 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Texture Superpixel Clustering from Patch-based Nearest Neighbor Matching
Mar 09, 2020
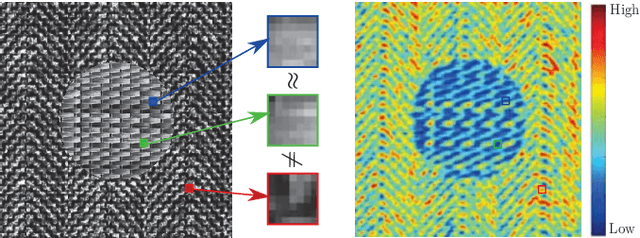
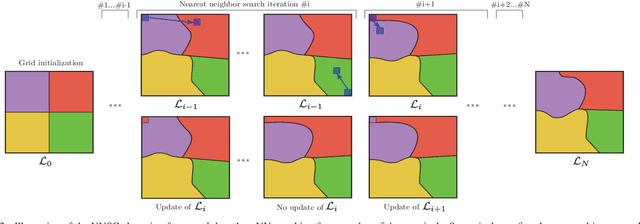
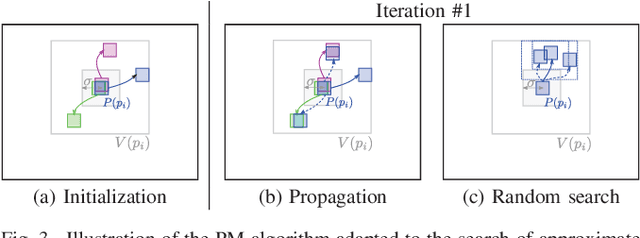
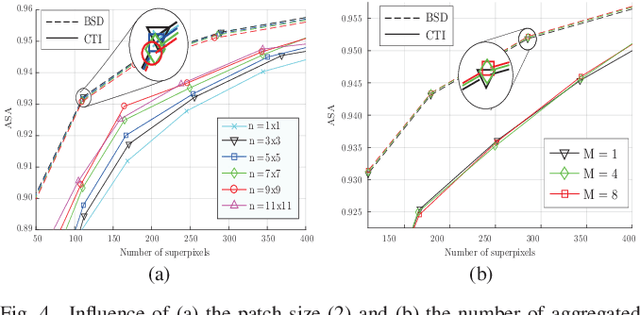
Superpixels are widely used in computer vision applications. Nevertheless, decomposition methods may still fail to efficiently cluster image pixels according to their local texture. In this paper, we propose a new Nearest Neighbor-based Superpixel Clustering (NNSC) method to generate texture-aware superpixels in a limited computational time compared to previous approaches. We introduce a new clustering framework using patch-based nearest neighbor matching, while most existing methods are based on a pixel-wise K-means clustering. Therefore, we directly group pixels in the patch space enabling to capture texture information. We demonstrate the efficiency of our method with favorable comparison in terms of segmentation performances on both standard color and texture datasets. We also show the computational efficiency of NNSC compared to recent texture-aware superpixel methods.
Quantum spectral analysis: frequency in time, with applications to signal and image processing
Mar 16, 2018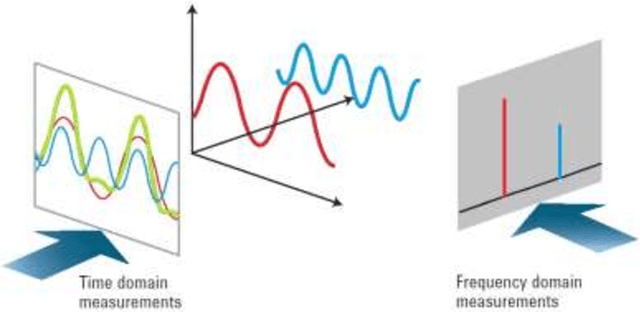

