 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Tensor Based Second Order Variational Model for Image Reconstruction
Sep 27, 2016


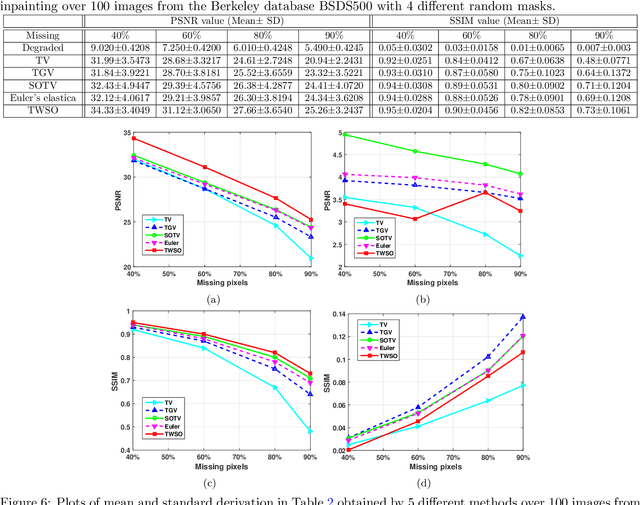
Second order total variation (SOTV) models have advantages for image reconstruction over their first order counterparts including their ability to remove the staircase artefact in the reconstructed image, but they tend to blur the reconstructed image. To overcome this drawback, we introduce a new Tensor Weighted Second Order (TWSO) model for image reconstruction. Specifically, we develop a novel regulariser for the SOTV model that uses the Frobenius norm of the product of the SOTV Hessian matrix and the anisotropic tensor. We then adapt the alternating direction method of multipliers (ADMM) to solve the proposed model by breaking down the original problem into several subproblems. All the subproblems have closed-forms and can thus be solved efficiently. The proposed method is compared with a range of state-of-the-art approaches such as tensor-based anisotropic diffusion, total generalised variation, Euler's elastica, etc. Numerical experimental results of the method on both synthetic and real images from the Berkeley database BSDS500 demonstrate that the proposed method eliminates both the staircase and blurring effects and outperforms the existing approaches for image inpainting and denoising applications.
DeshuffleGAN: A Self-Supervised GAN to Improve Structure Learning
Jun 15, 2020
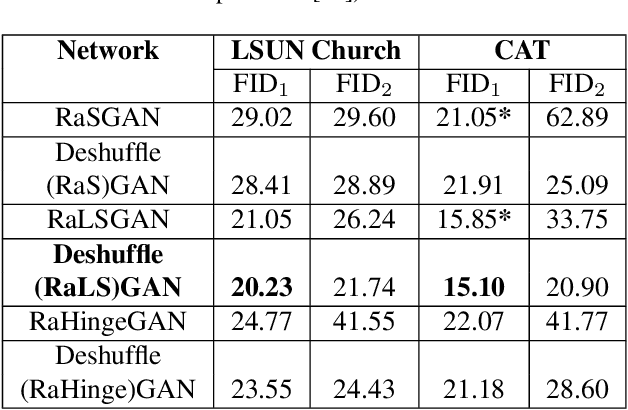
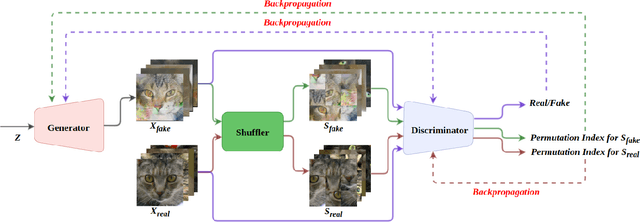

Generative Adversarial Networks (GANs) triggered an increased interest in problem of image generation due to their improved output image quality and versatility for expansion towards new methods. Numerous GAN-based works attempt to improve generation by architectural and loss-based extensions. We argue that one of the crucial points to improve the GAN performance in terms of realism and similarity to the original data distribution is to be able to provide the model with a capability to learn the spatial structure in data. To that end, we propose the DeshuffleGAN to enhance the learning of the discriminator and the generator, via a self-supervision approach. Specifically, we introduce a deshuffling task that solves a puzzle of randomly shuffled image tiles, which in turn helps the DeshuffleGAN learn to increase its expressive capacity for spatial structure and realistic appearance. We provide experimental evidence for the performance improvement in generated images, compared to the baseline methods, which is consistently observed over two different datasets.
