 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Automated Crabgrass Detection in Aerial Imagery with Context
Oct 01, 2019



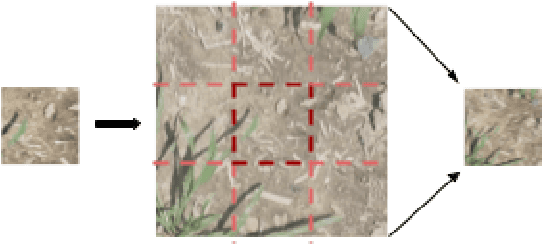
In this paper, we demonstrate the ability to discriminate between cultivated maize plant and crabgrass weed image segments using the context surrounding the image segments. While convolutional neural networks have brought state of the art accuracies within object detection, errors arise when objects in different classes share similar features. This scenario often occurs when objects in images are viewed at too small of a scale to discern distinct differences in features, causing images to be incorrectly classified or localized. To solve this problem, we will explore using context when classifying image segments. This technique involves feeding a convolutional neural network a central square image along with a border of its direct surroundings at train and test times. This means that although images are labelled at a smaller scale to preserve accurate localization, the network classifies the images and learns features that include the wider context. We demonstrate the benefits of this context technique in the object detection task through a case study of crabgrass detection in maize fields. In this standard situation, adding context alone nearly halved the error of the neural network from 7.1% to 4.3%. After only one epoch with context, the network also achieved a higher accuracy than the network without context did after 50 epochs. The benefits of using the context technique are likely to particularly evident in agricultural contexts in which parts (such as leaves) of several plants may appear similar when not taking into account the context in which those parts appear.
Bayesian Sparsification Methods for Deep Complex-valued Networks
