 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SABAF: Removing Strong Attribute Bias from Neural Networks with Adversarial Filtering
Nov 16, 2023
Ensuring a neural network is not relying on protected attributes (e.g., race, sex, age) for prediction is crucial in advancing fair and trustworthy AI. While several promising methods for removing attribute bias in neural networks have been proposed, their limitations remain under-explored. To that end, in this work, we mathematically and empirically reveal the limitation of existing attribute bias removal methods in presence of strong bias and propose a new method that can mitigate this limitation. Specifically, we first derive a general non-vacuous information-theoretical upper bound on the performance of any attribute bias removal method in terms of the bias strength, revealing that they are effective only when the inherent bias in the dataset is relatively weak. Next, we derive a necessary condition for the existence of any method that can remove attribute bias regardless of the bias strength. Inspired by this condition, we then propose a new method using an adversarial objective that directly filters out protected attributes in the input space while maximally preserving all other attributes, without requiring any specific target label. The proposed method achieves state-of-the-art performance in both strong and moderate bias settings. We provide extensive experiments on synthetic, image, and census datasets, to verify the derived theoretical bound and its consequences in practice, and evaluate the effectiveness of the proposed method in removing strong attribute bias.
Diverse Semantic Image Editing with Style Codes
Sep 25, 2023Semantic image editing requires inpainting pixels following a semantic map. It is a challenging task since this inpainting requires both harmony with the context and strict compliance with the semantic maps. The majority of the previous methods proposed for this task try to encode the whole information from erased images. However, when an object is added to a scene such as a car, its style cannot be encoded from the context alone. On the other hand, the models that can output diverse generations struggle to output images that have seamless boundaries between the generated and unerased parts. Additionally, previous methods do not have a mechanism to encode the styles of visible and partially visible objects differently for better performance. In this work, we propose a framework that can encode visible and partially visible objects with a novel mechanism to achieve consistency in the style encoding and final generations. We extensively compare with previous conditional image generation and semantic image editing algorithms. Our extensive experiments show that our method significantly improves over the state-of-the-art. Our method not only achieves better quantitative results but also provides diverse results. Please refer to the project web page for the released code and demo: https://github.com/hakansivuk/DivSem.
Fire Detection From Image and Video Using YOLOv5
Oct 10, 2023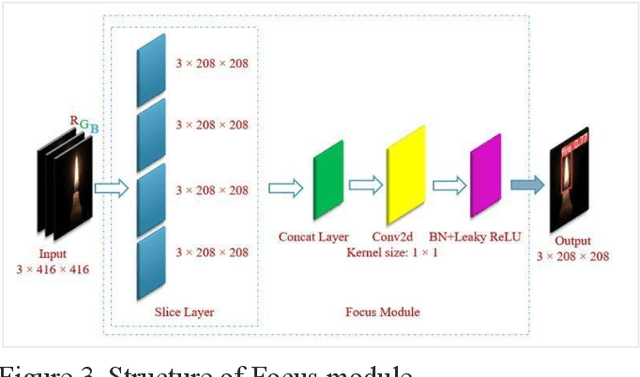
For the detection of fire-like targets in indoor, outdoor and forest fire images, as well as fire detection under different natural lights, an improved YOLOv5 fire detection deep learning algorithm is proposed. The YOLOv5 detection model expands the feature extraction network from three dimensions, which enhances feature propagation of fire small targets identification, improves network performance, and reduces model parameters. Furthermore, through the promotion of the feature pyramid, the top-performing prediction box is obtained. Fire-YOLOv5 attains excellent results compared to state-of-the-art object detection networks, notably in the detection of small targets of fire and smoke with mAP 90.5% and f1 score 88%. Overall, the Fire-YOLOv5 detection model can effectively deal with the inspection of small fire targets, as well as fire-like and smoke-like objects with F1 score 0.88. When the input image size is 416 x 416 resolution, the average detection time is 0.12 s per frame, which can provide real-time forest fire detection. Moreover, the algorithm proposed in this paper can also be applied to small target detection under other complicated situations. The proposed system shows an improved approach in all fire detection metrics such as precision, recall, and mean average precision.
