 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Comparison of Update and Genetic Training Algorithms in a Memristor Crossbar Perceptron
Dec 10, 2020
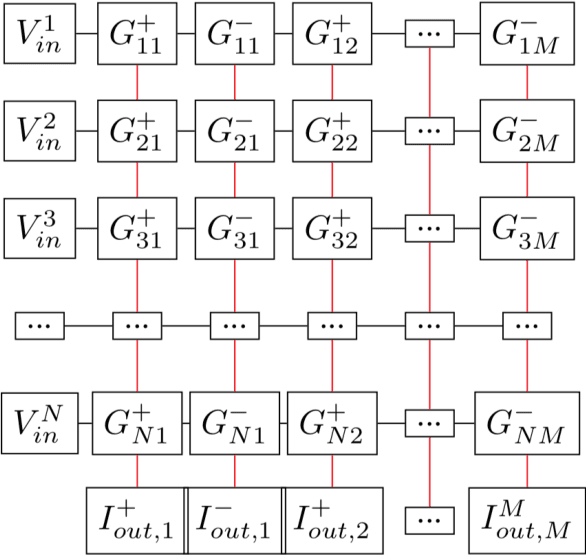
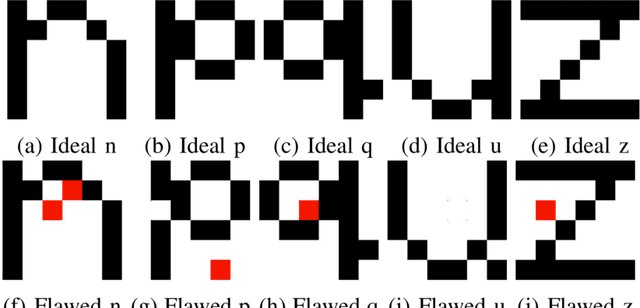
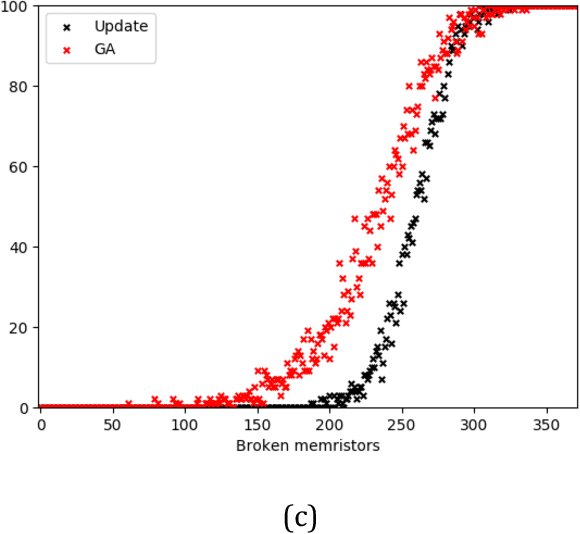
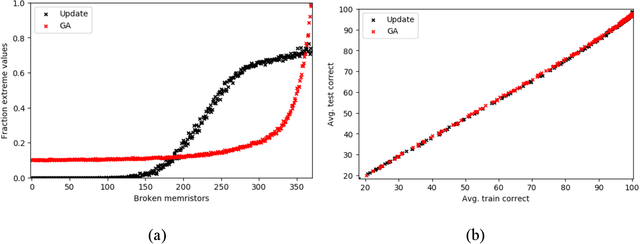
Memristor-based computer architectures are becoming more attractive as a possible choice of hardware for the implementation of neural networks. However, at present, memristor technologies are susceptible to a variety of failure modes, a serious concern in any application where regular access to the hardware may not be expected or even possible. In this study, we investigate whether certain training algorithms may be more resilient to particular hardware failure modes, and therefore more suitable for use in those applications. We implement two training algorithms -- a local update scheme and a genetic algorithm -- in a simulated memristor crossbar, and compare their ability to train for a simple image classification task as an increasing number of memristors fail to adjust their conductance. We demonstrate that there is a clear distinction between the two algorithms in several measures of the rate of failure to train.
