 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deformation Aware Image Compression
Apr 12, 2018

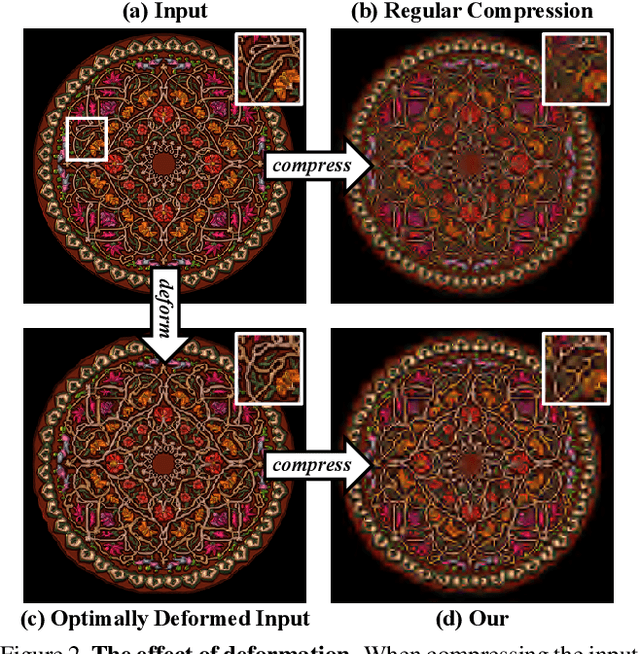

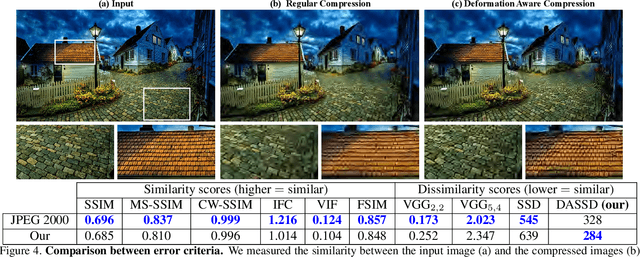
Lossy compression algorithms aim to compactly encode images in a way which enables to restore them with minimal error. We show that a key limitation of existing algorithms is that they rely on error measures that are extremely sensitive to geometric deformations (e.g. SSD, SSIM). These force the encoder to invest many bits in describing the exact geometry of every fine detail in the image, which is obviously wasteful, because the human visual system is indifferent to small local translations. Motivated by this observation, we propose a deformation-insensitive error measure that can be easily incorporated into any existing compression scheme. As we show, optimal compression under our criterion involves slightly deforming the input image such that it becomes more "compressible". Surprisingly, while these small deformations are barely noticeable, they enable the CODEC to preserve details that are otherwise completely lost. Our technique uses the CODEC as a "black box", thus allowing simple integration with arbitrary compression methods. Extensive experiments, including user studies, confirm that our approach significantly improves the visual quality of many CODECs. These include JPEG, JPEG2000, WebP, BPG, and a recent deep-net method.
