 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
k-Modulus Method for Image Transformation
Apr 24, 2013

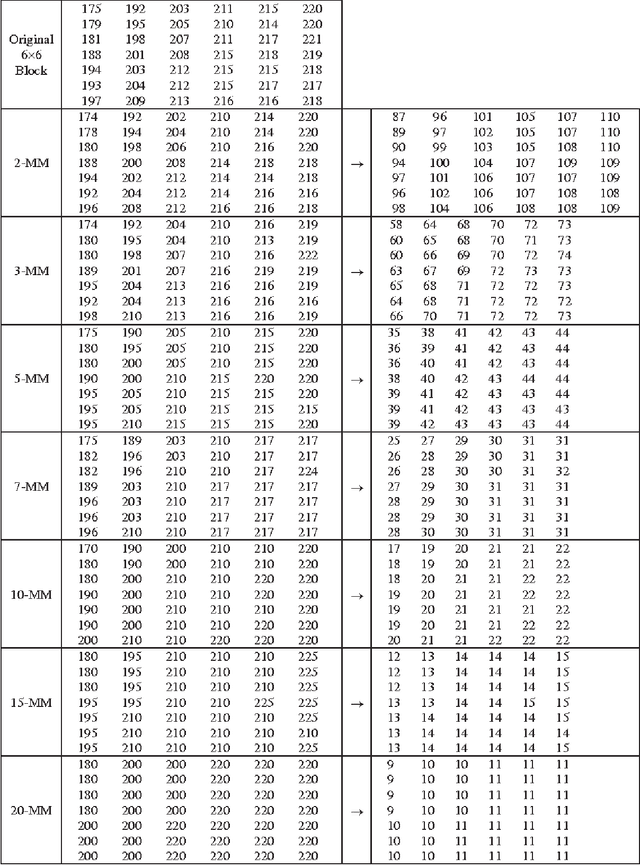

In this paper, we propose a new algorithm to make a novel spatial image transformation. The proposed approach aims to reduce the bit depth used for image storage. The basic technique for the proposed transformation is based of the modulus operator. The goal is to transform the whole image into multiples of predefined integer. The division of the whole image by that integer will guarantee that the new image surely less in size from the original image. The k-Modulus Method could not be used as a stand alone transform for image compression because of its high compression ratio. It could be used as a scheme embedded in other image processing fields especially compression. According to its high PSNR value, it could be amalgamated with other methods to facilitate the redundancy criterion.
* 5 pages, 2 tables, 6 figures
Interlocking Backpropagation: Improving depthwise model-parallelism
Oct 08, 2020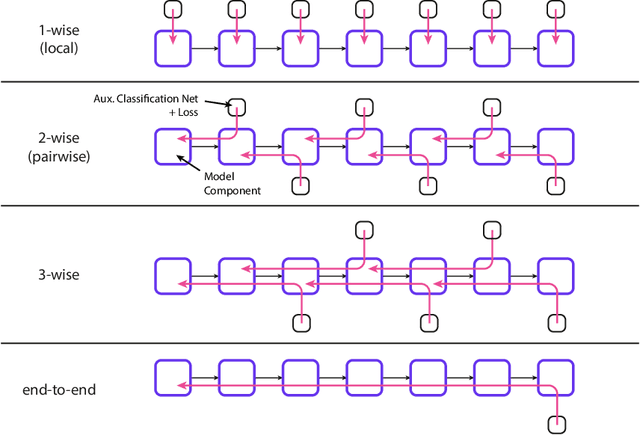

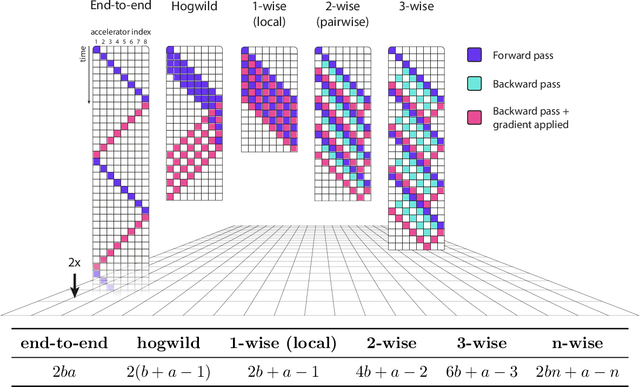
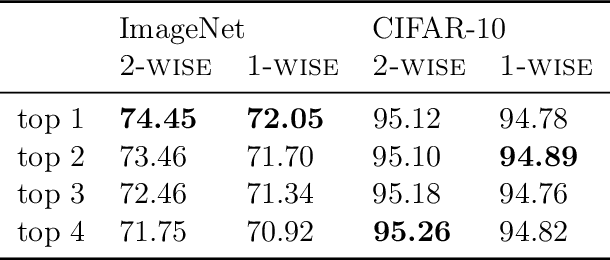
The number of parameters in state of the art neural networks has drastically increased in recent years. This surge of interest in large scale neural networks has motivated the development of new distributed training strategies enabling such models. One such strategy is model-parallel distributed training. Unfortunately, model-parallelism suffers from poor resource utilisation, which leads to wasted resources. In this work, we improve upon recent developments in an idealised model-parallel optimisation setting: local learning. Motivated by poor resource utilisation, we introduce a class of intermediary strategies between local and global learning referred to as interlocking