 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Algorithmic Question Answering: Towards a Compositionally Hybrid AI for Algorithmic Reasoning
Sep 29, 2021
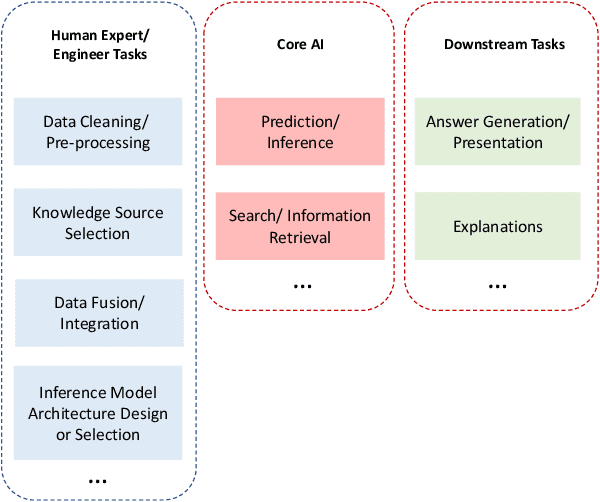
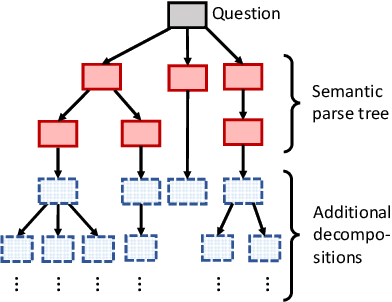
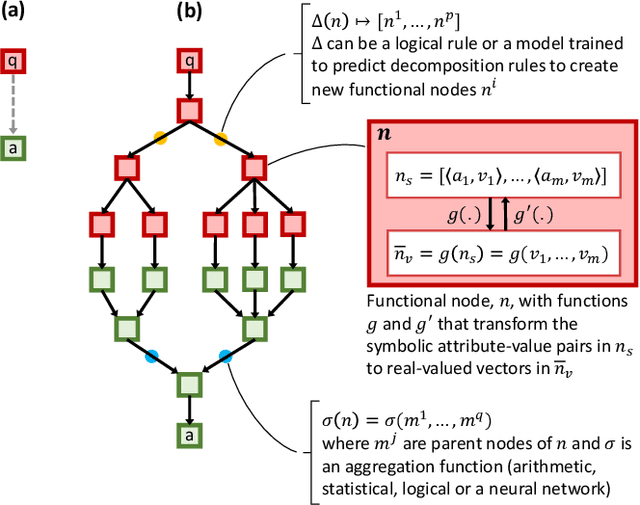
An important aspect of artificial intelligence (AI) is the ability to reason in a step-by-step "algorithmic" manner that can be inspected and verified for its correctness. This is especially important in the domain of question answering (QA). We argue that the challenge of algorithmic reasoning in QA can be effectively tackled with a "systems" approach to AI which features a hybrid use of symbolic and sub-symbolic methods including deep neural networks. Additionally, we argue that while neural network models with end-to-end training pipelines perform well in narrow applications such as image classification and language modelling, they cannot, on their own, successfully perform algorithmic reasoning, especially if the task spans multiple domains. We discuss a few notable exceptions and point out how they are still limited when the QA problem is widened to include other intelligence-requiring tasks. However, deep learning, and machine learning in general, do play important roles as components in the reasoning process. We propose an approach to algorithm reasoning for QA, Deep Algorithmic Question Answering (DAQA), based on three desirable properties: interpretability, generalizability and robustness which such an AI system should possess and conclude that they are best achieved with a combination of hybrid and compositional AI.
