 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Real-time Low-cost Artificial Intelligence System for Autonomous Spraying in Palm Plantations
Mar 06, 2021




In precision crop protection, (target-orientated) object detection in image processing can help navigate Unmanned Aerial Vehicles (UAV, crop protection drones) to the right place to apply the pesticide. Unnecessary application of non-target areas could be avoided. Deep learning algorithms dominantly use in modern computer vision tasks which require high computing time, memory footprint, and power consumption. Based on the Edge Artificial Intelligence, we investigate the main three paths that lead to dealing with this problem, including hardware accelerators, efficient algorithms, and model compression. Finally, we integrate them and propose a solution based on a light deep neural network (DNN), called Ag-YOLO, which can make the crop protection UAV have the ability to target detection and autonomous operation. This solution is restricted in size, cost, flexible, fast, and energy-effective. The hardware is only 18 grams in weight and 1.5 watts in energy consumption, and the developed DNN model needs only 838 kilobytes of disc space. We tested the developed hardware and software in comparison to the tiny version of the state-of-art YOLOv3 framework, known as YOLOv3-Tiny to detect individual palm in a plantation. An average F1 score of 0.9205 at the speed of 36.5 frames per second (in comparison to similar accuracy at 18 frames per second and 8.66 megabytes of the YOLOv3-Tiny algorithm) was reached. This developed detection system is easily plugged into any machines already purchased as long as the machines have USB ports and run Linux Operating System.
Human Expression Recognition using Facial Shape Based Fourier Descriptors Fusion
Dec 28, 2020Dynamic facial expression recognition has many useful applications in social networks, multimedia content analysis, security systems and others. This challenging process must be done under recurrent problems of image illumination and low resolution which changes at partial occlusions. This paper aims to produce a new facial expression recognition method based on the changes in the facial muscles. The geometric features are used to specify the facial regions i.e., mouth, eyes, and nose. The generic Fourier shape descriptor