Mar 25, 2020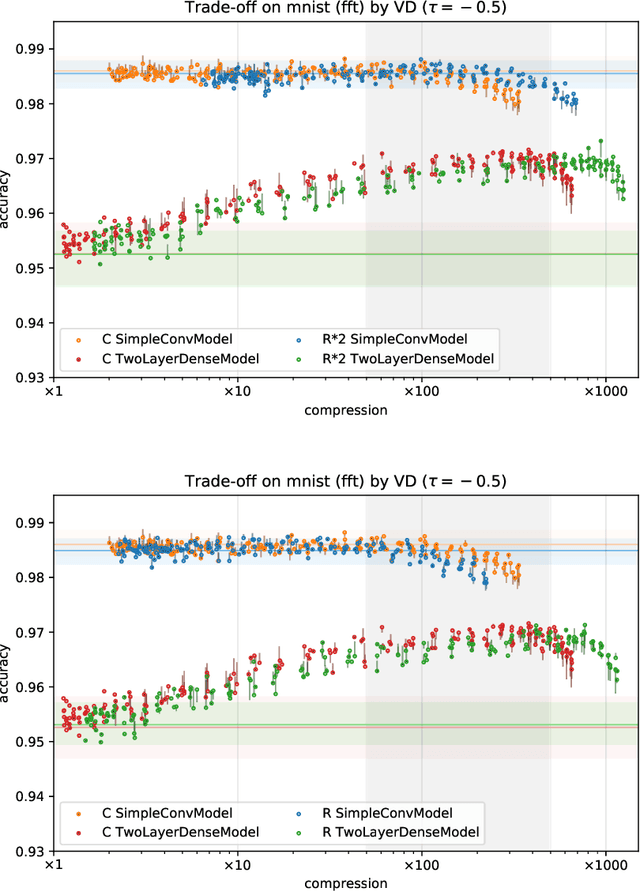
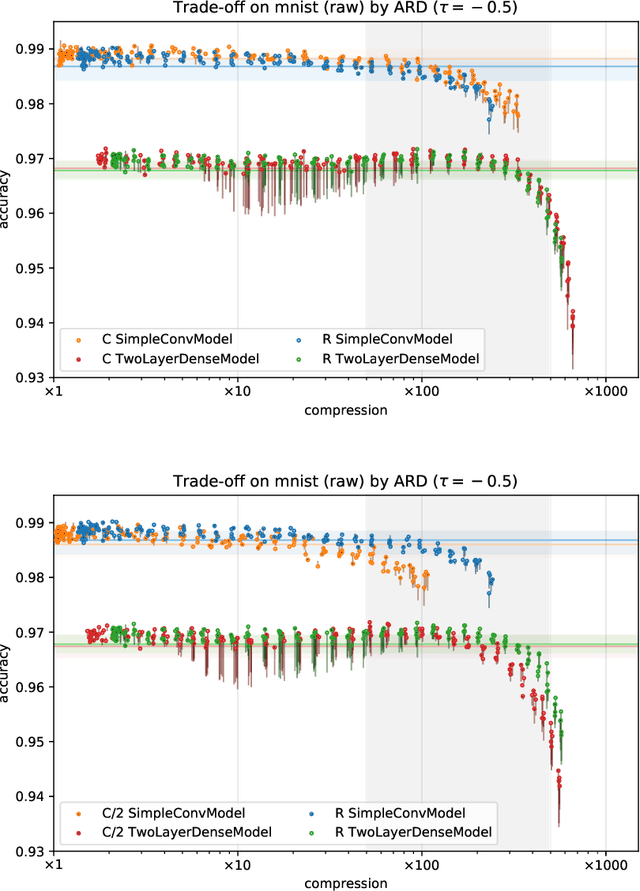
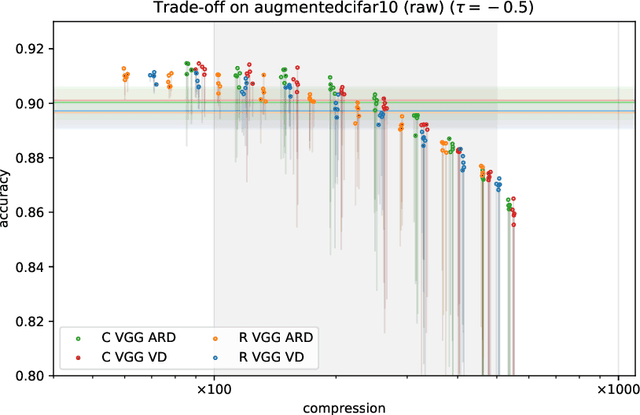
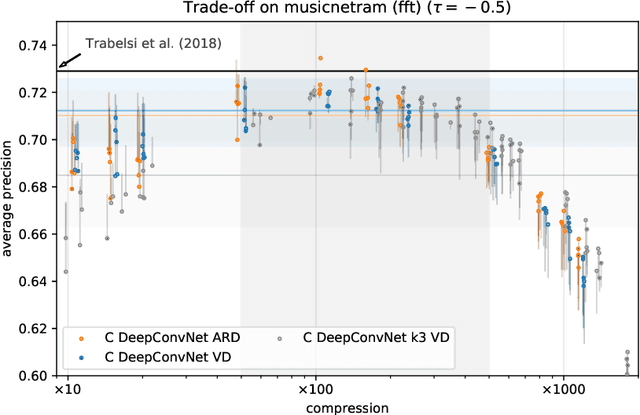
With continual miniaturization ever more applications of deep learning can be found in embedded systems, where it is common to encounter data with natural complex domain representation. To this end we extend Sparse Variational Dropout to complex-valued neural networks and verify the proposed Bayesian technique by conducting a large numerical study of the performance-compression trade-off of C-valued networks on two tasks: image recognition on MNIST-like and CIFAR10 datasets and music transcription on MusicNet. We replicate the state-of-the-art result by Trabelsi et al. [2018] on MusicNet with a complex-valued network compressed by 50-100x at a small performance penalty.
Bi-direction Context Propagation Network for Real-time Semantic Segmentation
May 22, 2020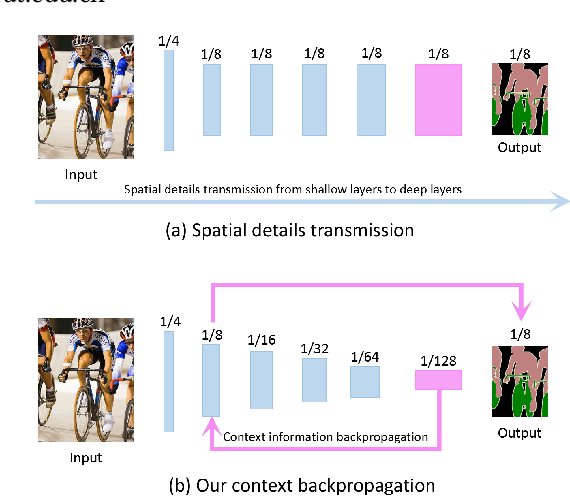
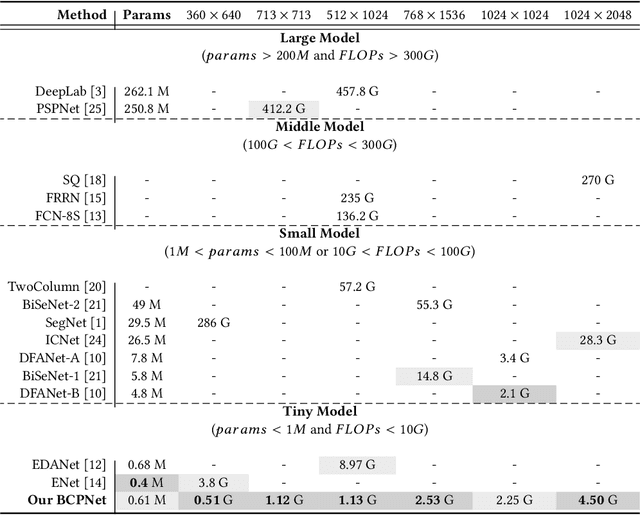
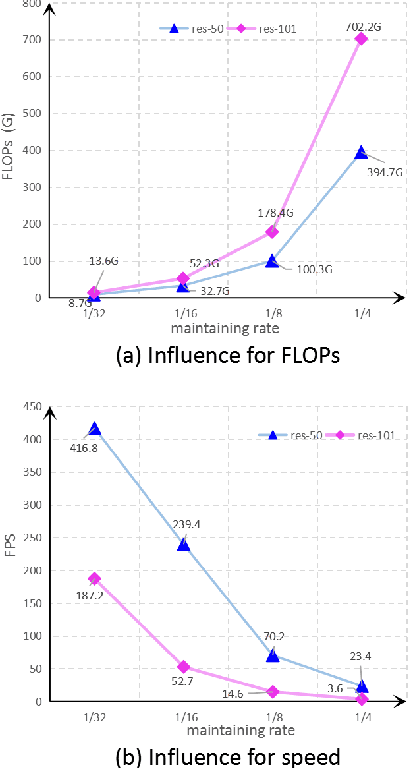

Spatial details and context correlations are two types of critical information for semantic segmentation. Generally, spatial details are most likely existed in shallow layers, but context correlations are most likely existed in deep layers. Aiming to use both of them, most of current methods choose forward transmitting the spatial details to deep layers. We find spatial details transmission is computationally expensives, and substantially lowers the model's execution speed. To address this problem, we propose a new Bi-direction Contexts Propagation Network (BCPNet), which performs semantic segmentation in real-time. Different from the previous methods, our BCPNet effectively back propagate the context information to the shallow layers, which is more