 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Predicting the Politics of an Image Using Webly Supervised Data
Oct 31, 2019
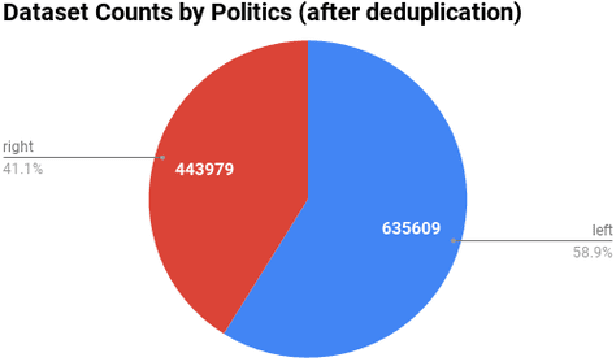

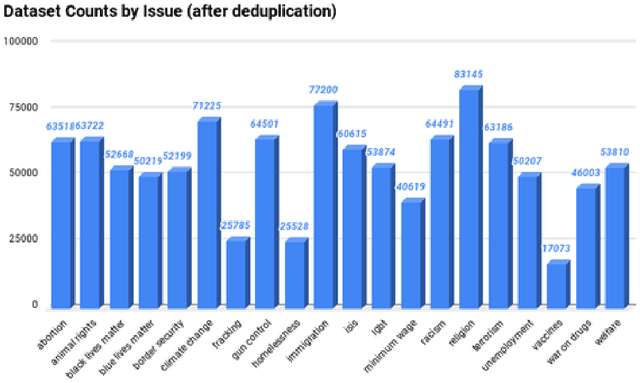

The news media shape public opinion, and often, the visual bias they contain is evident for human observers. This bias can be inferred from how different media sources portray different subjects or topics. In this paper, we model visual political bias in contemporary media sources at scale, using webly supervised data. We collect a dataset of over one million unique images and associated news articles from left- and right-leaning news sources, and develop a method to predict the image's political leaning. This problem is particularly challenging because of the enormous intra-class visual and semantic diversity of our data. We propose a two-stage method to tackle this problem. In the first stage, the model is forced to learn relevant visual concepts that, when joined with document embeddings computed from articles paired with the images, enable the model to predict bias. In the second stage, we remove the requirement of the text domain and train a visual classifier from the features of the former model. We show this two-stage approach facilitates learning and outperforms several strong baselines. We also present extensive qualitative results demonstrating the nuances of the data.
A Novel Feature Descriptor for Image Retrieval by Combining Modified Color Histogram and Diagonally Symmetric Co-occurrence Texture Pattern
Jan 03, 2018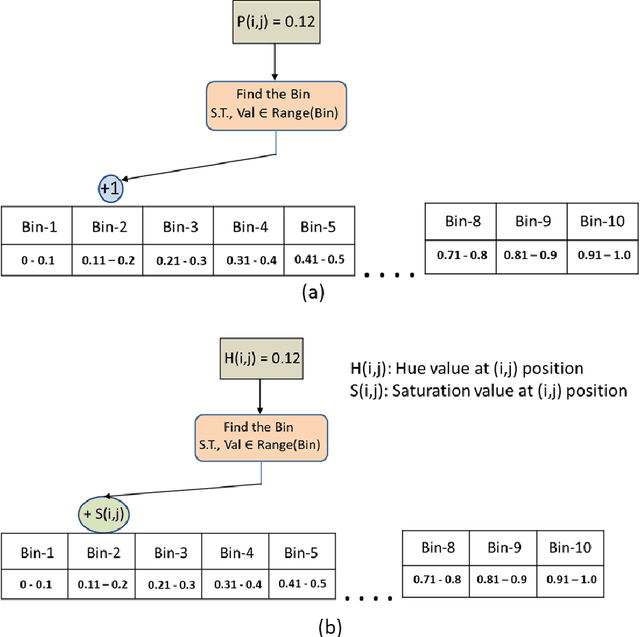

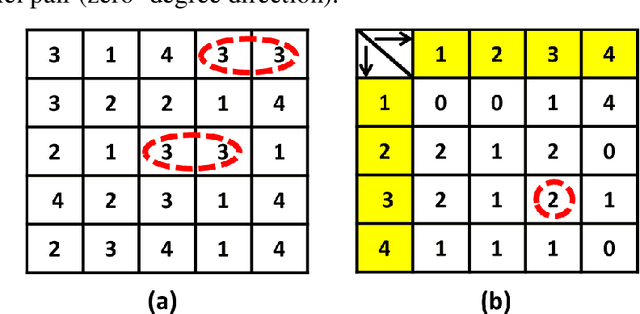
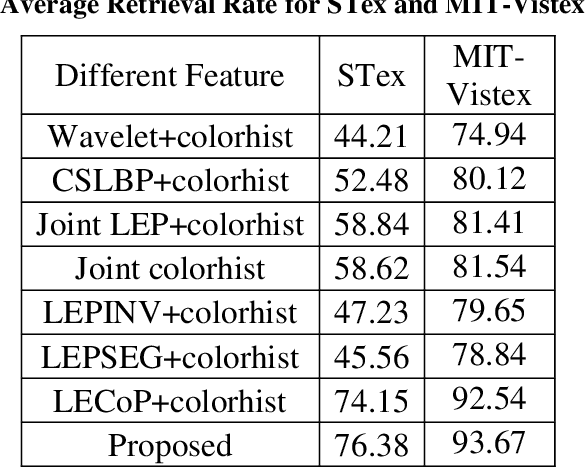
In this paper, we have proposed a novel feature descriptors combining color and texture information collectively. In our proposed color descriptor component, the inter-channel relationship between Hue (H) and Saturation (S) channels in the HSV color space has been explored which was not done earlier. We have quantized the H channel into a number of bins and performed the voting with saturation