Gabor Barcodes for Medical Image Retrieval
May 14, 2016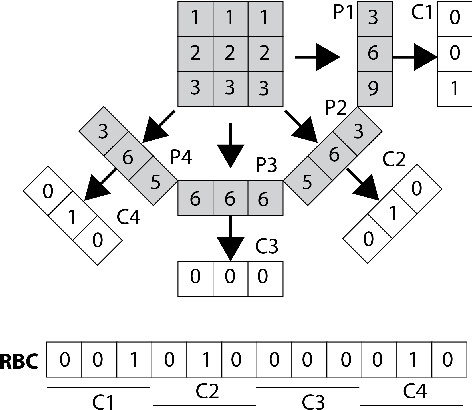
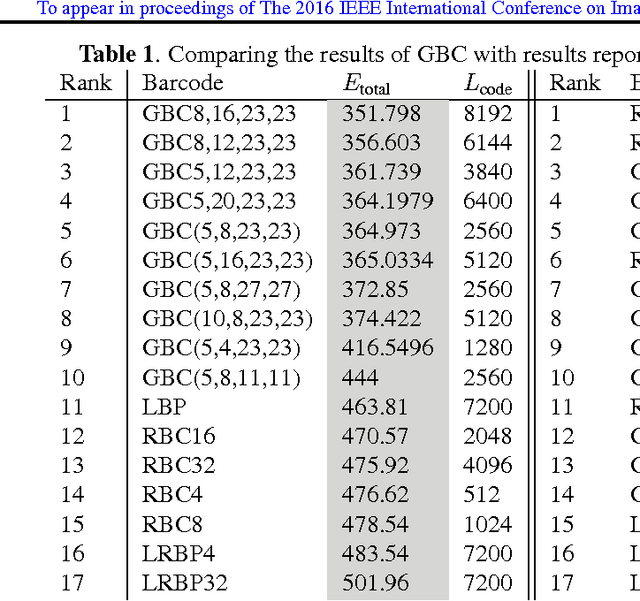
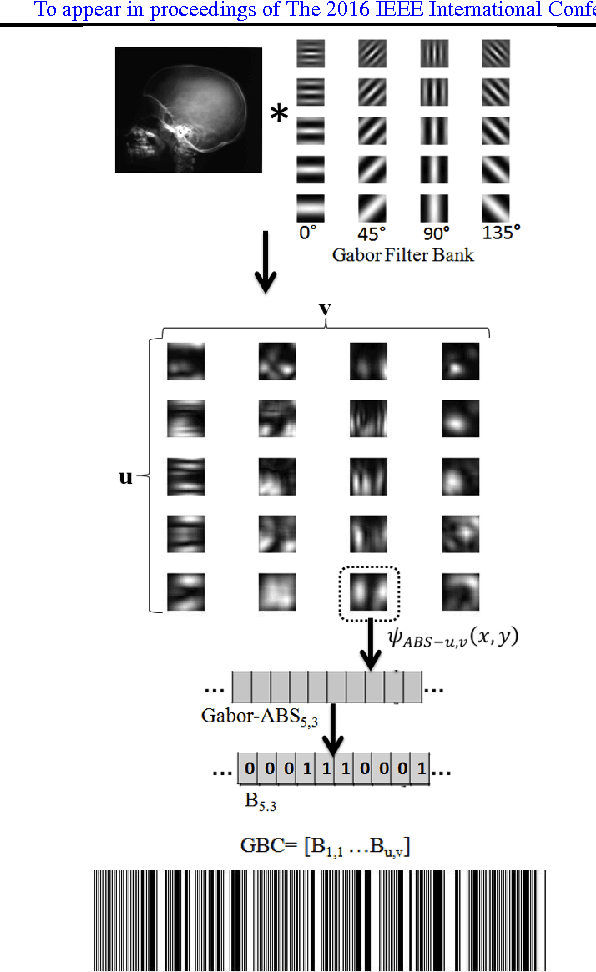
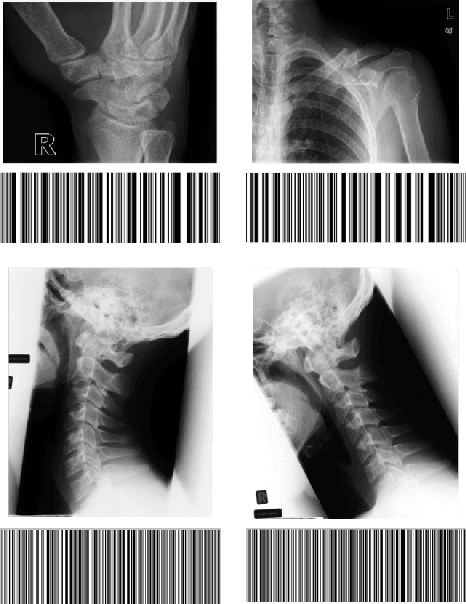
In recent years, advances in medical imaging have led to the emergence of massive databases, containing images from a diverse range of modalities. This has significantly heightened the need for automated annotation of the images on one side, and fast and memory-efficient content-based image retrieval systems on the other side. Binary descriptors have recently gained more attention as a potential vehicle to achieve these goals. One of the recently introduced binary descriptors for tagging of medical images are Radon barcodes (RBCs) that are driven from Radon transform via local thresholding. Gabor transform is also a powerful transform to extract texture-based information. Gabor features have exhibited robustness against rotation, scale, and also photometric disturbances, such as illumination changes and image noise in many applications. This paper introduces Gabor Barcodes (GBCs), as a novel framework for the image annotation. To find the most discriminative GBC for a given query image, the effects of employing Gabor filters with different parameters, i.e., different sets of scales and orientations, are investigated, resulting in different barcode lengths and retrieval performances. The proposed method has been evaluated on the IRMA dataset with 193 classes comprising of 12,677 x-ray images for indexing, and 1,733 x-rays images for testing. A total error score as low as $351$ ($\approx 80\%$ accuracy for the first hit) was achieved.
