 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Motion-blurred Video Interpolation and Extrapolation
Mar 10, 2021
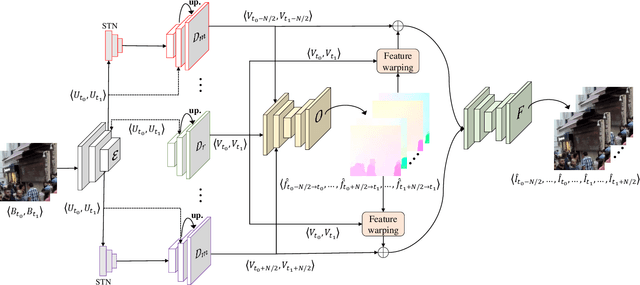
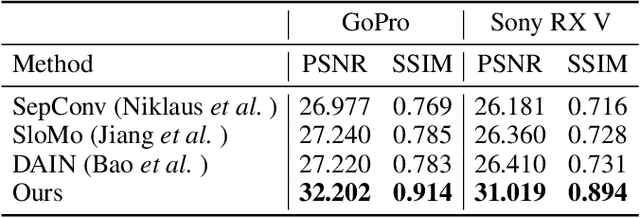

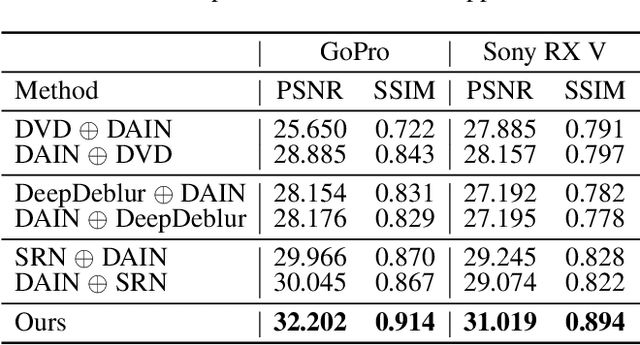
Abrupt motion of camera or objects in a scene result in a blurry video, and therefore recovering high quality video requires two types of enhancements: visual enhancement and temporal upsampling. A broad range of research attempted to recover clean frames from blurred image sequences or temporally upsample frames by interpolation, yet there are very limited studies handling both problems jointly. In this work, we present a novel framework for deblurring, interpolating and extrapolating sharp frames from a motion-blurred video in an end-to-end manner. We design our framework by first learning the pixel-level motion that caused the blur from the given inputs via optical flow estimation and then predict multiple clean frames by warping the decoded features with the estimated flows. To ensure temporal coherence across predicted frames and address potential temporal ambiguity, we propose a simple, yet effective flow-based rule. The effectiveness and favorability of our approach are highlighted through extensive qualitative and quantitative evaluations on motion-blurred datasets from high speed videos.
Color-Coded Symbology and New Computer Vision Tool to Predict the Historical Color Pallets of the Renaissance Oil Artworks
Feb 27, 2021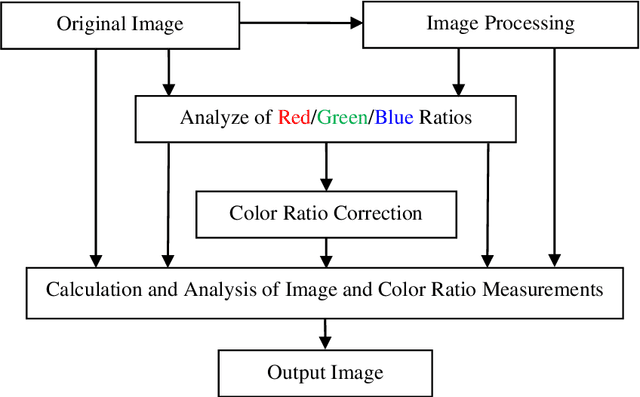
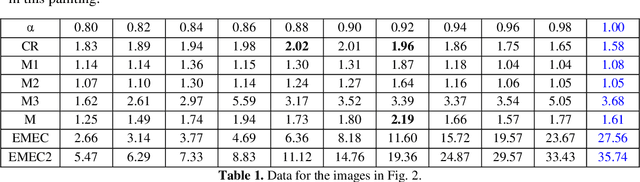

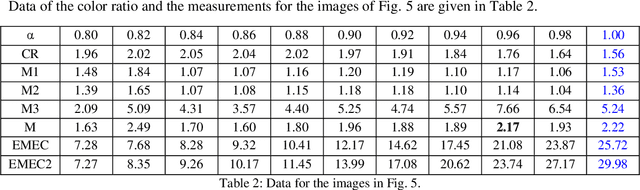
In this paper, we discuss possible color palletes, prediction and analysis of originality of the colors that Artists used on the Renaissance oil paintings. This framework goal is to help to use the color symbology and image enhancement tools, to predict the historical color palletes of the Renaissance oil artworks. This work is only the start of a development to explore the possibilities of prediction of color palletes of the Renaissance oil artworks. We believe that framework might be very useful in the prediction of color palletes of the Renaissance oil artworks and other artworks. The images in number 105 have been taken from the paintings of three well-known artists, Rafael, Leonardo Da Vinci, and Rembrandt that are available in the Olga's Gallery. Images are processed in the frequency domain to enhance a quality of images and ratios of primary colors are calculated and analyzed by using new measurements of color-ratios.