Self-distilled Masked Attention guided masked image modeling with noise Regularized Teacher (SMART) for medical image analysis
Oct 02, 2023Hierarchical shifted window transformers (Swin) are a computationally efficient and more accurate alternative to plain vision transformers. Masked image modeling (MIM)-based pretraining is highly effective in increasing models' transferability to a variety of downstream tasks. However, more accurate and efficient attention guided MIM approaches are difficult to implement with Swin due to it's lack of an explicit global attention. We thus architecturally enhanced Swin with semantic class attention for self-supervised attention guided co-distillation with MIM. We also introduced a noise injected momentum teacher, implemented with patch dropout of teacher's inputs for improved training regularization and accuracy. Our approach, called \underline{s}elf-distilled \underline{m}asked \underline{a}ttention MIM with noise \underline{r}egularized \underline{t}eacher (SMART) was pretrained with \textbf{10,412} unlabeled 3D computed tomography (CT)s of multiple disease sites and sourced from institutional and public datasets. We evaluated SMART for multiple downstream tasks involving analysis of 3D CTs of lung cancer (LC) patients for: (i) [Task I] predicting immunotherapy response in advanced stage LC (n = 200 internal dataset), (ii) [Task II] predicting LC recurrence in early stage LC before surgery (n = 156 public dataset), (iii) [Task III] LC segmentation (n = 200 internal, 21 public dataset), and (iv) [Task IV] unsupervised clustering of organs in the chest and abdomen (n = 1,743 public dataset) \underline{without} finetuning. SMART predicted immunotherapy response with an AUC of 0.916, LC recurrence with an AUC of 0.793, segmented LC with Dice accuracy of 0.81, and clustered organs with an inter-class cluster distance of 5.94, indicating capability of attention guided MIM for Swin in medical image analysis.
Performance of Machine Learning Classification in Mammography Images using BI-RADS
Nov 14, 2023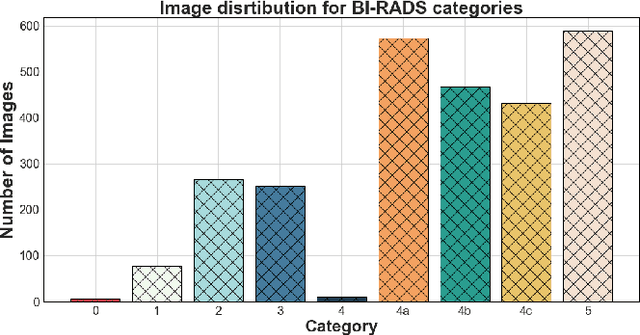

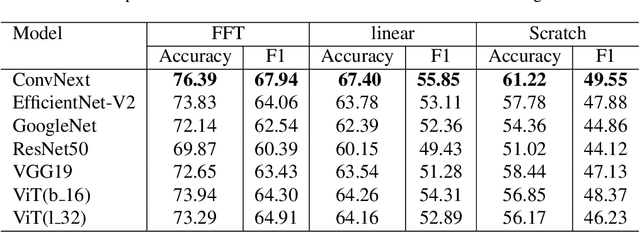
This research aims to investigate the classification accuracy of various state-of-the-art image classification models across different categories of breast ultrasound images, as defined by the Breast Imaging Reporting and Data System (BI-RADS). To achieve this, we have utilized a comprehensively assembled dataset of 2,945 mammographic images sourced from 1,540 patients. In order to conduct a thorough analysis, we employed six advanced classification architectures, including VGG19 \cite{simonyan2014very}, ResNet50 \cite{he2016deep}, GoogleNet \cite{szegedy2015going}, ConvNext \cite{liu2022convnet}, EfficientNet \cite{tan2019efficientnet}, and Vision Transformers (ViT) \cite{dosovitskiy2020image}, instead of traditional machine learning models. We evaluate models in three different settings: full fine-tuning, linear evaluation and training from scratch. Our findings demonstrate the effectiveness and capability of our Computer-Aided Diagnosis (CAD) system, with a remarkable accuracy of 76.39\% and an F1 score of 67.94\% in the full fine-tuning setting. Our findings indicate the potential for enhanced diagnostic accuracy in the field of breast imaging, providing a solid foundation for future endeavors aiming to improve the precision and reliability of CAD systems in medical imaging.
