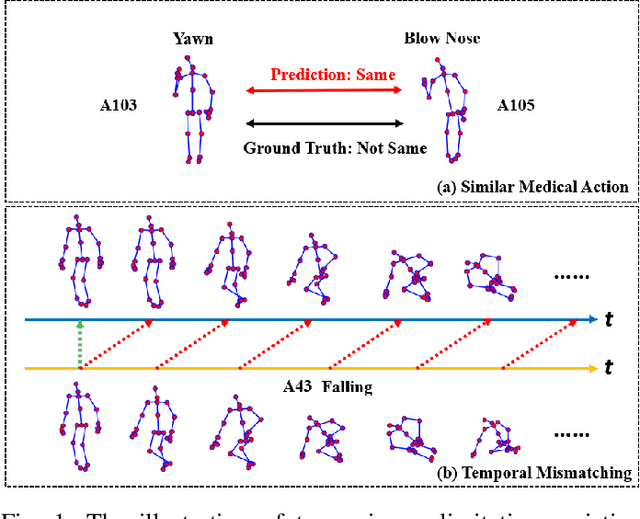
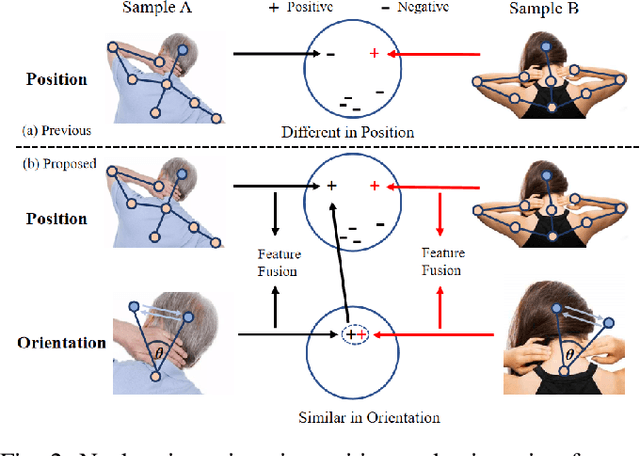
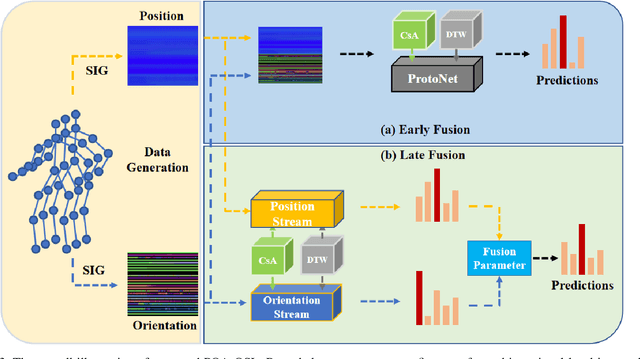
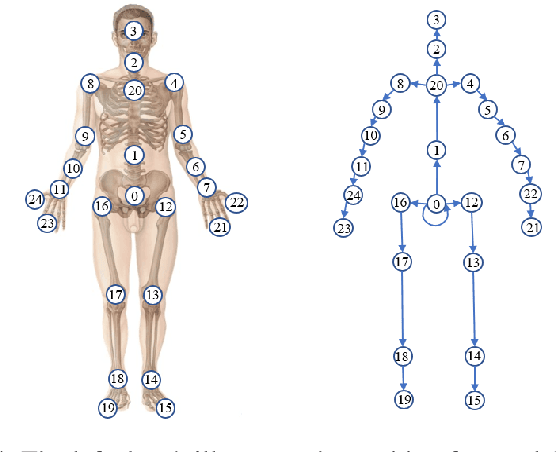
In this work, we propose a position and orientation-aware one-shot learning framework for medical action recognition from signal data. The proposed framework comprises two stages and each stage includes signal-level image generation (SIG), cross-attention (CsA), dynamic time warping (DTW) modules and the information fusion between the proposed privacy-preserved position and orientation features. The proposed SIG method aims to transform the raw skeleton data into privacy-preserved features for training. The CsA module is developed to guide the network in reducing medical action recognition bias and more focusing on important human body parts for each specific action, aimed at addressing similar medical action related issues. Moreover, the DTW module is employed to minimize temporal mismatching between instances and further improve model performance. Furthermore, the proposed privacy-preserved orientation-level features are utilized to assist the position-level features in both of the two stages for enhancing medical action recognition performance. Extensive experimental results on the widely-used and well-known NTU RGB+D 60, NTU RGB+D 120, and PKU-MMD datasets all demonstrate the effectiveness of the proposed method, which outperforms the other state-of-the-art methods with general dataset partitioning by 2.7%, 6.2% and 4.1%, respectively.