Monochrome and Color Polarization Demosaicking Using Edge-Aware Residual Interpolation
Jul 28, 2020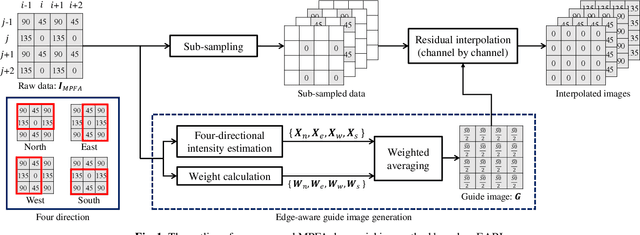
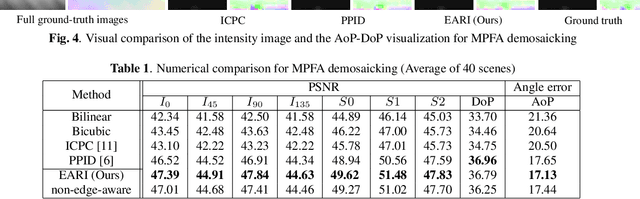
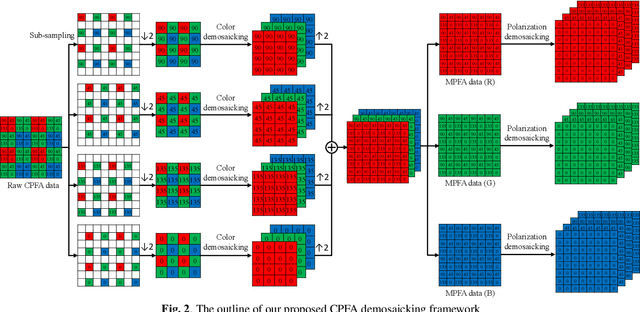
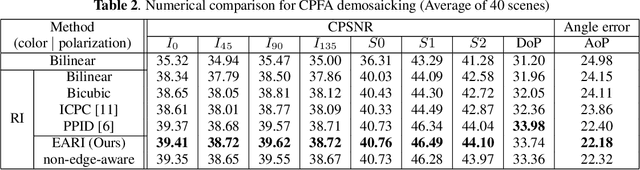
A division-of-focal-plane or microgrid image polarimeter enables us to acquire a set of polarization images in one shot. Since the polarimeter consists of an image sensor equipped with a monochrome or color polarization filter array (MPFA or CPFA), the demosaicking process to interpolate missing pixel values plays a crucial role in obtaining high-quality polarization images. In this paper, we propose a novel MPFA demosaicking method based on edge-aware residual interpolation (EARI) and also extend it to CPFA demosaicking. The key of EARI is a new edge detector for generating an effective guide image used to interpolate the missing pixel values. We also present a newly constructed full color-polarization image dataset captured using a 3-CCD camera and a rotating polarizer. Using the dataset, we experimentally demonstrate that our EARI-based method outperforms existing methods in MPFA and CPFA demosaicking.