values and vice versa by following a principle similar to that of the HOG descriptor, where orientation of the gradient is quantized into a certain number of bins and voting is done with gradient magnitude. This helps us to study the nature of variation of saturation with variation in Hue and nature of variation of Hue with the variation in saturation. The texture component of our descriptor considers the co-occurrence relationship between the pixels symmetric about both the diagonals of a 3x3 window. Our work is inspired from the work done by Dubey et al.[1]. These two components, viz. color and texture information individually perform better than existing texture and color descriptors. Moreover, when concatenated the proposed descriptors provide significant improvement over existing descriptors for content base color image retrieval. The proposed descriptor has been tested for image retrieval on five databases, including texture image databases - MIT VisTex database and Salzburg texture database and natural scene databases Corel 1K, Corel 5K and Corel 10K. The precision and recall values experimented on these databases are compared with some state-of-art local patterns. The proposed method provided satisfactory results from the experiments.
Functional Space Variational Inference for Uncertainty Estimation in Computer Aided Diagnosis
May 24, 2020
Deep neural networks have revolutionized medical image analysis and disease diagnosis. Despite their impressive performance, it is difficult to generate well-calibrated probabilistic outputs for such networks, which makes them uninterpretable black boxes. Bayesian neural networks provide a principled approach for modelling uncertainty and increasing patient safety, but they have a large computational overhead and provide limited improvement in calibration. In this work, by taking skin lesion classification as an example task, we show that by shifting Bayesian inference to the functional space we can craft meaningful priors that give better calibrated uncertainty estimates at a much lower computational cost.
