 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Communication-Efficient Distributed Linear and Deep Generalized Canonical Correlation Analysis
Sep 25, 2021
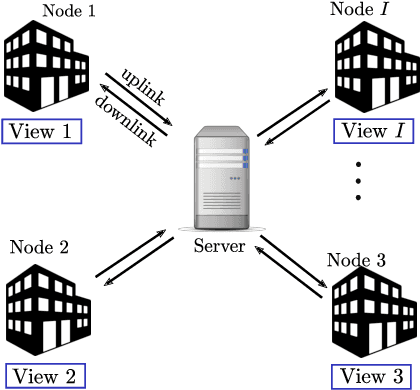
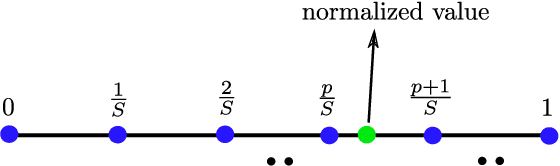
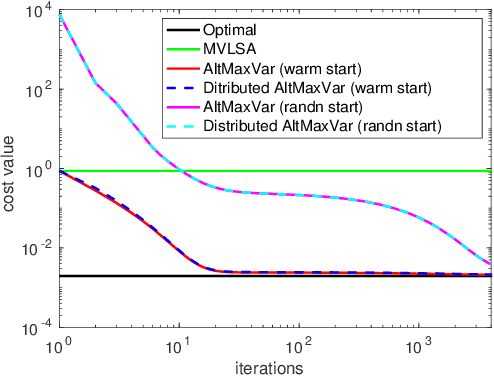
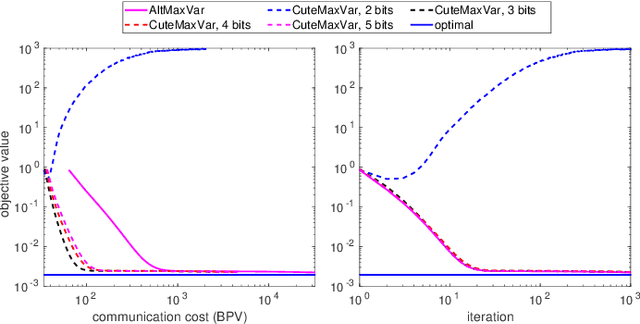
Classic and deep learning-based generalized canonical correlation analysis (GCCA) algorithms seek low-dimensional common representations of data entities from multiple ``views'' (e.g., audio and image) using linear transformations and neural networks, respectively. When the views are acquired and stored at different locations, organizations and edge devices, computing GCCA in a distributed, parallel and efficient manner is well-motivated. However, existing distributed GCCA algorithms may incur prohitively high communication overhead. This work puts forth a communication-efficient distributed framework for both linear and deep GCCA under the maximum variance (MAX-VAR) paradigm. The overhead issue is addressed by aggressively compressing (via quantization) the exchanging information between the distributed computing agents and a central controller. Compared to the unquantized version, the proposed algorithm consistently reduces the communication overhead by about $90\%$ with virtually no loss in accuracy and convergence speed. Rigorous convergence analyses are also presented -- which is a nontrivial effort since no existing generic result from quantized distributed optimization covers the special problem structure of GCCA. Our result shows that the proposed algorithms for both linear and deep GCCA converge to critical points in a sublinear rate, even under heavy quantization and stochastic approximations. In addition, it is shown that in the linear MAX-VAR case, the quantized algorithm approaches a {\it global optimum} in a {\it geometric} rate -- if the computing agents' updates meet a certain accuracy level. Synthetic and real data experiments are used to showcase the effectiveness of the proposed approach.