Improving Visual Reasoning by Exploiting The Knowledge in Texts
Feb 09, 2021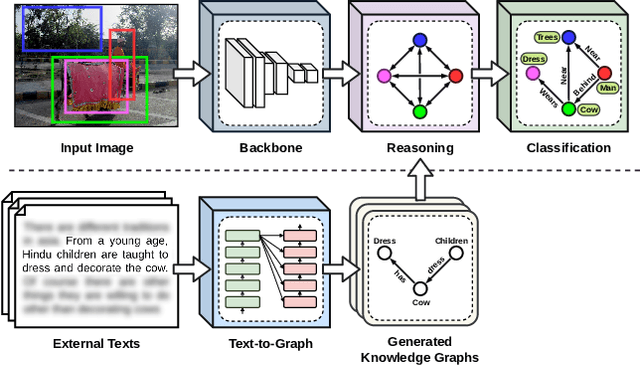

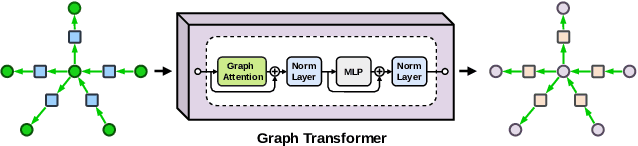
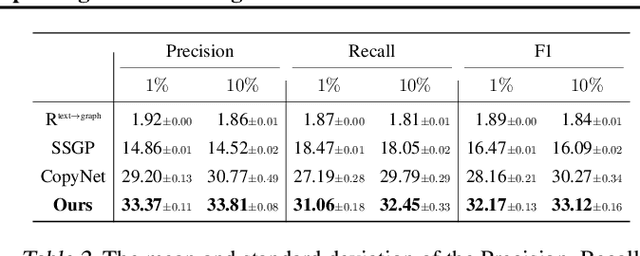
This paper presents a new framework for training image-based classifiers from a combination of texts and images with very few labels. We consider a classification framework with three modules: a backbone, a relational reasoning component, and a classification component. While the backbone can be trained from unlabeled images by self-supervised learning, we can fine-tune the relational reasoning and the classification components from external sources of knowledge instead of annotated images. By proposing a transformer-based model that creates structured knowledge from textual input, we enable the utilization of the knowledge in texts. We show that, compared to the supervised baselines with 1% of the annotated images, we can achieve ~8x more accurate results in scene graph classification, ~3x in object classification, and ~1.5x in predicate classification.
Image Captioning with Object Detection and Localization
Jun 08, 2017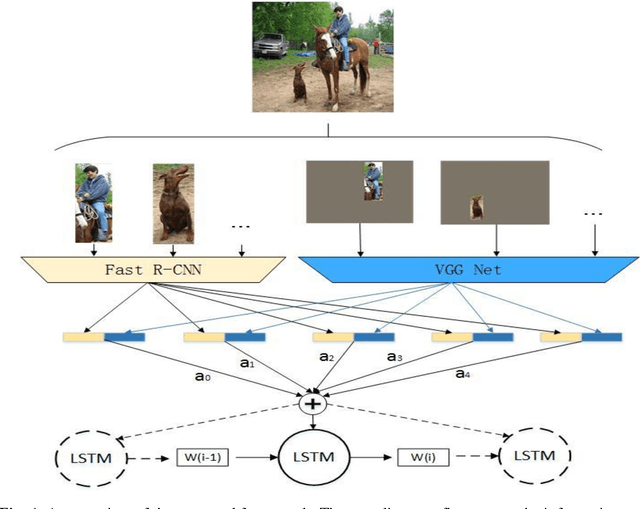
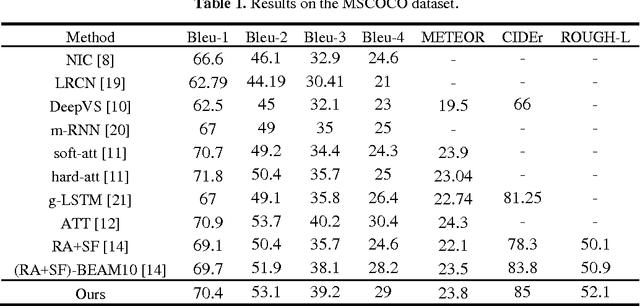


Automatically generating a natural language description of an image is a task close to the heart of image understanding. In this paper, we present a multi-model neural network method closely related to the human visual system that automatically learns to describe the content of images. Our model consists of two sub-models: an object detection and localization model, which extract the information of objects and their spatial relationship in images respectively; Besides, a deep recurrent neural network (RNN) based on long short-term memory (LSTM) units with attention mechanism for sentences generation. Each word of the description will be automatically aligned to different objects of the input image when it is generated. This is similar to the attention mechanism of the human visual system. Experimental results on the COCO dataset showcase the merit of the proposed method, which outperforms previous benchmark models.