in conjunction with elliptic Fourier shape descriptor is used as an attribute to represent different emotions under frequency spectrum features. Afterwards a multi-class support vector machine is applied for classification of seven human expression. The statistical analysis showed our approach obtained overall competent recognition using 5-fold cross validation with high accuracy on well-known facial expression dataset.
Deep Feature Space Trojan Attack of Neural Networks by Controlled Detoxification
Dec 21, 2020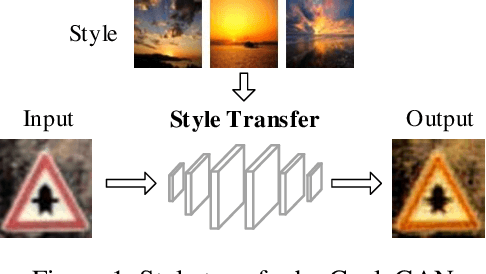
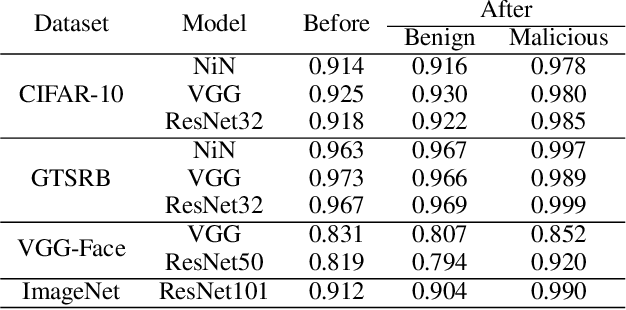
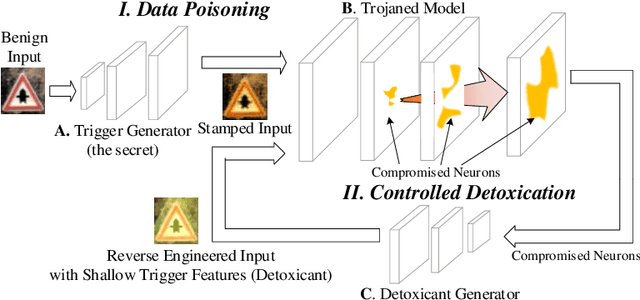
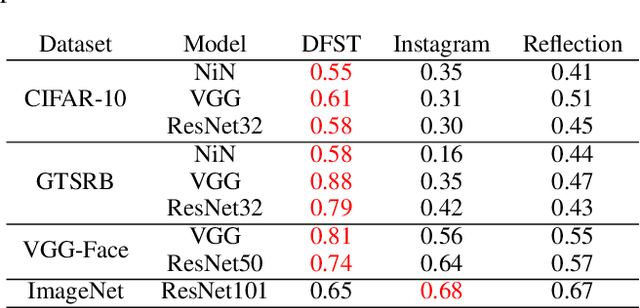
Trojan (backdoor) attack is a form of adversarial attack on deep neural networks where the attacker provides victims with a model trained/retrained on malicious data. The backdoor can be activated when a normal input is stamped with a certain pattern called trigger, causing misclassification. Many existing trojan attacks have their triggers being input space patches/objects (e.g., a polygon with solid color) or simple input transformations such as Instagram filters. These simple triggers are susceptible to recent backdoor detection algorithms. We propose a novel deep feature space trojan attack with five characteristics: effectiveness, stealthiness, controllability, robustness and reliance on deep features. We conduct extensive experiments on 9 image classifiers on various datasets including ImageNet to demonstrate these properties and show that our attack can evade state-of-the-art defense.
Ultimate Limits of Thermal Imaging
Oct 21, 2020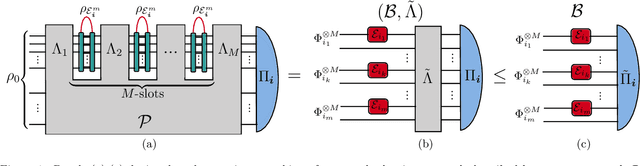
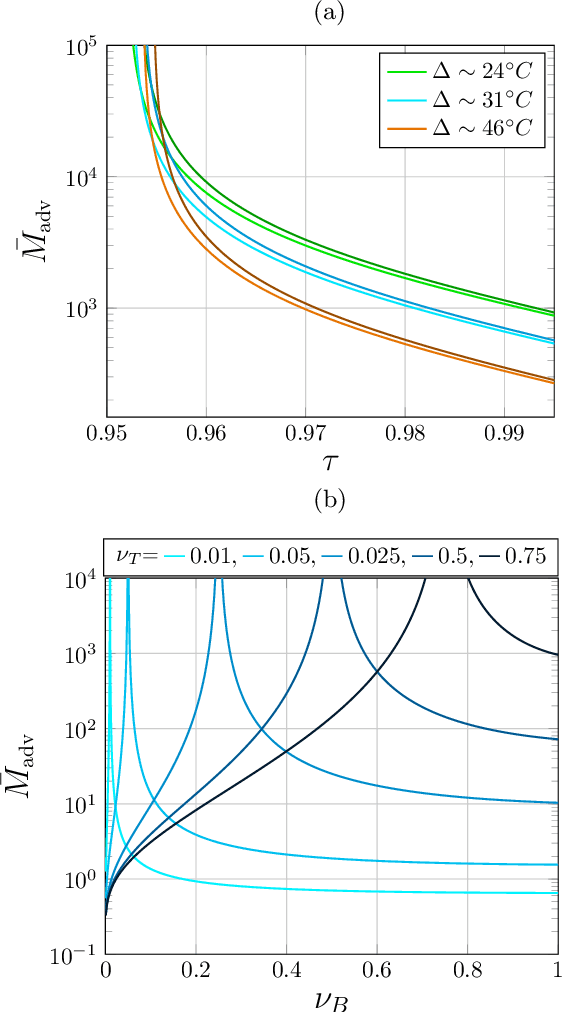
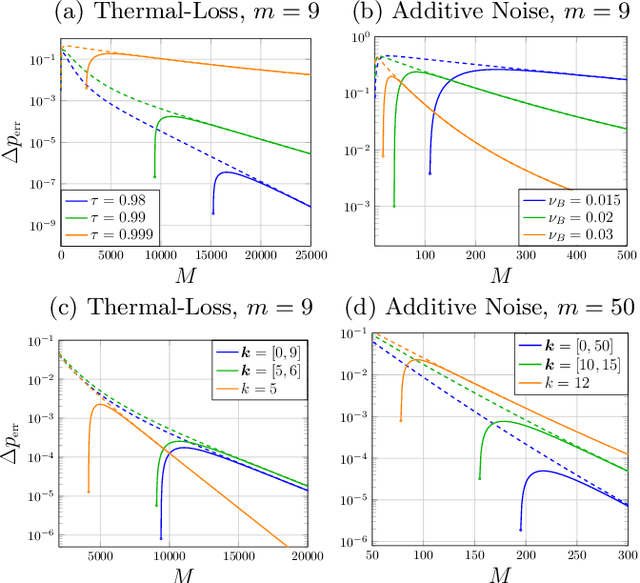

Quantum Channel Discrimination (QCD) presents a fundamental task in quantum information theory, with critical applications in quantum reading, illumination, data-readout and more. The extension to multiple quantum channel discrimination has seen a recent focus to characterise potential quantum advantage associated with quantum enhanced discriminatory protocols. In this paper, we study thermal imaging as an environment localisation task, in which thermal images are modelled as ensembles of Gaussian phase insensitive channels with identical transmissivity, and pixels possess properties according