Exploring to establish an appropriate model for image aesthetic assessment via CNN-based RSRL: An empirical study
Jun 28, 2021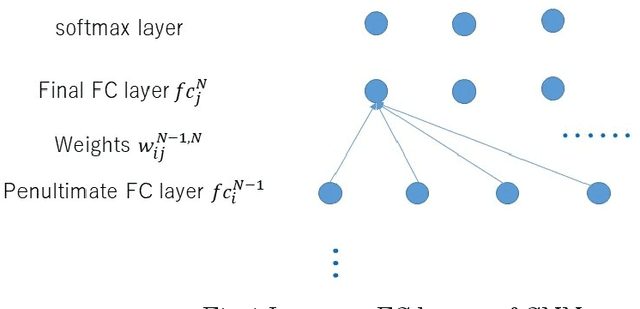

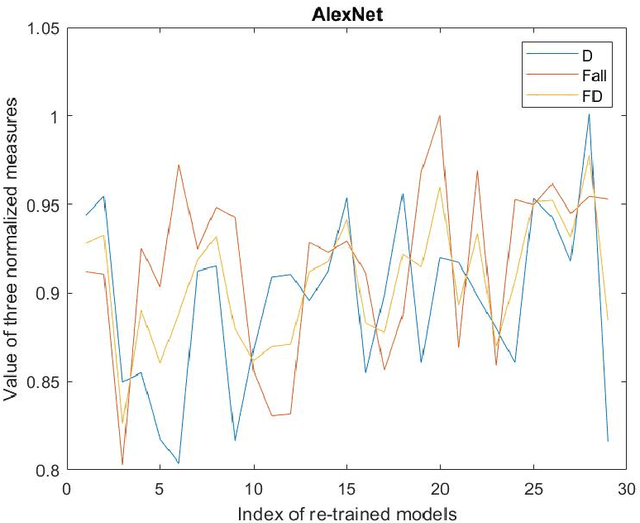
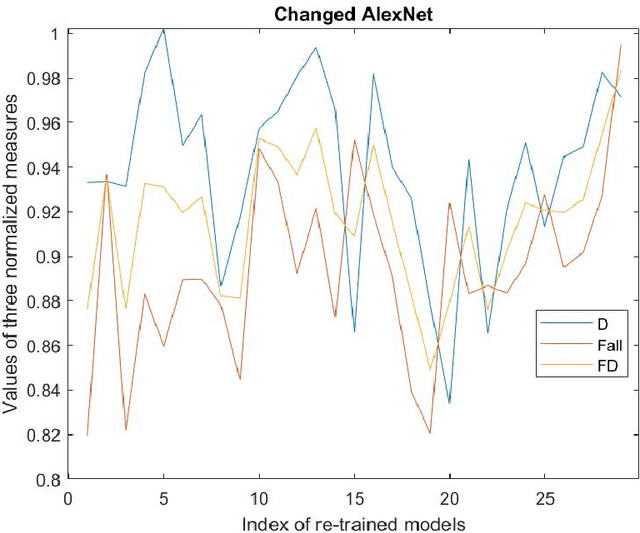
To establish an appropriate model for photo aesthetic assessment, in this paper, a D-measure which reflects the disentanglement degree of the final layer FC nodes of CNN is introduced. By combining F-measure with D-measure to obtain a FD measure, an algorithm of determining the optimal model from the multiple photo score prediction models generated by CNN-based repetitively self-revised learning(RSRL) is proposed. Furthermore, the first fixation perspective(FFP) and the assessment interest region(AIR) of the models are defined and calculated. The experimental results show that the FD measure is effective for establishing the appropriate model from the multiple score prediction models with different CNN structures. Moreover, the FD-determined optimal models with the comparatively high FD always have the FFP an AIR which are close to the human's aesthetic perception when enjoying photos.
