 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
3D Human Pose Estimation from a Single Image via Distance Matrix Regression
Nov 28, 2016
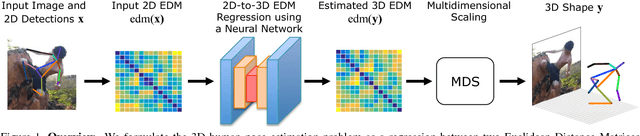
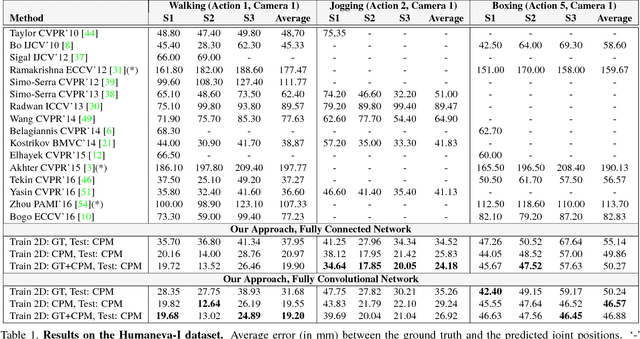
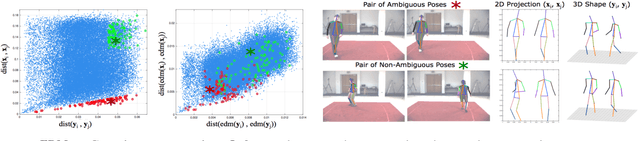
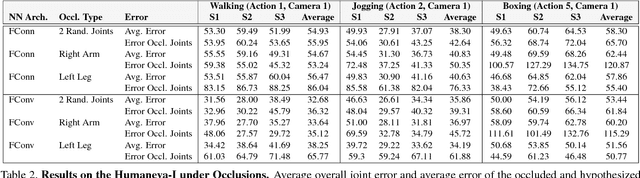
This paper addresses the problem of 3D human pose estimation from a single image. We follow a standard two-step pipeline by first detecting the 2D position of the $N$ body joints, and then using these observations to infer 3D pose. For the first step, we use a recent CNN-based detector. For the second step, most existing approaches perform 2$N$-to-3$N$ regression of the Cartesian joint coordinates. We show that more precise pose estimates can be obtained by representing both the 2D and 3D human poses using $N\times N$ distance matrices, and formulating the problem as a 2D-to-3D distance matrix regression. For learning such a regressor we leverage on simple Neural Network architectures, which by construction, enforce positivity and symmetry of the predicted matrices. The approach has also the advantage to naturally handle missing observations and allowing to hypothesize the position of non-observed joints. Quantitative results on Humaneva and Human3.6M datasets demonstrate consistent performance gains over state-of-the-art. Qualitative evaluation on the images in-the-wild of the LSP dataset, using the regressor learned on Human3.6M, reveals very promising generalization results.
Noisier2Noise: Learning to Denoise from Unpaired Noisy Data
Oct 25, 2019
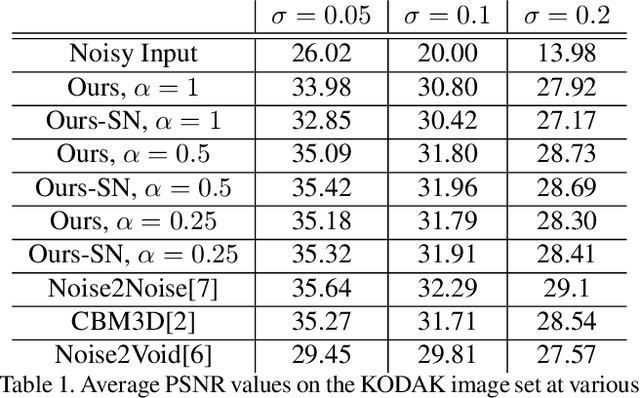


We present a method for training a neural network to perform image denoising without access to clean training examples or access to paired noisy training examples. Our method requires only a single noisy realization of each training example and a statistical model of the noise distribution, and is applicable to a wide variety of noise models, including spatially structured noise. Our model produces results which are competitive with other learned methods which require richer training data, and outperforms traditional non-learned denoising methods. We present derivations of our method for arbitrary additive noise, an improvement specific to Gaussian additive noise, and an extension to multiplicative Bernoulli noise.