NN2CAM: Automated Neural Network Mapping for Multi-Precision Edge Processing on FPGA-Based Cameras
Jun 24, 2021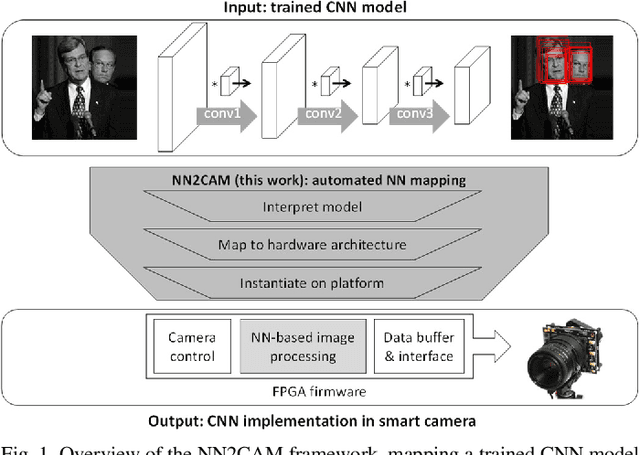
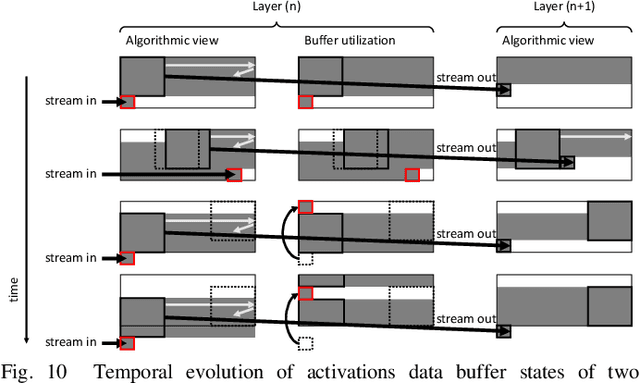
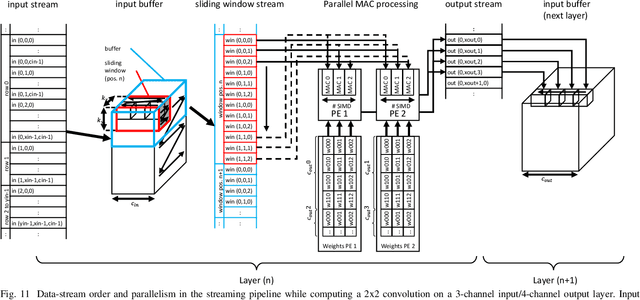

The record-breaking achievements of deep neural networks (DNNs) in image classification and detection tasks resulted in a surge of new computer vision applications during the past years. However, their computational complexity is restricting their deployment to powerful stationary or complex dedicated processing hardware, limiting their use in smart edge processing applications. We propose an automated deployment framework for DNN acceleration at the edge on field-programmable gate array (FPGA)-based cameras. The framework automatically converts an arbitrary-sized and quantized trained network into an efficient streaming-processing IP block that is instantiated within a generic adapter block in the FPGA. In contrast to prior work, the accelerator is purely logic and thus supports end-to-end processing on FPGAs without on-chip microprocessors. Our mapping tool features automatic translation from a trained Caffe network, arbitrary layer-wise fixed-point precision for both weights and activations, an efficient XNOR implementation for fully binary layers as well as a balancing mechanism for effective allocation of computational resources in the streaming dataflow. To present the performance of the system we employ this tool to implement two CNN edge processing networks on an FPGA-based high-speed camera with various precision settings showing computational throughputs of up to 337GOPS in low-latency streaming mode (no batching), running entirely on the camera.