Facial Manipulation Detection Based on the Color Distribution Analysis in Edge Region
Feb 02, 2021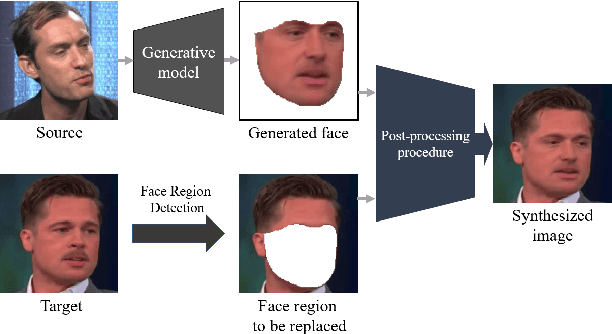
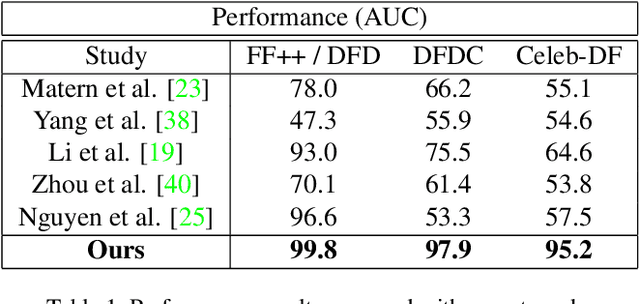

In this work, we present a generalized and robust facial manipulation detection method based on color distribution analysis of the vertical region of edge in a manipulated image. Most of the contemporary facial manipulation method involves pixel correction procedures for reducing awkwardness of pixel value differences along the facial boundary in a synthesized image. For this procedure, there are distinctive differences in the facial boundary between face manipulated image and unforged natural image. Also, in the forged image, there should be distinctive and unnatural features in the gap distribution between facial boundary and background edge region because it tends to damage the natural effect of lighting. We design the neural network for detecting face-manipulated image with these distinctive features in facial boundary and background edge. Our extensive experiments show that our method outperforms other existing face manipulation detection methods on detecting synthesized face image in various datasets regardless of whether it has participated in training.
Improving Few-shot Learning with Weakly-supervised Object Localization
May 25, 2021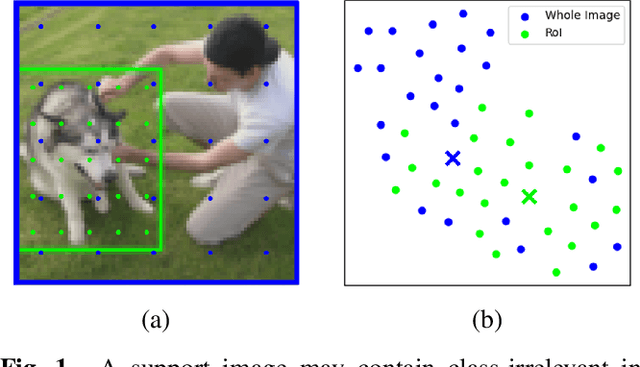
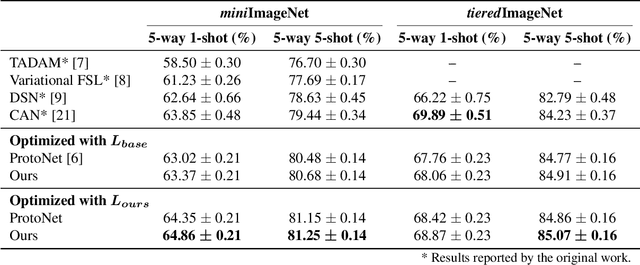
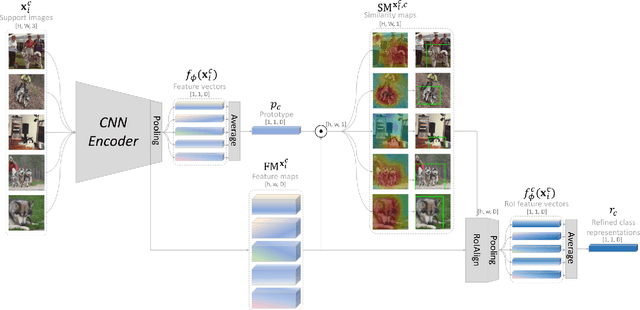

Few-shot learning often involves metric learning-based classifiers, which predict the image label by comparing the distance between the extracted feature vector and class representations. However, applying global pooling in the backend of the feature extractor may not produce an embedding that correctly focuses on the class object. In this work, we propose a novel framework that generates class representations by extracting features from class-relevant regions of the images. Given only a few exemplary images with image-level labels, our framework first localizes the class objects by spatially decomposing the similarity between the images and their class prototypes. Then, enhanced class representations are achieved from the localization results. We also propose a loss function to enhance distinctions of the refined features. Our method outperforms the baseline few-shot model in miniImageNet and tieredImageNet benchmarks.