Hand-drawn Symbol Recognition of Surgical Flowsheet Graphs with Deep Image Segmentation
Jun 30, 2020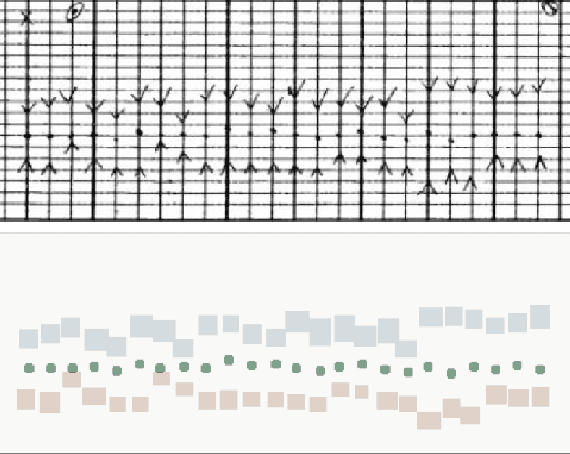
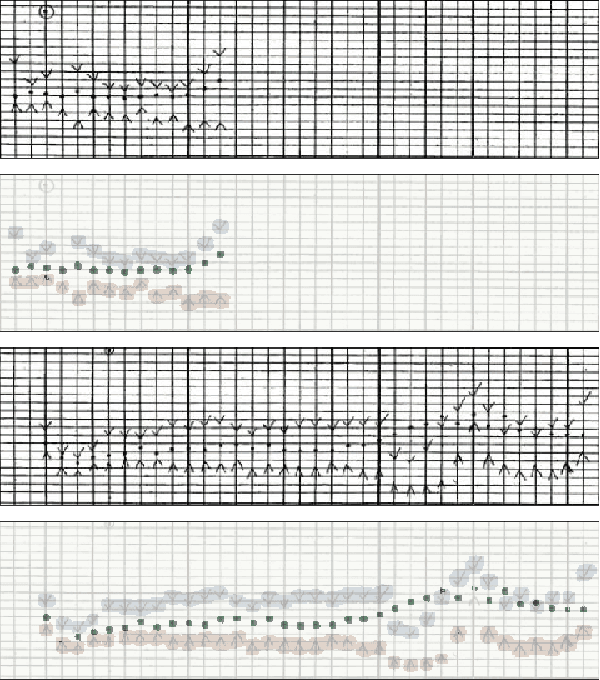

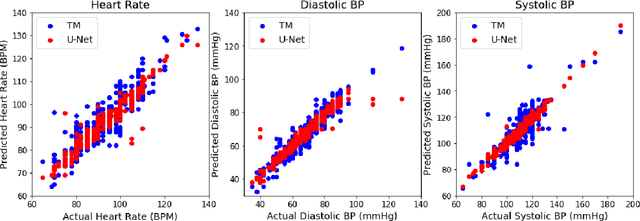
Perioperative data are essential to investigating the causes of adverse surgical outcomes. In some low to middle income countries, these data are computationally inaccessible due to a lack of digitization of surgical flowsheets. In this paper, we present a deep image segmentation approach using a U-Net architecture that can detect hand-drawn symbols on a flowsheet graph. The segmentation mask outputs are post-processed with techniques unique to each symbol to convert into numeric values. The U-Net method can detect, at the appropriate time intervals, the symbols for heart rate and blood pressure with over 99 percent accuracy. Over 95 percent of the predictions fall within an absolute error of five when compared to the actual value. The deep learning model outperformed template matching even with a small size of annotated images available for the training set.