backpropagation. These strategies preserve many of the compute-efficiency advantages of local optimisation, while recovering much of the task performance achieved by global optimisation. We assess our strategies on both image classification ResNets and Transformer language models, finding that our strategy consistently out-performs local learning in terms of task performance, and out-performs global learning in training efficiency.
Correction of Chromatic Aberration from a Single Image Using Keypoints
Feb 08, 2020

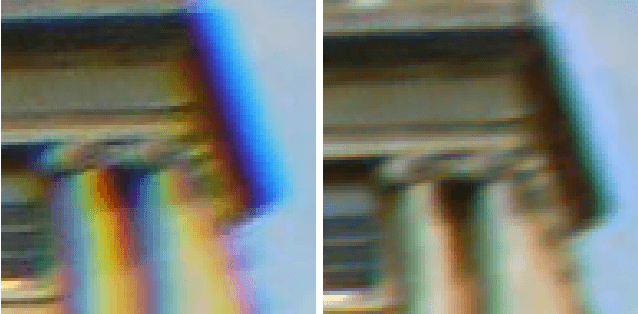
In this paper, we propose a method to correct for chromatic aberration in a single photograph. Our method replicates what a user would do in a photo editing program to account for this defect. We find matching keypoints in each colour channel then align them as a user would.
Patternless Adversarial Attacks on Video Recognition Networks
Feb 12, 2020

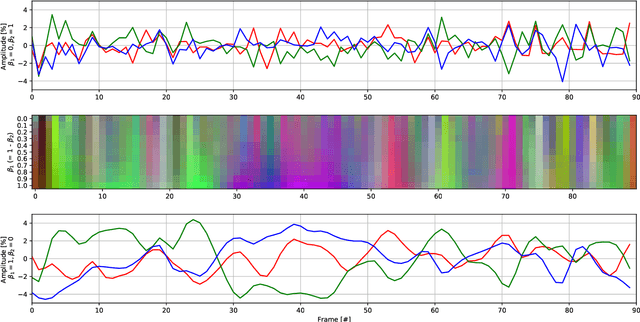
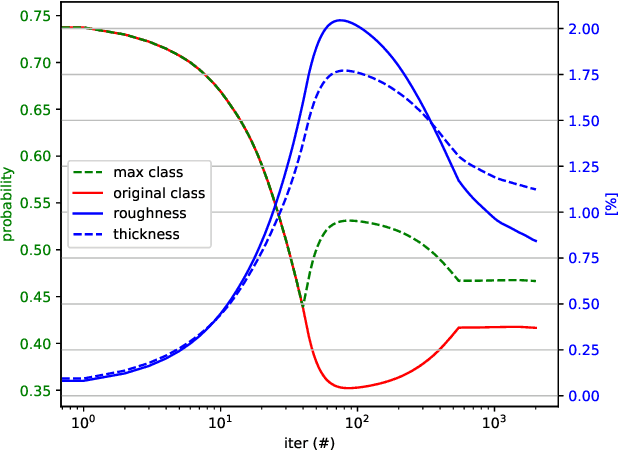
Deep neural networks for classification of videos, just like image classification networks, may be subjected to adversarial manipulation. The main difference between image classifiers and video classifiers is that the latter usually use temporal information contained within the video in the form of optical flow or implicitly by various differences between adjacent frames. In this work we present a manipulation scheme for fooling video classifiers by introducing a spatial patternless temporal perturbation that is practically unnoticed by human observers and undetectable by leading image adversarial pattern detection algorithms. After demonstrating the manipulation of action classification of single videos, we generalize the procedure to make adversarial patterns with temporal invariance that generalizes across different classes for both targeted and untargeted attacks.