Learning to Ground Visual Objects for Visual Dialog
Sep 13, 2021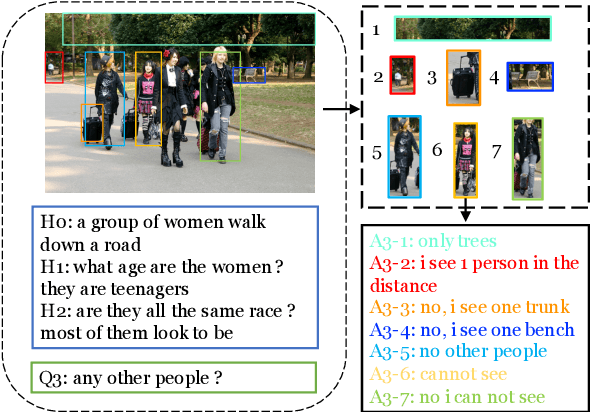
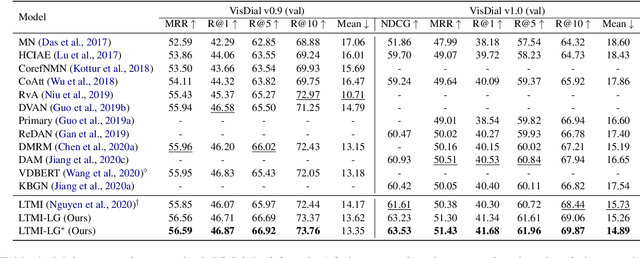
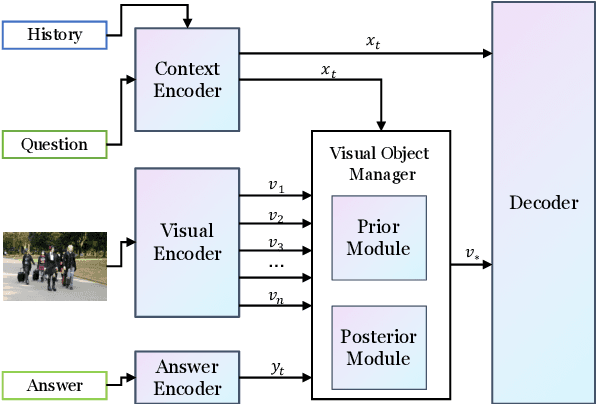
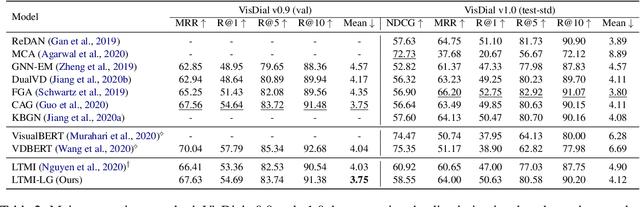
Visual dialog is challenging since it needs to answer a series of coherent questions based on understanding the visual environment. How to ground related visual objects is one of the key problems. Previous studies utilize the question and history to attend to the image and achieve satisfactory performance, however these methods are not sufficient to locate related visual objects without any guidance. The inappropriate grounding of visual objects prohibits the performance of visual dialog models. In this paper, we propose a novel approach to Learn to Ground visual objects for visual dialog, which employs a novel visual objects grounding mechanism where both prior and posterior distributions over visual objects are used to facilitate visual objects grounding. Specifically, a posterior distribution over visual objects is inferred from both context (history and questions) and answers, and it ensures the appropriate grounding of visual objects during the training process. Meanwhile, a prior distribution, which is inferred from context only, is used to approximate the posterior distribution so that appropriate visual objects can be grounded even without answers during the inference process. Experimental results on the VisDial v0.9 and v1.0 datasets demonstrate that our approach improves the previous strong models in both generative and discriminative settings by a significant margin.