* Meaningful priors on the functional space rather than the weight space, result in well calibrated uncertainty estimates
The OARF Benchmark Suite: Characterization and Implications for Federated Learning Systems
Jun 14, 2020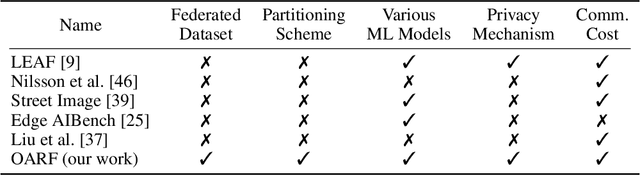
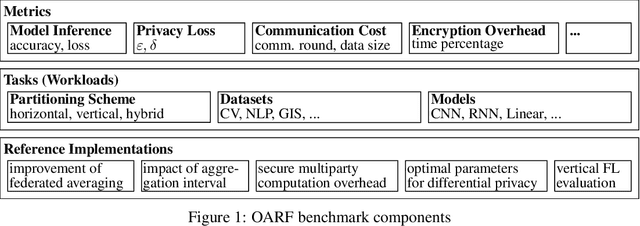
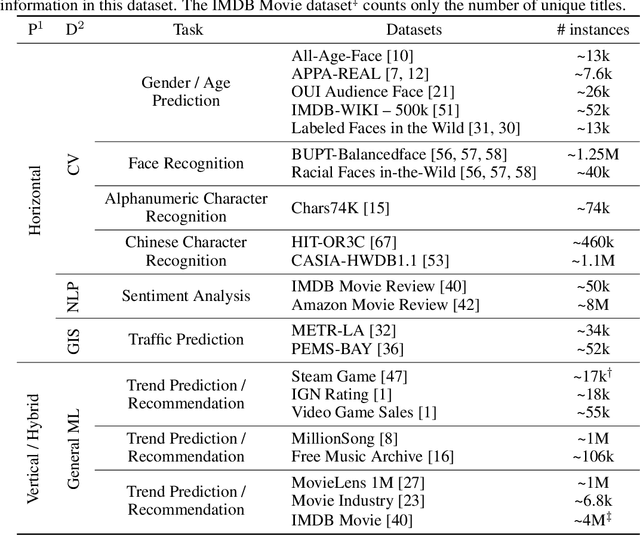
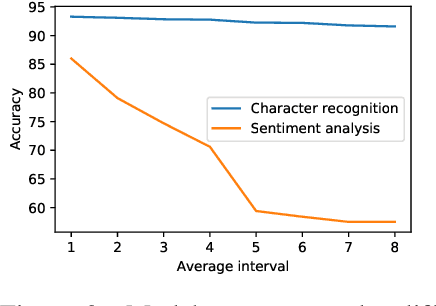
This paper presents and characterizes an Open Application Repository for Federated Learning (OARF), a benchmark suite for federated machine learning systems. Previously available benchmarks for federated learning have focused mainly on synthetic datasets and use a very limited number of applications. OARF includes different data partitioning methods (horizontal, vertical and hybrid) as well as emerging applications in image, text and structured data, which represent different scenarios in federated learning. Our characterization shows that the benchmark suite is diverse in data size, distribution, feature distribution and learning task complexity. We have developed reference implementations, and evaluated the important aspects of federated learning, including model accuracy, communication cost, differential privacy, secure multiparty computation and vertical federated learning.