Sequence-to-Sequence Contrastive Learning for Text Recognition
Dec 20, 2020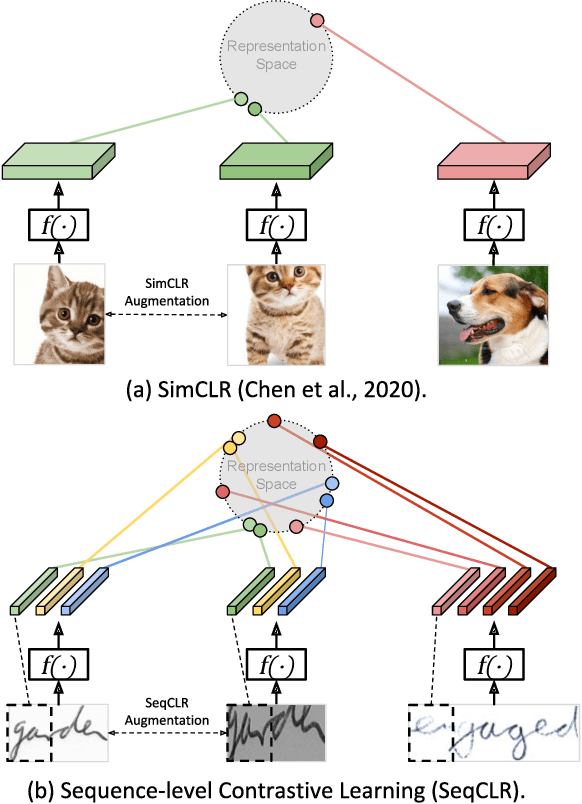
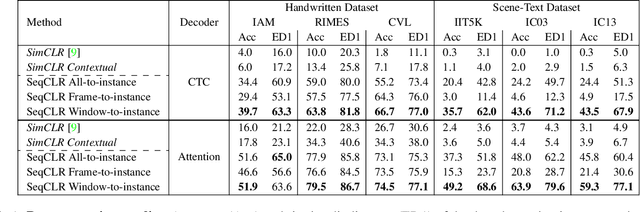
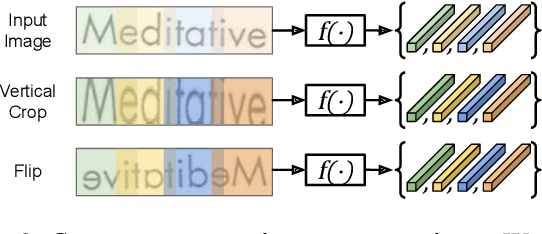
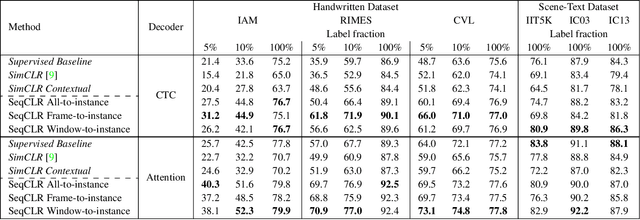
We propose a framework for sequence-to-sequence contrastive learning (SeqCLR) of visual representations, which we apply to text recognition. To account for the sequence-to-sequence structure, each feature map is divided into different instances over which the contrastive loss is computed. This operation enables us to contrast in a sub-word level, where from each image we extract several positive pairs and multiple negative examples. To yield effective visual representations for text recognition, we further suggest novel augmentation heuristics, different encoder architectures and custom projection heads. Experiments on handwritten text and on scene text show that when a text decoder is trained on the learned representations, our method outperforms non-sequential contrastive methods. In addition, when the amount of supervision is reduced, SeqCLR significantly improves performance compared with supervised training, and when fine-tuned with 100% of the labels, our method achieves state-of-the-art results on standard handwritten text recognition benchmarks.