to background (cold) or target (warm) thermal channels. Via the teleportation stretching of adaptive quantum protocols, we derive ultimate limits on the precision of pattern classification of abstract, binary thermal image spaces, and show that quantum enhanced strategies may be used to provide significant quantum advantage over known optimal classical strategies. The environmental conditions and necessary resources for which advantage may be obtained are studied and discussed. We then numerically investigate the use of quantum enhanced statistical classifiers, in which quantum sensors are used in conjunction with machine learning image classification methods. Proving definitive advantage in the low loss regime, this work motivates the use of quantum enhanced sources for short-range thermal imaging and detection techniques for future quantum technologies.
Input Similarity from the Neural Network Perspective
Feb 10, 2021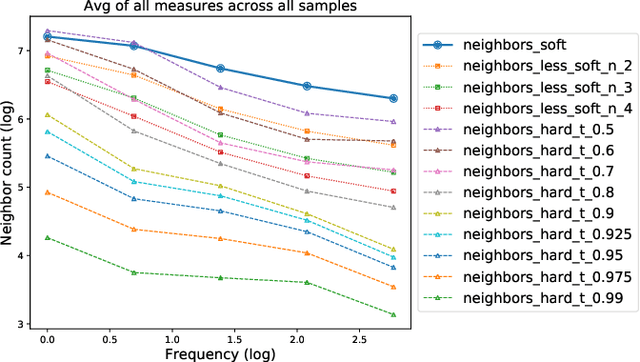
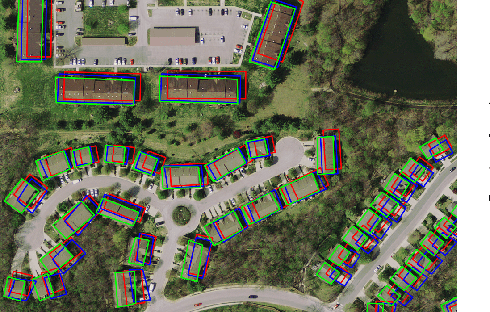
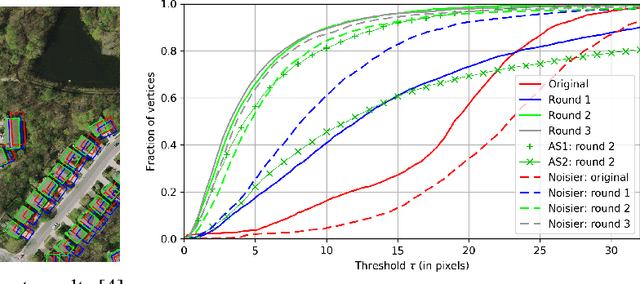

We first exhibit a multimodal image registration task, for which a neural network trained on a dataset with noisy labels reaches almost perfect accuracy, far beyond noise variance. This surprising auto-denoising phenomenon can be explained as a noise averaging effect over the labels of similar input examples. This effect theoretically grows with the number of similar examples; the question is then to define and estimate the similarity of examples. We express a proper definition of similarity, from the neural network perspective, i.e. we quantify how undissociable two inputs $A$ and $B$ are, taking a machine learning viewpoint: how much a parameter variation designed to change the output for $A$ would impact the output for $B$ as well? We study the mathematical properties of this similarity measure, and show how to use it on a trained network to estimate sample density, in low complexity, enabling new types of statistical analysis for neural networks. We analyze data by retrieving samples perceived as similar by the network, and are able to quantify the denoising effect without requiring true labels. We also propose, during training, to enforce that examples known to be similar should also be seen as similar by the network, and notice speed-up training effects for certain datasets.