TopoTag: A Robust and Scalable Topological Fiducial Marker System
Aug 05, 2019
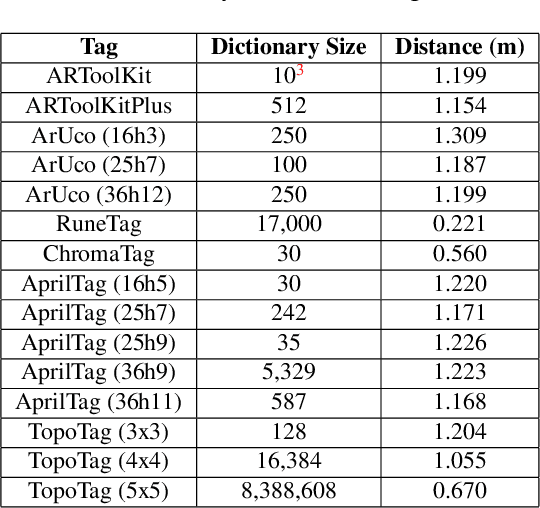

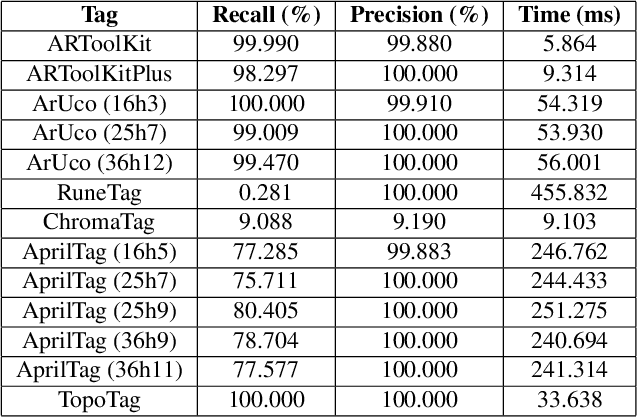
Fiducial markers have been playing an important role in augmented reality (AR), robot navigation, and general applications where the relative pose between a camera and an object is required. We introduce TopoTag, a robust and scalable topological fiducial marker system, which supports reliable and accurate pose estimation from a single image. TopoTag uses topological and geometrical information in marker detection to achieve higher robustness. Without sacrificing bits for higher recall and precision like previous systems, TopoTag can use full bits for ID encoding and supports tens of thousands unique IDs and easily extends to millions and more by adding more bits, thus achieves perfect scalability. We collect a large dataset including in total 169,713 images for evaluation, involving in-plane and out-of-plane rotation, image blur, different distances and various backgrounds, etc. Experiments show that TopoTag significantly outperforms previous fiducial marker systems in terms of various metrics, including detection accuracy, vertex jitter, pose jitter and accuracy, etc. In addition, TopoTag supports occlusion as long as main tag topological structure is maintained and flexible shape design where users can customize inter and outer marker shapes. Our dataset, marker design and detection algorithm are public to the community.