Physically Inspired Dense Fusion Networks for Relighting
May 05, 2021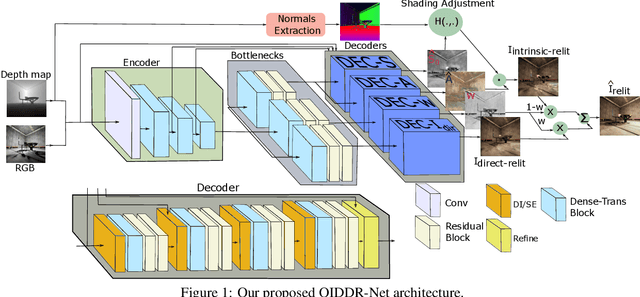

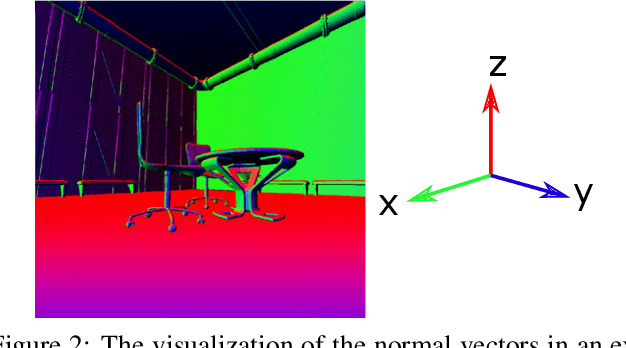

Image relighting has emerged as a problem of significant research interest inspired by augmented reality applications. Physics-based traditional methods, as well as black box deep learning models, have been developed. The existing deep networks have exploited training to achieve a new state of the art; however, they may perform poorly when training is limited or does not represent problem phenomenology, such as the addition or removal of dense shadows. We propose a model which enriches neural networks with physical insight. More precisely, our method generates the relighted image with new illumination settings via two different strategies and subsequently fuses them using a weight map (w). In the first strategy, our model predicts the material reflectance parameters (albedo) and illumination/geometry parameters of the scene (shading) for the relit image (we refer to this strategy as intrinsic image decomposition (IID)). The second strategy is solely based on the black box approach, where the model optimizes its weights based on the ground-truth images and the loss terms in the training stage and generates the relit output directly (we refer to this strategy as direct). While our proposed method applies to both one-to-one and any-to-any relighting problems, for each case we introduce problem-specific components that enrich the model performance: 1) For one-to-one relighting we incorporate normal vectors of the surfaces in the scene to adjust gloss and shadows accordingly in the image. 2) For any-to-any relighting, we propose an additional multiscale block to the architecture to enhance feature extraction. Experimental results on the VIDIT 2020 and the VIDIT 2021 dataset (used in the NTIRE 2021 relighting challenge) reveals that our proposal can outperform many state-of-the-art methods in terms of well-known fidelity metrics and perceptual loss.
SCEHR: Supervised Contrastive Learning for Clinical Risk Prediction using Electronic Health Records
Oct 11, 2021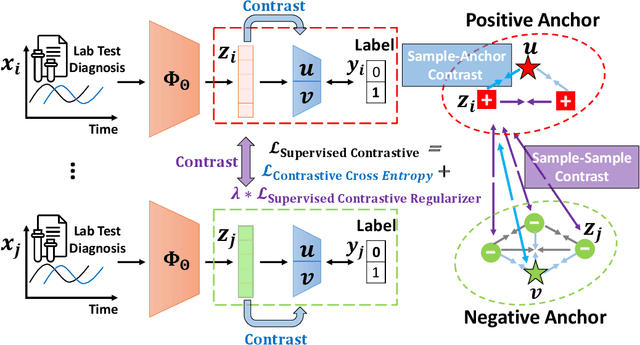
