 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOLORA: Efficient Fine-Tuning for Convolutional Models with a Study Case on Optical Coherence Tomography Image Classification
May 23, 2025We introduce the Convolutional Low-Rank Adaptation (CoLoRA) method, designed explicitly to overcome the inefficiencies found in current CNN fine-tuning methods. CoLoRA can be seen as a natural extension of the convolutional architectures of the Low-Rank Adaptation (LoRA) technique. We demonstrate the capabilities of our method by developing and evaluating models using the widely adopted CNN backbone pre-trained on ImageNet. We observed that this strategy results in a stable and accurate coarse-tuning procedure. Moreover, this strategy is computationally efficient and significantly reduces the number of parameters required for fine-tuning compared to traditional methods. Furthermore, our method substantially improves the speed and stability of training. Our case study focuses on classifying retinal diseases from optical coherence tomography (OCT) images, specifically using the OCTMNIST dataset. Experimental results demonstrate that a CNN backbone fine-tuned with CoLoRA surpasses nearly 1\% in accuracy. Such a performance is comparable to the Vision Transformer, State-space discrete, and Kolmogorov-Arnold network models.
EXTRACTER: Efficient Texture Matching with Attention and Gradient Enhancing for Large Scale Image Super Resolution
Oct 02, 2023Recent Reference-Based image super-resolution (RefSR) has improved SOTA deep methods introducing attention mechanisms to enhance low-resolution images by transferring high-resolution textures from a reference high-resolution image. The main idea is to search for matches between patches using LR and Reference image pair in a feature space and merge them using deep architectures. However, existing methods lack the accurate search of textures. They divide images into as many patches as possible, resulting in inefficient memory usage, and cannot manage large images. Herein, we propose a deep search with a more efficient memory usage that reduces significantly the number of image patches and finds the $k$ most relevant texture match for each low-resolution patch over the high-resolution reference patches, resulting in an accurate texture match. We enhance the Super Resolution result adding gradient density information using a simple residual architecture showing competitive metrics results: PSNR and SSMI.
GAMIX-VAE: A VAE with Gaussian Mixture Based Posterior
Sep 22, 2023



Variational Autoencoders (VAEs) have become a cornerstone in generative modeling and representation learning within machine learning. This paper explores a nuanced aspect of VAEs, focusing on interpreting the Kullback Leibler (KL) Divergence, a critical component within the Evidence Lower Bound (ELBO) that governs the trade-off between reconstruction accuracy and regularization. While the KL Divergence enforces alignment between latent variable distributions and a prior imposing a structure on the overall latent space but leaves individual variable distributions unconstrained. The proposed method redefines the ELBO with a mixture of Gaussians for the posterior probability, introduces a regularization term to prevent variance collapse, and employs a PatchGAN discriminator to enhance texture realism. Implementation details involve ResNetV2 architectures for both the Encoder and Decoder. The experiments demonstrate the ability to generate realistic faces, offering a promising solution for enhancing VAE based generative models.
Attentive VQ-VAE
Sep 20, 2023



We present a novel approach to enhance the capabilities of VQVAE models through the integration of an Attentive Residual Encoder (AREN) and a Residual Pixel Attention layer. The objective of our research is to improve the performance of VQVAE while maintaining practical parameter levels. The AREN encoder is designed to operate effectively at multiple levels, accommodating diverse architectural complexities. The key innovation is the integration of an inter-pixel auto-attention mechanism into the AREN encoder. This approach allows us to efficiently capture and utilize contextual information across latent vectors. Additionally, our models uses additional encoding levels to further enhance the model's representational power. Our attention layer employs a minimal parameter approach, ensuring that latent vectors are modified only when pertinent information from other pixels is available. Experimental results demonstrate that our proposed modifications lead to significant improvements in data representation and generation, making VQVAEs even more suitable for a wide range of applications.
Hadamard Layer to Improve Semantic Segmentation
Feb 20, 2023The Hadamard Layer, a simple and computationally efficient way to improve results in semantic segmentation tasks, is presented. This layer has no free parameters that require to be trained. Therefore it does not increase the number of model parameters, and the extra computational cost is marginal. Experimental results show that the new Hadamard layer substantially improves the performance of the investigated models (variants of the Pix2Pix model). The performance's improvement can be explained by the Hadamard layer forcing the network to produce an internal encoding of the classes so that all bins are active. Therefore, the network computation is more distributed. In a sort that the Hadamard layer requires that to change the predicted class, it is necessary to modify $2^{k-1}$ bins, assuming $k$ bins in the encoding. A specific loss function allows a stable and fast training convergence.