computationally modesty. Extensive experiments validate that our BCPNet has achieved a good balance between accuracy and speed. For accuracy, our BCPNet has achieved 68.4 \% IoU on the Cityscapes test set and 67.8 % mIoU on the CamVid test set. For speed, our BCPNet can achieve 585.9 FPS and 1.7 ms runtime per an image.
Streaming convolutional neural networks for end-to-end learning with multi-megapixel images
Nov 11, 2019



Due to memory constraints on current hardware, most convolution neural networks (CNN) are trained on sub-megapixel images. For example, most popular datasets in computer vision contain images much less than a megapixel in size (0.09MP for ImageNet and 0.001MP for CIFAR-10). In some domains such as medical imaging, multi-megapixel images are needed to identify the presence of disease accurately. We propose a novel method to directly train convolutional neural networks using any input image size end-to-end. This method exploits the locality of most operations in modern convolutional neural networks by performing the forward and backward pass on smaller tiles of the image. In this work, we show a proof of concept using images of up to 66-megapixels (8192x8192), saving approximately 50GB of memory per image. Using two public challenge datasets, we demonstrate that CNNs can learn to extract relevant information from these large images and benefit from increasing resolution. We improved the area under the receiver-operating characteristic curve from 0.580 (4MP) to 0.706 (66MP) for metastasis detection in breast cancer (CAMELYON17). We also obtained a Spearman correlation metric approaching state-of-the-art performance on the TUPAC16 dataset, from 0.485 (1MP) to 0.570 (16MP). Code to reproduce a subset of the experiments is available at https://github.com/DIAGNijmegen/StreamingCNN.