Keypoint-Augmented Self-Supervised Learning for Medical Image Segmentation with Limited Annotation
Oct 02, 2023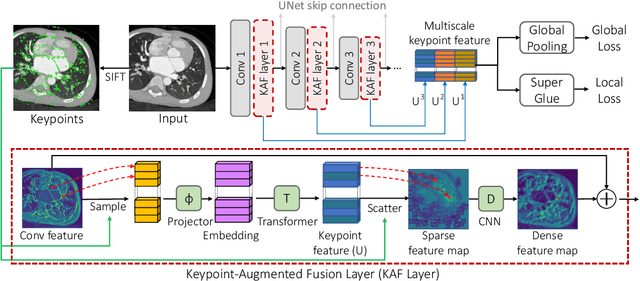
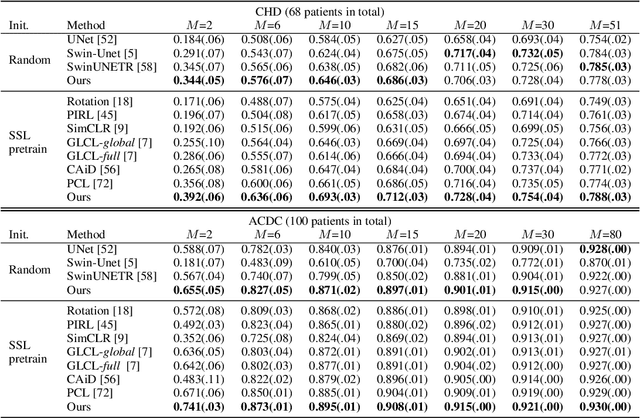
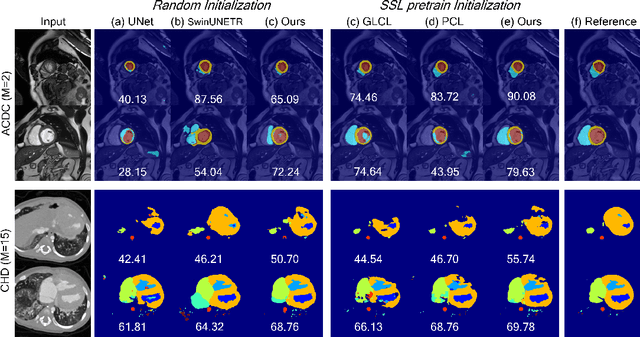
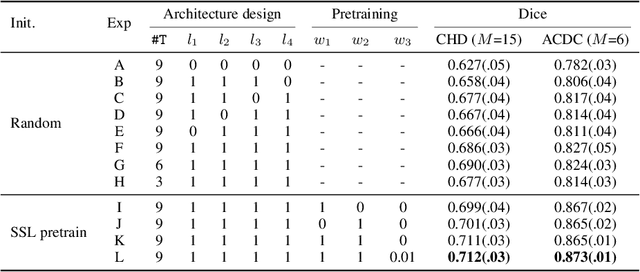
Pretraining CNN models (i.e., UNet) through self-supervision has become a powerful approach to facilitate medical image segmentation under low annotation regimes. Recent contrastive learning methods encourage similar global representations when the same image undergoes different transformations, or enforce invariance across different image/patch features that are intrinsically correlated. However, CNN-extracted global and local features are limited in capturing long-range spatial dependencies that are essential in biological anatomy. To this end, we present a keypoint-augmented fusion layer that extracts representations preserving both short- and long-range self-attention. In particular, we augment the CNN feature map at multiple scales by incorporating an additional input that learns long-range spatial self-attention among localized keypoint features. Further, we introduce both global and local self-supervised pretraining for the framework. At the global scale, we obtain global representations from both the bottleneck of the UNet, and by aggregating multiscale keypoint features. These global features are subsequently regularized through image-level contrastive objectives. At the local scale, we define a distance-based criterion to first establish correspondences among keypoints and encourage similarity between their features. Through extensive experiments on both MRI and CT segmentation tasks, we demonstrate the architectural advantages of our proposed method in comparison to both CNN and Transformer-based UNets, when all architectures are trained with randomly initialized weights. With our proposed pretraining strategy, our method further outperforms existing SSL methods by producing more robust self-attention and achieving state-of-the-art segmentation results. The code is available at https://github.com/zshyang/kaf.git.