Robust Domain-Free Domain Generalization with Class-aware Alignment
Feb 17, 2021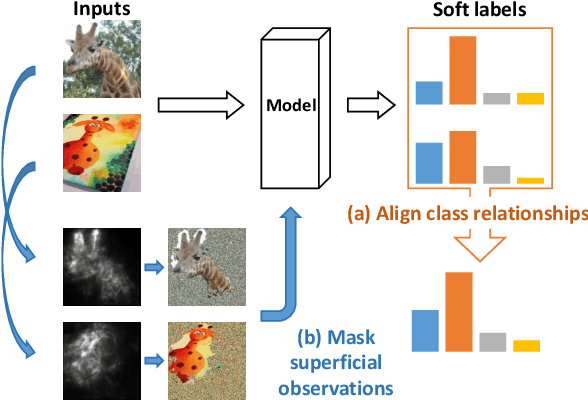
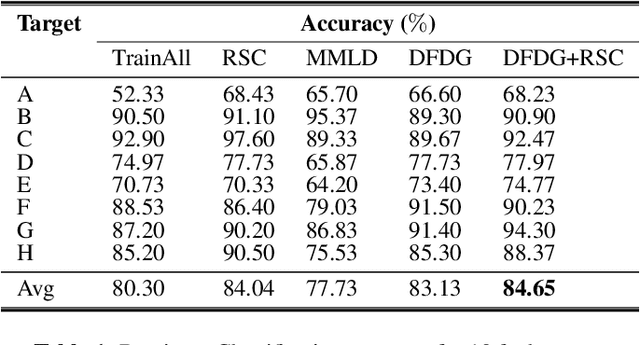
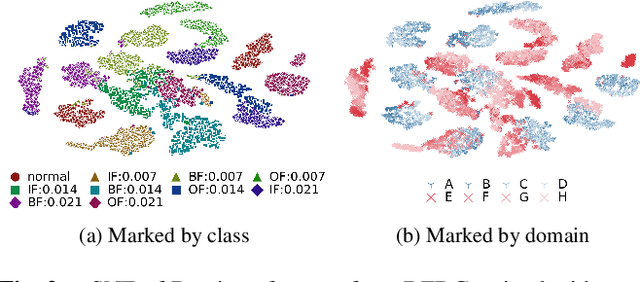
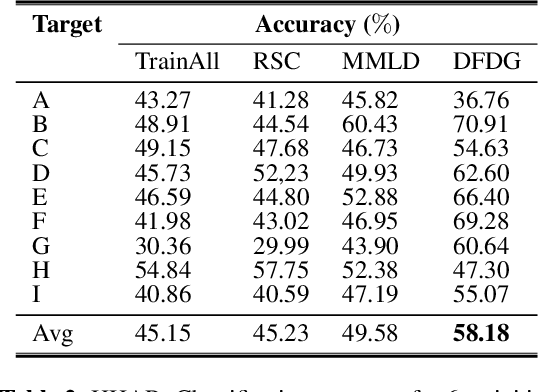
While deep neural networks demonstrate state-of-the-art performance on a variety of learning tasks, their performance relies on the assumption that train and test distributions are the same, which may not hold in real-world applications. Domain generalization addresses this issue by employing multiple source domains to build robust models that can generalize to unseen target domains subject to shifts in data distribution. In this paper, we propose Domain-Free Domain Generalization (DFDG), a model-agnostic method to achieve better generalization performance on the unseen test domain without the need for source domain labels. DFDG uses novel strategies to learn domain-invariant class-discriminative features. It aligns class relationships of samples through class-conditional soft labels, and uses saliency maps, traditionally developed for post-hoc analysis of image classification networks, to remove superficial observations from training inputs. DFDG obtains competitive performance on both time series sensor and image classification public datasets.