Detecting natural disasters, damage, and incidents in the wild
Aug 20, 2020

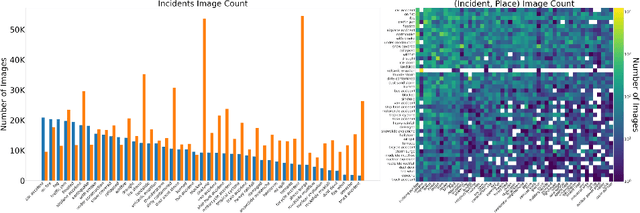
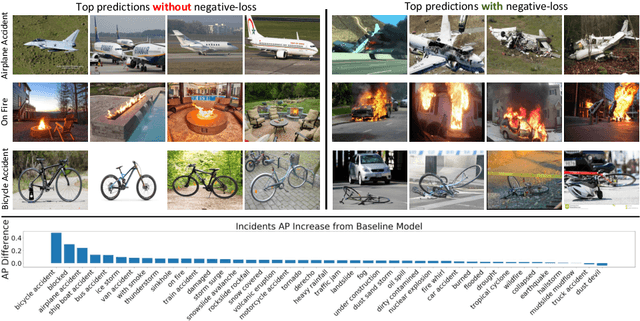
Responding to natural disasters, such as earthquakes, floods, and wildfires, is a laborious task performed by on-the-ground emergency responders and analysts. Social media has emerged as a low-latency data source to quickly understand disaster situations. While most studies on social media are limited to text, images offer more information for understanding disaster and incident scenes. However, no large-scale image datasets for incident detection exists. In this work, we present the Incidents Dataset, which contains 446,684 images annotated by humans that cover 43 incidents across a variety of scenes. We employ a baseline classification model that mitigates false-positive errors and we perform image filtering experiments on millions of social media images from Flickr and Twitter. Through these experiments, we show how the Incidents Dataset can be used to detect images with incidents in the wild. Code, data, and models are available online at http://incidentsdataset.csail.mit.edu.
Generative Adversarial Networks in Digital Pathology: A Survey on Trends and Future Potential
Apr 30, 2020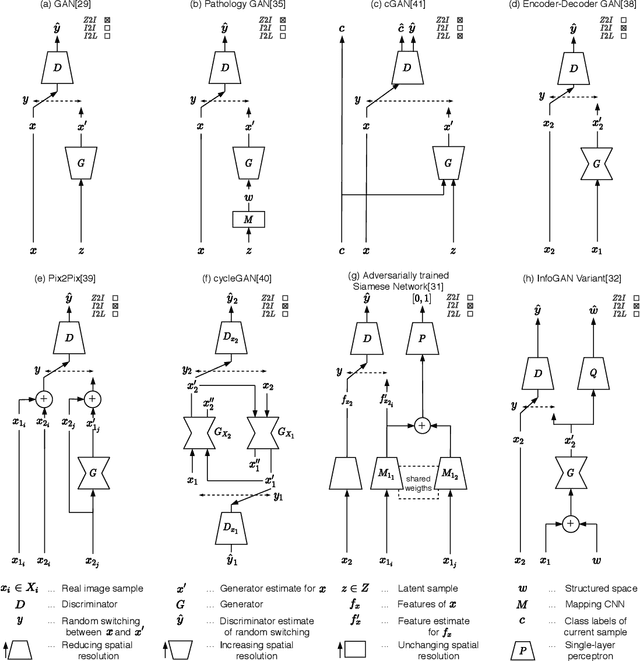
Image analysis in the field of digital pathology has recently gained increased popularity. The use of high-quality whole slide scanners enables the fast acquisition of large amounts of image data, showing extensive context and microscopic detail at the same time. Simultaneously, novel machine learning algorithms have boosted the performance of image analysis approaches. In this paper, we focus on a particularly powerful class of architectures, called Generative Adversarial Networks (GANs), applied to histological image data. Besides improving performance, GANs also enable application scenarios in this field, which were previously intractable. However, GANs could exhibit a potential for introducing bias. Hereby, we summarize the recent state-of-the-art developments in a generalizing notation, present the main applications of GANs and give an outlook of some chosen promising approaches and their possible future applications. In addition, we identify currently unavailable methods with potential for future applications.