Anchor Distance for 3D Multi-Object Distance Estimation from 2D Single Shot
Jan 25, 2021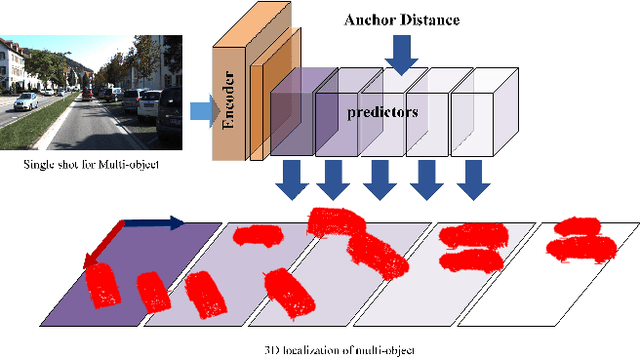
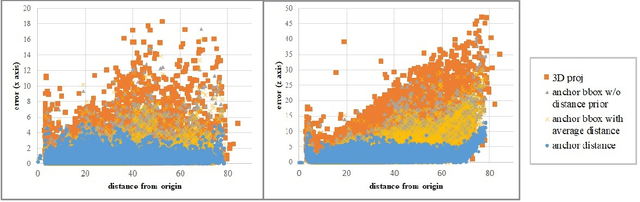
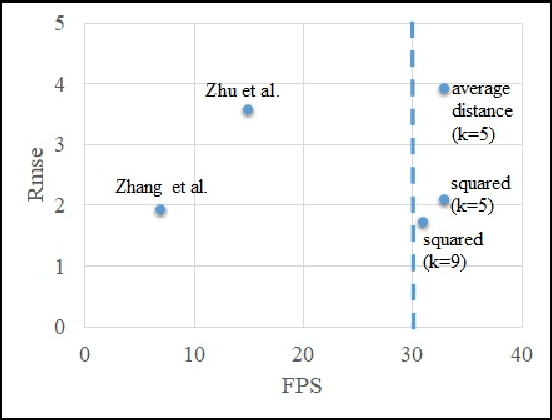
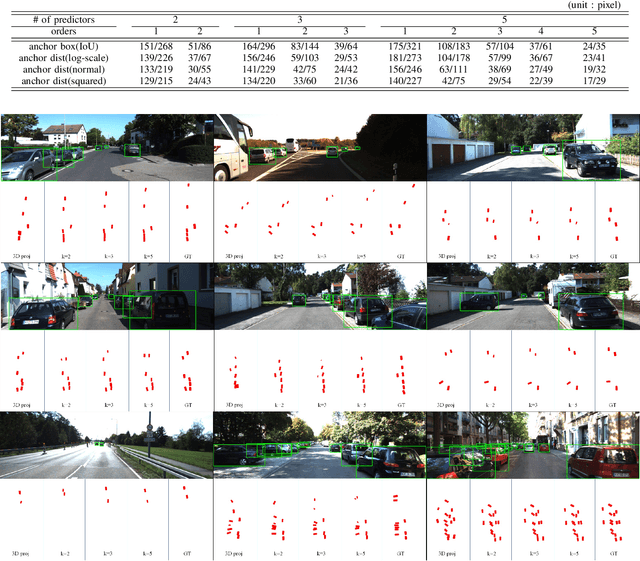
Visual perception of the objects in a 3D environment is a key to successful performance in autonomous driving and simultaneous localization and mapping (SLAM). In this paper, we present a real time approach for estimating the distances to multiple objects in a scene using only a single-shot image. Given a 2D Bounding Box (BBox) and object parameters, a 3D distance to the object can be calculated directly using 3D reprojection; however, such methods are prone to significant errors because an error from the 2D detection can be amplified in 3D. In addition, it is also challenging to apply such methods to a real-time system due to the computational burden. In the case of the traditional multi-object detection methods, %they mostly pay attention to existing works have been developed for specific tasks such as object segmentation or 2D BBox regression. These methods introduce the concept of anchor BBox for elaborate 2D BBox estimation, and predictors are specialized and trained for specific 2D BBoxes. In order to estimate the distances to the 3D objects from a single 2D image, we introduce the notion of \textit{anchor distance} based on an object's location and propose a method that applies the anchor distance to the multi-object detector structure. We let the predictors catch the distance prior using anchor distance and train the network based on the distance. The predictors can be characterized to the objects located in a specific distance range. By propagating the distance prior using a distance anchor to the predictors, it is feasible to perform the precise distance estimation and real-time execution simultaneously. The proposed method achieves about 30 FPS speed, and shows the lowest RMSE compared to the existing methods.