One-Pixel Attack Deceives Automatic Detection of Breast Cancer
Dec 16, 2020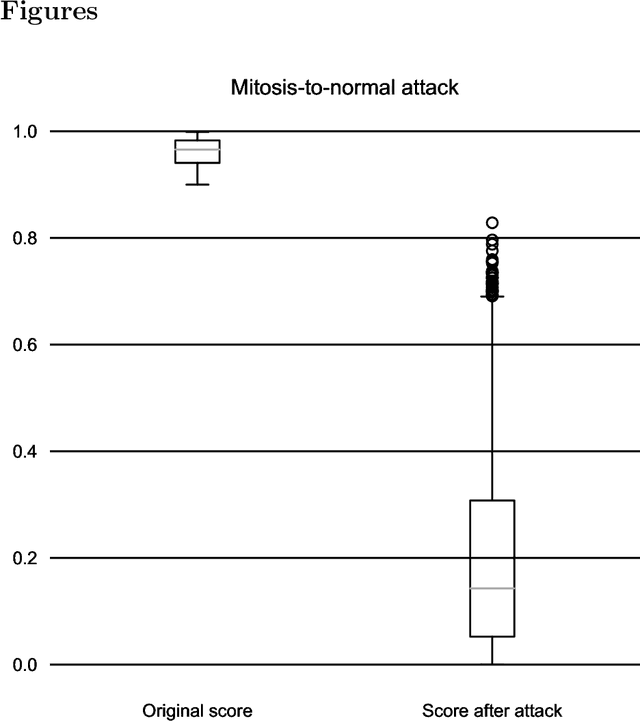
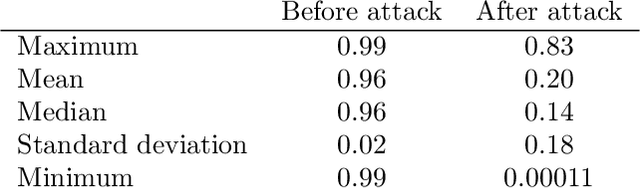
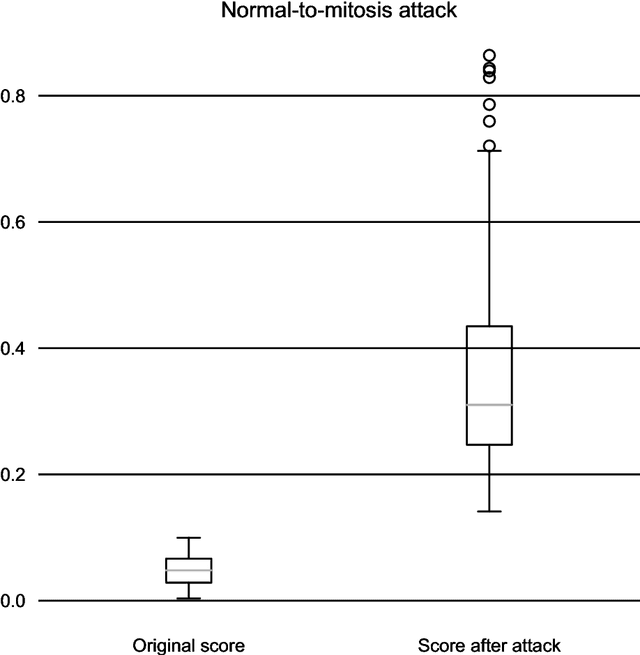
In this article we demonstrate that a state-of-the-art machine learning model predicting whether a whole slide image contains mitosis can be fooled by changing just a single pixel in the input image. Computer vision and machine learning can be used to automate various tasks in cancer diagnostic and detection. If an attacker can manipulate the automated processing, the results can be devastating and in the worst case lead to wrong diagnostic and treatments. In this research one-pixel attack is demonstrated in a real-life scenario with a real tumor dataset. The results indicate that a minor one-pixel modification of a whole slide image under analysis can affect the diagnosis. The attack poses a threat from the cyber security perspective: the one-pixel method can be used as an attack vector by a motivated attacker.