The Impact of Debiasing on the Performance of Language Models in Downstream Tasks is Underestimated
Sep 16, 2023Pre-trained language models trained on large-scale data have learned serious levels of social biases. Consequently, various methods have been proposed to debias pre-trained models. Debiasing methods need to mitigate only discriminatory bias information from the pre-trained models, while retaining information that is useful for the downstream tasks. In previous research, whether useful information is retained has been confirmed by the performance of downstream tasks in debiased pre-trained models. On the other hand, it is not clear whether these benchmarks consist of data pertaining to social biases and are appropriate for investigating the impact of debiasing. For example in gender-related social biases, data containing female words (e.g. ``she, female, woman''), male words (e.g. ``he, male, man''), and stereotypical words (e.g. ``nurse, doctor, professor'') are considered to be the most affected by debiasing. If there is not much data containing these words in a benchmark dataset for a target task, there is the possibility of erroneously evaluating the effects of debiasing. In this study, we compare the impact of debiasing on performance across multiple downstream tasks using a wide-range of benchmark datasets that containing female, male, and stereotypical words. Experiments show that the effects of debiasing are consistently \emph{underestimated} across all tasks. Moreover, the effects of debiasing could be reliably evaluated by separately considering instances containing female, male, and stereotypical words than all of the instances in a benchmark dataset.
Stock Market Sentiment Classification and Backtesting via Fine-tuned BERT
Sep 21, 2023With the rapid development of big data and computing devices, low-latency automatic trading platforms based on real-time information acquisition have become the main components of the stock trading market, so the topic of quantitative trading has received widespread attention. And for non-strongly efficient trading markets, human emotions and expectations always dominate market trends and trading decisions. Therefore, this paper starts from the theory of emotion, taking East Money as an example, crawling user comment titles data from its corresponding stock bar and performing data cleaning. Subsequently, a natural language processing model BERT was constructed, and the BERT model was fine-tuned using existing annotated data sets. The experimental results show that the fine-tuned model has different degrees of performance improvement compared to the original model and the baseline model. Subsequently, based on the above model, the user comment data crawled is labeled with emotional polarity, and the obtained label information is combined with the Alpha191 model to participate in regression, and significant regression results are obtained. Subsequently, the regression model is used to predict the average price change for the next five days, and use it as a signal to guide automatic trading. The experimental results show that the incorporation of emotional factors increased the return rate by 73.8\% compared to the baseline during the trading period, and by 32.41\% compared to the original alpha191 model. Finally, we discuss the advantages and disadvantages of incorporating emotional factors into quantitative trading, and give possible directions for further research in the future.
Semi-supervised 3D Video Information Retrieval with Deep Neural Network and Bi-directional Dynamic-time Warping Algorithm
Sep 03, 2023This paper presents a novel semi-supervised deep learning algorithm for retrieving similar 2D and 3D videos based on visual content. The proposed approach combines the power of deep convolutional and recurrent neural networks with dynamic time warping as a similarity measure. The proposed algorithm is designed to handle large video datasets and retrieve the most related videos to a given inquiry video clip based on its graphical frames and contents. We split both the candidate and the inquiry videos into a sequence of clips and convert each clip to a representation vector using an autoencoder-backed deep neural network. We then calculate a similarity measure between the sequences of embedding vectors using a bi-directional dynamic time-warping method. This approach is tested on multiple public datasets, including CC\_WEB\_VIDEO, Youtube-8m, S3DIS, and Synthia, and showed good results compared to state-of-the-art. The algorithm effectively solves video retrieval tasks and outperforms the benchmarked state-of-the-art deep learning model.