IterInv: Iterative Inversion for Pixel-Level T2I Models
Oct 30, 2023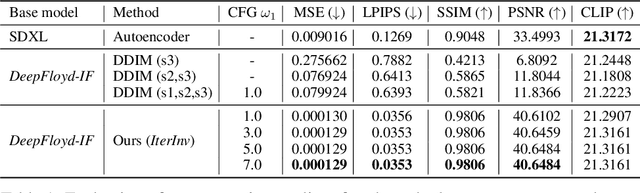

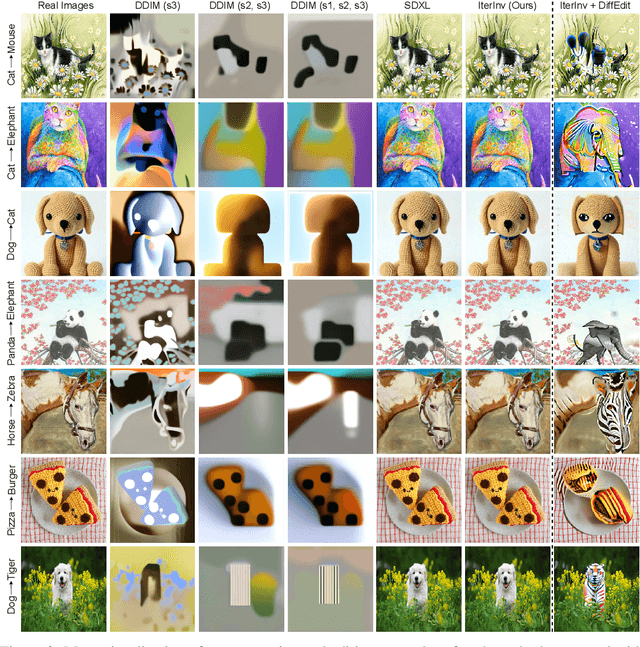
Large-scale text-to-image diffusion models have been a ground-breaking development in generating convincing images following an input text prompt. The goal of image editing research is to give users control over the generated images by modifying the text prompt. Current image editing techniques are relying on DDIM inversion as a common practice based on the Latent Diffusion Models (LDM). However, the large pretrained T2I models working on the latent space as LDM suffer from losing details due to the first compression stage with an autoencoder mechanism. Instead, another mainstream T2I pipeline working on the pixel level, such as Imagen and DeepFloyd-IF, avoids this problem. They are commonly composed of several stages, normally with a text-to-image stage followed by several super-resolution stages. In this case, the DDIM inversion is unable to find the initial noise to generate the original image given that the super-resolution diffusion models are not compatible with the DDIM technique. According to our experimental findings, iteratively concatenating the noisy image as the condition is the root of this problem. Based on this observation, we develop an iterative inversion (IterInv) technique for this stream of T2I models and verify IterInv with the open-source DeepFloyd-IF model. By combining our method IterInv with a popular image editing method, we prove the application prospects of IterInv. The code will be released at \url{https://github.com/Tchuanm/IterInv.git}.
Weakly supervised cross-modal learning in high-content screening
Nov 12, 2023With the surge in available data from various modalities, there is a growing need to bridge the gap between different data types. In this work, we introduce a novel approach to learn cross-modal representations between image data and molecular representations for drug discovery. We propose EMM and IMM, two innovative loss functions built on top of CLIP that leverage weak supervision and cross sites replicates in High-Content Screening. Evaluating our model against known baseline on cross-modal retrieval, we show that our proposed approach allows to learn better representations and mitigate batch effect. In addition, we also present a preprocessing method for the JUMP-CP dataset that effectively reduce the required space from 85Tb to a mere usable 7Tb size, still retaining all perturbations and most of the information content.