Decomposed Generation Networks with Structure Prediction for Recipe Generation from Food Images
Jul 27, 2020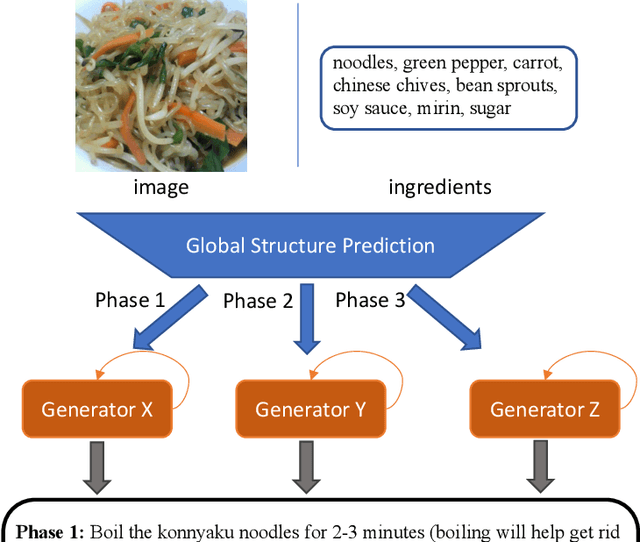
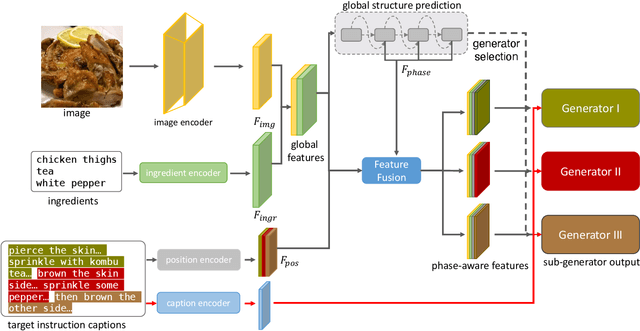
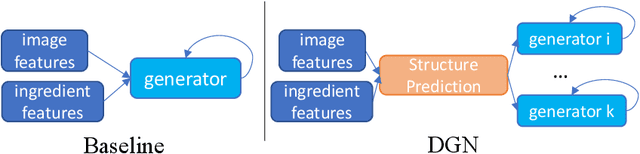
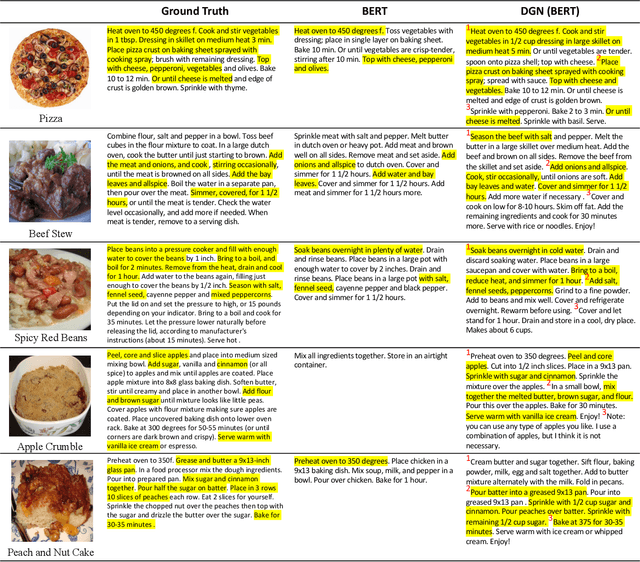
Recipe generation from food images and ingredients is a challenging task, which requires the interpretation of the information from another modality. Different from the image captioning task, where the captions usually have one sentence, cooking instructions contain multiple sentences and have obvious structures. To help the model capture the recipe structure and avoid missing some cooking details, we propose a novel framework: Decomposed Generation Networks (DGN) with structure prediction, to get more structured and complete recipe generation outputs. To be specific, we split each cooking instruction into several phases, and assign different sub-generators to each phase. Our approach includes two novel ideas: (i) learning the recipe structures with the global structure prediction component and (ii) producing recipe phases in the sub-generator output component based on the predicted structure. Extensive experiments on the challenging large-scale Recipe1M dataset validate the effectiveness of our proposed model DGN, which improves the performance over the state-of-the-art results.
Using multiple sensors for autonomous mobile robot navigation
May 13, 2020This paper presents the use of multi-sensor measurement system to guide autonomous mobile robot in the house. The system allows the 3D image acquisition to global mapping, and algorithms to reduce the dimensionality of images to 2D global map navigation, trajectory design approach using the Lyapunov function method and avoid obstacles by the potential energy can also be presented. Also, sensor integrated method based on extended Kalman filter allows us to identify the exact location and orientation of the robot in the presence of interference from the environment.