A quantum time-dependent spectrum analysis, or simply, quantum spectral analysis (QSA) is presented in this work, and it is based on Schrodinger equation, which is a partial differential equation that describes how the quantum state of a non-relativistic physical system changes with time. In classic world is named frequency in time (FIT), which is presented here in opposition and as a complement of traditional spectral analysis frequency-dependent based on Fourier theory. Besides, FIT is a metric, which assesses the impact of the flanks of a signal on its frequency spectrum, which is not taken into account by Fourier theory and even less in real time. Even more, and unlike all derived tools from Fourier Theory (i.e., continuous, discrete, fast, short-time, fractional and quantum Fourier Transform, as well as, Gabor) FIT has the following advantages: a) compact support with excellent energy output treatment, b) low computational cost, O(N) for signals and O(N2) for images, c) it does not have phase uncertainties (indeterminate phase for magnitude = 0) as Discrete and Fast Fourier Transform (DFT, FFT, respectively), d) among others. In fact, FIT constitutes one side of a triangle (which from now on is closed) and it consists of the original signal in time, spectral analysis based on Fourier Theory and FIT. Thus a toolbox is completed, which it is essential for all applications of Digital Signal Processing (DSP) and Digital Image Processing (DIP); and, even, in the latter, FIT allows edge detection (which is called flank detection in case of signals), denoising, despeckling, compression, and superresolution of still images. Such applications include signals intelligence and imagery intelligence. On the other hand, we will present other DIP tools, which are also derived from the Schrodinger equation.
Region Mutual Information Loss for Semantic Segmentation
Oct 26, 2019

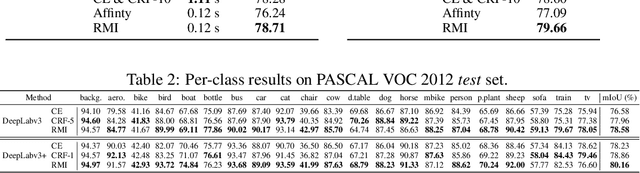

Semantic segmentation is a fundamental problem in computer vision. It is considered as a pixel-wise classification problem in practice, and most segmentation models use a pixel-wise loss as their optimization riterion. However, the pixel-wise loss ignores the dependencies between pixels in an image. Several ways to exploit the relationship between pixels have been investigated, \eg, conditional random fields (CRF) and pixel affinity based methods. Nevertheless, these methods usually require additional model branches, large extra memories, or more inference time. In this paper, we develop a region mutual information (RMI) loss to model the dependencies among pixels more simply and efficiently. In contrast to the pixel-wise loss which treats the pixels as independent samples, RMI uses one pixel and its neighbour pixels to represent this pixel. Then for each pixel in an image, we get a multi-dimensional point that encodes the relationship between pixels, and the image is cast into a multi-dimensional distribution of these high-dimensional points. The prediction and ground truth thus can achieve high order consistency through maximizing the mutual information (MI) between their multi-dimensional distributions. Moreover, as the actual value of the MI is hard to calculate, we derive a lower bound of the MI and maximize the lower bound to maximize the real value of the MI. RMI only requires a few extra computational resources in the training stage, and there is no overhead during testing. Experimental results demonstrate that RMI can achieve substantial and consistent improvements in performance on PASCAL VOC 2012 and CamVid datasets. The code is available at https://github.com/ZJULearning/RMI.
Adversarial Patches Exploiting Contextual Reasoning in Object Detection
Sep 30, 2019


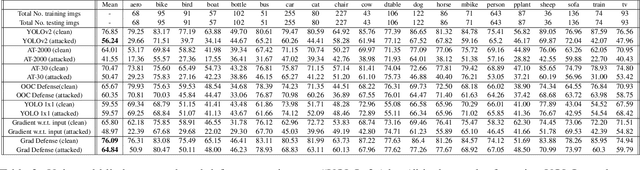
The usefulness of spatial context in most fast object detection algorithms that do a single forward pass per image is well known where they utilize context to improve their accuracy. In fact, they must do it to increase the inference speed by processing the image just once. We show that an adversary can attack the model by exploiting contextual reasoning. We develop adversarial attack algorithms that make an object detector blind to a particular category chosen by the adversary even though the patch does not overlap with the missed detections. We also show that limiting the use of contextual reasoning in learning the object detector acts as a form of defense that improves the accuracy of the detector after an attack. We believe defending against our practical adversarial attack algorithms is not easy and needs attention from the research community.
Mask Embedding in conditional GAN for Guided Synthesis of High Resolution Images
Jul 03, 2019