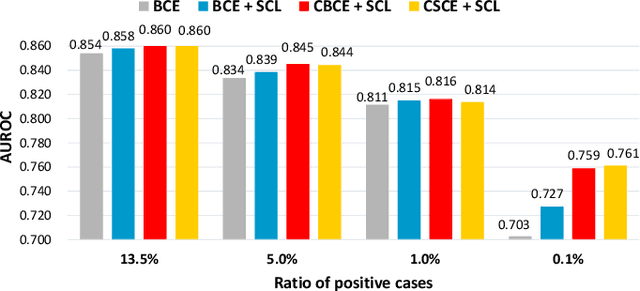
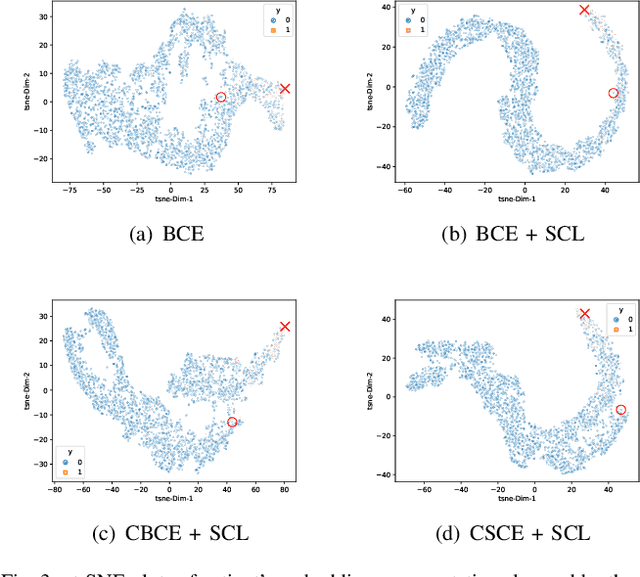

Contrastive learning has demonstrated promising performance in image and text domains either in a self-supervised or a supervised manner. In this work, we extend the supervised contrastive learning framework to clinical risk prediction problems based on longitudinal electronic health records (EHR). We propose a general supervised contrastive loss $\mathcal{L}_{\text{Contrastive Cross Entropy} } + \lambda \mathcal{L}_{\text{Supervised Contrastive Regularizer}}$ for learning both binary classification (e.g. in-hospital mortality prediction) and multi-label classification (e.g. phenotyping) in a unified framework. Our supervised contrastive loss practices the key idea of contrastive learning, namely, pulling similar samples closer and pushing dissimilar ones apart from each other, simultaneously by its two components: $\mathcal{L}_{\text{Contrastive Cross Entropy} }$ tries to contrast samples with learned anchors which represent positive and negative clusters, and $\mathcal{L}_{\text{Supervised Contrastive Regularizer}}$ tries to contrast samples with each other according to their supervised labels. We propose two versions of the above supervised contrastive loss and our experiments on real-world EHR data demonstrate that our proposed loss functions show benefits in improving the performance of strong baselines and even state-of-the-art models on benchmarking tasks for clinical risk predictions. Our loss functions work well with extremely imbalanced data which are common for clinical risk prediction problems. Our loss functions can be easily used to replace (binary or multi-label) cross-entropy loss adopted in existing clinical predictive models. The Pytorch code is released at \url{https://github.com/calvin-zcx/SCEHR}.
Reduce Noise in Computed Tomography Image using Adaptive Gaussian Filter
Feb 05, 2019
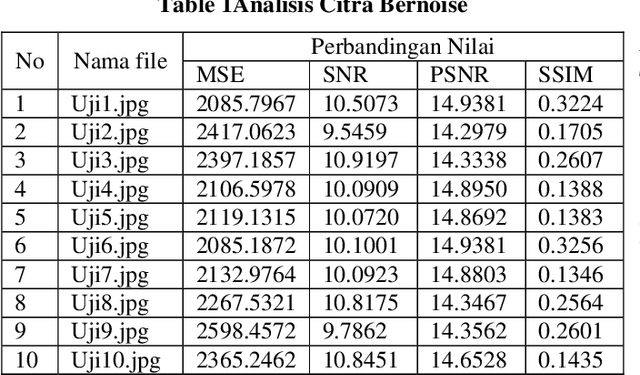
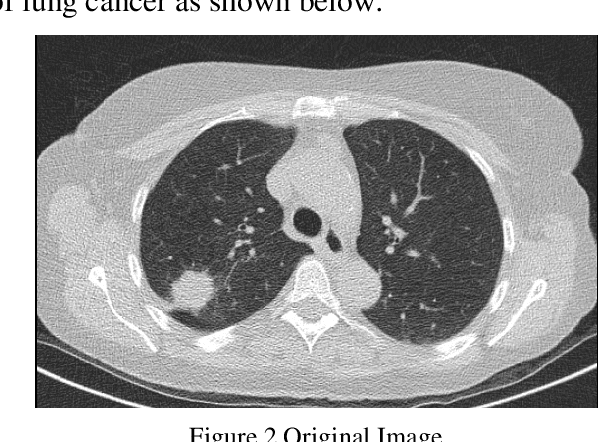
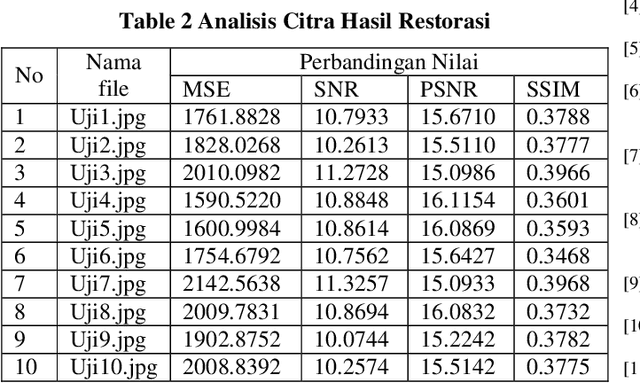