Scale-invariant scale-channel networks: Deep networks that generalise to previously unseen scales
Jun 11, 2021
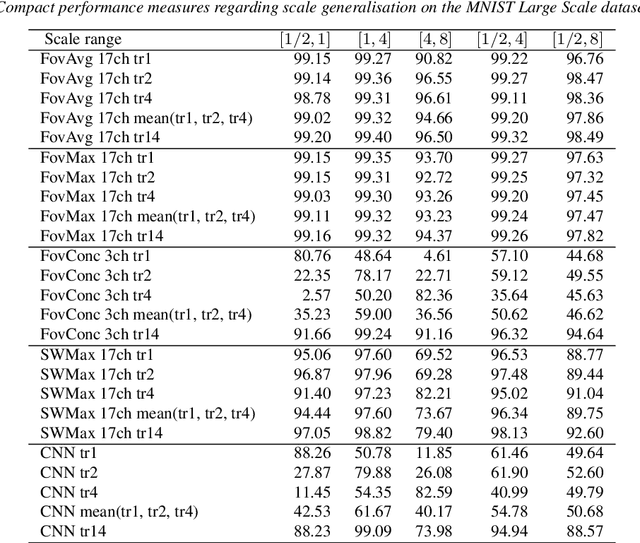
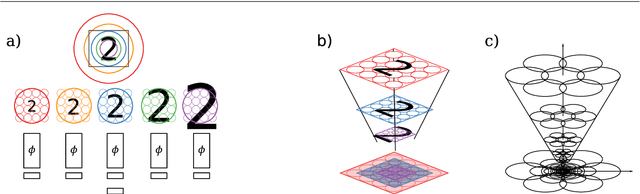

The ability to handle large scale variations is crucial for many real world visual tasks. A straightforward approach for handling scale in a deep network is to process an image at several scales simultaneously in a set of scale channels. Scale invariance can then, in principle, be achieved by using weight sharing between the scale channels together with max or average pooling over the outputs from the scale channels. The ability of such scale channel networks to generalise to scales not present in the training set over significant scale ranges has, however, not previously been explored. In this paper, we present a systematic study of this methodology by implementing different types of scale channel networks and evaluating their ability to generalise to previously unseen scales. We develop a formalism for analysing the covariance and invariance properties of scale channel networks, and explore how different design choices, unique to scaling transformations, affect the overall performance of scale channel networks. We first show that two previously proposed scale channel network designs do not generalise well to scales not present in the training set. We explain theoretically and demonstrate experimentally why generalisation fails in these cases. We then propose a new type of foveated scale channel architecture}, where the scale channels process increasingly larger parts of the image with decreasing resolution. This new type of scale channel network is shown to generalise extremely well, provided sufficient image resolution and the absence of boundary effects. Our proposed FovMax and FovAvg networks perform almost identically over a scale range of 8, also when training on single scale training data, and do also give improved performance when learning from datasets with large scale variations in the small sample regime.