Multiple Exemplars-based Hallucinationfor Face Super-resolution and Editing
Sep 17, 2020
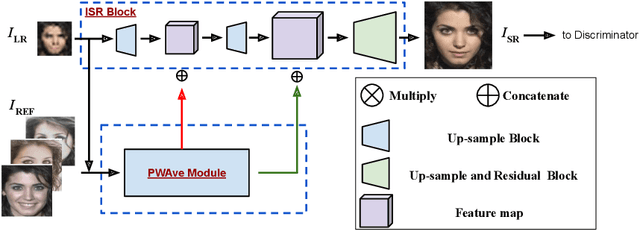

Given a really low-resolution input image of a face (say 16x16 or 8x8 pixels), the goal of this paper is to reconstruct a high-resolution version thereof. This, by itself, is an ill-posed problem, as the high-frequency information is missing in the low-resolution input and needs to be hallucinated, based on prior knowledge about the image content. Rather than relying on a generic face prior, in this paper, we explore the use of a set of exemplars, i.e. other high-resolution images of the same person. These guide the neural network as we condition the output on them. Multiple exemplars work better than a single one. To combine the information from multiple exemplars effectively, we introduce a pixel-wise weight generation module. Besides standard face super-resolution, our method allows to perform subtle face editing simply by replacing the exemplars with another set with different facial features. A user study is conducted and shows the super-resolved images can hardly be distinguished from real images on the CelebA dataset. A qualitative comparison indicates our model outperforms methods proposed in the literature on the CelebA and WebFace dataset.
GAP++: Learning to generate target-conditioned adversarial examples
Jun 09, 2020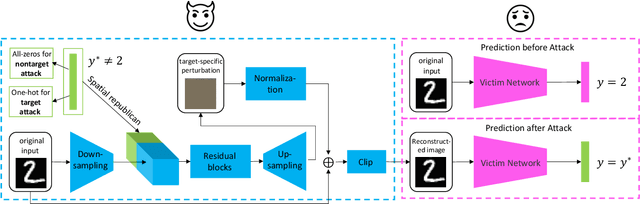
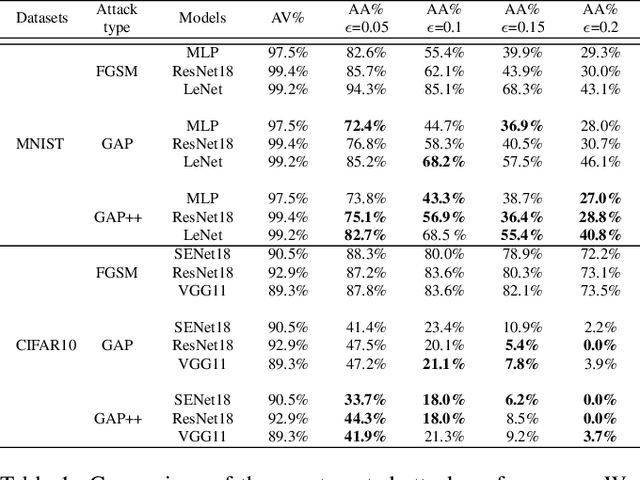
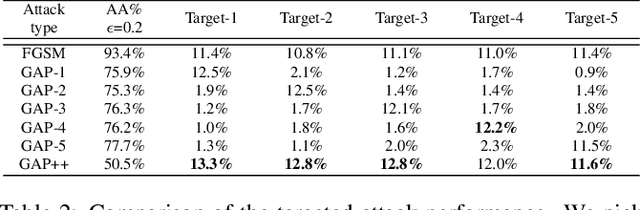
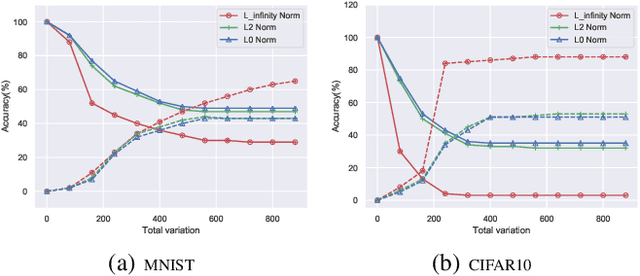
Adversarial examples are perturbed inputs which can cause a serious threat for machine learning models. Finding these perturbations is such a hard task that we can only use the iterative methods to traverse. For computational efficiency, recent works use adversarial generative networks to model the distribution of both the universal or image-dependent perturbations directly. However, these methods generate perturbations only rely on input images. In this work, we propose a more general-purpose framework