Photo-realistic Image Super-resolution with Fast and Lightweight Cascading Residual Network
Mar 06, 2019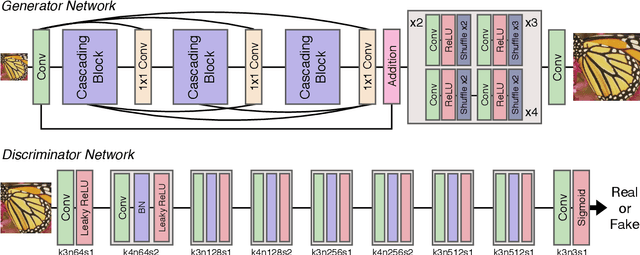
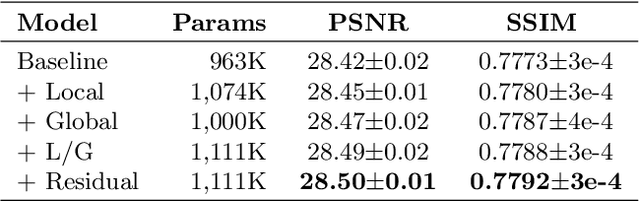
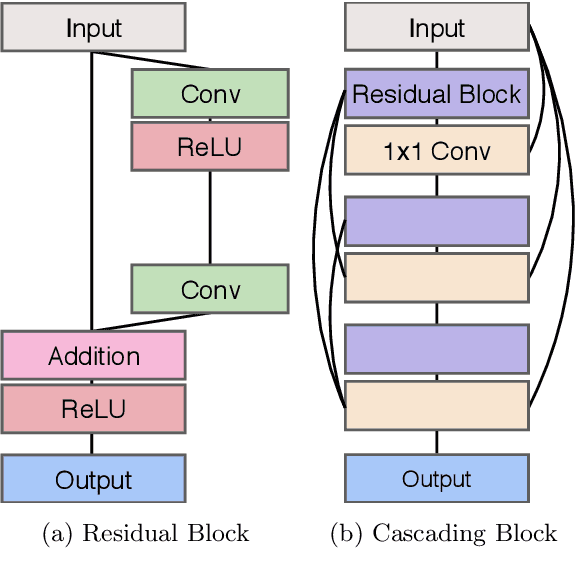

Recent progress in the deep learning-based models has improved single-image super-resolution significantly. However, despite their powerful performance, many models are difficult to apply to the real-world applications because of the heavy computational requirements. To facilitate the use of a deep learning model in such demands, we focus on keeping the model fast and lightweight while maintaining its accuracy. In detail, we design an architecture that implements a cascading mechanism on a residual network to boost the performance with limited resources via multi-level feature fusion. Moreover, we adopt group convolution and weight-tying for our proposed model in order to achieve extreme efficiency. In addition to the traditional super-resolution task, we apply our methods to the photo-realistic super-resolution field using the adversarial learning paradigm and a multi-scale discriminator approach. By doing so, we show that the performances of the proposed models surpass those of the recent methods, which have a complexity similar to ours, for both traditional pixel-based and perception-based tasks.
Robust watermarking with double detector-discriminator approach
Jun 06, 2020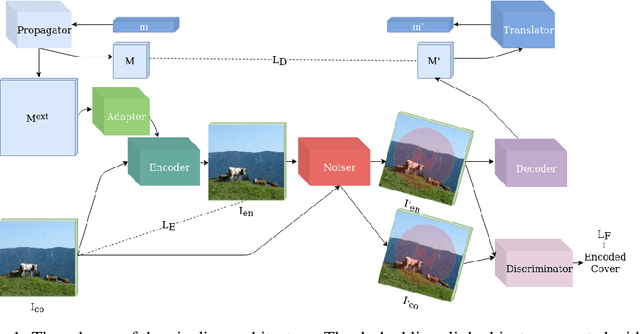
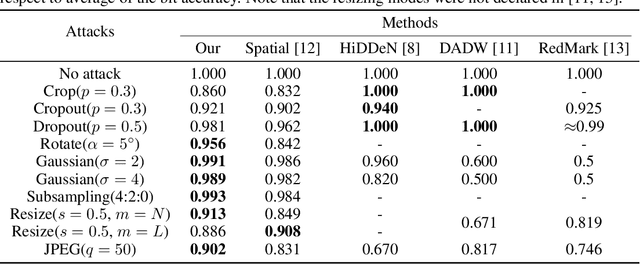

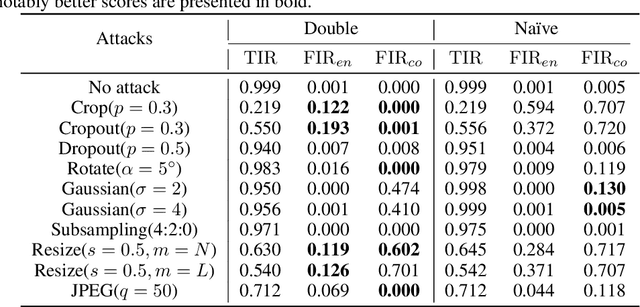
In this paper we present a novel deep framework for a watermarking - a technique of embedding a transparent message into an image in a way that allows retrieving the message from a (perturbed) copy, so that copyright infringement can be tracked. For this technique, it is essential to extract the information from the image even after imposing some digital processing operations on it. Our framework outperforms recent methods in the context of robustness against not only spectrum of attacks (e.g. rotation, resizing, Gaussian smoothing) but also against compression, especially JPEG. The bit