BEV-MODNet: Monocular Camera based Bird's Eye View Moving Object Detection for Autonomous Driving
Jul 11, 2021



Detection of moving objects is a very important task in autonomous driving systems. After the perception phase, motion planning is typically performed in Bird's Eye View (BEV) space. This would require projection of objects detected on the image plane to top view BEV plane. Such a projection is prone to errors due to lack of depth information and noisy mapping in far away areas. CNNs can leverage the global context in the scene to project better. In this work, we explore end-to-end Moving Object Detection (MOD) on the BEV map directly using monocular images as input. To the best of our knowledge, such a dataset does not exist and we create an extended KITTI-raw dataset consisting of 12.9k images with annotations of moving object masks in BEV space for five classes. The dataset is intended to be used for class agnostic motion cue based object detection and classes are provided as meta-data for better tuning. We design and implement a two-stream RGB and optical flow fusion architecture which outputs motion segmentation directly in BEV space. We compare it with inverse perspective mapping of state-of-the-art motion segmentation predictions on the image plane. We observe a significant improvement of 13% in mIoU using the simple baseline implementation. This demonstrates the ability to directly learn motion segmentation output in BEV space. Qualitative results of our baseline and the dataset annotations can be found in https://sites.google.com/view/bev-modnet.
InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image
Aug 21, 2020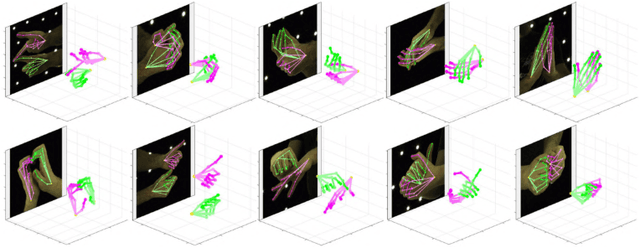
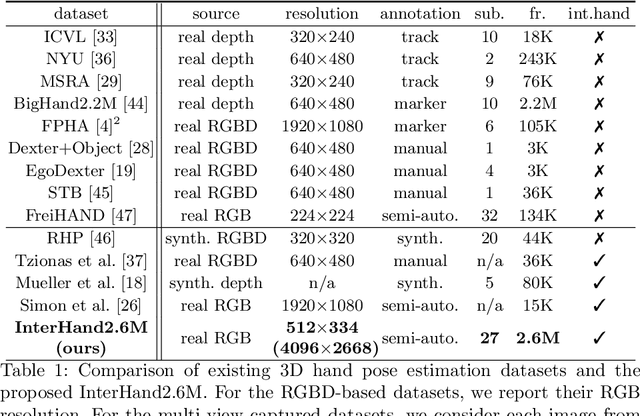

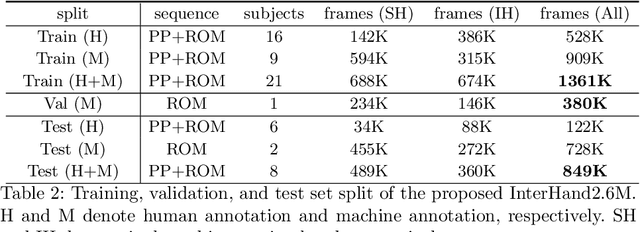
Analysis of hand-hand interactions is a crucial step towards better understanding human behavior. However, most researches in 3D hand pose estimation have focused on the isolated single hand case. Therefore, we firstly propose (1) a large-scale dataset, InterHand2.6M, and (2) a baseline network, InterNet, for 3D interacting hand pose estimation from a single RGB image. The proposed InterHand2.6M consists of \textbf{2.6M labeled single and interacting hand frames} under various poses from multiple subjects. Our InterNet simultaneously performs 3D single and interacting hand pose estimation. In our experiments, we demonstrate big gains in 3D interacting hand pose estimation accuracy when leveraging the interacting hand data in InterHand2.6M. We also report the accuracy of InterNet on InterHand2.6M, which serves as a strong baseline for this new dataset. Finally, we show 3D interacting hand pose estimation results from general images. Our code and dataset are available at https://mks0601.github.io/InterHand2.6M/.