One image processing application that is very helpful for humans is to improve image quality, poor image quality makes the image more difficult to interpret because the information conveyed by the image is reduced. In the process of the acquisition of medical images, the resulting image has decreased quality (degraded) due to external factors and medical equipment used. For this reason, it is necessary to have an image processing process to improve the quality of medical images, so that later it is expected to help facilitate medical personnel in analyzing and translating medical images, which will lead to an improvement in the quality of diagnosis. In this study, an analysis will be carried out to improve the quality of medical images with noise reduction with the Gaussian Filter Method. Next, it is carried out, and tested against medical images, in this case, the lung photo image. The test image is given noise in the form of impulse salt & pepper and adaptive Gaussian then analyzed its performance qualitatively by comparing the output filter image, noise image, and the original image by naked eye.
Visual Correspondence Hallucination: Towards Geometric Reasoning
Jun 17, 2021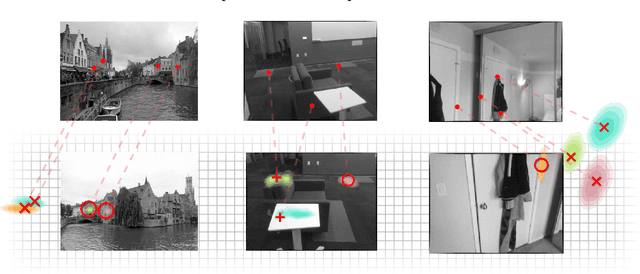
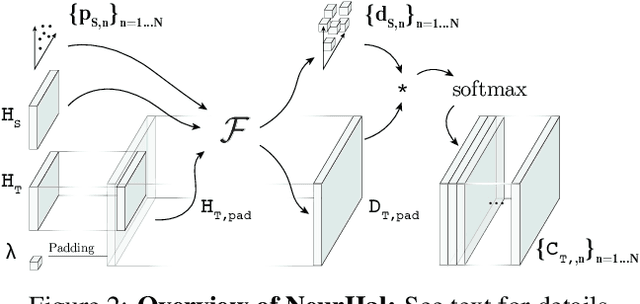
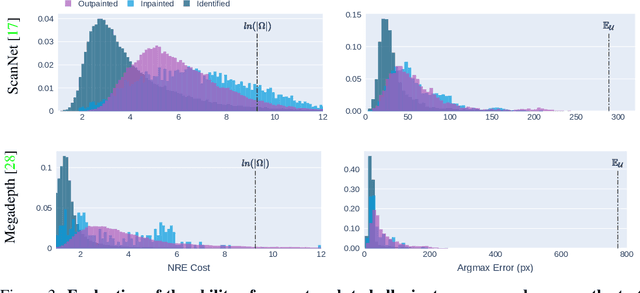
Given a pair of partially overlapping source and target images and a keypoint in the source image, the keypoint's correspondent in the target image can be either visible, occluded or outside the field of view. Local feature matching methods are only able to identify the correspondent's location when it is visible, while humans can also hallucinate its location when it is occluded or outside the field of view through geometric reasoning. In this paper, we bridge this gap by training a network to output a peaked probability distribution over the correspondent's location, regardless of this correspondent being visible, occluded, or outside the field of view. We experimentally demonstrate that this network is indeed able to hallucinate correspondences on unseen pairs of images. We also apply this network to a camera pose estimation problem and find it is significantly more robust than state-of-the-art local feature matching-based competitors.