Self-supervised Monocular Trained Depth Estimation using Self-attention and Discrete Disparity Volume
Mar 31, 2020
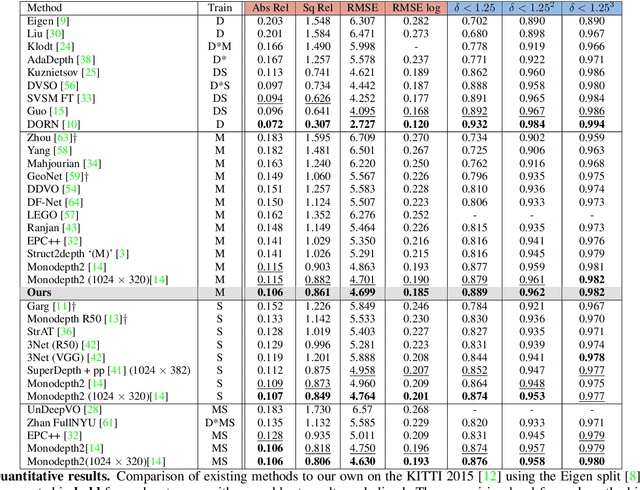
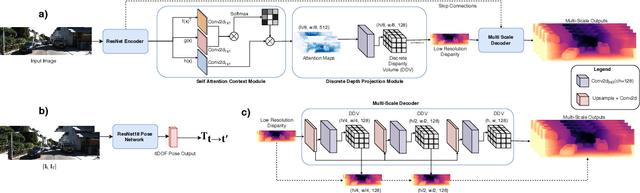
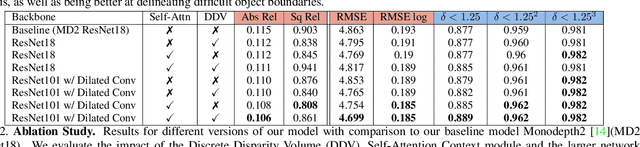
Monocular depth estimation has become one of the most studied applications in computer vision, where the most accurate approaches are based on fully supervised learning models. However, the acquisition of accurate and large ground truth data sets to model these fully supervised methods is a major challenge for the further development of the area. Self-supervised methods trained with monocular videos constitute one the most promising approaches to mitigate the challenge mentioned above due to the wide-spread availability of training data. Consequently, they have been intensively studied, where the main ideas explored consist of different types of model architectures, loss functions, and occlusion masks to address non-rigid motion. In this paper, we propose two new ideas to improve self-supervised monocular trained depth estimation: 1) self-attention, and 2) discrete disparity prediction. Compared with the usual localised convolution operation, self-attention can explore a more general contextual information that allows the inference of similar disparity values at non-contiguous regions of the image. Discrete disparity prediction has been shown by fully supervised methods to provide a more robust and sharper depth estimation than the more common continuous disparity prediction, besides enabling the estimation of depth uncertainty. We show that the extension of the state-of-the-art self-supervised monocular trained depth estimator Monodepth2 with these two ideas allows us to design a model that produces the best results in the field in KITTI 2015 and Make3D, closing the gap with respect self-supervised stereo training and fully supervised approaches.
Label Smoothing and Logit Squeezing: A Replacement for Adversarial Training?
Oct 25, 2019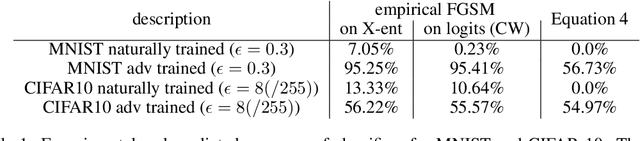
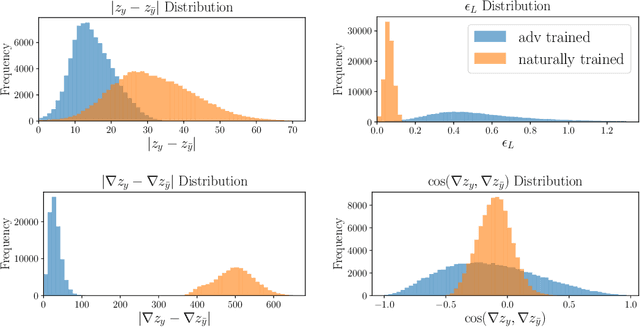
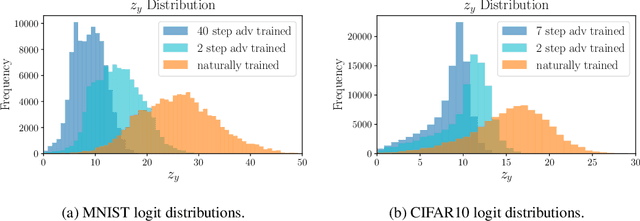
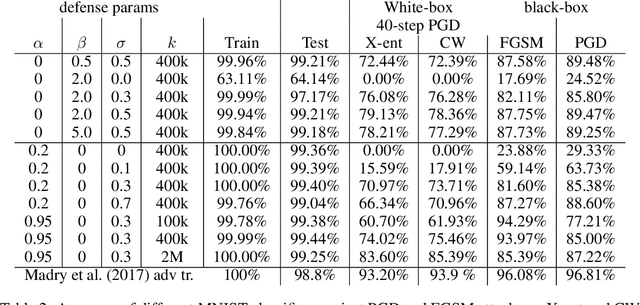