Joint Deformable Registration of Large EM Image Volumes: A Matrix Solver Approach
Apr 26, 2018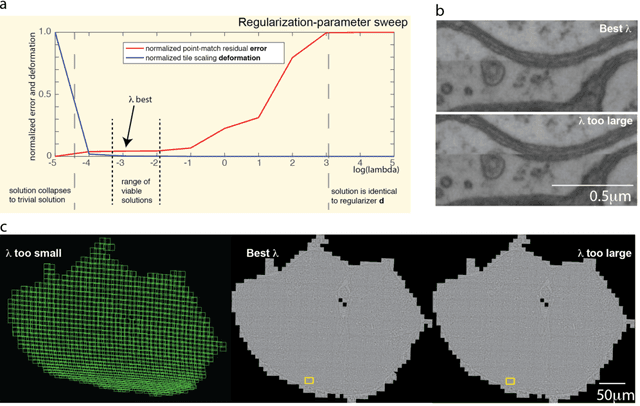
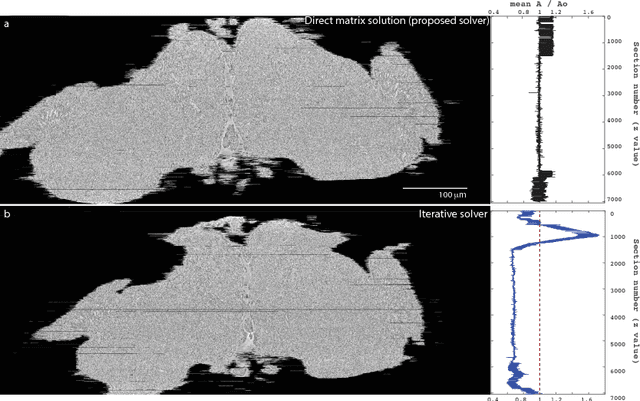
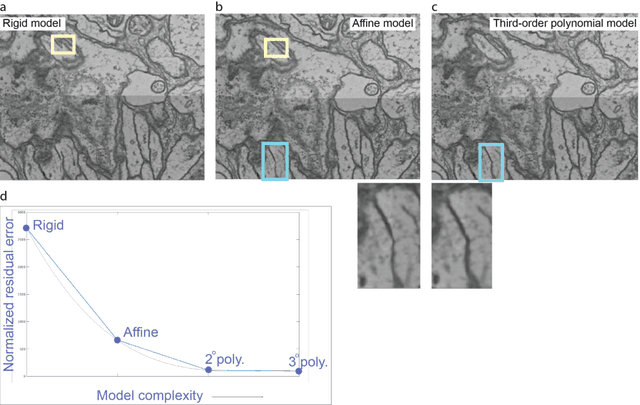
Large electron microscopy image datasets for connectomics are typically composed of thousands to millions of partially overlapping two-dimensional images (tiles), which must be registered into a coherent volume prior to further analysis. A common registration strategy is to find matching features between neighboring and overlapping image pairs, followed by a numerical estimation of optimal image deformation using a so-called solver program. Existing solvers are inadequate for large data volumes, and inefficient for small-scale image registration. In this work, an efficient and accurate matrix-based solver method is presented. A linear system is constructed that combines minimization of feature-pair square distances with explicit constraints in a regularization term. In absence of reliable priors for regularization, we show how to construct a rigid-model approximation to use as prior. The linear system is solved using available computer programs, whose performance on typical registration tasks we briefly compare, and to which future scale-up is delegated. Our method is applied to the joint alignment of 2.67 million images, with more than 200 million point-pairs and has been used for successfully aligning the first full adult fruit fly brain.