Minority Reports Defense: Defending Against Adversarial Patches
Apr 28, 2020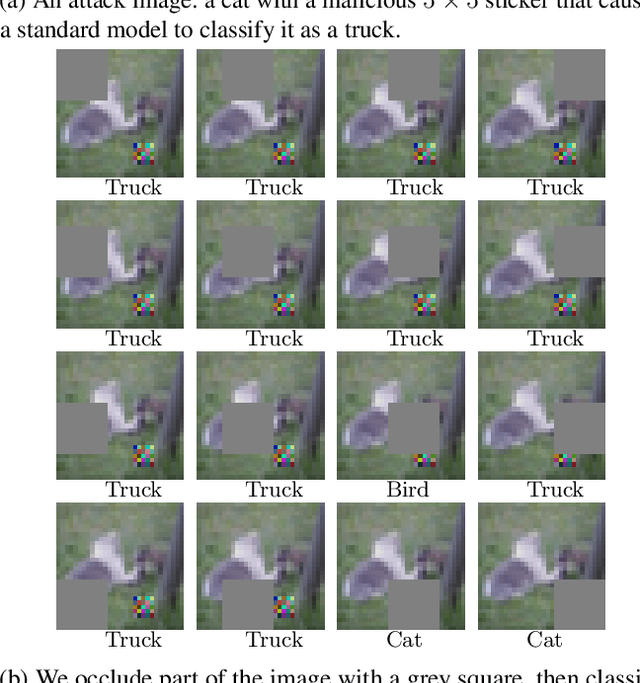
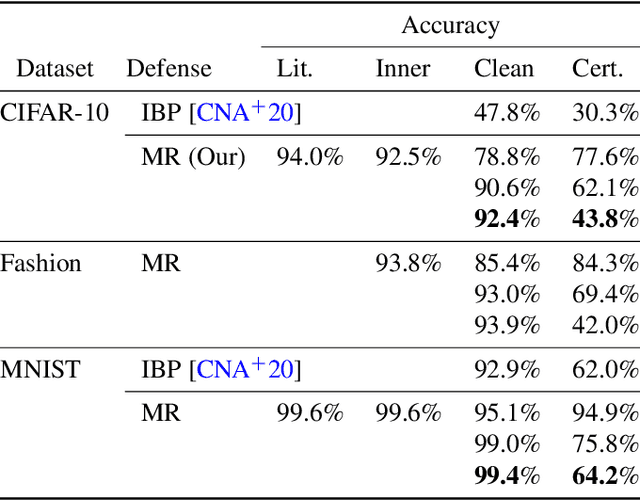
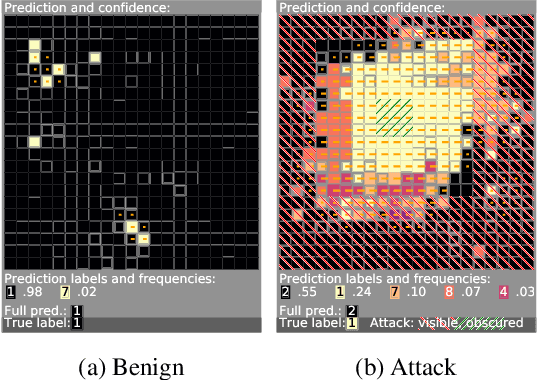
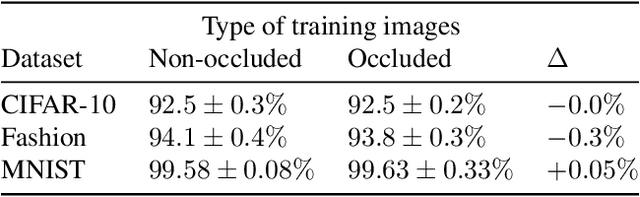
Deep learning image classification is vulnerable to adversarial attack, even if the attacker changes just a small patch of the image. We propose a defense against patch attacks based on partially occluding the image around each candidate patch location, so that a few occlusions each completely hide the patch. We demonstrate on CIFAR-10, Fashion MNIST, and MNIST that our defense provides certified security against patch attacks of a certain size.