which infers target-conditioned perturbations dependent on both input image and target label. Different from previous single-target attack models, our model can conduct target-conditioned attacks by learning the relations of attack target and the semantics in image. Using extensive experiments on the datasets of MNIST and CIFAR10, we show that our method achieves superior performance with single target attack models and obtains high fooling rates with small perturbation norms.
Data Processing for Short-Term Solar Irradiance Forecasting using Ground-Based Infrared Images
Jan 21, 2021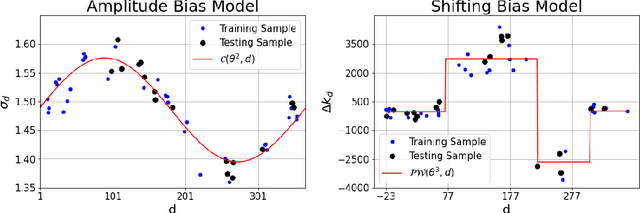
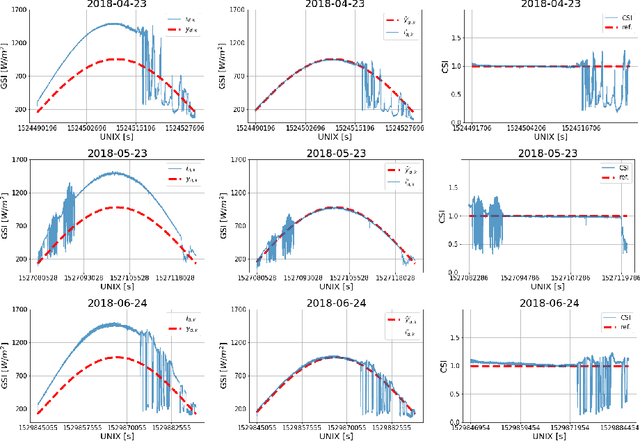
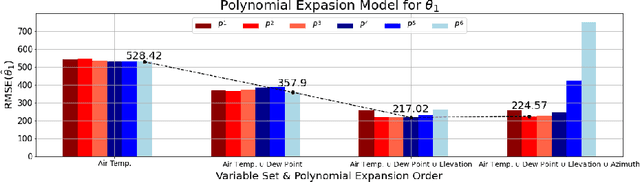
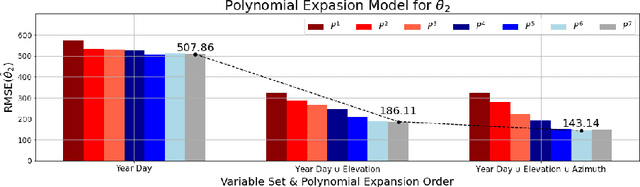
The generation of energy in a power grid which uses Photovoltaic (PV) systems depends on the projection of shadows from moving clouds in the Troposphere. This investigation proposes an efficient method of data processing for the statistical quantification of cloud features using long-wave infrared (IR) images and Global Solar Irradiance (GSI) measurements. The IR images are obtained using a data acquisition system (DAQ) mounted on a solar tracker. We explain how to remove cyclostationary biases in GSI measurements. Seasonal trends are removed from the GSI time series, using the theoretical GSI to obtain the Clear-Sky Index (CSI) time series. We introduce an atmospheric model to remove from IR images both the effect of atmosphere scatter irradiance and the effect of the Sun's direct irradiance. Scattering is produced by water spots and dust particles on the germanium lens of the enclosure. We explain how to remove the scattering effect produced by the germanium lens attached to the DAQ enclosure window of the IR camera. An atmospheric condition model classifies the sky-conditions in four different categories: clear-sky, cumulus, stratus and nimbus. When an IR image is classified in the category of clear-sky, it is used to model the scattering effect of the germanium lens.