Guessing State Tracking for Visual Dialogue
Feb 27, 2020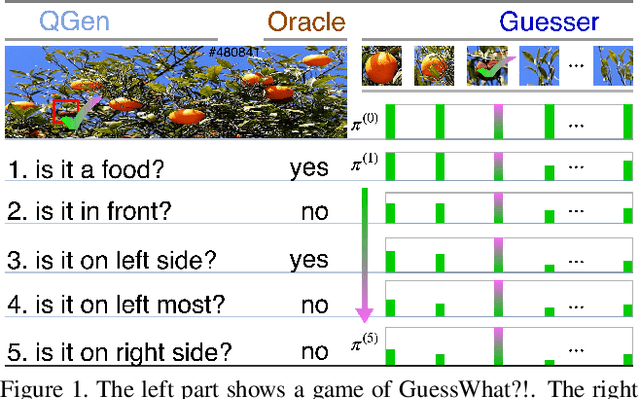
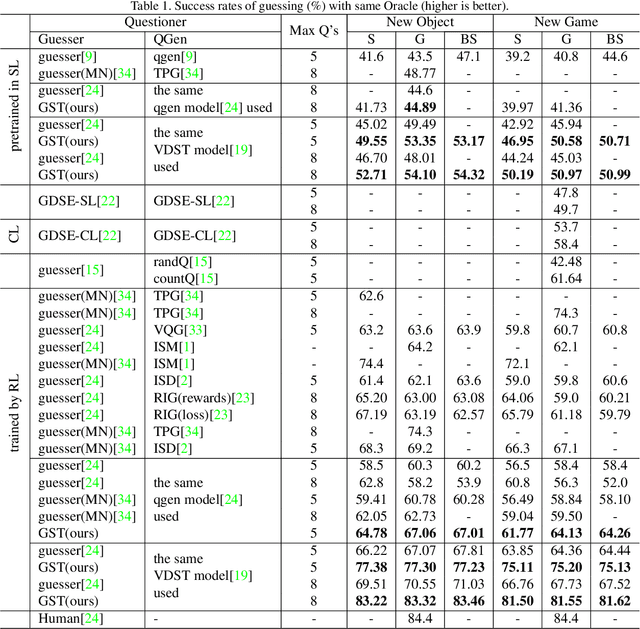
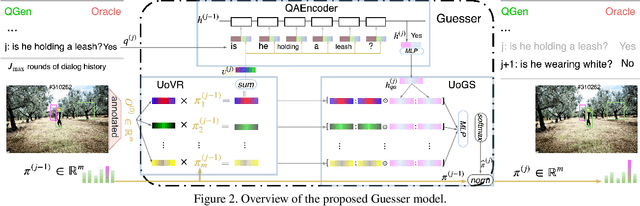
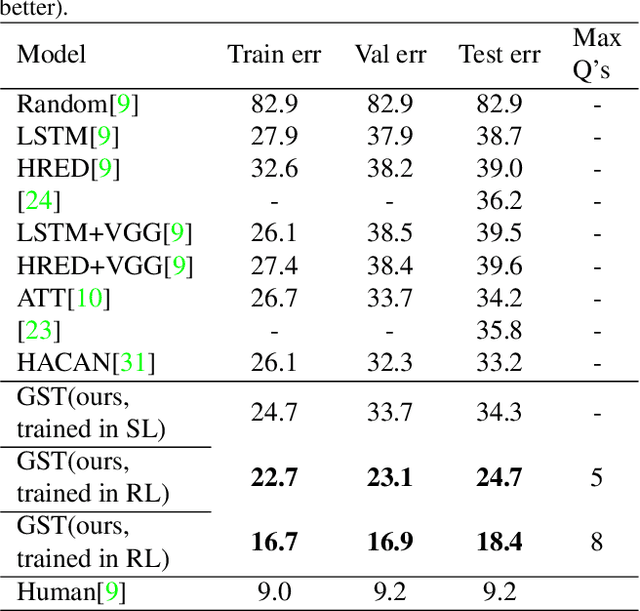
The Guesser plays an important role in GuessWhat?! like visual dialogues. It locates the target object in an image supposed by an oracle oneself over a question-answer based dialogue between a Questioner and the Oracle. Most existing guessers make one and only one guess after receiving all question-answer pairs in a dialogue with predefined number of rounds. This paper proposes the guessing state for the guesser, and regards guess as a process with change of guessing state through a dialogue. A guessing state tracking based guess model is therefore proposed. The guessing state is defined as a distribution on candidate objects in the image. A state update algorithm including three modules is given. UoVR updates the representation of the image according to current guessing state, QAEncoder encodes the question-answer pairs, and UoGS updates the guessing state by combining both information from the image and dialogue history. With the guessing state in hand, two loss functions are defined as supervisions for model training. Early supervision brings supervision to guesser at early rounds, and incremental supervision brings monotonicity to the guessing state. Experimental results on GuessWhat?! dataset show that our model significantly outperforms previous models, achieves new state-of-the-art, especially, the success rate of guessing 83.3% is approaching human-level performance 84.4%.