Rethinking Semantic Segmentation Evaluation for Explainability and Model Selection
Jan 21, 2021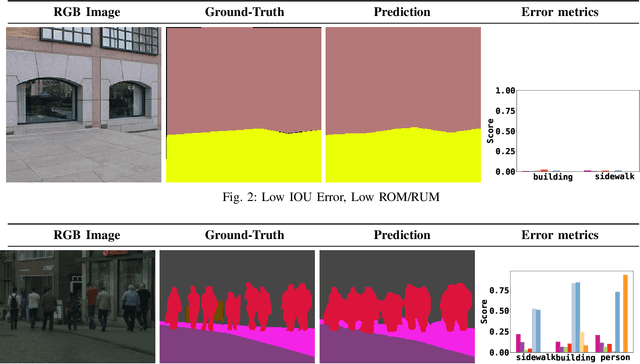
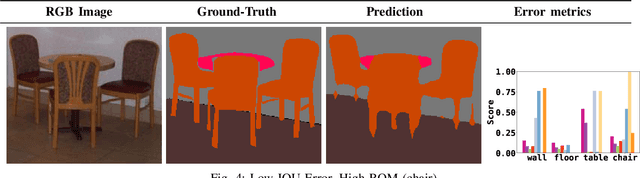
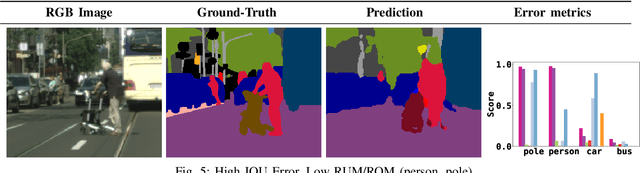

Semantic segmentation aims to robustly predict coherent class labels for entire regions of an image. It is a scene understanding task that powers real-world applications (e.g., autonomous navigation). One important application, the use of imagery for automated semantic understanding of pedestrian environments, provides remote mapping of accessibility features in street environments. This application (and others like it) require detailed geometric information of geographical objects. Semantic segmentation is a prerequisite for this task since it maps contiguous regions of the same class as single entities. Importantly, semantic segmentation uses like ours are not pixel-wise outcomes; however, most of their quantitative evaluation metrics (e.g., mean Intersection Over Union) are based on pixel-wise similarities to a ground-truth, which fails to emphasize over- and under-segmentation properties of a segmentation model. Here, we introduce a new metric to assess region-based over- and under-segmentation. We analyze and compare it to other metrics, demonstrating that the use of our metric lends greater explainability to semantic segmentation model performance in real-world applications.