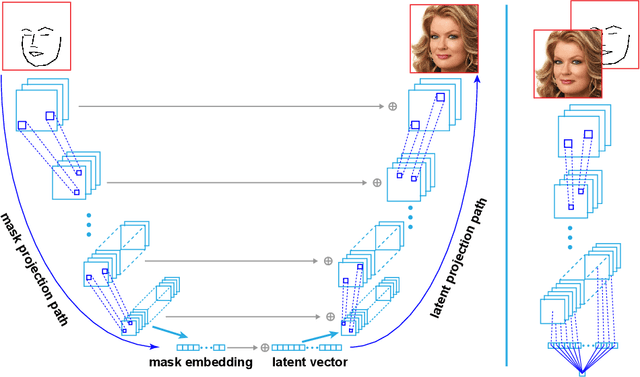
Recent advancements in conditional Generative Adversarial Networks (cGANs) have shown promises in label guided image synthesis. Semantic masks, such as sketches and label maps, are another intuitive and effective form of guidance in image synthesis. Directly incorporating the semantic masks as constraints dramatically reduces the variability and quality of the synthesized results. We observe this is caused by the incompatibility of features from different inputs (such as mask image and latent vector) of the generator. To use semantic masks as guidance whilst providing realistic synthesized results with fine details, we propose to use mask embedding mechanism to allow for a more efficient initial feature projection in the generator. We validate the effectiveness of our approach by training a mask guided face generator using CELEBA-HQ dataset. We can generate realistic and high resolution facial images up to the resolution of 512*512 with a mask guidance. Our code is publicly available.
Apache Spark Accelerated Deep Learning Inference for Large Scale Satellite Image Analytics
Aug 08, 2019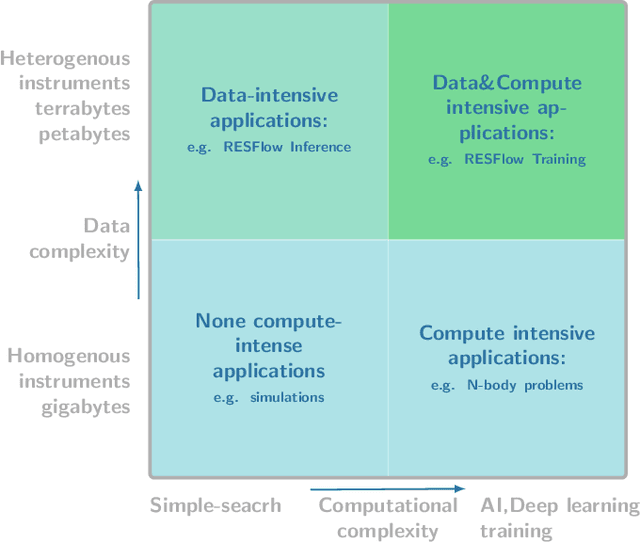


The shear volumes of data generated from earth observation and remote sensing technologies continue to make major impact; leaping key geospatial applications into the dual data and compute intensive era. As a consequence, this rapid advancement poses new computational and data processing challenges. We implement a novel remote sensing data flow (RESFlow) for advanced machine learning and computing with massive amounts of remotely sensed imagery. The core contribution is partitioning massive amount of data based on the spectral and semantic characteristics for distributed imagery analysis. RESFlow takes advantage of both a unified analytics engine for large-scale data processing and the availability of modern computing hardware to harness the acceleration of deep learning inference on expansive remote sensing imagery. The framework incorporates a strategy to optimize resource utilization across multiple executors assigned to a single worker. We showcase its deployment across computationally and data-intensive on pixel-level labeling workloads. The pipeline invokes deep learning inference at three stages; during deep feature extraction, deep metric mapping, and deep semantic segmentation. The tasks impose compute intensive and GPU resource sharing challenges motivating for a parallelized pipeline for all execution steps. By taking advantage of Apache Spark, Nvidia DGX1, and DGX2 computing platforms, we demonstrate unprecedented compute speed-ups for deep learning inference on pixel labeling workloads; processing 21,028~Terrabytes of imagery data and delivering an output maps at area rate of 5.245sq.km/sec, amounting to 453,168 sq.km/day - reducing a 28 day workload to 21~hours.
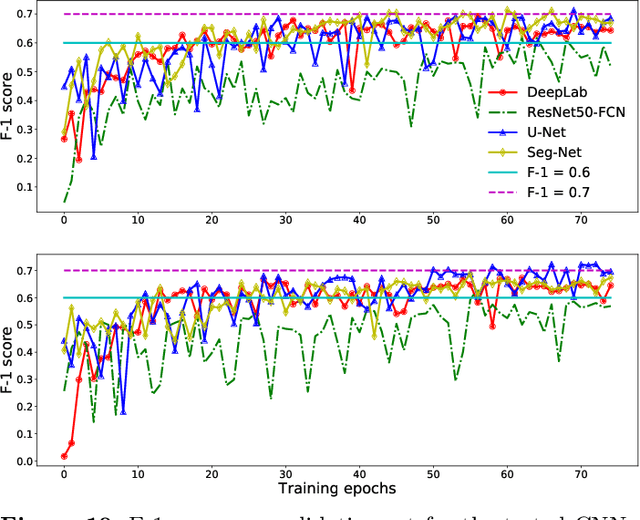
Image Denoising using New Adaptive Based Median Filters
Sep 10, 2014
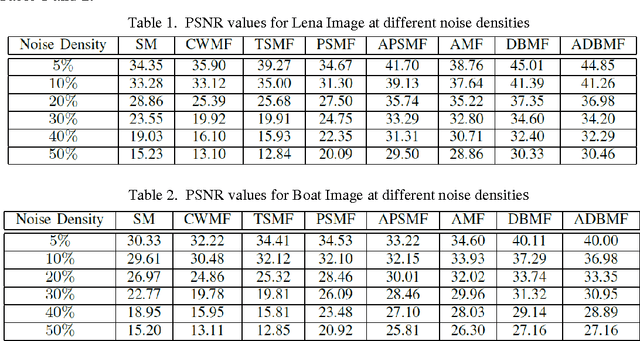

