 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Detection of Life-Threatening Texts
Jun 12, 2025Detecting life-threatening language is essential for safeguarding individuals in distress, promoting mental health and well-being, and preventing potential harm and loss of life. This paper presents an effective approach to identifying life-threatening texts using large language models (LLMs) and compares them with traditional methods such as bag of words, word embedding, topic modeling, and Bidirectional Encoder Representations from Transformers. We fine-tune three open-source LLMs including Gemma, Mistral, and Llama-2 using their 7B parameter variants on different datasets, which are constructed with class balance, imbalance, and extreme imbalance scenarios. Experimental results demonstrate a strong performance of LLMs against traditional methods. More specifically, Mistral and Llama-2 models are top performers in both balanced and imbalanced data scenarios while Gemma is slightly behind. We employ the upsampling technique to deal with the imbalanced data scenarios and demonstrate that while this method benefits traditional approaches, it does not have as much impact on LLMs. This study demonstrates a great potential of LLMs for real-world life-threatening language detection problems.
Sensitive Image Classification by Vision Transformers
Dec 21, 2024When it comes to classifying child sexual abuse images, managing similar inter-class correlations and diverse intra-class correlations poses a significant challenge. Vision transformer models, unlike conventional deep convolutional network models, leverage a self-attention mechanism to capture global interactions among contextual local elements. This allows them to navigate through image patches effectively, avoiding incorrect correlations and reducing ambiguity in attention maps, thus proving their efficacy in computer vision tasks. Rather than directly analyzing child sexual abuse data, we constructed two datasets: one comprising clean and pornographic images and another with three classes, which additionally include images indicative of pornography, sourced from Reddit and Google Open Images data. In our experiments, we also employ an adult content image benchmark dataset. These datasets served as a basis for assessing the performance of vision transformer models in pornographic image classification. In our study, we conducted a comparative analysis between various popular vision transformer models and traditional pre-trained ResNet models. Furthermore, we compared them with established methods for sensitive image detection such as attention and metric learning based CNN and Bumble. The findings demonstrated that vision transformer networks surpassed the benchmark pre-trained models, showcasing their superior classification and detection capabilities in this task.
Object Detection Approaches to Identifying Hand Images with High Forensic Values
Dec 21, 2024Forensic science plays a crucial role in legal investigations, and the use of advanced technologies, such as object detection based on machine learning methods, can enhance the efficiency and accuracy of forensic analysis. Human hands are unique and can leave distinct patterns, marks, or prints that can be utilized for forensic examinations. This paper compares various machine learning approaches to hand detection and presents the application results of employing the best-performing model to identify images of significant importance in forensic contexts. We fine-tune YOLOv8 and vision transformer-based object detection models on four hand image datasets, including the 11k hands dataset with our own bounding boxes annotated by a semi-automatic approach. Two YOLOv8 variants, i.e., YOLOv8 nano (YOLOv8n) and YOLOv8 extra-large (YOLOv8x), and two vision transformer variants, i.e., DEtection TRansformer (DETR) and Detection Transformers with Assignment (DETA), are employed for the experiments. Experimental results demonstrate that the YOLOv8 models outperform DETR and DETA on all datasets. The experiments also show that YOLOv8 approaches result in superior performance compared with existing hand detection methods, which were based on YOLOv3 and YOLOv4 models. Applications of our fine-tuned YOLOv8 models for identifying hand images (or frames in a video) with high forensic values produce excellent results, significantly reducing the time required by forensic experts. This implies that our approaches can be implemented effectively for real-world applications in forensics or related fields.