accuracy of our method is at least 0.86 for all types of distortions. We also achieved 0.90 bit accuracy for JPEG while recent methods provided at most 0.83. Our method retains high transparency and capacity as well. Moreover, we present our double detector-discriminator approach - a scheme to detect and discriminate if the image contains the embedded message or not, which is crucial for real-life watermarking systems and up to now was not investigated using neural networks. With this, we design a testing formula to validate our extended approach and compared it with a common procedure. We also present an alternative method of balancing between image quality and robustness on attacks which is easily applicable to the framework.
A Little Bit More: Bitplane-Wise Bit-Depth Recovery
May 03, 2020

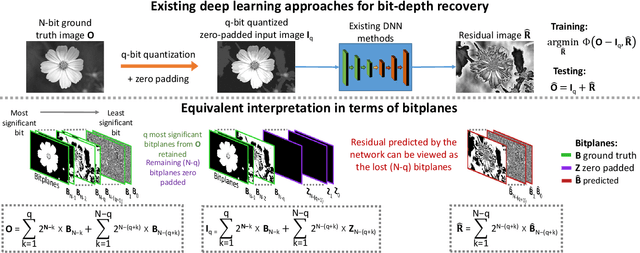
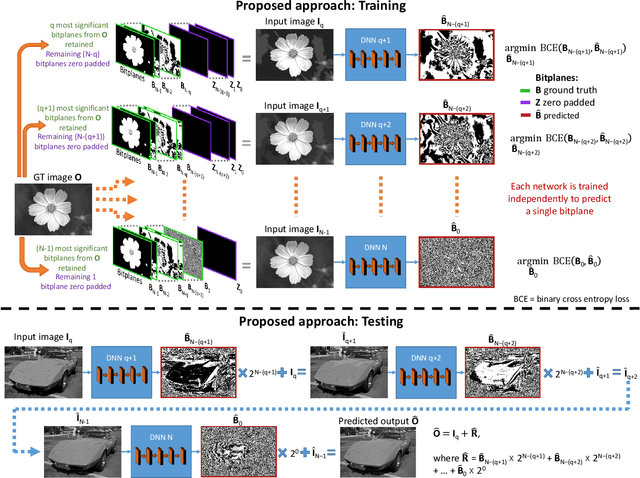
Imaging sensors digitize incoming scene light at a dynamic range of 10--12 bits (i.e., 1024--4096 tonal values). The sensor image is then processed onboard the camera and finally quantized to only 8 bits (i.e., 256 tonal values) to conform to prevailing encoding standards. There are a number of important applications, such as high-bit-depth displays and photo editing, where it is beneficial to recover the lost bit depth. Deep neural networks are effective at this bit-depth reconstruction task. Given the quantized low-bit-depth image as input, existing deep learning methods employ a single-shot approach that attempts to either (1) directly estimate the high-bit-depth image, or (2) directly estimate the residual between the high- and low-bit-depth images. In contrast, we propose a training and inference strategy that recovers the residual image bitplane-by-bitplane. Our bitplane-wise learning framework has the advantage of allowing for multiple levels of supervision during training and is able to obtain state-of-the-art results using a simple network architecture. We test our proposed method extensively on several image datasets and demonstrate an improvement from 0.5dB to 2.3dB PSNR over prior methods depending on the quantization level.