Learning Memory-Efficient Stable Linear Dynamical Systems for Prediction and Control
Jun 06, 2020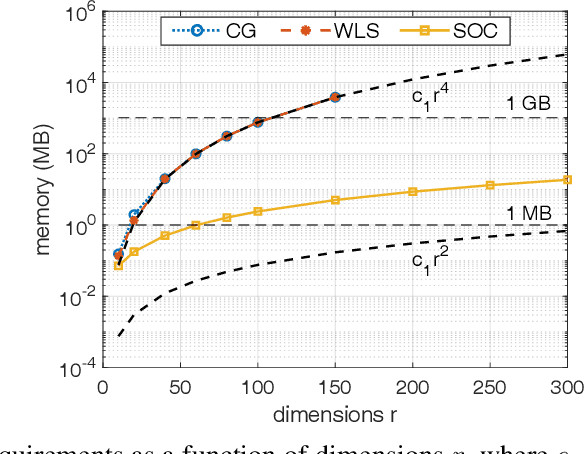
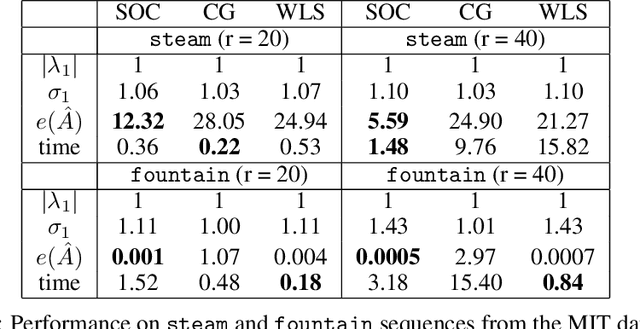
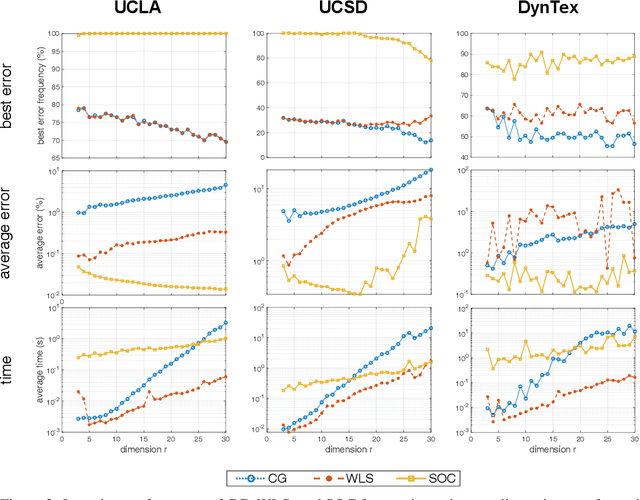

Learning a stable Linear Dynamical System (LDS) from data involves creating models that both minimize reconstruction error and enforce stability of the learned representation. We propose a novel algorithm for learning stable LDSs. Using a recent characterization of stable matrices, we present an optimization method that ensures stability at every step and iteratively improves the reconstruction error using gradient directions derived in this paper. When applied to LDSs with inputs, our approach---in contrast to current methods for learning stable LDSs---updates both the state and control matrices, expanding the solution space and allowing for models with lower reconstruction error. We apply our algorithm in simulations and experiments to a variety of problems, including learning dynamic textures from image sequences and controlling a robotic manipulator. Compared to existing approaches, our proposed method achieves an orders-of-magnitude improvement in reconstruction error and superior results in terms of control performance. In addition, it is provably more memory-efficient, with an O(n^2) space complexity compared to O(n^4) of competing alternatives, thus scaling to higher-dimensional systems when the other methods fail.
Train Like a (Var)Pro: Efficient Training of Neural Networks with Variable Projection
Jul 26, 2020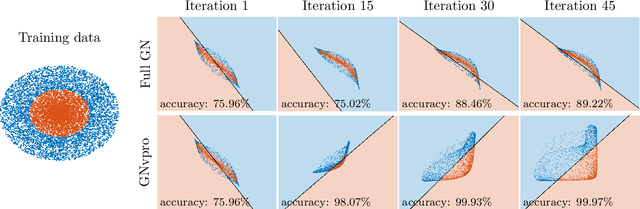
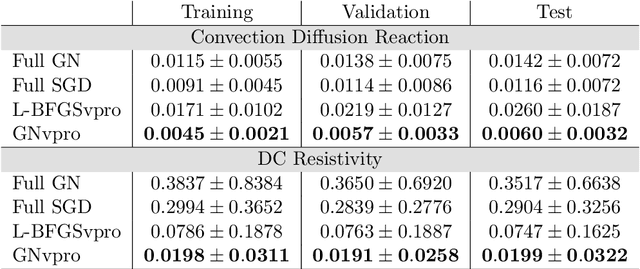
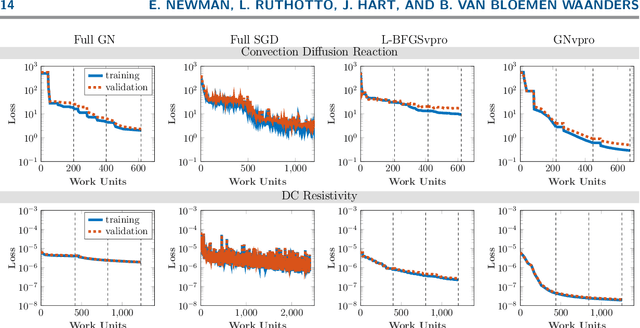
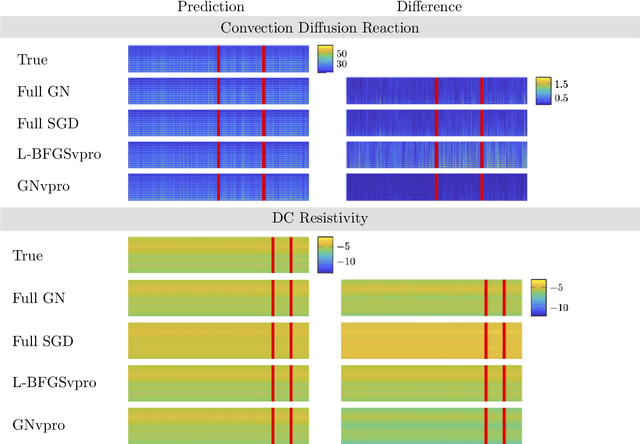
Deep neural networks (DNNs) have achieved state-of-the-art performance across a variety of traditional machine learning tasks, e.g., speech recognition, image classification, and segmentation. The ability of DNNs to efficiently approximate high-dimensional functions has also motivated their use in scientific applications, e.g., to solve partial differential equations (PDE) and to generate surrogate models. In this paper, we consider the supervised training of DNNs, which arises in many of the above applications. We focus on the central problem of optimizing the weights of the given DNN such that it accurately approximates the