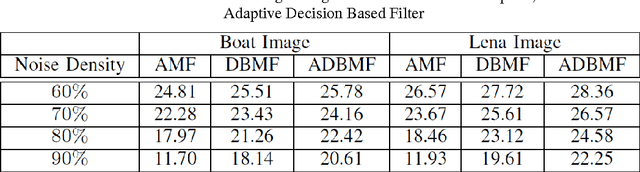
Noise is a major issue while transferring images through all kinds of electronic communication. One of the most common noise in electronic communication is an impulse noise which is caused by unstable voltage. In this paper, the comparison of known image denoising techniques is discussed and a new technique using the decision based approach has been used for the removal of impulse noise. All these methods can primarily preserve image details while suppressing impulsive noise. The principle of these techniques is at first introduced and then analysed with various simulation results using MATLAB. Most of the previously known techniques are applicable for the denoising of images corrupted with less noise density. Here a new decision based technique has been presented which shows better performances than those already being used. The comparisons are made based on visual appreciation and further quantitatively by Mean Square error (MSE) and Peak Signal to Noise Ratio (PSNR) of different filtered images..
Layer-wise Pruning and Auto-tuning of Layer-wise Learning Rates in Fine-tuning of Deep Networks
Feb 17, 2020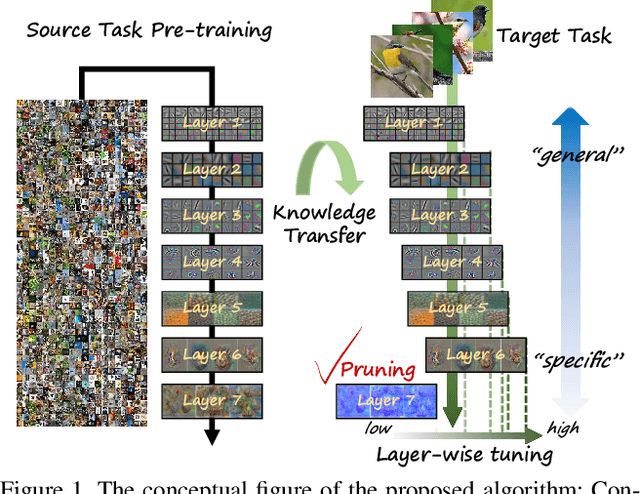
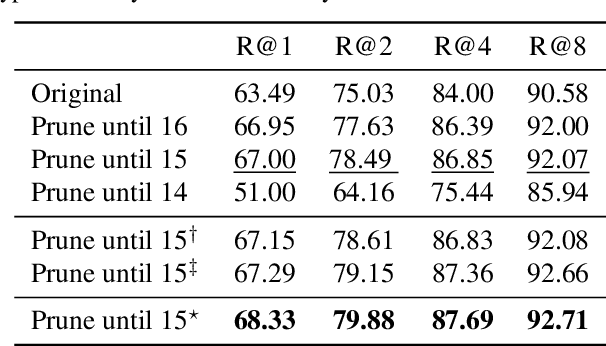
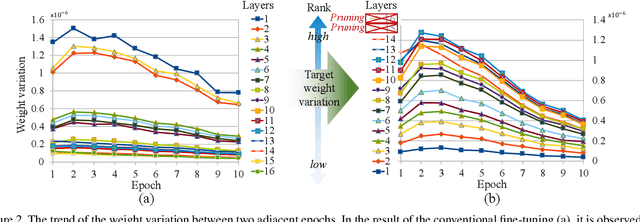