PDQ & TMK + PDQF -- A Test Drive of Facebook's Perceptual Hashing Algorithms
Dec 16, 2019

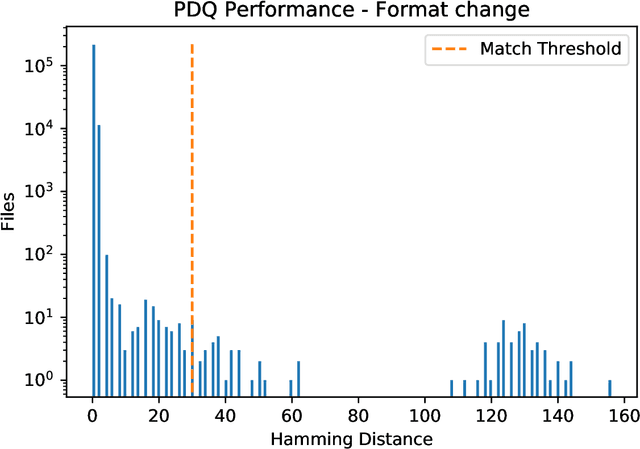
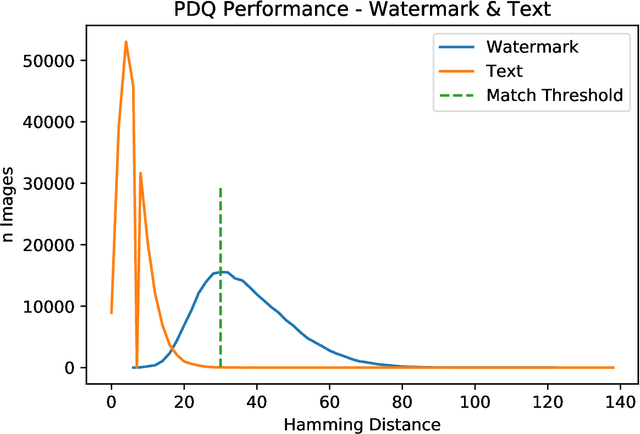
Efficient and reliable automated detection of modified image and multimedia files has long been a challenge for law enforcement, compounded by the harm caused by repeated exposure to psychologically harmful materials. In August 2019 Facebook open-sourced their PDQ and TMK + PDQF algorithms for image and video similarity measurement, respectively. In this report, we review the algorithms' performance on detecting commonly encountered transformations on real-world case data, sourced from contemporary investigations. We also provide a reference implementation to demonstrate the potential application and integration of such algorithms within existing law enforcement systems.
A Deep Convolutional Network for Seismic Shot-Gather Image Quality Classification
Dec 03, 2019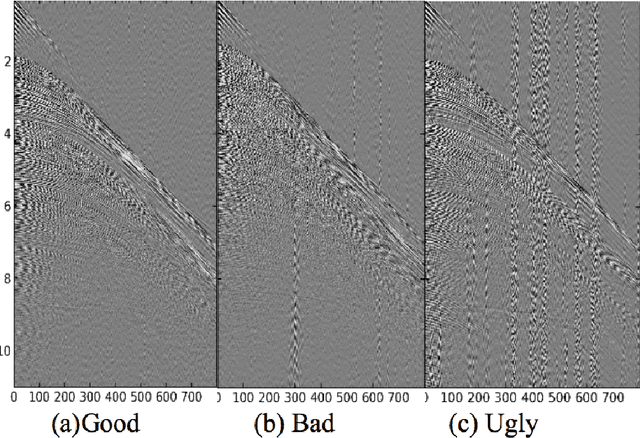
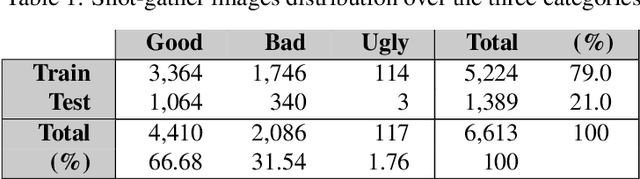

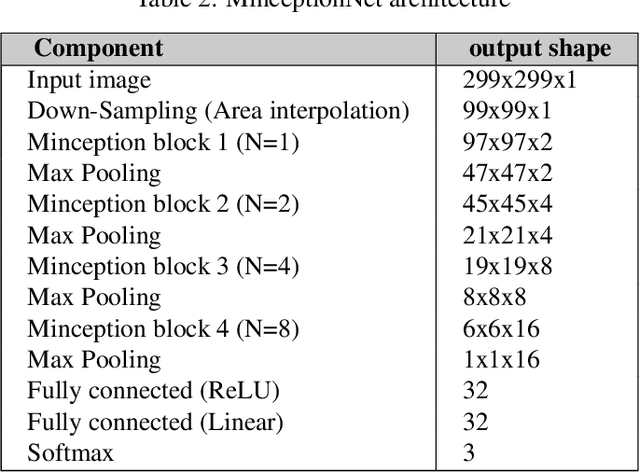
Deep Learning-based models such as Convolutional Neural Networks, have led to significant advancements in several areas of computing applications. Seismogram quality assurance is a relevant Geophysics task, since in the early stages of seismic processing, we are required to identify and fix noisy sail lines. In this work, we introduce a real-world seismogram quality classification dataset based on 6,613 examples, manually labeled by human experts as good, bad or ugly, according to their noise intensity. This dataset is used to train a CNN classifier for seismic shot-gathers quality prediction. In our empirical evaluation, we observe an F1-score of 93.56% in the test set.