Synthesize-It-Classifier: Learning a Generative Classifier through RecurrentSelf-analysis
Mar 26, 2021
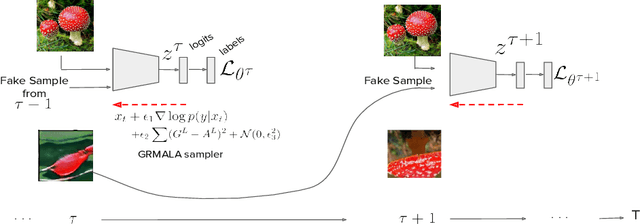


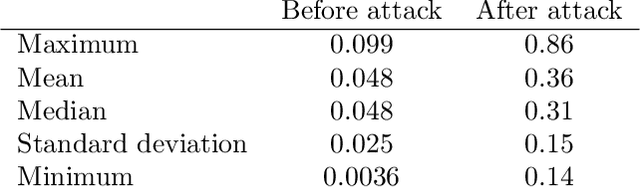
In this work, we show the generative capability of an image classifier network by synthesizing high-resolution, photo-realistic, and diverse images at scale. The overall methodology, called Synthesize-It-Classifier (STIC), does not require an explicit generator network to estimate the density of the data distribution and sample images from that, but instead uses the classifier's knowledge of the boundary to perform gradient ascent w.r.t. class logits and then synthesizes images using Gram Matrix Metropolis Adjusted Langevin Algorithm (GRMALA) by drawing on a blank canvas. During training, the classifier iteratively uses these synthesized images as fake samples and re-estimates the class boundary in a recurrent fashion to improve both the classification accuracy and quality of synthetic images. The STIC shows the mixing of the hard fake samples (i.e. those synthesized by the one hot class conditioning), and the soft fake samples (which are synthesized as a convex combination of classes, i.e. a mixup of classes) improves class interpolation. We demonstrate an Attentive-STIC network that shows an iterative drawing of synthesized images on the ImageNet dataset that has thousands of classes. In addition, we introduce the synthesis using a class conditional score classifier (Score-STIC) instead of a normal image classifier and show improved results on several real-world datasets, i.e. ImageNet, LSUN, and CIFAR 10.
Unsupervised 3D End-to-End Medical Image Registration with Volume Tweening Network
Feb 13, 2019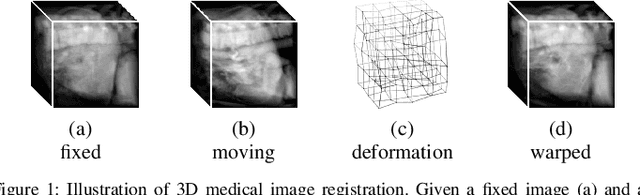
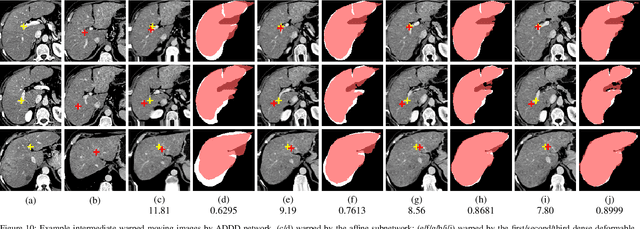
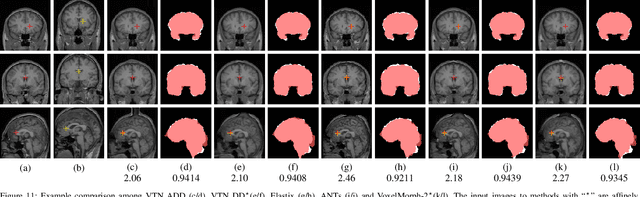
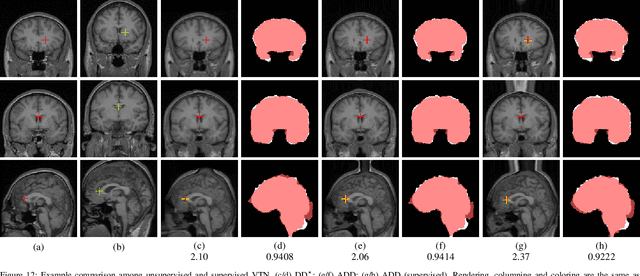
3D medical image registration is of great clinical importance. However, supervised learning methods require a large amount of accurately annotated corresponding control points (or morphing). The ground truth for 3D medical images is very difficult to obtain. Unsupervised learning methods ease the burden of manual annotation by exploiting unlabeled data without supervision. In this paper, we propose a new unsupervised learning method using convolutional neural networks under an end-to-end framework, Volume Tweening Network (VTN), to register 3D medical images. Three technical components ameliorate our unsupervised learning system for 3D end-to-end medical image registration: (1) We cascade the registration subnetworks; (2) We integrate affine registration into our network; and (3) We incorporate an additional invertibility loss into the training process. Experimental results demonstrate that our algorithm is 880x faster (or 3.3x faster without GPU acceleration) than traditional optimization-based methods and achieves state-of-the-art performance in medical image registration.