AutoDO: Robust AutoAugment for Biased Data with Label Noise via Scalable Probabilistic Implicit Differentiation
Mar 10, 2021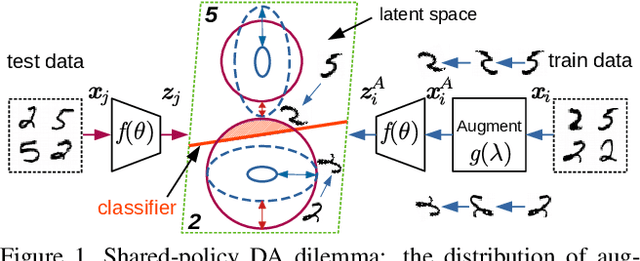
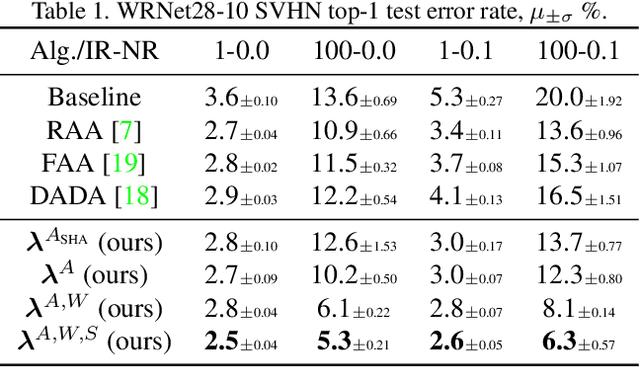

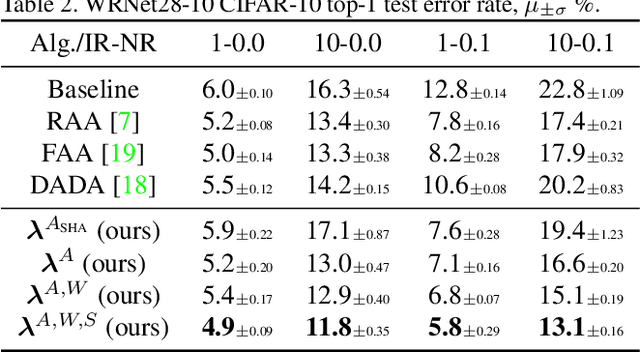
AutoAugment has sparked an interest in automated augmentation methods for deep learning models. These methods estimate image transformation policies for train data that improve generalization to test data. While recent papers evolved in the direction of decreasing policy search complexity, we show that those methods are not robust when applied to biased and noisy data. To overcome these limitations, we reformulate AutoAugment as a generalized automated dataset optimization (AutoDO) task that minimizes the distribution shift between test data and distorted train dataset. In our AutoDO model, we explicitly estimate a set of per-point hyperparameters to flexibly change distribution of train data. In particular, we include hyperparameters for augmentation, loss weights, and soft-labels that are jointly estimated using implicit differentiation. We develop a theoretical probabilistic interpretation of this framework using Fisher information and show that its complexity scales linearly with the dataset size. Our experiments on SVHN, CIFAR-10/100, and ImageNet classification show up to 9.3% improvement for biased datasets with label noise compared to prior methods and, importantly, up to 36.6% gain for underrepresented SVHN classes.
Learning Intrinsic Image Decomposition from Watching the World
Apr 02, 2018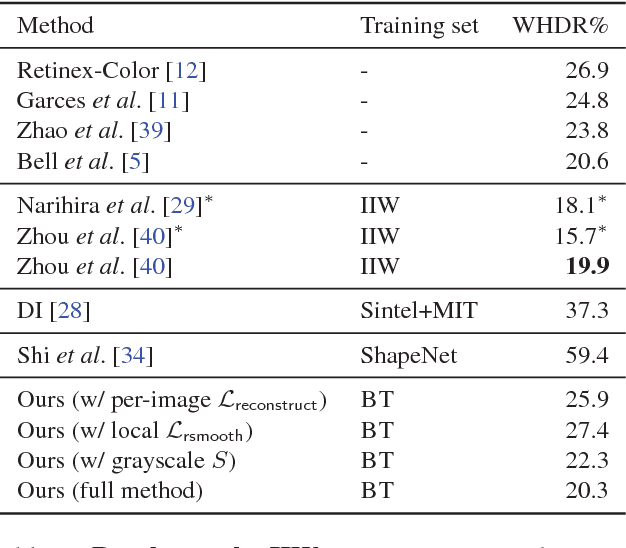
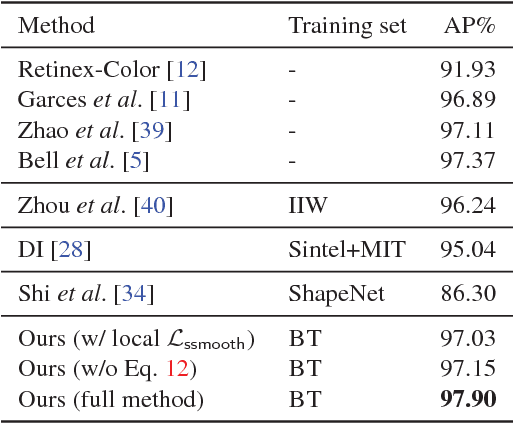


Single-view intrinsic image decomposition is a highly ill-posed problem, and so a promising approach is to learn from large amounts of data. However, it is difficult to collect ground truth training data at scale for intrinsic images. In this paper, we explore a different approach to learning intrinsic images: observing image sequences over time depicting the same scene under changing illumination, and learning single-view decompositions that are consistent with these changes. This approach allows us to learn without ground truth decompositions, and to instead exploit information available from multiple images when training. Our trained model can then be applied at test time to single views. We describe a new learning