Deep Sketch-guided Cartoon Video Synthesis
Aug 10, 2020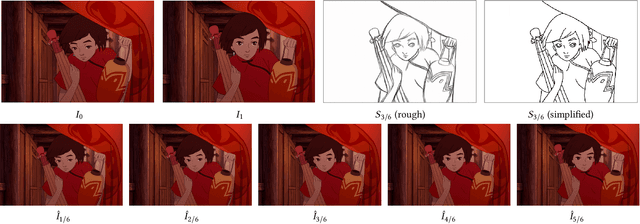
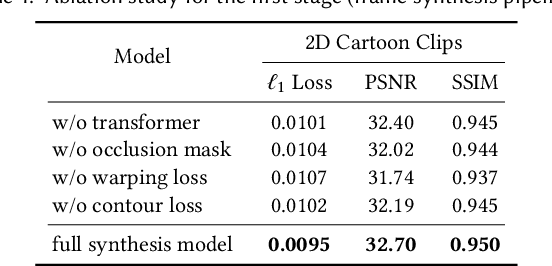

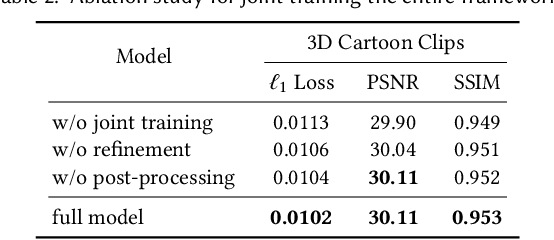
We propose a novel framework to produce cartoon videos by fetching the color information from two input keyframes while following the animated motion guided by a user sketch. The key idea of the proposed approach is to estimate the dense cross-domain correspondence between the sketch and cartoon video frames, following by a blending module with occlusion estimation to synthesize the middle frame guided by the sketch. After that, the inputs and the synthetic frame equipped with established correspondence are fed into an arbitrary-time frame interpolation pipeline to generate and refine additional inbetween frames. Finally, a video post-processing approach is used to further improve the result. Compared to common frame interpolation methods, our approach can address frames with relatively large motion and also has the flexibility to enable users to control the generated video sequences by editing the sketch guidance. By explicitly considering the correspondence between frames and the sketch, our methods can achieve high-quality synthetic results compared with image synthesis methods. Our results show that our system generalizes well to different movie frames, achieving better results than existing solutions.