Weakly-Supervised Saliency Detection via Salient Object Subitizing
Jan 04, 2021
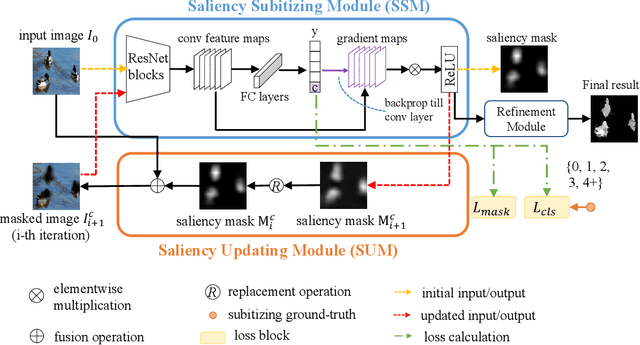

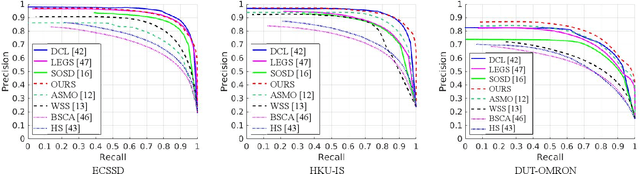
Salient object detection aims at detecting the most visually distinct objects and producing the corresponding masks. As the cost of pixel-level annotations is high, image tags are usually used as weak supervisions. However, an image tag can only be used to annotate one class of objects. In this paper, we introduce saliency subitizing as the weak supervision since it is class-agnostic. This allows the supervision to be aligned with the property of saliency detection, where the salient objects of an image could be from more than one class. To this end, we propose a model with two modules, Saliency Subitizing Module (SSM) and Saliency Updating Module (SUM). While SSM learns to generate the initial saliency masks using the subitizing information, without the need for any unsupervised methods or some random seeds, SUM helps iteratively refine the generated saliency masks. We conduct extensive experiments on five benchmark datasets. The experimental results show that our method outperforms other weakly-supervised methods and even performs comparably to some fully-supervised methods.
Image Classification Based on Quantum KNN Algorithm
May 16, 2018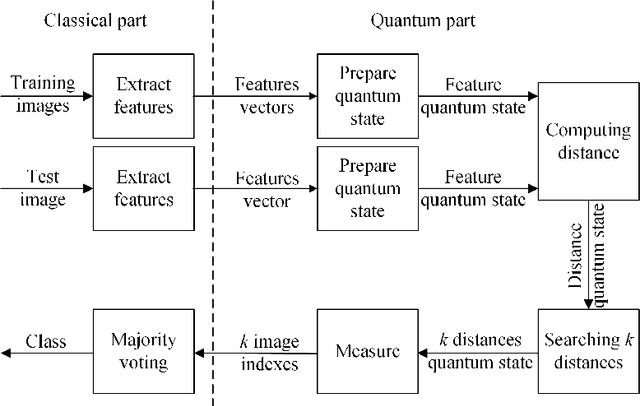
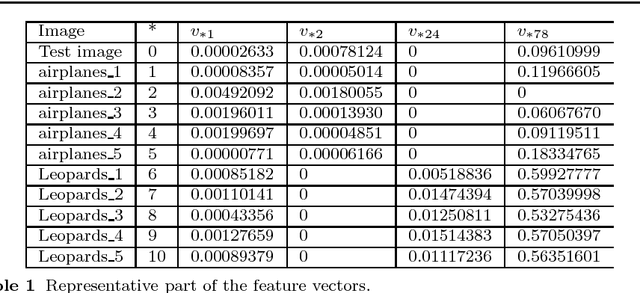
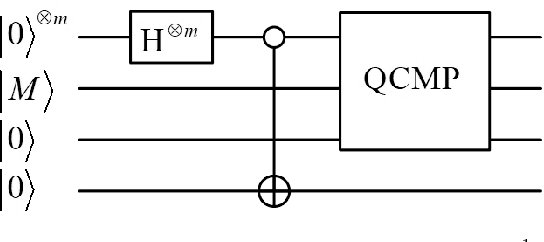
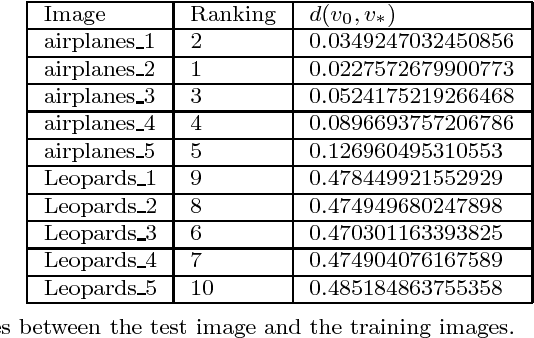
Image classification is an important task in the field of machine learning and image processing. However, the usually used classification method --- the K Nearest-Neighbor algorithm has high complexity, because its two main processes: similarity computing and searching are time-consuming. Especially in the era of big data, the problem is prominent when the amount of images to be classified is