relation between observed input and target data. Devising effective solvers for this optimization problem is notoriously challenging due to the large number of weights, non-convexity, data-sparsity, and non-trivial choice of hyperparameters. To solve the optimization problem more efficiently, we propose the use of variable projection (VarPro), a method originally designed for separable nonlinear least-squares problems. Our main contribution is the Gauss-Newton VarPro method (GNvpro) that extends the reach of the VarPro idea to non-quadratic objective functions, most notably, cross-entropy loss functions arising in classification. These extensions make GNvpro applicable to all training problems that involve a DNN whose last layer is an affine mapping, which is common in many state-of-the-art architectures. In numerical experiments from classification and surrogate modeling, GNvpro not only solves the optimization problem more efficiently but also yields DNNs that generalize better than commonly-used optimization schemes.
RankPose: Learning Generalised Feature with Rank Supervision for Head Pose Estimation
May 22, 2020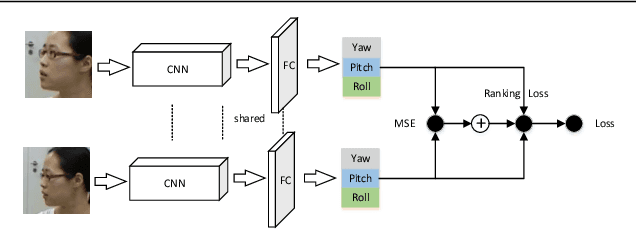
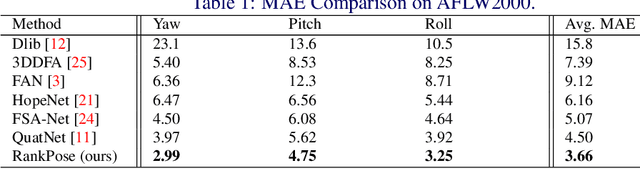
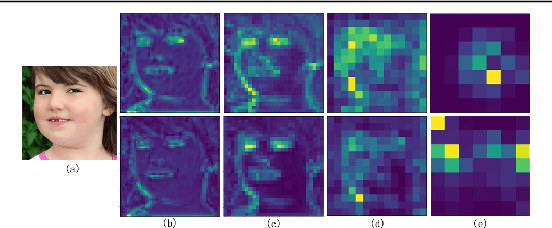

We address the challenging problem of RGB image-based head pose estimation. We first reformulate head pose representation learning to constrain it to a bounded space. Head pose represented as vector projection or vector angles shows helpful to improving performance. Further, a ranking loss combined with MSE regression loss is proposed. The ranking loss supervises a neural network with paired samples of the same person and penalises incorrect ordering of pose prediction. Analysis on this new loss function suggests it contributes to a better local feature extractor, where features are generalised to Abstract Landmarks which are pose-related features instead of pose-irrelevant information such as identity, age, and lighting. Extensive experiments show that our method significantly outperforms the current state-of-the-art schemes on public datasets: AFLW2000 and BIWI. Our model achieves significant improvements over previous SOTA MAE on AFLW2000 and BIWI from 4.50 to 3.66 and from 4.0 to 3.71 respectively. Source code will be made available at: https://github.com/seathiefwang/RankHeadPose.