Group-Level Emotion Recognition Using a Unimodal Privacy-Safe Non-Individual Approach
Sep 15, 2020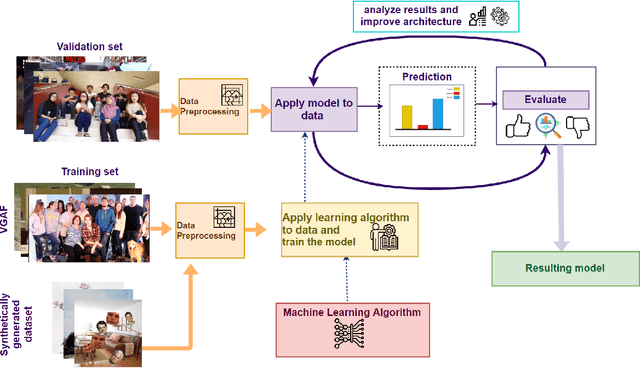
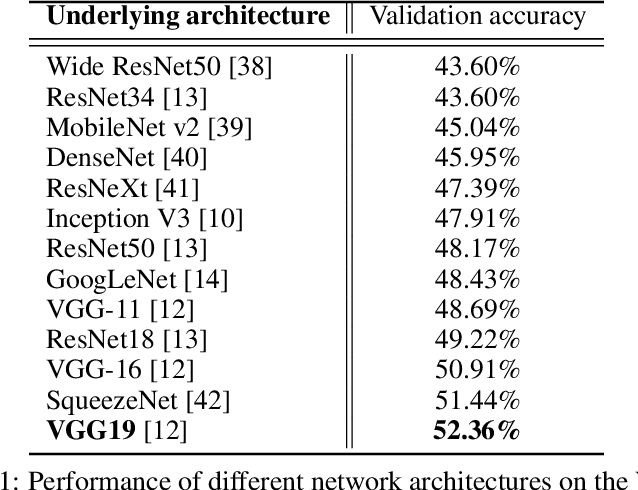

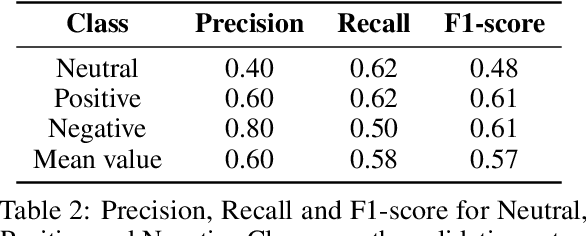
This article presents our unimodal privacy-safe and non-individual proposal for the audio-video group emotion recognition subtask at the Emotion Recognition in the Wild (EmotiW) Challenge 2020 1. This sub challenge aims to classify in the wild videos into three categories: Positive, Neutral and Negative. Recent deep learning models have shown tremendous advances in analyzing interactions between people, predicting human behavior and affective evaluation. Nonetheless, their performance comes from individual-based analysis, which means summing up and averaging scores from individual detections, which inevitably leads to some privacy issues. In this research, we investigated a frugal approach towards a model able to capture the global moods from the whole image without using face or pose detection, or any individual-based feature as input. The proposed methodology mixes state-of-the-art and dedicated synthetic corpora as training sources. With an in-depth exploration of neural network architectures for group-level emotion recognition, we built a VGG-based model achieving 59.13% accuracy on the VGAF test set (eleventh place of the challenge). Given that the analysis is unimodal based only on global features and that the performance is evaluated on a real-world dataset, these results are promising and let us envision extending this model to multimodality for classroom ambiance evaluation, our final target application.