 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup-Level Emotion Recognition Using a Unimodal Privacy-Safe Non-Individual Approach
Paper and Code
Sep 15, 2020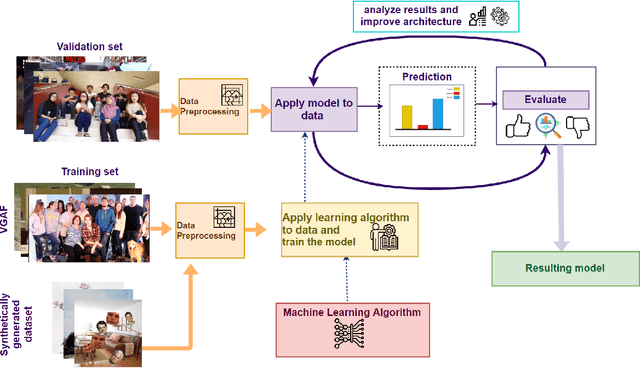
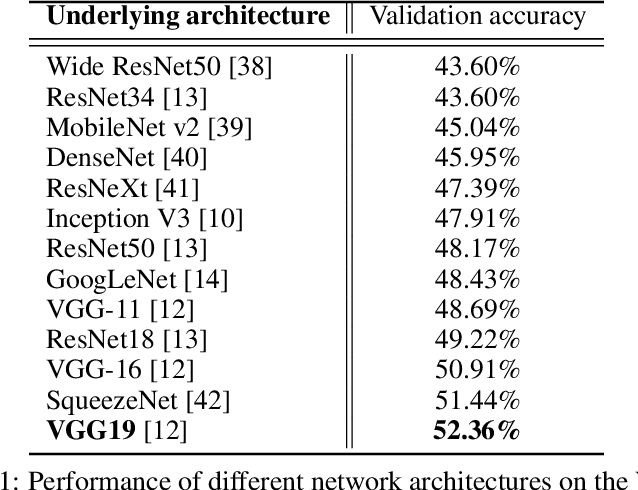

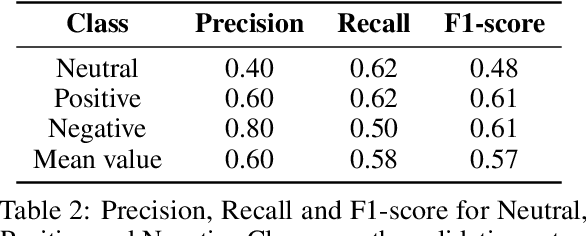
This article presents our unimodal privacy-safe and non-individual proposal for the audio-video group emotion recognition subtask at the Emotion Recognition in the Wild (EmotiW) Challenge 2020 1. This sub challenge aims to classify in the wild videos into three categories: Positive, Neutral and Negative. Recent deep learning models have shown tremendous advances in analyzing interactions between people, predicting human behavior and affective evaluation. Nonetheless, their performance comes from individual-based analysis, which means summing up and averaging scores from individual detections, which inevitably leads to some privacy issues. In this research, we investigated a frugal approach towards a model able to capture the global moods from the whole image without using face or pose detection, or any individual-based feature as input. The proposed methodology mixes state-of-the-art and dedicated synthetic corpora as training sources. With an in-depth exploration of neural network architectures for group-level emotion recognition, we built a VGG-based model achieving 59.13% accuracy on the VGAF test set (eleventh place of the challenge). Given that the analysis is unimodal based only on global features and that the performance is evaluated on a real-world dataset, these results are promising and let us envision extending this model to multimodality for classroom ambiance evaluation, our final target application.