Projected Task-Specific Layers for Multi-Task Reinforcement Learning
Sep 15, 2023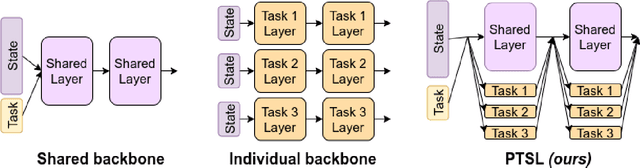
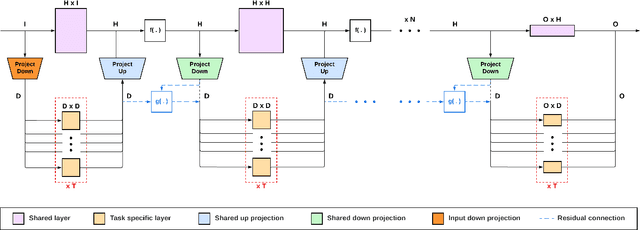
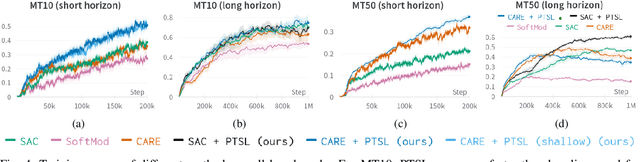
Multi-task reinforcement learning could enable robots to scale across a wide variety of manipulation tasks in homes and workplaces. However, generalizing from one task to another and mitigating negative task interference still remains a challenge. Addressing this challenge by successfully sharing information across tasks will depend on how well the structure underlying the tasks is captured. In this work, we introduce our new architecture, Projected Task-Specific Layers (PTSL), that leverages a common policy with dense task-specific corrections through task-specific layers to better express shared and variable task information. We then show that our model outperforms the state of the art on the MT10 and MT50 benchmarks of Meta-World consisting of 10 and 50 goal-conditioned tasks for a Sawyer arm.
BeamSec: A Practical mmWave Physical Layer Security Scheme Against Strong Adversaries
Sep 19, 2023The high directionality of millimeter-wave (mmWave) communication systems has proven effective in reducing the attack surface against eavesdropping, thus improving the physical layer security. However, even with highly directional beams, the system is still exposed to eavesdropping against adversaries located within the main lobe. In this paper, we propose \acrshort{BSec}, a solution to protect the users even from adversaries located in the main lobe. The key feature of BeamSec are: (i) Operating without the knowledge of eavesdropper's location/channel; (ii) Robustness against colluding eavesdropping attack and (iii) Standard compatibility, which we prove using experiments via our IEEE 802.11ad/ay-compatible 60 GHz phased-array testbed. Methodologically, BeamSec first identifies uncorrelated and diverse beam-pairs between the transmitter and receiver by analyzing signal characteristics available through standard-compliant procedures. Next, it encodes the information jointly over all selected beam-pairs to minimize information leakage. We study two methods for allocating transmission time among different beams, namely uniform allocation (no knowledge of the wireless channel) and optimal allocation for maximization of the secrecy rate (with partial knowledge of the wireless channel). Our experiments show that \acrshort{BSec} outperforms the benchmark schemes against single and colluding eavesdroppers and enhances the secrecy rate by 79.8% over a random paths selection benchmark.