Fast Adaptation to Super-Resolution Networks via Meta-Learning
Jan 09, 2020
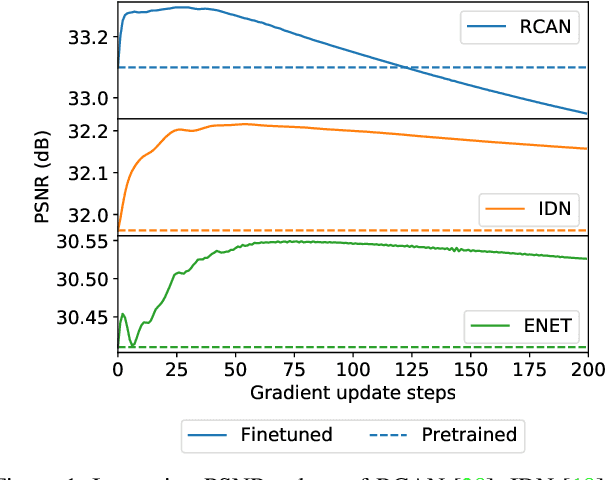
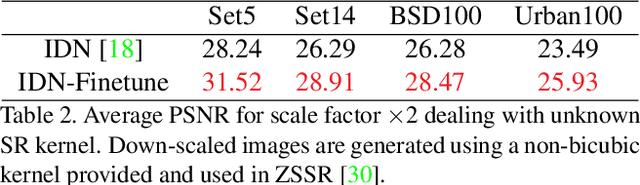
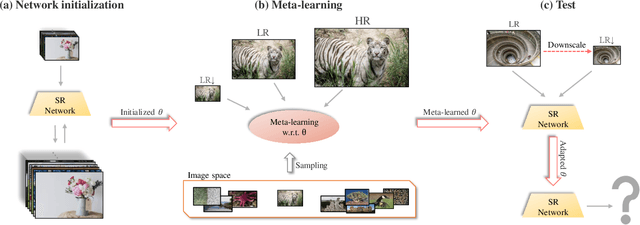
Conventional supervised super-resolution (SR) approaches are trained with massive external SR datasets but fail to exploit desirable properties of the given test image. On the other hand, self-supervised SR approaches utilize the internal information within a test image but suffer from computational complexity in run-time. In this work, we observe the opportunity for further improvement of the performance of SISR without changing the architecture of conventional SR networks by practically exploiting additional information given from the input image. In the training stage, we train the network via meta-learning; thus, the network can quickly adapt to any input image at test time. Then, in the test stage, parameters of this meta-learned network are rapidly fine-tuned with only a few iterations by only using the given low-resolution image. The adaptation at the test time takes full advantage of patch-recurrence property observed in natural images. Our method effectively handles unknown SR kernels and can be applied to any existing model. We demonstrate that the proposed model-agnostic approach consistently improves the performance of conventional SR networks on various benchmark SR datasets.