Adversarial training is one of the strongest defenses against adversarial attacks, but it requires adversarial examples to be generated for every mini-batch during optimization. The expense of producing these examples during training often precludes adversarial training from use on complex image datasets. In this study, we explore the mechanisms by which adversarial training improves classifier robustness, and show that these mechanisms can be effectively mimicked using simple regularization methods, including label smoothing and logit squeezing. Remarkably, using these simple regularization methods in combination with Gaussian noise injection, we are able to achieve strong adversarial robustness -- often exceeding that of adversarial training -- using no adversarial examples.
A Scalable Multilabel Classification to Deploy Deep Learning Architectures For Edge Devices
Nov 05, 2019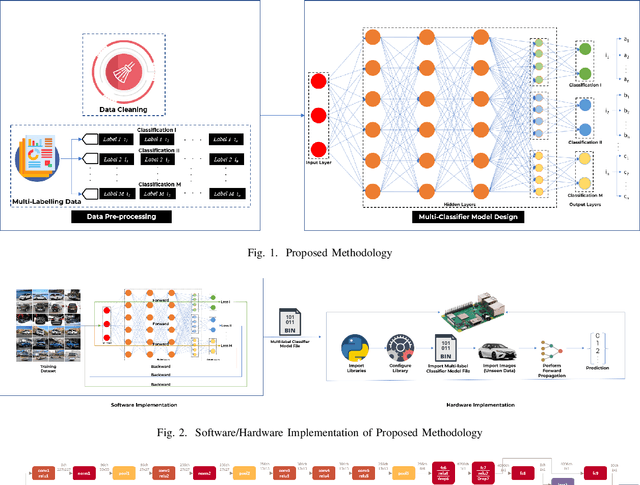

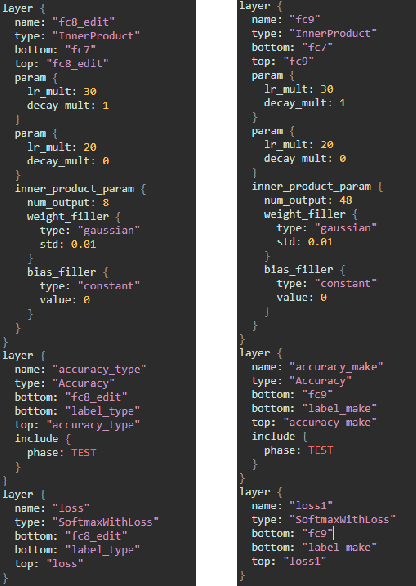
Convolution Neural Networks (CNN) have performed well in many applications such as object detection, pattern recognition, video surveillance and so on. CNN carryout feature extraction on labelled data to perform classification. Multi-label classification assigns more than one label to a particular data sample in a data set. In multi-label classification, properties of a data point that are considered to be mutually exclusive are classified. However, existing multi-label classification requires some form of data pre-processing that involves image training data cropping or image tiling. The computation and memory requirement of these multi-label CNN models makes their deployment on edge devices challenging. In this paper, we propose a methodology that solves this problem by extending the capability of existing multi-label classification and provide models with lower latency that requires smaller memory size when deployed on edge devices. We make use of a single CNN model designed with multiple loss layers and multiple accuracy layers. This methodology is tested on state-of-the-art deep learning algorithms such as AlexNet, GoogleNet and SqueezeNet using the Stanford Cars Dataset and deployed on Raspberry Pi3. From the results the proposed methodology achieves comparable accuracy with 1.8x less MACC operation, 0.97x reduction in latency and 0.5x, 0.84x and 0.97x reduction in size for the generated AlexNet, GoogleNet and SqueezeNet CNN models respectively when compared to conventional ways of achieving multi-label classification like hard-coding multi-label instances into single labels. The methodology also yields CNN models that achieve 50\% less MACC operations, 50% reduction in latency and size of generated versions of AlexNet, GoogleNet and SqueezeNet respectively when compared to conventional ways using 2 different single-labelled models to achieve multi-label classification.