large. In this paper, we try to use the powerful parallel computing ability of quantum computers to optimize the efficiency of image classification. The scheme is based on quantum K Nearest-Neighbor algorithm. Firstly, the feature vectors of images are extracted on classical computers. Then the feature vectors are inputted into a quantum superposition state, which is used to achieve parallel computing of similarity. Next, the quantum minimum search algorithm is used to speed up searching process for similarity. Finally, the image is classified by quantum measurement. The complexity of the quantum algorithm is only O((kM)^(1/2)), which is superior to the classical algorithms. Moreover, the measurement step is executed only once to ensure the validity of the scheme. The experimental results show that, the classification accuracy is 83.1% on Graz-01 dataset and 78% on Caltech-101 dataset, which is close to existing classical algorithms. Hence, our quantum scheme has a good classification performance while greatly improving the efficiency.
Compressed Sensing, ASBSR-method of image sampling and reconstruction and the problem of digital image acquisition with the lowest possible sampling rate
Feb 28, 2018
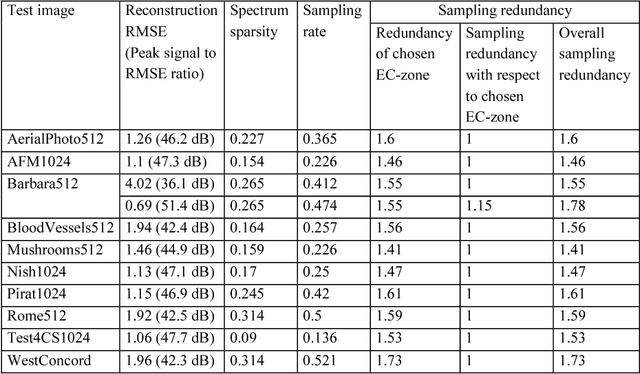
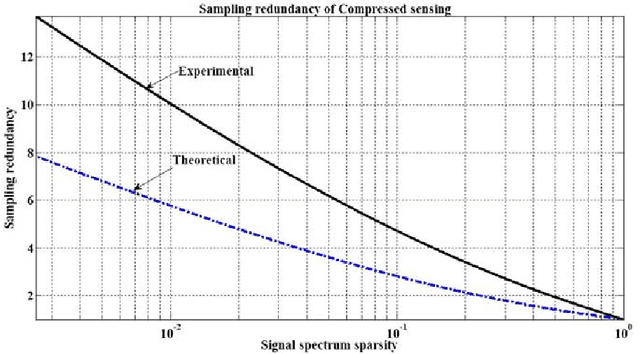
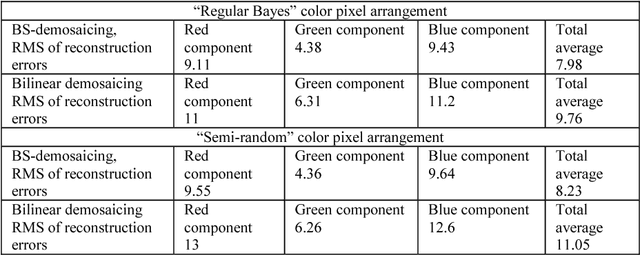
The problem of minimization of the number of measurements needed for digital image acquisition and reconstruction with a given accuracy is addressed. Basics of the sampling theory are outlined to show that the lower bound of signal sampling rate sufficient for signal reconstruction with a given accuracy is equal to the spectrum sparsity of the signal sparse approximation that has this accuracy. It is revealed that the compressed sensing approach, which was advanced as a solution to the sampling rate minimization problem, is far from reaching