Multi-Modal Financial Time-Series Retrieval Through Latent Space Projections
Sep 28, 2023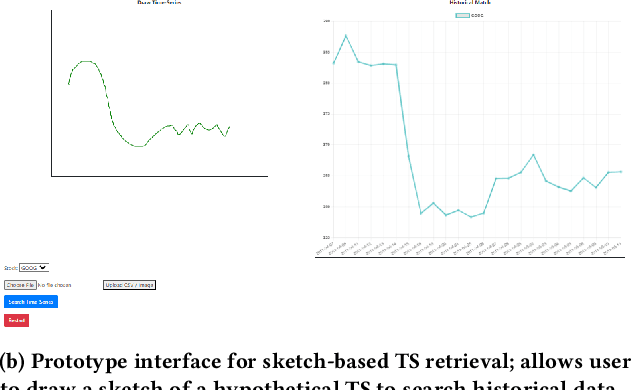
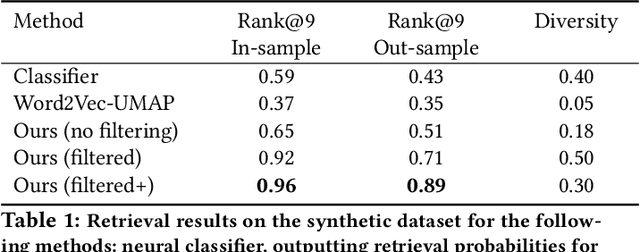
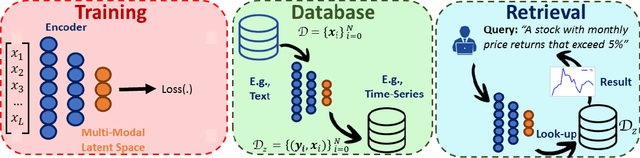
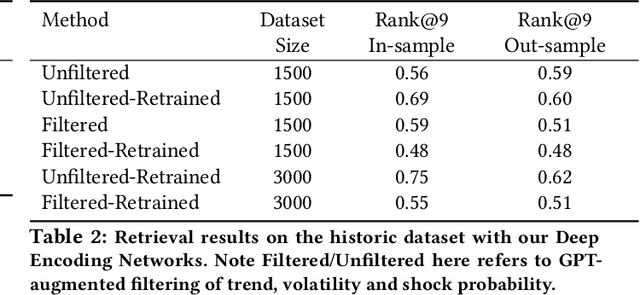
Financial firms commonly process and store billions of time-series data, generated continuously and at a high frequency. To support efficient data storage and retrieval, specialized time-series databases and systems have emerged. These databases support indexing and querying of time-series by a constrained Structured Query Language(SQL)-like format to enable queries like "Stocks with monthly price returns greater than 5%", and expressed in rigid formats. However, such queries do not capture the intrinsic complexity of high dimensional time-series data, which can often be better described by images or language (e.g., "A stock in low volatility regime"). Moreover, the required storage, computational time, and retrieval complexity to search in the time-series space are often non-trivial. In this paper, we propose and demonstrate a framework to store multi-modal data for financial time-series in a lower-dimensional latent space using deep encoders, such that the latent space projections capture not only the time series trends but also other desirable information or properties of the financial time-series data (such as price volatility). Moreover, our approach allows user-friendly query interfaces, enabling natural language text or sketches of time-series, for which we have developed intuitive interfaces. We demonstrate the advantages of our method in terms of computational efficiency and accuracy on real historical data as well as synthetic data, and highlight the utility of latent-space projections in the storage and retrieval of financial time-series data with intuitive query modalities.