Adaptive Knowledge Distillation for Classification of Hand Images using Explainable Vision Transformers
Aug 20, 2024Assessing the forensic value of hand images involves the use of unique features and patterns present in an individual's hand. The human hand has distinct characteristics, such as the pattern of veins, fingerprints, and the geometry of the hand itself. This paper investigates the use of vision transformers (ViTs) for classification of hand images. We use explainability tools to explore the internal representations of ViTs and assess their impact on the model outputs. Utilizing the internal understanding of ViTs, we introduce distillation methods that allow a student model to adaptively extract knowledge from a teacher model while learning on data of a different domain to prevent catastrophic forgetting. Two publicly available hand image datasets are used to conduct a series of experiments to evaluate performance of the ViTs and our proposed adaptive distillation methods. The experimental results demonstrate that ViT models significantly outperform traditional machine learning methods and the internal states of ViTs are useful for explaining the model outputs in the classification task. By averting catastrophic forgetting, our distillation methods achieve excellent performance on data from both source and target domains, particularly when these two domains exhibit significant dissimilarity. The proposed approaches therefore can be developed and implemented effectively for real-world applications such as access control, identity verification, and authentication systems.
Fine-Tuning Llama 2 Large Language Models for Detecting Online Sexual Predatory Chats and Abusive Texts
Aug 28, 2023



Detecting online sexual predatory behaviours and abusive language on social media platforms has become a critical area of research due to the growing concerns about online safety, especially for vulnerable populations such as children and adolescents. Researchers have been exploring various techniques and approaches to develop effective detection systems that can identify and mitigate these risks. Recent development of large language models (LLMs) has opened a new opportunity to address this problem more effectively. This paper proposes an approach to detection of online sexual predatory chats and abusive language using the open-source pretrained Llama 2 7B-parameter model, recently released by Meta GenAI. We fine-tune the LLM using datasets with different sizes, imbalance degrees, and languages (i.e., English, Roman Urdu and Urdu). Based on the power of LLMs, our approach is generic and automated without a manual search for a synergy between feature extraction and classifier design steps like conventional methods in this domain. Experimental results show a strong performance of the proposed approach, which performs proficiently and consistently across three distinct datasets with five sets of experiments. This study's outcomes indicate that the proposed method can be implemented in real-world applications (even with non-English languages) for flagging sexual predators, offensive or toxic content, hate speech, and discriminatory language in online discussions and comments to maintain respectful internet or digital communities. Furthermore, it can be employed for solving text classification problems with other potential applications such as sentiment analysis, spam and phishing detection, sorting legal documents, fake news detection, language identification, user intent recognition, text-based product categorization, medical record analysis, and resume screening.
The Data Airlock: infrastructure for restricted data informatics
Mar 17, 2022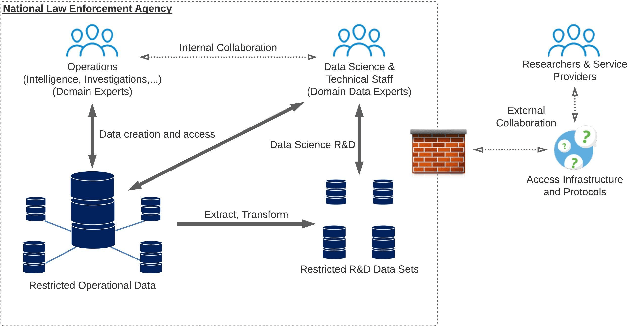
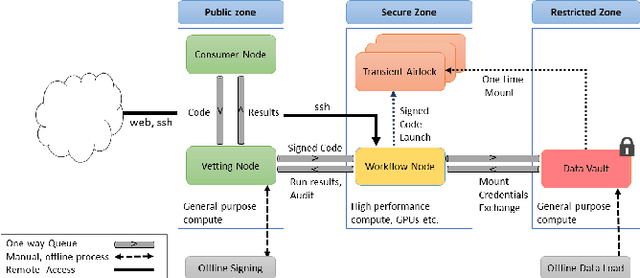
Data science collaboration is problematic when access to operational data or models from outside the data-holding organisation is prohibited, for a variety of legal, security, ethical, or practical reasons. There are significant data privacy challenges when performing collaborative data science work against such restricted data. In this paper we describe a range of causes and risks associated with restricted data along with the social, environmental, data, and cryptographic measures that may be used to mitigate such issues. We then show how these are generally inadequate for restricted data contexts and introduce the 'Data Airlock' - secure infrastructure that facilitates 'eyes-off' data science workloads. After describing our use-case we detail the architecture and implementation of a first, single-organisation version of the Data Airlock infrastructure. We conclude with outcomes and learning from this implementation, and outline requirements for a second, federated version.