Evaluation of Neural Networks for Image Recognition Applications: Designing a 0-1 MILP Model of a CNN to create adversarials
Sep 01, 2018


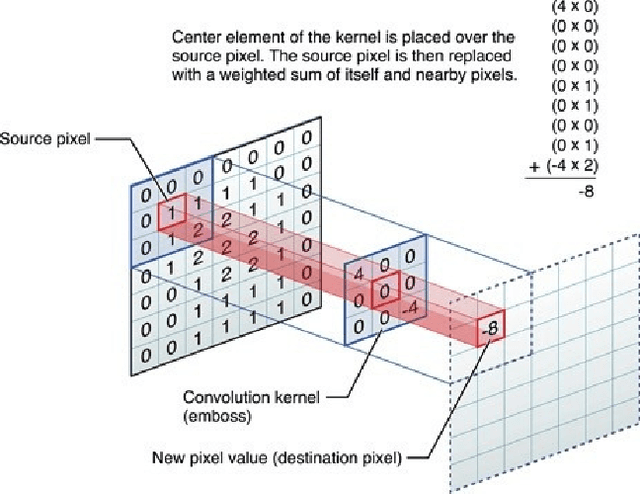
Image Recognition is a central task in computer vision with applications ranging across search, robotics, self-driving cars and many others. There are three purposes of this document: 1. We follow up on (Fischetti & Jo, December, 2017) and show how standard convolutional neural network can be optimized to a more sophisticated capsule architecture. 2. We introduce a MILP model based on CNN to create adversarials. 3. We compare and evaluate each network for image recognition tasks.
Visual Relationship Detection using Scene Graphs: A Survey
May 16, 2020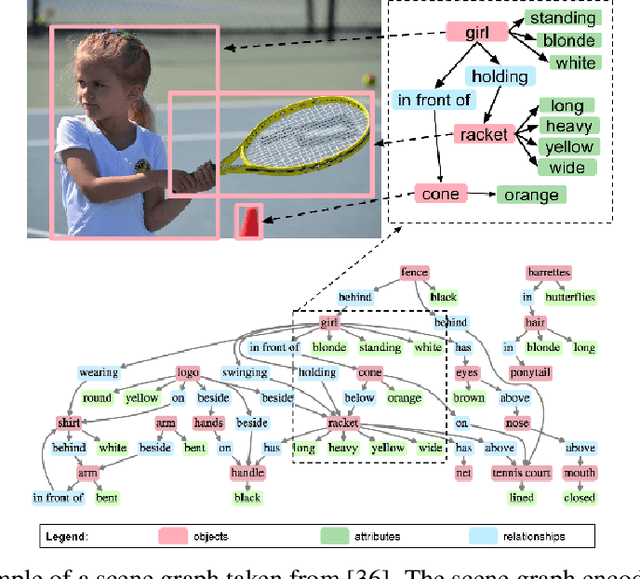
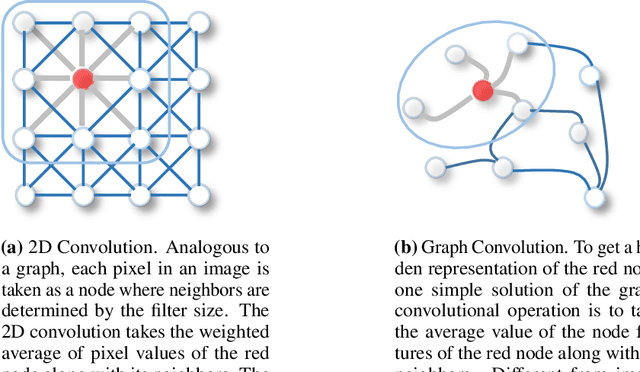
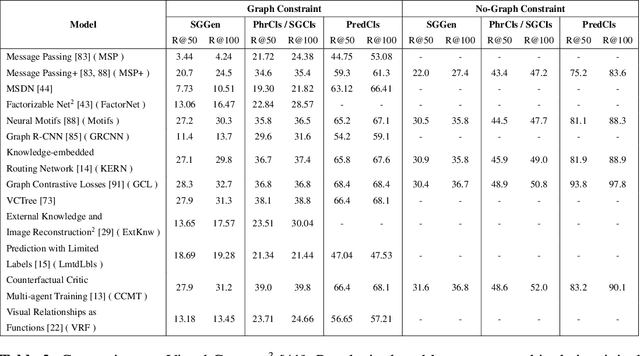
Understanding a scene by decoding the visual relationships depicted in an image has been a long studied problem. While the recent advances in deep learning and the usage of deep neural networks have achieved near human accuracy on many tasks, there still exists a pretty big gap between human and machine level performance when it comes to various visual relationship detection tasks. Developing on earlier tasks like object recognition, segmentation and captioning which focused on a relatively coarser image understanding, newer tasks have been introduced recently to deal with a finer level of image understanding. A Scene Graph is one such technique to better represent a scene and the various relationships present in it. With its wide number of applications in various tasks like Visual Question Answering, Semantic Image Retrieval, Image Generation, among many others, it has proved to be a useful tool for deeper and better visual relationship understanding. In this paper, we present a detailed survey on the various techniques for scene graph generation, their