Halluci-Net: Scene Completion by Exploiting Object Co-occurrence Relationships
Apr 18, 2020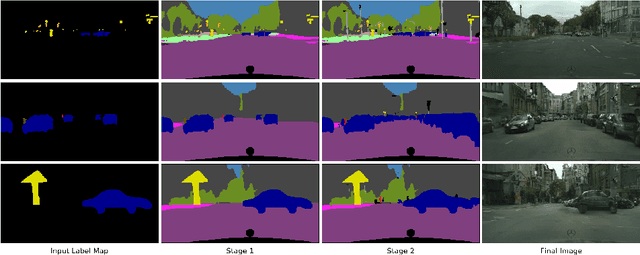

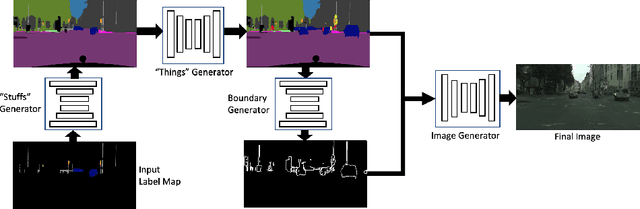

We address the new problem of complex scene completion from sparse label maps. We use a two-stage deep network based method, called `Halluci-Net', that uses object co-occurrence relationships to produce a dense and complete label map. The generated dense label map is fed into a state-of-the-art image synthesis method to obtain the final image. The proposed method is evaluated on the Cityscapes dataset and it outperforms a single-stage baseline method on various performance metrics like Fr\'echet Inception Distance (FID), semantic segmentation accuracy, and similarity in object co-occurrences. In addition to this, we show qualitative results on a subset of ADE20K dataset containing bedroom images.
CAS-CNN: A Deep Convolutional Neural Network for Image Compression Artifact Suppression
Nov 22, 2016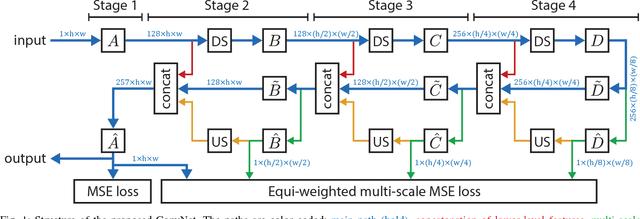
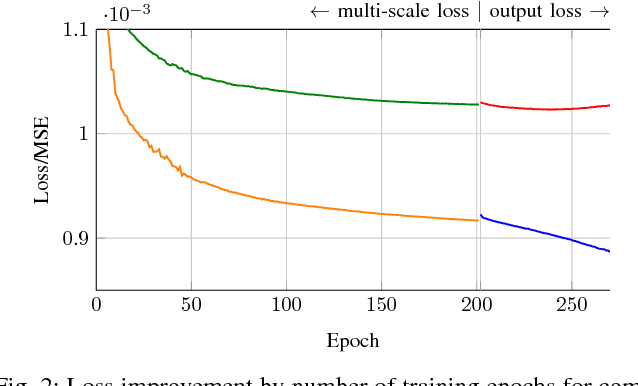
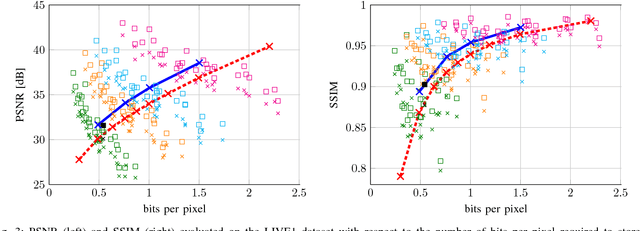
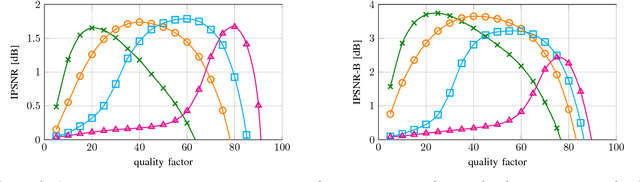
Lossy image compression algorithms are pervasively used to reduce the size of images transmitted over the web and recorded on data storage media. However, we pay for their high compression rate with visual artifacts degrading the user experience. Deep convolutional neural networks have become a widespread tool to address high-level computer vision tasks very successfully. Recently, they have found their way into the areas of low-level computer vision and image processing to solve regression problems mostly with relatively