Existing fine-tuning methods use a single learning rate over all layers. In this paper, first, we discuss that trends of layer-wise weight variations by fine-tuning using a single learning rate do not match the well-known notion that lower-level layers extract general features and higher-level layers extract specific features. Based on our discussion, we propose an algorithm that improves fine-tuning performance and reduces network complexity through layer-wise pruning and auto-tuning of layer-wise learning rates. Through in-depth experiments on image retrieval (CUB-200-2011, Stanford online products, and Inshop) and fine-grained classification (Stanford cars, Aircraft) datasets, the effectiveness of the proposed algorithm is verified.
Explaining Predictions by Approximating the Local Decision Boundary
Jun 14, 2020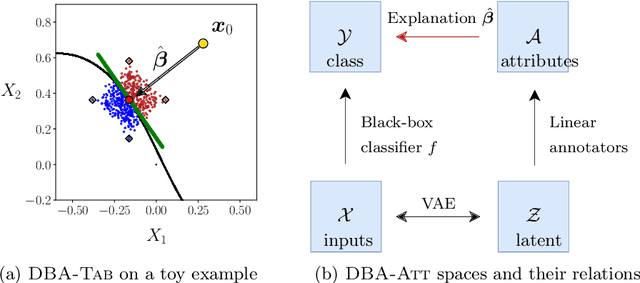

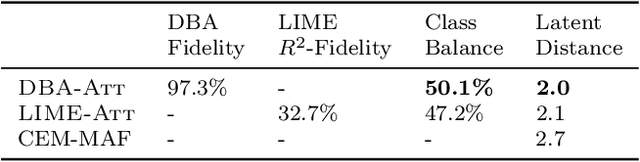
Constructing accurate model-agnostic explanations for opaque machine learning models remains a challenging task. Classification models for high-dimensional data, like images, are often complex and highly parameterized. To reduce this complexity, various authors attempt to explain individual predictions locally, either in terms of a simpler local surrogate model or by communicating how the predictions contrast with those of another class. However, existing approaches still fall short in the following ways: a) they measure locality using a (Euclidean) metric that is not meaningful for non-linear high-dimensional data; or b) they do not attempt to explain the decision boundary, which is the most relevant characteristic of classifiers that are optimized for classification accuracy; or c) they do not give the user any freedom in specifying attributes that are meaningful to them. We address these issues in a new procedure for local decision boundary approximation (DBA). To construct a meaningful metric, we train a variational autoencoder to learn a Euclidean latent space of encoded data representations. We impose interpretability by exploiting attribute annotations to map the latent space to attributes that are meaningful to the user. A difficulty in evaluating explainability approaches is the lack of a ground truth. We address this by introducing a new benchmark data set with artificially generated Iris images, and showing that we can recover the latent attributes that locally determine the class. We further evaluate our approach on the CelebA image data set.
PicHunt: Social Media Image Retrieval for Improved Law Enforcement
Sep 15, 2016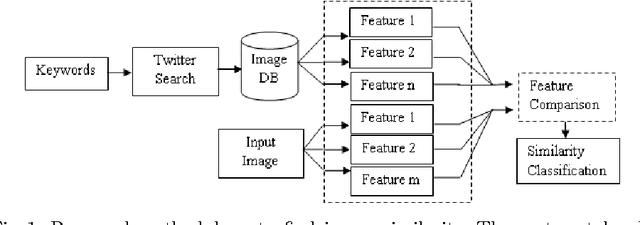


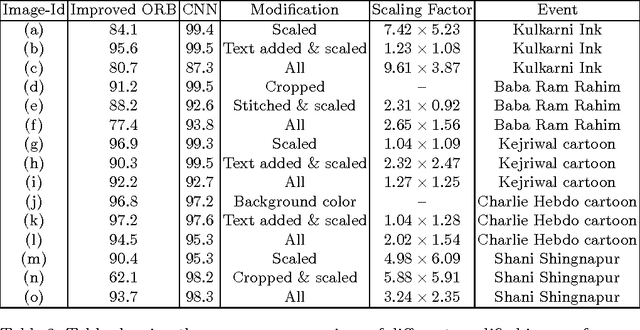
First responders are increasingly using social media to identify and reduce crime for well-being and safety of the society. Images shared on social media hurting religious, political, communal and other sentiments of people, often instigate violence and create law & order situations in society. This results in the need for first responders to inspect the spread of such images and users propagating them on social media. In this paper, we present a comparison between different hand-crafted features and a Convolutional Neural Network (CNN) model to retrieve similar images, which outperforms state-of-art hand-crafted features. We propose an Open-Source-Intelligent (OSINT) real-time image search system, robust to retrieve modified images that allows first responders to analyze the current spread of images, sentiments floating and details of users propagating such content. The system also aids officials to save time of manually analyzing the content by reducing the search space on an average by 67%.