Neural Networks-based Regularization of Large-Scale Inverse Problems in Medical Imaging
Dec 19, 2019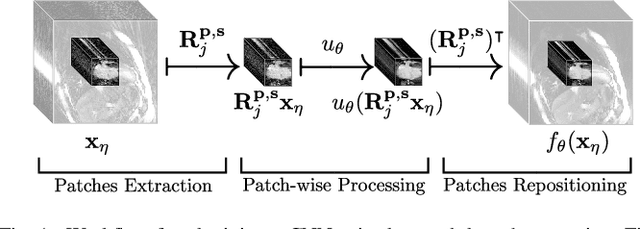
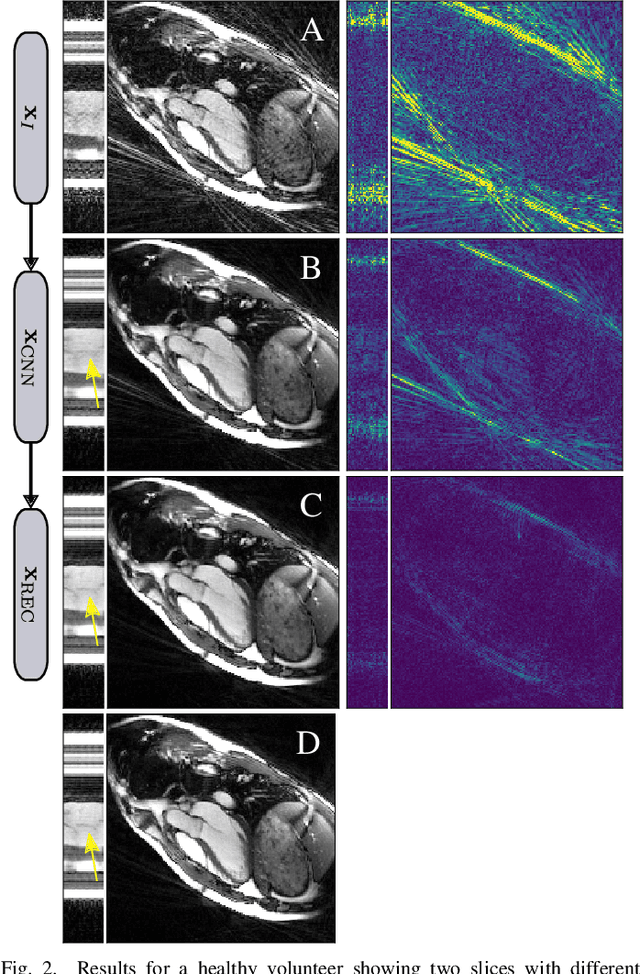
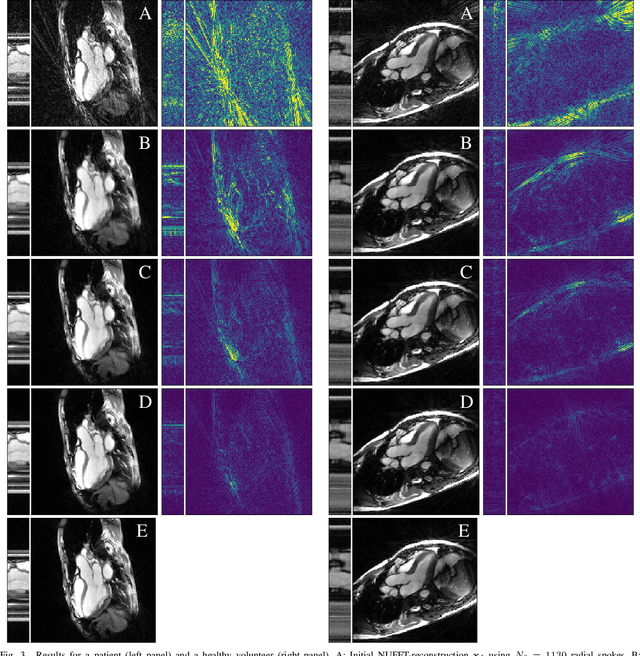
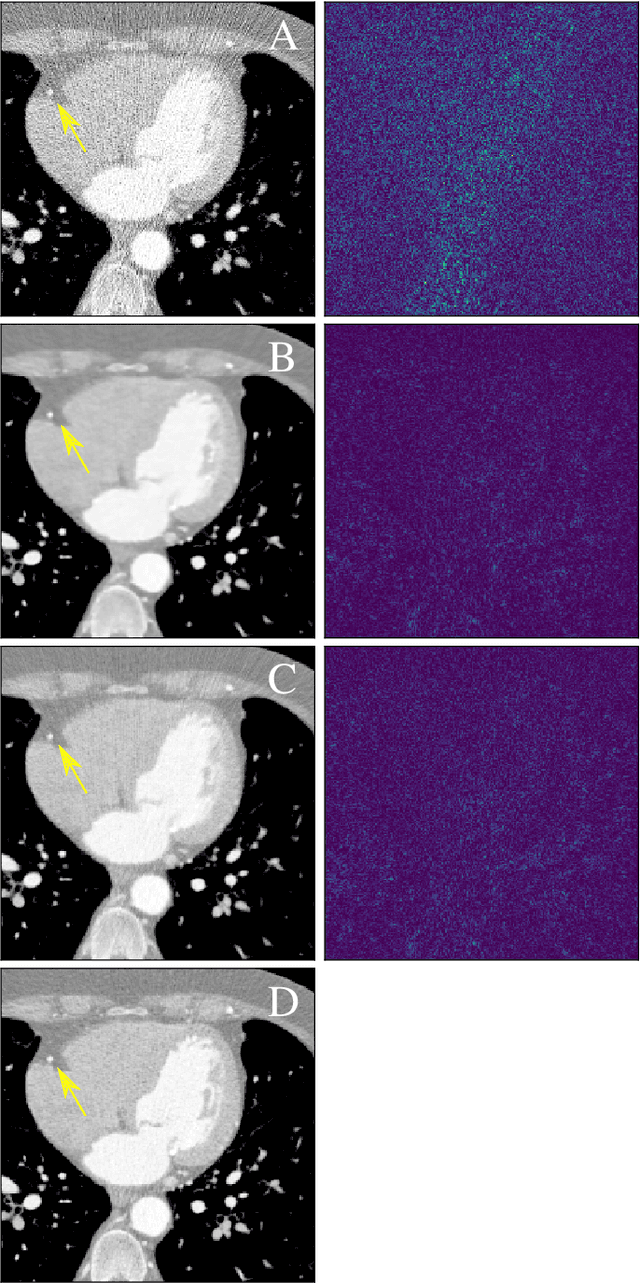
In this paper we present a generalized Deep Learning-based approach to solve ill-posed large-scale inverse problems occurring in medical imaging. Recently, Deep Learning methods using iterative neural networks and cascaded neural networks have been reported to achieve excellent image quality for the task of image reconstruction in different imaging modalities. However, the fact that these approaches employ the forward and adjoint operators repeatedly in the network architecture requires the network to process the whole images or volumes at once, which for some applications is computationally infeasible. In this work, we follow a different reconstruction strategy by decoupling the regularization of the solution from ensuring consistency with the measured data. The regularization is given in the form of an image prior obtained by the output of a previously trained neural network which is used in a Tikhonov regularization framework. By doing so, more complex and sophisticated network architectures can be used for the removal of the artefacts or noise than it is usually the case in iterative networks. Due to the large scale of the considered problems and the resulting computational complexity of the employed networks, the priors are obtained by processing the images or volumes as patches or slices. We evaluated the method for the cases of 3D cone-beam low dose CT and undersampled 2D radial cine MRI and compared it to a total variation-minimization-based reconstruction algorithm as well as to a method with regularization based on learned overcomplete dictionaries. The proposed method outperformed all the reported methods with respect to all chosen quantitative measures and further accelerates the regularization step in the reconstruction by several orders of magnitude.