AxonNet: A self-supervised Deep Neural Network for Intravoxel Structure Estimation from DW-MRI
Mar 19, 2021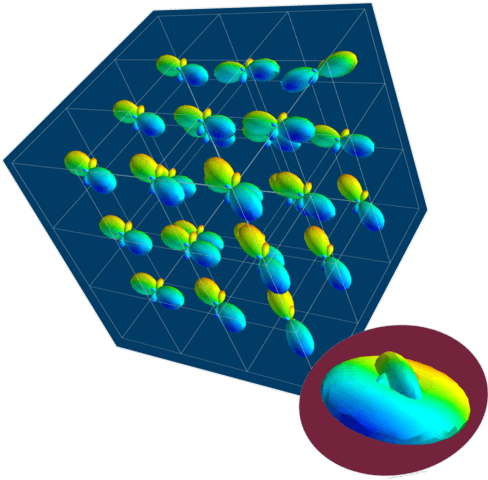
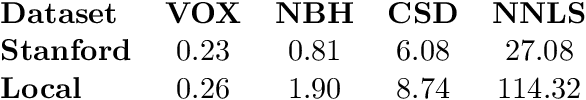
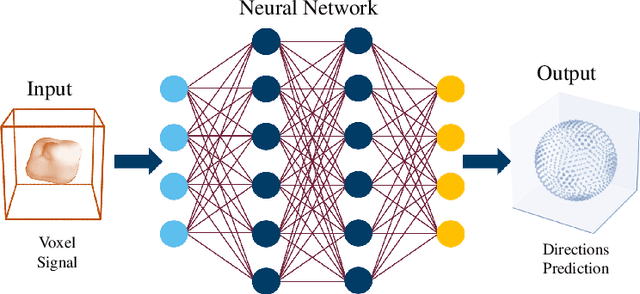
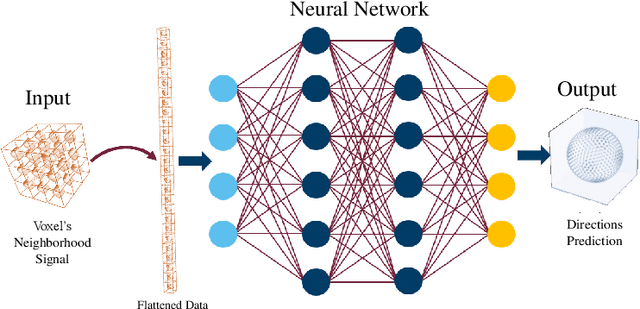
We present a method for estimating intravoxel parameters from a DW-MRI based on deep learning techniques. We show that neural networks (DNNs) have the potential to extract information from diffusion-weighted signals to reconstruct cerebral tracts. We present two DNN models: one that estimates the axonal structure in the form of a voxel and the other to calculate the structure of the central voxel using the voxel neighborhood. Our methods are based on a proposed parameter representation suitable for the problem. Since it is practically impossible to have real tagged data for any acquisition protocol, we used a self-supervised strategy. Experiments with synthetic data and real data show that our approach is competitive, and the computational times show that our approach is faster than the SOTA methods, even if training times are considered. This computational advantage increases if we consider the prediction of multiple images with the same acquisition protocol.
Deep neural network for fringe pattern filtering and normalisation
Jun 14, 2019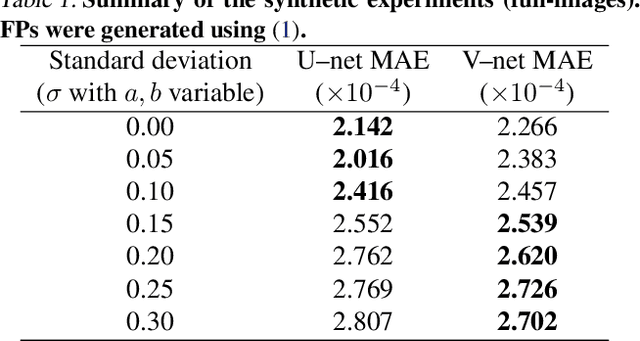
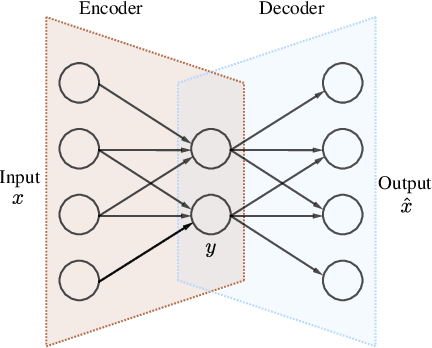
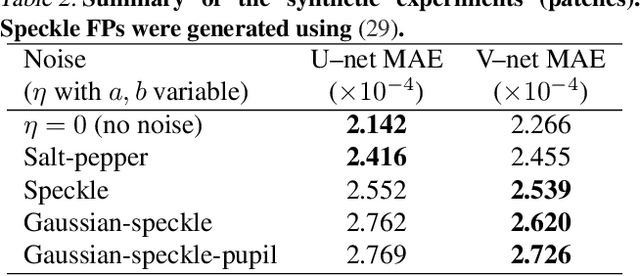
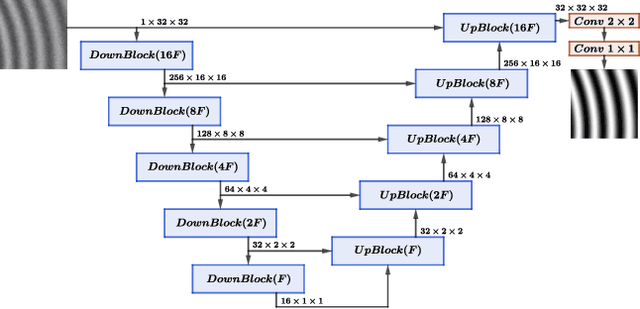
We propose a new framework for processing Fringe Patterns (FP). Our novel approach builds upon the hypothesis that the denoising and normalisation of FPs can be learned by a deep neural network if enough pairs of corrupted and cleaned FPs are provided. Although similar proposals have been reported in the literature, we propose an improvement of a well-known deep neural network architecture, which produces high-quality results in terms of stability and repeatability. We test the performance of our method in various scenarios: FPs corrupted with different degrees of noise, and corrupted with different noise distributions. We compare our methodology versus other state-of-the-art methods. The experimental results (on both synthetic and real data) demonstrate the capabilities and potential of this new paradigm for processing interferograms. We expect our work would motivate more sophisticated developments in this direction.