OnionBot: A System for Collaborative Computational Cooking
Nov 10, 2020
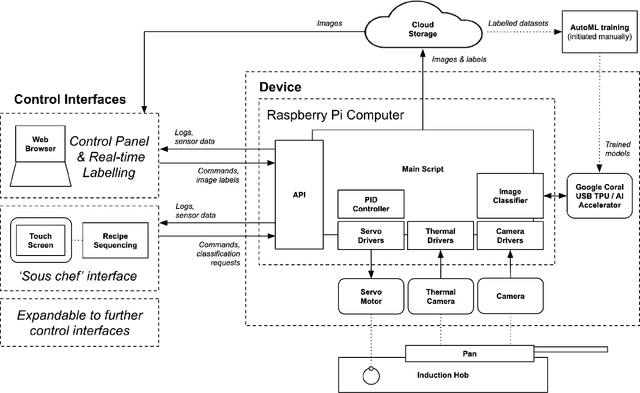
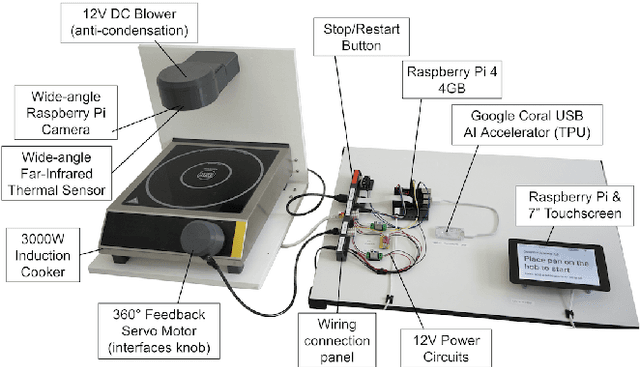
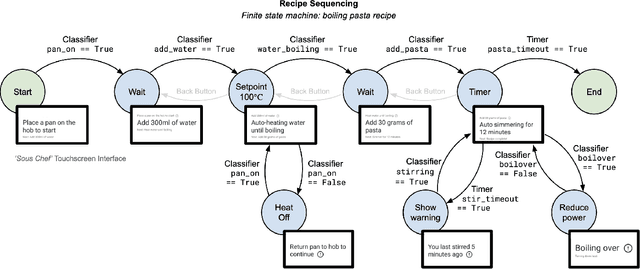
An unsolved challenge in cooking automation is designing for shared kitchen workspaces. In particular, robots struggle with dexterity in the unstructured and dynamic kitchen environment. We propose that human-machine collaboration can be achieved without robotic manipulation. We describe a novel system design using computer vision to inform intelligent cooking interventions. This human-centered approach does not require actuators and promotes dynamic, natural collaboration. We show that automation that assists user-led actions can offer meaningful cooking assistance and can generate the image databases needed for fully autonomous robotic systems of the future. We provide an open source implementation of our work and encourage the research community to build upon it.