the sampling rate theoretical minimum. Potentials and limitations of compressed sensing are demystified using a simple and intutive model, A method of image Arbitrary Sampling and Bounded Spectrum Reconstruction (ASBSR-method) is described that allows to draw near the image sampling rate theoretical minimum. Presented and discussed are also results of experimental verification of the ASBSR-method and its possible applicability extensions to solving various underdetermined inverse problems such as color image demosaicing, image in-painting, image reconstruction from their sparsely sampled or decimated projections, image reconstruction from the modulus of its Fourier spectrum, and image reconstruction from its sparse samples in Fourier domain
* 28 pages, 19 figures
Maintaining Natural Image Statistics with the Contextual Loss
Jul 18, 2018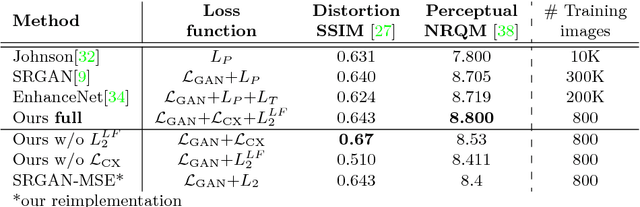
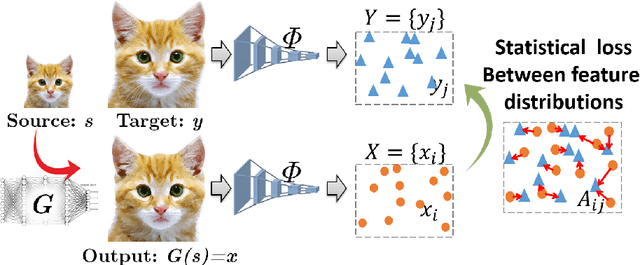

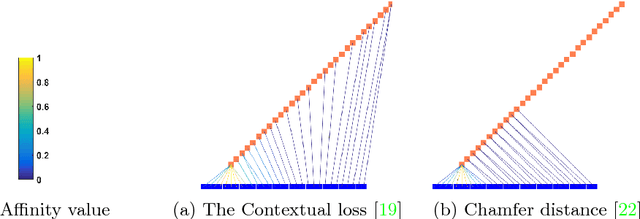
Maintaining natural image statistics is a crucial factor in restoration and generation of realistic looking images. When training CNNs, photorealism is usually attempted by adversarial training (GAN), that pushes the output images to lie on the manifold of natural images. GANs are very powerful, but not perfect. They are hard to train and the results still often suffer from artifacts. In this paper we propose a complementary approach, that could be applied with or without GAN, whose goal is to train a feed-forward CNN to maintain natural internal statistics. We look explicitly at the distribution of features in an image and train the network to generate images with natural feature distributions. Our approach reduces by orders of magnitude the number of images required for training and achieves state-of-the-art results on both single-image super-resolution, and high-resolution surface normal estimation.