Eliminating artefacts in Polarimetric Images using Deep Learning
Nov 19, 2019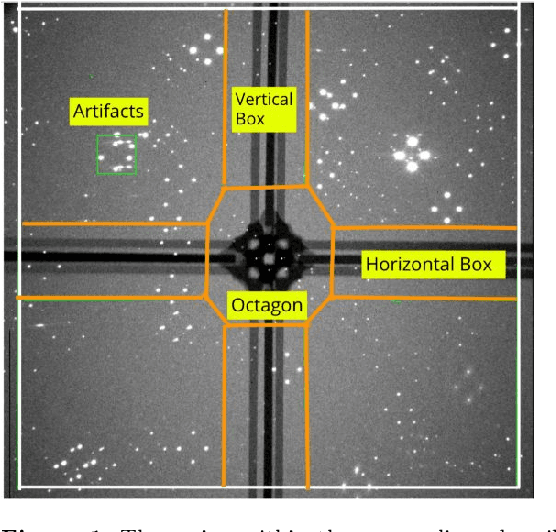
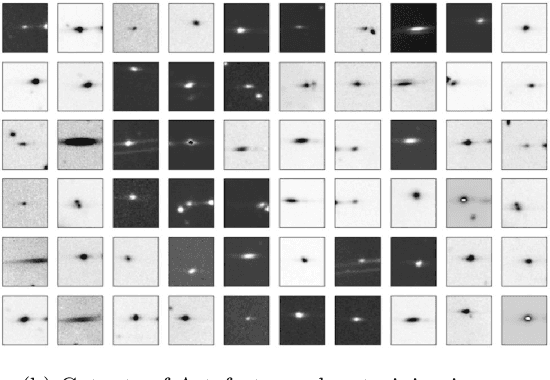
Polarization measurements done using Imaging Polarimeters such as the Robotic Polarimeter are very sensitive to the presence of artefacts in images. Artefacts can range from internal reflections in a telescope to satellite trails that could contaminate an area of interest in the image. With the advent of wide-field polarimetry surveys, it is imperative to develop methods that automatically flag artefacts in images. In this paper, we implement a Convolutional Neural Network to identify the most dominant artefacts in the images. We find that our model can successfully classify sources with 98\% true positive and 97\% true negative rates. Such models, combined with transfer learning, will give us a running start in artefact elimination for near-future surveys like WALOP.
Studying Satellite Image Quality Based on the Fusion Techniques
Oct 22, 2011



Various and different methods can be used to produce high-resolution multispectral images from high-resolution panchromatic image (PAN) and low-resolution multispectral images (MS), mostly on the pixel level. However, the jury is still out on the benefits of a fused image compared to its original images. There is also a lack of measures for assessing the objective quality of the spatial resolution for the fusion methods. Therefore, an objective quality of the spatial resolution assessment for fusion images is required. So, this study attempts to develop a new qualitative assessment to evaluate the spatial quality of the pan sharpened images by many spatial quality metrics. Also, this paper deals with a comparison of various image fusion techniques based on pixel and feature fusion techniques.