Deep Learning Based Traffic Surveillance System For Missing and Suspicious Car Detection
Jul 17, 2020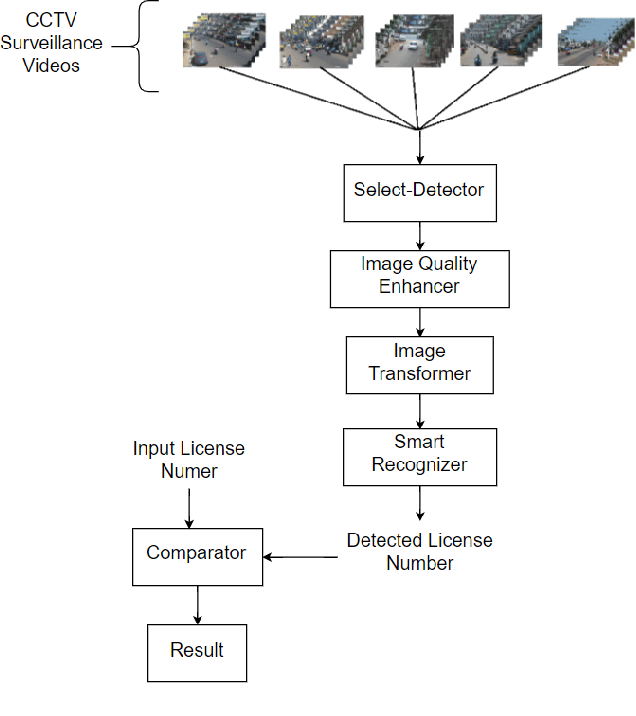


Vehicle theft is arguably one of the fastest-growing types of crime in India. In some of the urban areas, vehicle theft cases are believed to be around 100 each day. Identification of stolen vehicles in such precarious scenarios is not possible using traditional methods like manual checking and radio frequency identification(RFID) based technologies. This paper presents a deep learning based automatic traffic surveillance system for the detection of stolen/suspicious cars from the closed circuit television(CCTV) camera footage. It mainly comprises of four parts: Select-Detector, Image Quality Enhancer, Image Transformer, and Smart Recognizer. The Select-Detector is used for extracting the frames containing vehicles and to detect the license plates much efficiently with minimum time complexity. The quality of the license plates is then enhanced using Image Quality Enhancer which uses pix2pix generative adversarial network(GAN) for enhancing the license plates that are affected by temporal changes like low light, shadow, etc. Image Transformer is used to tackle the problem of inefficient recognition of license plates which are not horizontal(which are at an angle) by transforming the license plate to different levels of rotation and cropping. Smart Recognizer recognizes the license plate number using Tesseract optical character recognition(OCR) and corrects the wrongly recognized characters using Error-Detector. The effectiveness of the proposed approach is tested on the government's CCTV camera footage, which resulted in identifying the stolen/suspicious cars with an accuracy of 87%.
Exploring and Exploiting Diversity for Image Segmentation
Sep 05, 2017

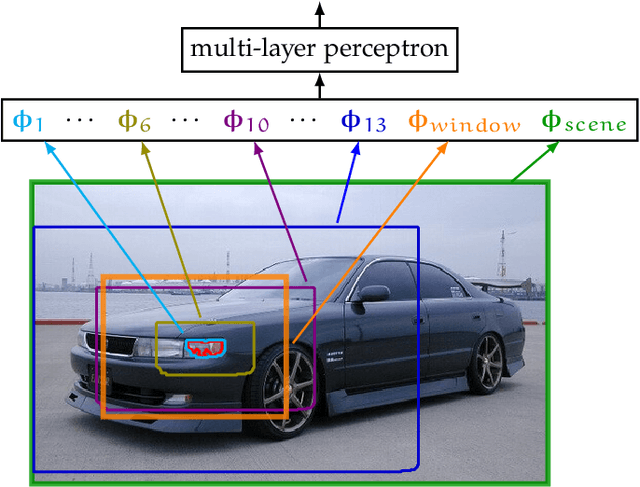

Semantic image segmentation is an important computer vision task that is difficult because it consists of both recognition and segmentation. The task is often cast as a structured output problem on an exponentially large output-space, which is typically modeled by a discrete probabilistic model. The best segmentation is found by inferring the Maximum a-Posteriori (MAP) solution over the output distribution defined by the model. Due to limitations in optimization, the model cannot be arbitrarily complex. This leads to a trade-off: devise a more accurate model that incorporates rich high-order interactions between image elements at the cost of inaccurate and possibly intractable optimization OR leverage a tractable model which produces less accurate MAP solutions but may contain high quality solutions as other modes of its output distribution. This thesis investigates the latter and presents a two stage approach to semantic segmentation. In the first stage a tractable segmentation model outputs a set of high probability segmentations from the underlying distribution that are not just minor perturbations of each other. Critically the output of this stage is a diverse set of plausible solutions and not just a single one. In the second stage, a discriminatively trained re-ranking model selects the best segmentation from this set. The re-ranking stage can use much more complex features than what could be tractably used in the segmentation model, allowing a better exploration of the solution space than simply returning the MAP solution. The formulation is agnostic to the underlying segmentation model (e.g. CRF, CNN, etc.) and optimization algorithm, which makes it applicable to a wide range of models and inference methods. Evaluation of the approach on a number of semantic image segmentation benchmark datasets highlight its superiority over inferring the MAP solution.
