 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Exemplars-based Hallucinationfor Face Super-resolution and Editing
Paper and Code
Sep 17, 2020
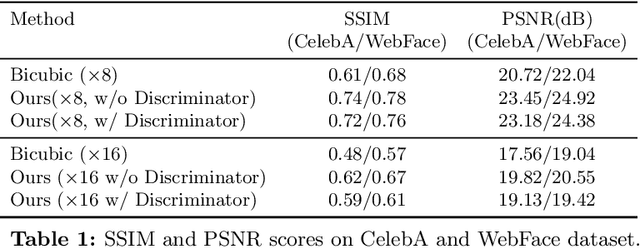
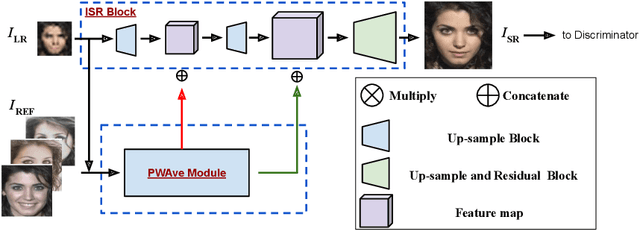

Given a really low-resolution input image of a face (say 16x16 or 8x8 pixels), the goal of this paper is to reconstruct a high-resolution version thereof. This, by itself, is an ill-posed problem, as the high-frequency information is missing in the low-resolution input and needs to be hallucinated, based on prior knowledge about the image content. Rather than relying on a generic face prior, in this paper, we explore the use of a set of exemplars, i.e. other high-resolution images of the same person. These guide the neural network as we condition the output on them. Multiple exemplars work better than a single one. To combine the information from multiple exemplars effectively, we introduce a pixel-wise weight generation module. Besides standard face super-resolution, our method allows to perform subtle face editing simply by replacing the exemplars with another set with different facial features. A user study is conducted and shows the super-resolved images can hardly be distinguished from real images on the CelebA dataset. A qualitative comparison indicates our model outperforms methods proposed in the literature on the CelebA and WebFace dataset.