Bayes Merging of Multiple Vocabularies for Scalable Image Retrieval
Apr 13, 2014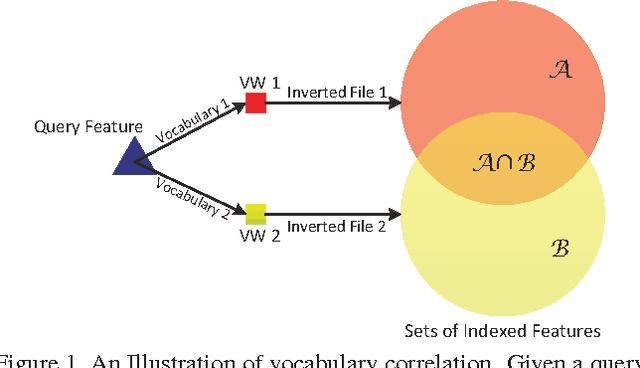
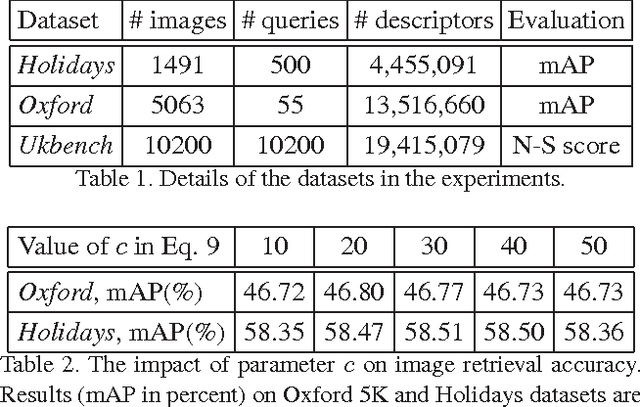
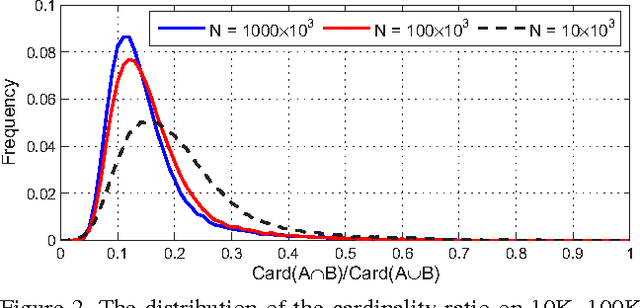

The Bag-of-Words (BoW) representation is well applied to recent state-of-the-art image retrieval works. Typically, multiple vocabularies are generated to correct quantization artifacts and improve recall. However, this routine is corrupted by vocabulary correlation, i.e., overlapping among different vocabularies. Vocabulary correlation leads to an over-counting of the indexed features in the overlapped area, or the intersection set, thus compromising the retrieval accuracy. In order to address the correlation problem while preserve the benefit of high recall, this paper proposes a Bayes merging approach to down-weight the indexed features in the intersection set. Through explicitly modeling the correlation problem in a probabilistic view, a joint similarity on both image- and feature-level is estimated for the indexed features in the intersection set. We evaluate our method through extensive experiments on three benchmark datasets. Albeit simple, Bayes merging can be well applied in various merging tasks, and consistently improves the baselines on multi-vocabulary merging. Moreover, Bayes merging is efficient in terms of both time and memory cost, and yields competitive performance compared with the state-of-the-art methods.
lambda-Connectedness Determination for Image Segmentation
Mar 16, 2008

Image segmentation is to separate an image into distinct homogeneous regions belonging to different objects. It is an essential step in image analysis and computer vision. This paper compares some segmentation technologies and attempts to find an automated way to better determine the parameters for image segmentation, especially the connectivity value of $\lambda$ in $\lambda$-connected segmentation. Based on the theories on the maximum entropy method and Otsu's minimum variance method, we propose:(1)maximum entropy connectedness determination: a method that uses maximum entropy to determine the best $\lambda$ value in $\lambda$-connected segmentation, and (2) minimum variance connectedness determination: a method that uses the principle of minimum variance to determine $\lambda$ value. Applying these optimization techniques in real images, the experimental results have shown great promise in the development of the new methods. In the end, we extend the above method to more general case in order to compare it with the famous Mumford-Shah method that uses variational principle and geometric measure.