EXTRACTER: Efficient Texture Matching with Attention and Gradient Enhancing for Large Scale Image Super Resolution
Oct 02, 2023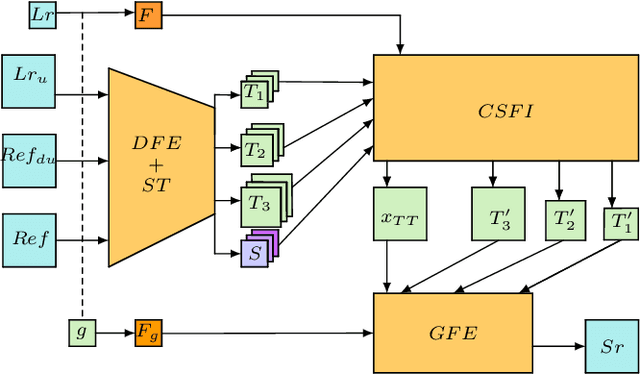

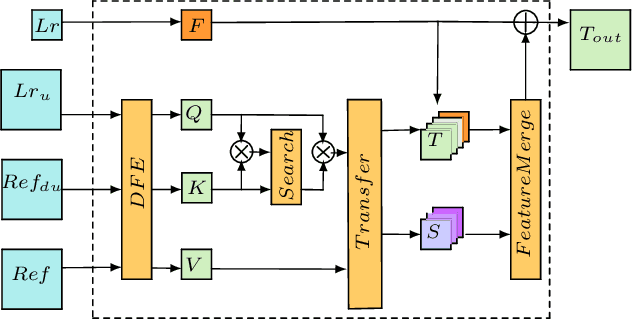

Recent Reference-Based image super-resolution (RefSR) has improved SOTA deep methods introducing attention mechanisms to enhance low-resolution images by transferring high-resolution textures from a reference high-resolution image. The main idea is to search for matches between patches using LR and Reference image pair in a feature space and merge them using deep architectures. However, existing methods lack the accurate search of textures. They divide images into as many patches as possible, resulting in inefficient memory usage, and cannot manage large images. Herein, we propose a deep search with a more efficient memory usage that reduces significantly the number of image patches and finds the $k$ most relevant texture match for each low-resolution patch over the high-resolution reference patches, resulting in an accurate texture match. We enhance the Super Resolution result adding gradient density information using a simple residual architecture showing competitive metrics results: PSNR and SSMI.
'Person' == Light-skinned, Western Man, and Sexualization of Women of Color: Stereotypes in Stable Diffusion
Nov 10, 2023We study stereotypes embedded within one of the most popular text-to-image generators: Stable Diffusion. We examine what stereotypes of gender and nationality/continental identity does Stable Diffusion display in the absence of such information i.e. what gender and nationality/continental identity is assigned to `a person', or to `a person from Asia'. Using vision-language model CLIP's cosine similarity to compare images generated by CLIP-based Stable Diffusion v2.1 verified by manual examination, we chronicle results from 136 prompts (50 results/prompt) of front-facing images of persons from 6 different continents, 27 nationalities and 3 genders. We observe how Stable Diffusion outputs of `a person' without any additional gender/nationality information correspond closest to images of men and least with persons of nonbinary gender, and to persons from Europe/North America over Africa/Asia, pointing towards Stable Diffusion having a concerning representation of personhood to be a European/North American man. We also show continental stereotypes and resultant harms e.g. a person from Oceania is deemed to be Australian/New Zealander over Papua New Guinean, pointing to the erasure of Indigenous Oceanic peoples, who form a majority over descendants of colonizers both in Papua New Guinea and in Oceania overall. Finally, we unexpectedly observe a pattern of oversexualization of women, specifically Latin American, Mexican, Indian and Egyptian women relative to other nationalities, measured through an NSFW detector. This demonstrates how Stable Diffusion perpetuates Western fetishization of women of color through objectification in media, which if left unchecked will amplify this stereotypical representation. Image datasets are made publicly available.