DiffGAN-F2S: Symmetric and Efficient Denoising Diffusion GANs for Structural Connectivity Prediction from Brain fMRI
Sep 28, 2023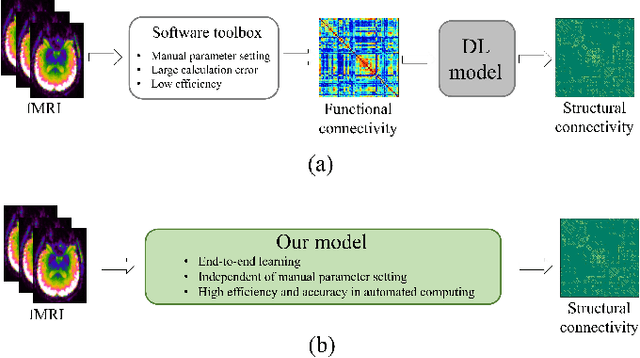
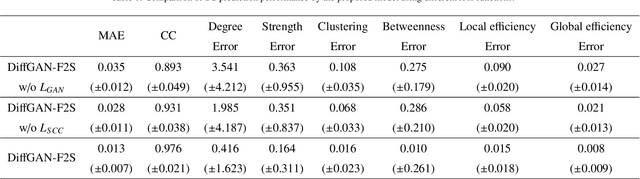
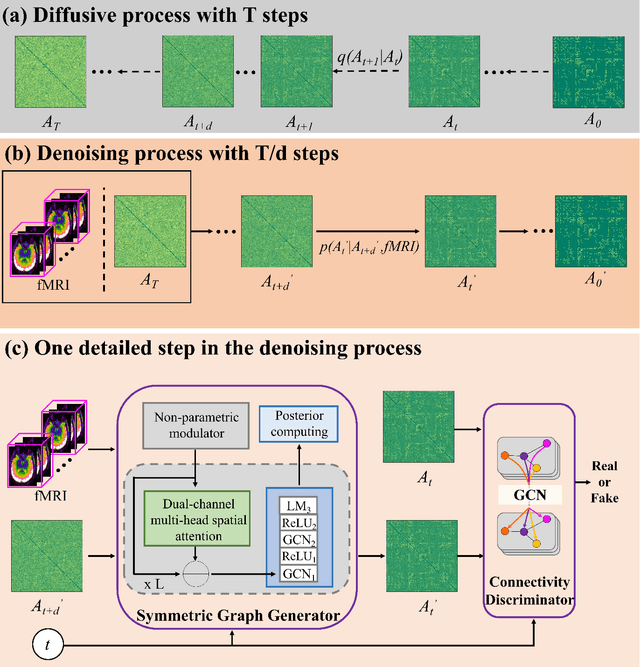
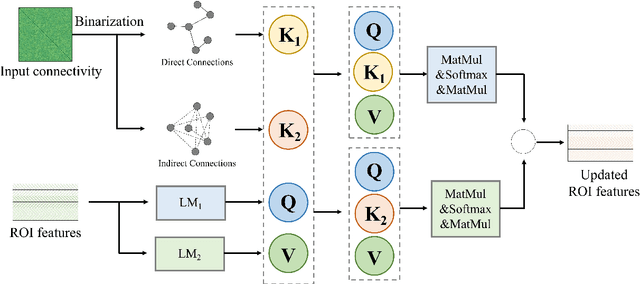
Mapping from functional connectivity (FC) to structural connectivity (SC) can facilitate multimodal brain network fusion and discover potential biomarkers for clinical implications. However, it is challenging to directly bridge the reliable non-linear mapping relations between SC and functional magnetic resonance imaging (fMRI). In this paper, a novel diffusision generative adversarial network-based fMRI-to-SC (DiffGAN-F2S) model is proposed to predict SC from brain fMRI in an end-to-end manner. To be specific, the proposed DiffGAN-F2S leverages denoising diffusion probabilistic models (DDPMs) and adversarial learning to efficiently generate high-fidelity SC through a few steps from fMRI. By designing the dual-channel multi-head spatial attention (DMSA) and graph convolutional modules, the symmetric graph generator first captures global relations among direct and indirect connected brain regions, then models the local brain region interactions. It can uncover the complex mapping relations between fMRI and structural connectivity. Furthermore, the spatially connected consistency loss is devised to constrain the generator to preserve global-local topological information for accurate intrinsic SC prediction. Testing on the public Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset, the proposed model can effectively generate empirical SC-preserved connectivity from four-dimensional imaging data and shows superior performance in SC prediction compared with other related models. Furthermore, the proposed model can identify the vast majority of important brain regions and connections derived from the empirical method, providing an alternative way to fuse multimodal brain networks and analyze clinical disease.