Synthetic Image Augmentation for Improved Classification using Generative Adversarial Networks
Jul 31, 2019
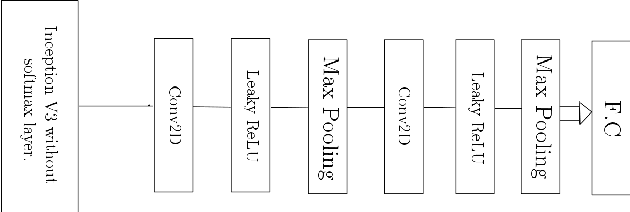
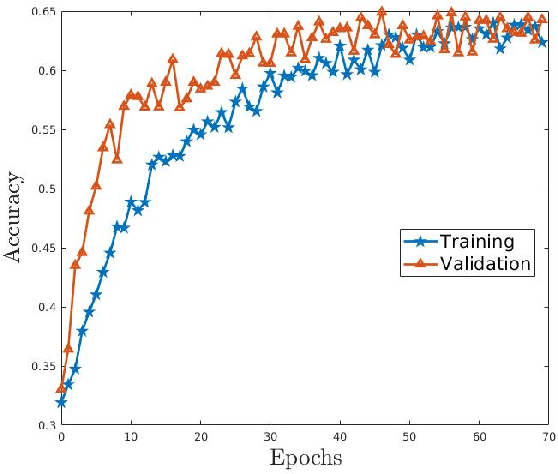
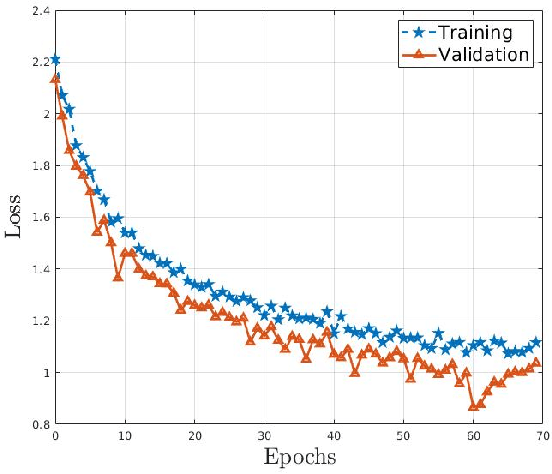
Object detection and recognition has been an ongoing research topic for a long time in the field of computer vision. Even in robotics, detecting the state of an object by a robot still remains a challenging task. Also, collecting data for each possible state is also not feasible. In this literature, we use a deep convolutional neural network with SVM as a classifier to help with recognizing the state of a cooking object. We also study how a generative adversarial network can be used for synthetic data augmentation and improving the classification accuracy. The main motivation behind this work is to estimate how well a robot could recognize the current state of an object
Deep Polynomial Neural Networks
Jun 20, 2020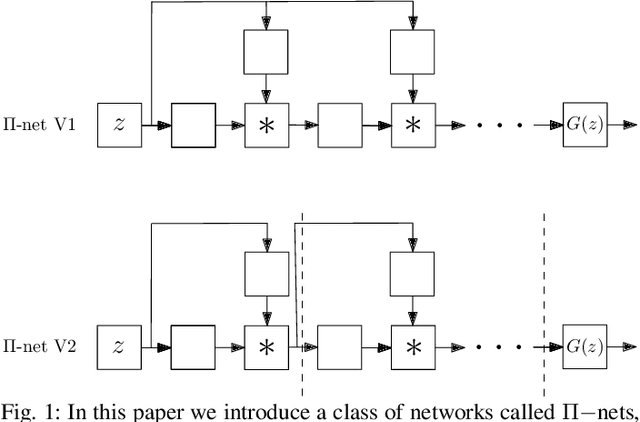

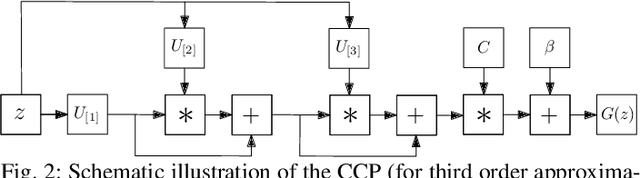
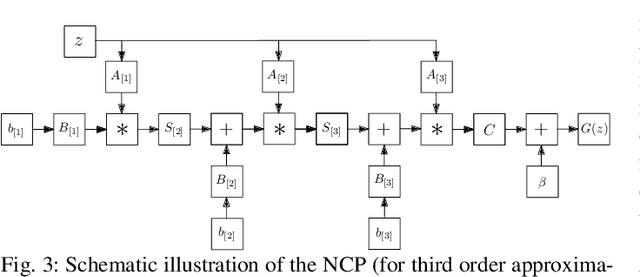
Deep Convolutional Neural Networks (DCNNs) are currently the method of choice both for generative, as well as for discriminative learning in computer vision and machine learning. The success of DCNNs can be attributed to the careful selection of their building blocks (e.g., residual blocks, rectifiers, sophisticated normalization schemes, to mention but a few). In this paper, we propose $\Pi$-Nets, a new class of DCNNs. $\Pi$-Nets are polynomial neural networks, i.e., the output is a high-order polynomial of the input. The unknown parameters, which are naturally represented by high-order tensors, are estimated through a collective tensor factorization with factors sharing. We introduce three tensor decompositions that significantly reduce the number of parameters and show how they can be efficiently implemented by hierarchical neural networks. We empirically demonstrate that $\Pi$-Nets are very expressive and they even produce good results without the use of non-linear activation functions in a large battery of tasks and signals, i.e., images, graphs, and audio. When used in conjunction with activation functions, $\Pi$-Nets produce state-of-the-art results in three challenging tasks, i.e. image generation, face verification and 3D mesh representation learning.