The Image Torque Operator for Contour Processing
Jan 18, 2016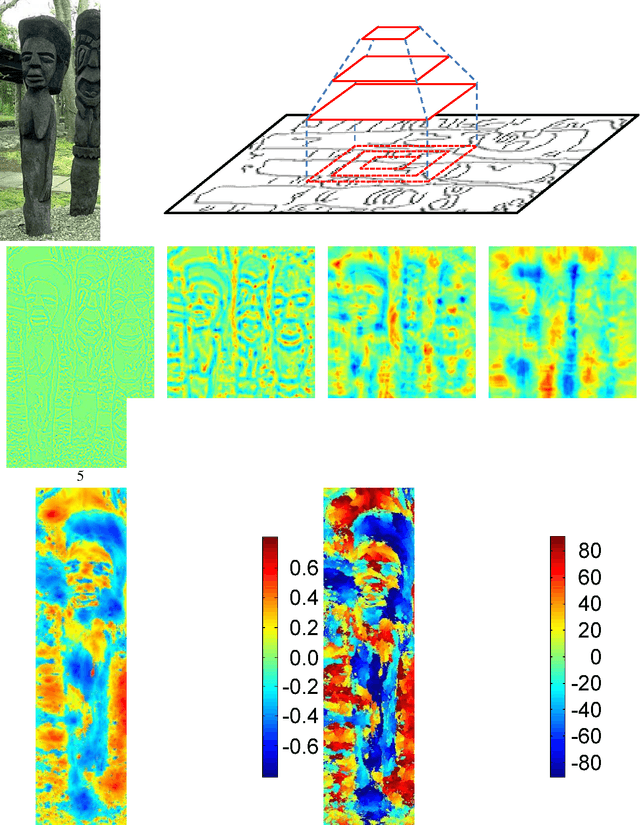
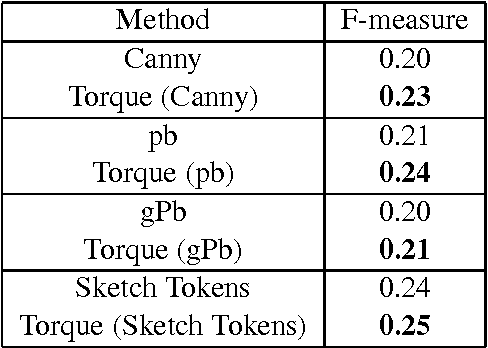
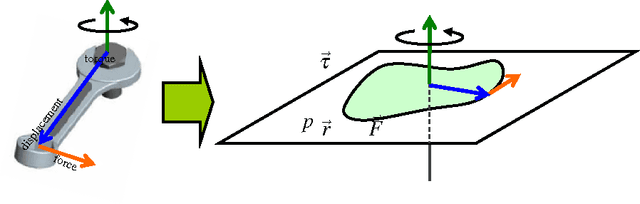
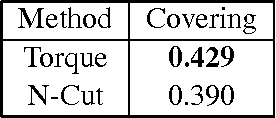
Contours are salient features for image description, but the detection and localization of boundary contours is still considered a challenging problem. This paper introduces a new tool for edge processing implementing the Gestaltism idea of edge grouping. This tool is a mid-level image operator, called the Torque operator, that is designed to help detect closed contours in images. The torque operator takes as input the raw image and creates an image map by computing from the image gradients within regions of multiple sizes a measure of how well the edges are aligned to form closed convex contours. Fundamental properties of the torque are explored and illustrated through examples. Then it is applied in pure bottom-up processing in a variety of applications, including edge detection, visual attention and segmentation and experimentally demonstrated a useful tool that can improve existing techniques. Finally, its extension as a more general grouping mechanism and application in object recognition is discussed.
Iteratively Optimized Patch Label Inference Network for Automatic Pavement Disease Detection
May 27, 2020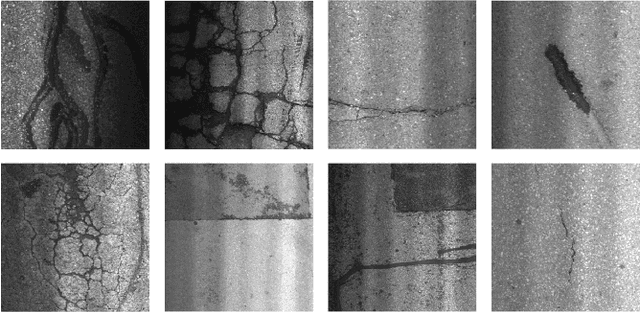
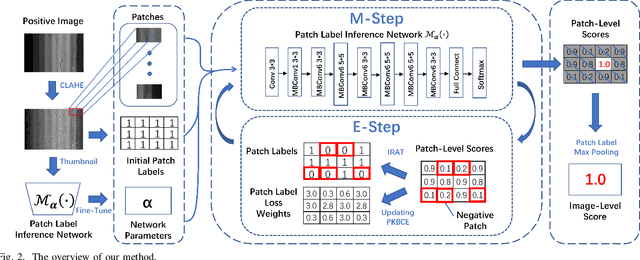
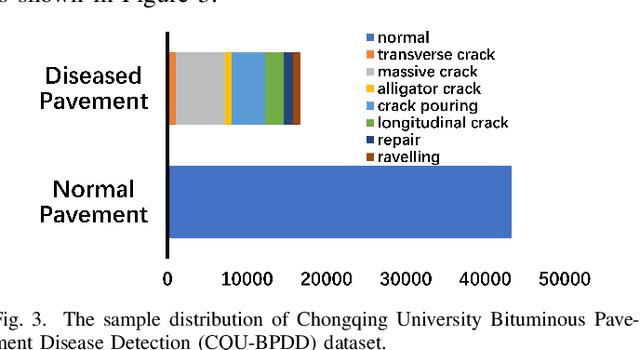
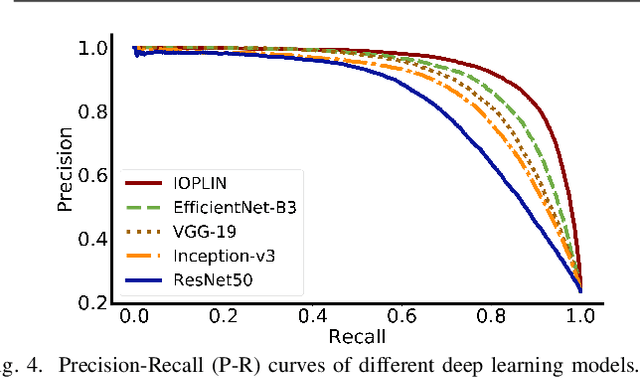
We present a novel deep learning framework named Iteratively Optimized Patch Label Inference Network (IOPLIN) for automatically detecting various pavement diseases not just limited to the specific ones, such as crack and pothole. IOPLIN can be iteratively trained with only the image label via using Expectation-Maximization Inspired Patch Label Distillation (EMIPLD) strategy, and accomplishes this task well by inferring the labels of patches from the pavement images. IOPLIN enjoys many desirable properties over the state-of-the-art single branch CNN models such as GoogLeNet and EfficientNet. It is able to handle any resolution of image and sufficiently utilize image information particularly for the high-resolution ones. Moreover, it