mlVIRNET: Multilevel Variational Image Registration Network
Sep 22, 2019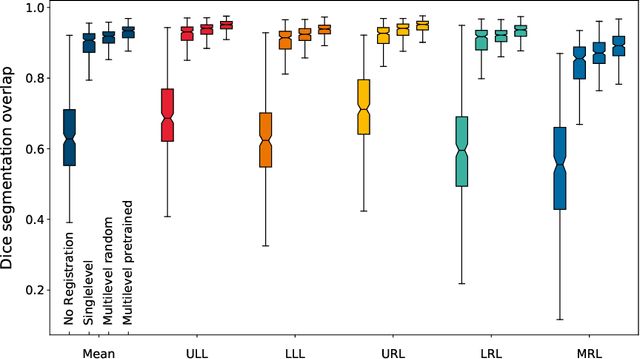
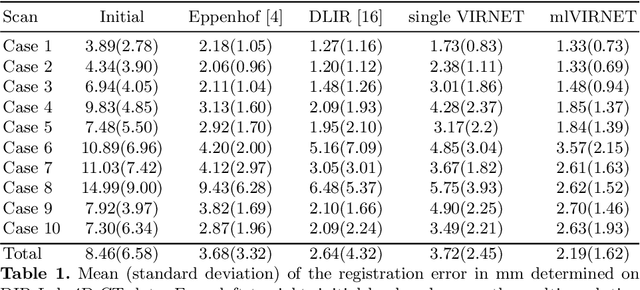
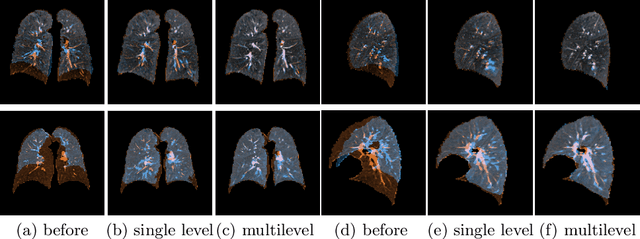
We present a novel multilevel approach for deep learning based image registration. Recently published deep learning based registration methods have shown promising results for a wide range of tasks. However, these algorithms are still limited to relatively small deformations. Our method addresses this shortcoming by introducing a multilevel framework, which computes deformation fields on different scales, similar to conventional methods. Thereby, a coarse-level alignment is obtained first, which is subsequently improved on finer levels. We demonstrate our method on the complex task of inhale-to-exhale lung registration. We show that the use of a deep learning multilevel approach leads to significantly better registration results.
Is deep learning a good choice for image segmentation?
Apr 16, 2019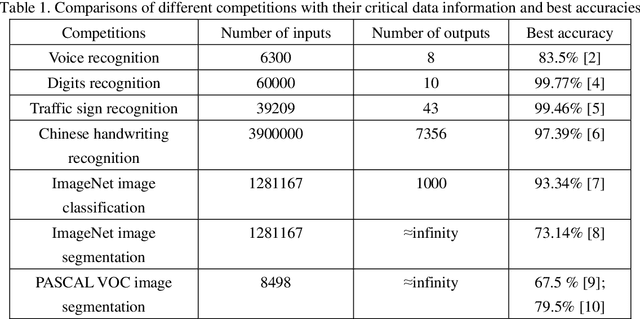
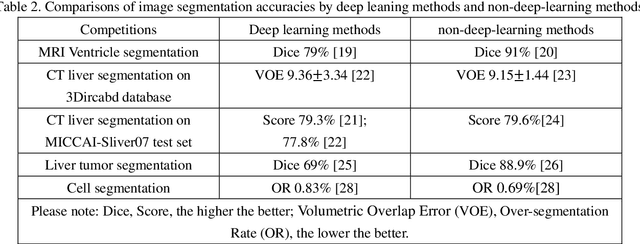
Deep learning works as a discrete non-linear mapping function and has achieved great success as a powerful classification tool. However, it has been overhyped in many fields. This comment takes image segmentation as a typical filed to prove this point of view. Firstly, deep learning is not omnipotent. It only generates a prediction map and relies on other segmentation methods to complete the segmentation task. Secondly, the performance of deep learning is inversely proportional to the number of outputs. Consequently, deep learning is not a good choice for image segmentation unless the resolution of the image is extremely small.