framework based on this idea, including new loss functions that can be efficiently evaluated over entire sequences. While prior learning-based methods achieve good performance on specific benchmarks, we show that our approach generalizes well to several diverse datasets, including MIT intrinsic images, Intrinsic Images in the Wild and Shading Annotations in the Wild.
Application of Facial Recognition using Convolutional Neural Networks for Entry Access Control
Nov 23, 2020
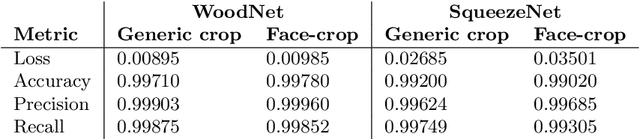
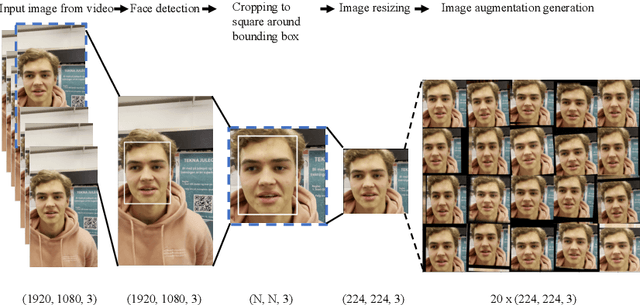
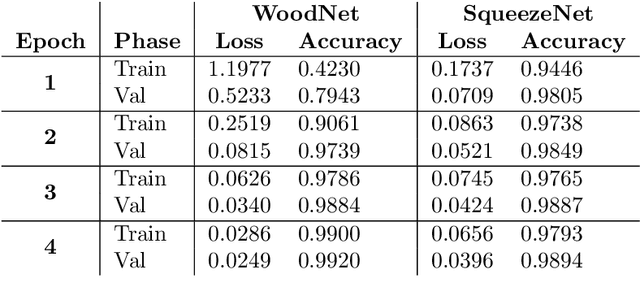
The purpose of this paper is to design a solution to the problem of facial recognition by use of convolutional neural networks, with the intention of applying the solution in a camera-based home-entry access control system. More specifically, the paper focuses on solving the supervised classification problem of taking images of people as input and classifying the person in the image as one of the authors or not. Two approaches are proposed: (1) building and training a neural network called WoodNet from scratch and (2) leveraging transfer learning by utilizing a network pre-trained on the ImageNet database and adapting it to this project's data and classes. In order to train the models to recognize the authors, a dataset containing more than 150 000 images has been created, balanced over the authors and others. Image extraction from videos and image augmentation techniques were instrumental for dataset creation. The results are two models classifying the individuals in the dataset with high accuracy, achieving over 99% accuracy on held-out test data. The pre-trained model fitted significantly faster than WoodNet, and seems to generalize better. However, these results come with a few caveats. Because of the way the dataset was compiled, as well as the high accuracy, one has reason to believe the models over-fitted to the data to some degree. An added consequence of the data compilation method is that the test dataset may not be sufficiently different from the training data, limiting its ability to validate generalization of the models. However, utilizing the models in a web-cam based system, classifying faces in real-time, shows promising results and indicates that the models generalized fairly well for at least some of the classes (see the accompanying video).