Direct Evolutionary Optimization of Variational Autoencoders With Binary Latents
Nov 27, 2020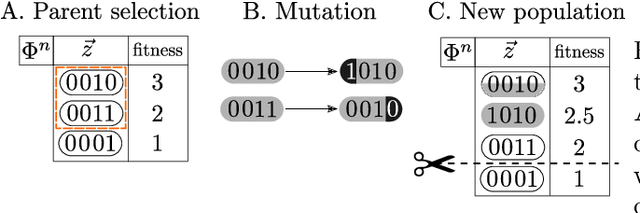

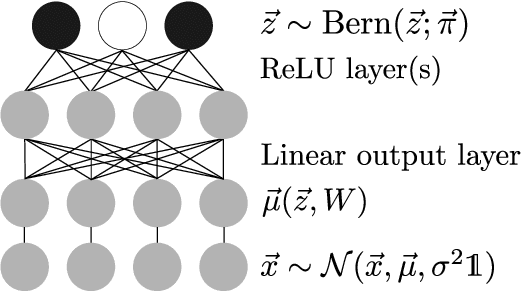
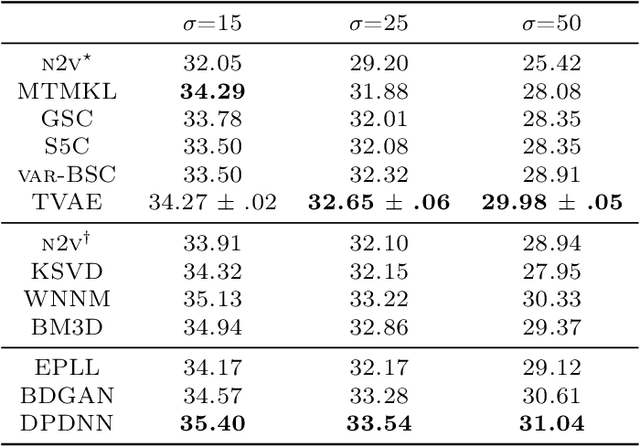
Discrete latent variables are considered important for real world data, which has motivated research on Variational Autoencoders (VAEs) with discrete latents. However, standard VAE-training is not possible in this case, which has motivated different strategies to manipulate discrete distributions in order to train discrete VAEs similarly to conventional ones. Here we ask if it is also possible to keep the discrete nature of the latents fully intact by applying a direct discrete optimization for the encoding model. The approach is consequently strongly diverting from standard VAE-training by sidestepping sampling approximation, reparameterization trick and amortization. Discrete optimization is realized in a variational setting using truncated posteriors in conjunction with evolutionary algorithms. For VAEs with binary latents, we (A) show how such a discrete variational method ties into gradient ascent for network weights, and (B) how the decoder is used to select latent states for training. Conventional amortized training is more efficient and applicable to large neural networks. However, using smaller networks, we here find direct discrete optimization to be efficiently scalable to hundreds of latents. More importantly, we find the effectiveness of direct optimization to be highly competitive in `zero-shot' learning. In contrast to large supervised networks, the here investigated VAEs can, e.g., denoise a single image without previous training on clean data and/or training on large image datasets. More generally, the studied approach shows that training of VAEs is indeed possible without sampling-based approximation and reparameterization, which may be interesting for the analysis of VAE-training in general. For `zero-shot' settings a direct optimization, furthermore, makes VAEs competitive where they have previously been outperformed by non-generative approaches.