shallow networks. We present a novel 12-layer deep convolutional network for image compression artifact suppression with hierarchical skip connections and a multi-scale loss function. We achieve a boost of up to 1.79 dB in PSNR over ordinary JPEG and an improvement of up to 0.36 dB over the best previous ConvNet result. We show that a network trained for a specific quality factor (QF) is resilient to the QF used to compress the input image - a single network trained for QF 60 provides a PSNR gain of more than 1.5 dB over the wide QF range from 40 to 76.
Error-Corrected Margin-Based Deep Cross-Modal Hashing for Facial Image Retrieval
Apr 03, 2020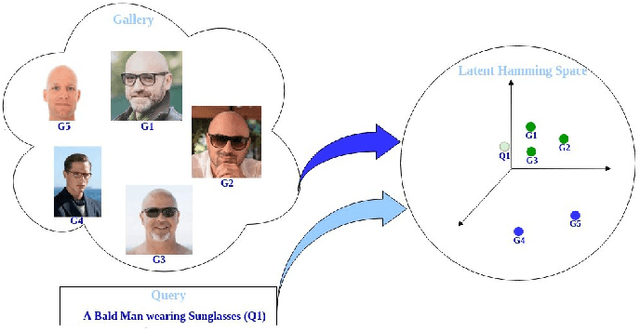
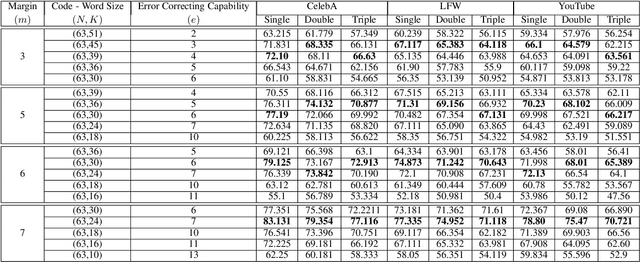
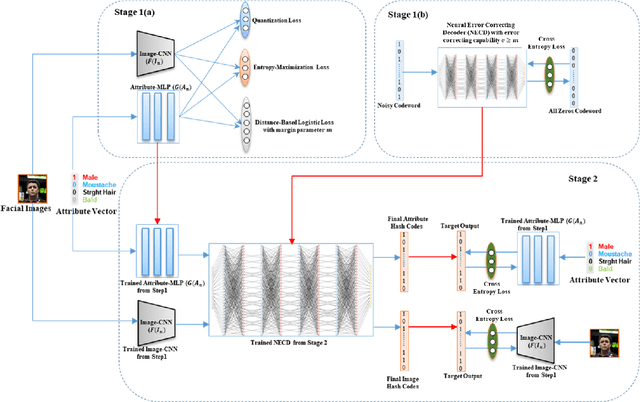
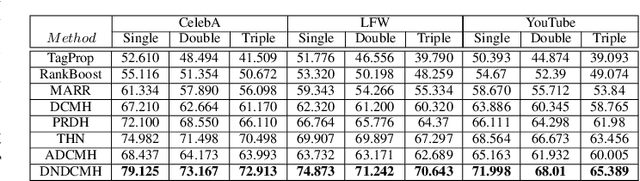
Cross-modal hashing facilitates mapping of heterogeneous multimedia data into a common Hamming space, which can beutilized for fast and flexible retrieval across different modalities. In this paper, we propose a novel cross-modal hashingarchitecture-deep neural decoder cross-modal hashing (DNDCMH), which uses a binary vector specifying the presence of certainfacial attributes as an input query to retrieve relevant face images from a database. The DNDCMH network consists of two separatecomponents: an attribute-based deep cross-modal hashing (ADCMH) module, which uses a margin (m)-based loss function toefficiently learn compact binary codes to preserve similarity between modalities in the Hamming space, and a neural error correctingdecoder (NECD), which is an error correcting decoder implemented with a neural network. The goal of NECD network