PDQ & TMK + PDQF -- A Test Drive of Facebook's Perceptual Hashing Algorithms
Dec 16, 2019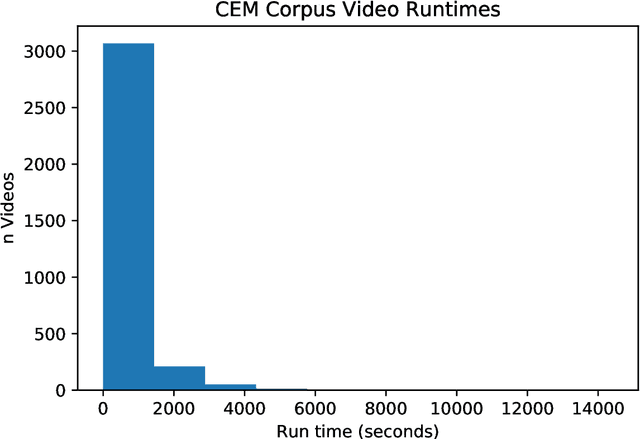

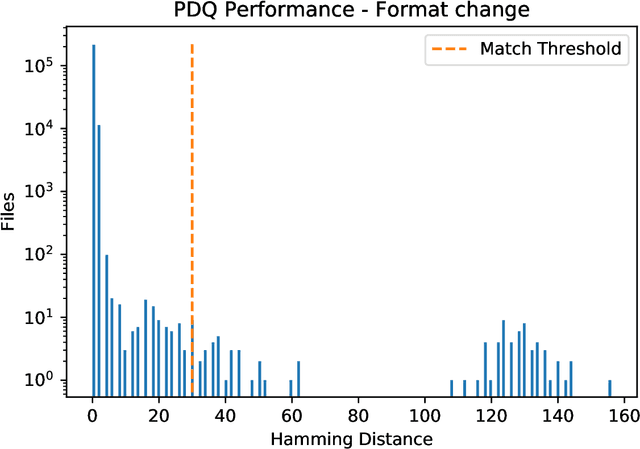
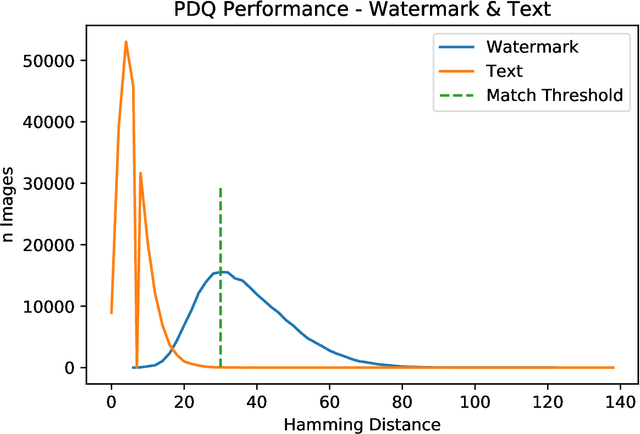
Efficient and reliable automated detection of modified image and multimedia files has long been a challenge for law enforcement, compounded by the harm caused by repeated exposure to psychologically harmful materials. In August 2019 Facebook open-sourced their PDQ and TMK + PDQF algorithms for image and video similarity measurement, respectively. In this report, we review the algorithms' performance on detecting commonly encountered transformations on real-world case data, sourced from contemporary investigations. We also provide a reference implementation to demonstrate the potential application and integration of such algorithms within existing law enforcement systems.