can roughly localize the pavement distress without using any prior localization information in training phase. In order to better evaluate the effectiveness of our method in practice, we construct a large-scale Bituminous Pavement Disease Detection dataset named CQU-BPDD consists of 60059 high-resolution pavement images, which are acquired from different areas at different time. Extensive results on this dataset demonstrate the superiority of IOPLIN over the state-of-the-art image classificaiton approaches in automatic pavement disease detection.
NeMo: Neural Mesh Models of Contrastive Features for Robust 3D Pose Estimation
Feb 02, 2021
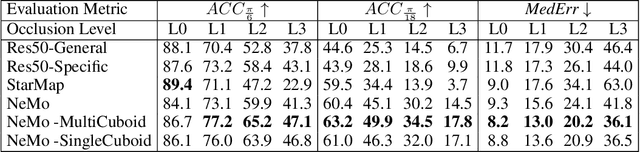
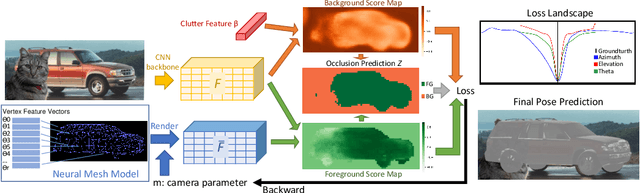

3D pose estimation is a challenging but important task in computer vision. In this work, we show that standard deep learning approaches to 3D pose estimation are not robust when objects are partially occluded or viewed from a previously unseen pose. Inspired by the robustness of generative vision models to partial occlusion, we propose to integrate deep neural networks with 3D generative representations of objects into a unified neural architecture that we term NeMo. In particular, NeMo learns a generative model of neural feature activations at each vertex on a dense 3D mesh. Using differentiable rendering we estimate the 3D object pose by minimizing the reconstruction error between NeMo and the feature representation of the target image. To avoid local optima in the reconstruction loss, we train the feature extractor to maximize the distance between the individual feature representations on the mesh using contrastive learning. Our extensive experiments on PASCAL3D+, occluded-PASCAL3D+ and ObjectNet3D show that NeMo is much more robust to partial occlusion and unseen pose compared to standard deep networks, while retaining competitive performance on regular data. Interestingly, our experiments also show that NeMo performs reasonably well even when the mesh representation only crudely approximates the true object geometry with a cuboid, hence revealing that the detailed 3D geometry is not needed for accurate 3D pose estimation. The code is publicly available at https://github.com/Angtian/NeMo.