in DNDCMH isto error correct the hash codes generated by ADCMH to improve the retrieval efficiency. The NECD network is trained such that it hasan error correcting capability greater than or equal to the margin (m) of the margin-based loss function. This results in NECD cancorrect the corrupted hash codes generated by ADCMH up to the Hamming distance of m. We have evaluated and comparedDNDCMH with state-of-the-art cross-modal hashing methods on standard datasets to demonstrate the superiority of our method.
Brain-Inspired Model for Incremental Learning Using a Few Examples
Feb 27, 2020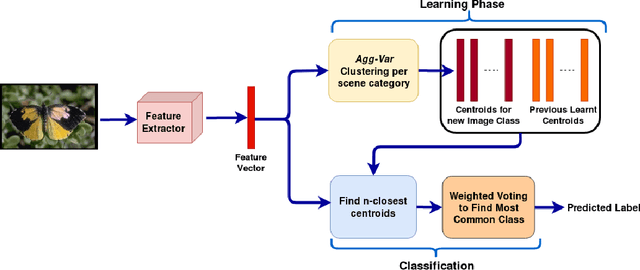
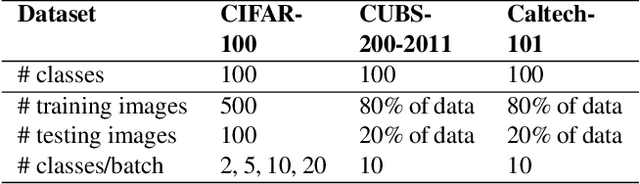
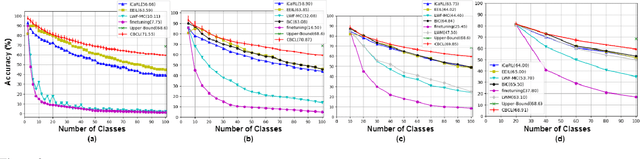
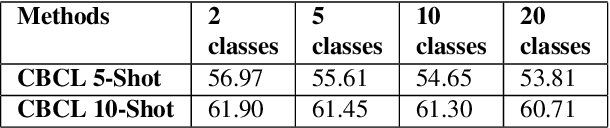
Incremental learning attempts to develop a classifier which learns continuously from a stream of data segregated into different classes. Deep learning approaches suffer from catastrophic forgetting when learning classes incrementally. We propose a novel approach to incremental learning inspired by the concept learning model of the hippocampus that represents each image class as centroids and does not suffer from catastrophic forgetting. Classification of a test image is accomplished using the distance of the test image to the n closest centroids. We further demonstrate that our approach can incrementally learn from only a few examples per class. Evaluations of our approach on three class-incremental learning benchmarks: Caltech-101, CUBS-200-2011 and CIFAR-100 for incremental and few-shot incremental learning depict state-of-the-art results in terms of classification accuracy over all learned classes.