Stochastic Digital Twin for Copy Detection Patterns
Sep 28, 2023Copy detection patterns (CDP) present an efficient technique for product protection against counterfeiting. However, the complexity of studying CDP production variability often results in time-consuming and costly procedures, limiting CDP scalability. Recent advancements in computer modelling, notably the concept of a "digital twin" for printing-imaging channels, allow for enhanced scalability and the optimization of authentication systems. Yet, the development of an accurate digital twin is far from trivial. This paper extends previous research which modelled a printing-imaging channel using a machine learning-based digital twin for CDP. This model, built upon an information-theoretic framework known as "Turbo", demonstrated superior performance over traditional generative models such as CycleGAN and pix2pix. However, the emerging field of Denoising Diffusion Probabilistic Models (DDPM) presents a potential advancement in generative models due to its ability to stochastically model the inherent randomness of the printing-imaging process, and its impressive performance in image-to-image translation tasks. This study aims at comparing the capabilities of the Turbo framework and DDPM on the same CDP datasets, with the goal of establishing the real-world benefits of DDPM models for digital twin applications in CDP security. Furthermore, the paper seeks to evaluate the generative potential of the studied models in the context of mobile phone data acquisition. Despite the increased complexity of DDPM methods when compared to traditional approaches, our study highlights their advantages and explores their potential for future applications.
Channel Vision Transformers: An Image Is Worth C x 16 x 16 Words
Sep 28, 2023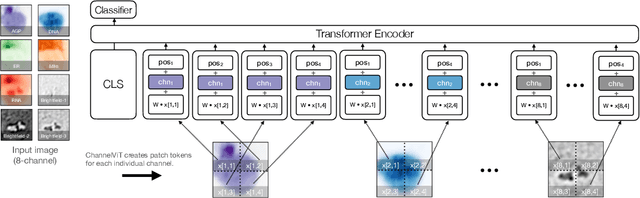
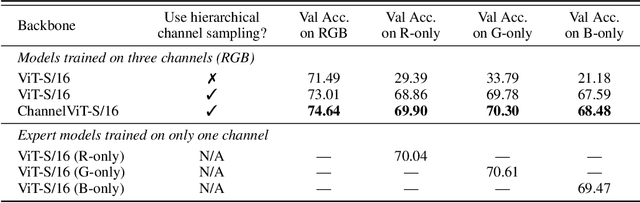
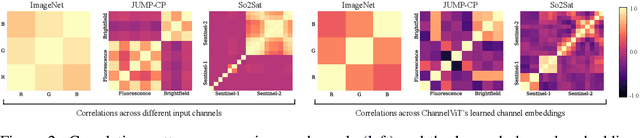
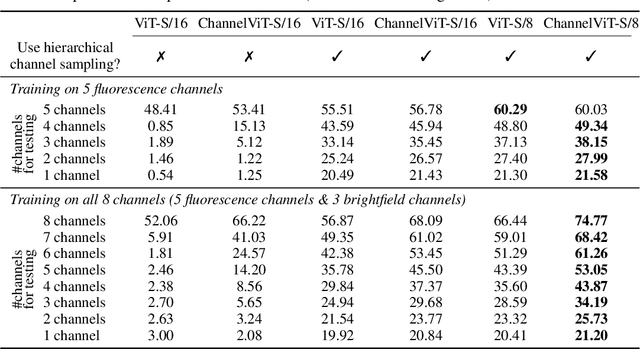
Vision Transformer (ViT) has emerged as a powerful architecture in the realm of modern computer vision. However, its application in certain imaging fields, such as microscopy and satellite imaging, presents unique challenges. In these domains, images often contain multiple channels, each carrying semantically distinct and independent information. Furthermore, the model must demonstrate robustness to sparsity in input channels, as they may not be densely available during training or testing. In this paper, we propose a modification to the ViT architecture that enhances reasoning across the input channels and introduce Hierarchical Channel Sampling (HCS) as an additional regularization technique to ensure robustness when only partial channels are presented during test time. Our proposed model, ChannelViT, constructs patch tokens independently from each input channel and utilizes a learnable channel embedding that is added to the patch tokens, similar to positional embeddings. We evaluate the performance of ChannelViT on ImageNet, JUMP-CP (microscopy cell imaging), and So2Sat (satellite imaging). Our results show that ChannelViT outperforms ViT on classification tasks and generalizes well, even when a subset of input channels is used during testing. Across our experiments, HCS proves to be a powerful regularizer, independent of the architecture employed, suggesting itself as a straightforward technique for robust ViT training. Lastly, we find that ChannelViT generalizes effectively even when there is limited access to all channels during training, highlighting its potential for multi-channel imaging under real-world conditions with sparse sensors.