efficacy to represent visual relationships and how it has been used to solve various downstream tasks. We also attempt to analyze the various future directions in which the field might advance in the future. Being one of the first papers to give a detailed survey on this topic, we also hope to give a succinct introduction to scene graphs, and guide practitioners while developing approaches for their applications.
Learning to do multiframe blind deconvolution unsupervisedly
Jun 02, 2020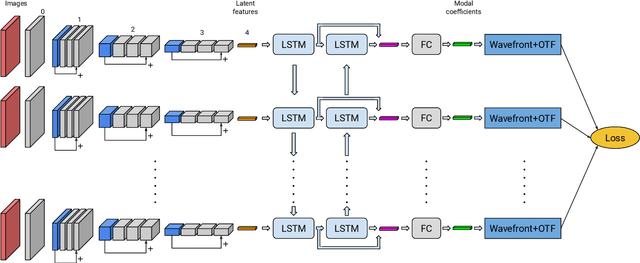

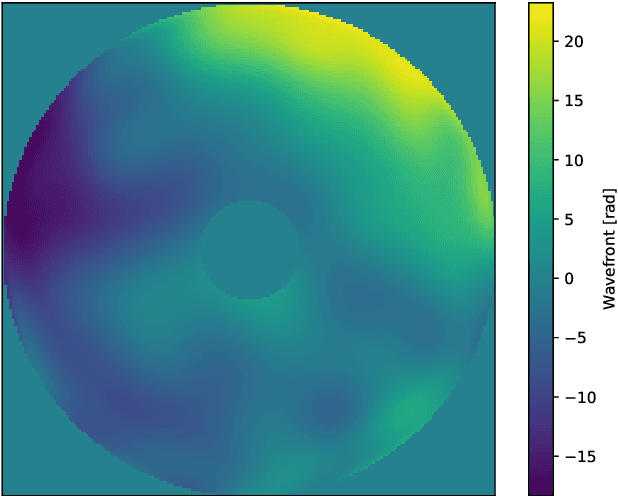

Observation from ground based telescopes are affected by the presence of the Earth atmosphere, which severely perturbs them. The use of adaptive optics techniques has allowed us to partly beat this limitation. However, image selection or post-facto image reconstruction methods are routinely needed to reach the diffraction limit of telescopes. Deep learning has been recently used to accelerate these image reconstructions. Currently, these deep neural networks are trained with supervision, so that standard deconvolution algorithms need to be applied a-priori to generate the training sets. Our aim is to propose an unsupervised method which can then be trained simply with observations and check it with data from the FastCam instrument. We use a neural model composed of three neural networks that are trained end-to-end by leveraging the linear image formation theory to construct a physically-motivated loss function. The analysis of the trained neural model shows that multiframe blind deconvolution can be trained self-supervisedly, i.e., using only observations. The output of the network are the corrected images and also estimations of the instantaneous wavefronts. The network model is of the order of 1000 times faster than applying standard deconvolution based on optimization. With some work, the model can bed used on real-time at the telescope.