Partially-Supervised Image Captioning
Jun 15, 2018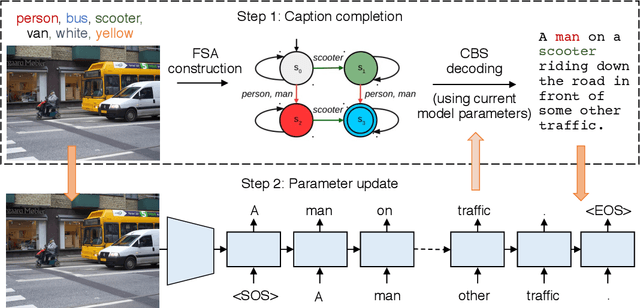
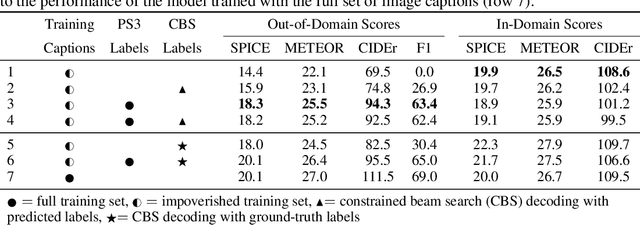
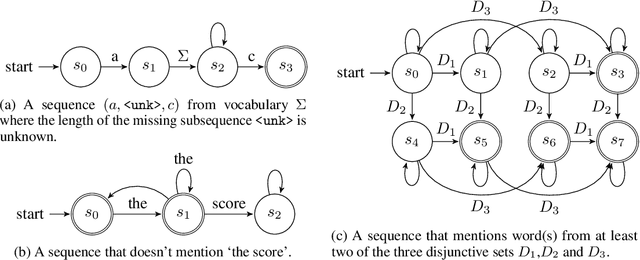
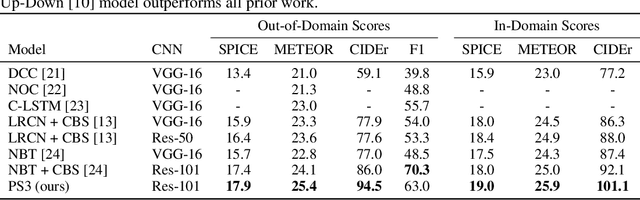
Image captioning models are becoming increasingly successful at describing the content of images in restricted domains. However, if these models are to function in the wild - for example, as aids for the visually impaired - a much larger number and variety of visual concepts must be understood. In this work, we teach image captioning models new visual concepts with partial supervision, such as available from object detection and image label datasets. As these datasets contain text fragments rather than complete captions, we formulate this problem as learning from incomplete data. To flexibly characterize our uncertainty about the unobserved complete sequence, we represent each incomplete training sequence with its own finite state automaton encoding acceptable complete sequences. We then propose a novel algorithm for training sequence models, such as recurrent neural networks, on incomplete sequences specified in this manner. In the context of image captioning, our method lifts the restriction that previously required image captioning models to be trained on paired image-sentence corpora only, or otherwise required specialized model architectures to take advantage of alternative data modalities. Applying our approach to an existing neural captioning model, we achieve state of the art results on the novel object captioning task using the COCO dataset. We further show that we can train a captioning model to describe new visual concepts from the Open Images dataset while maintaining competitive COCO evaluation scores.
Recall@k Surrogate Loss with Large Batches and Similarity Mixup
Aug 25, 2021
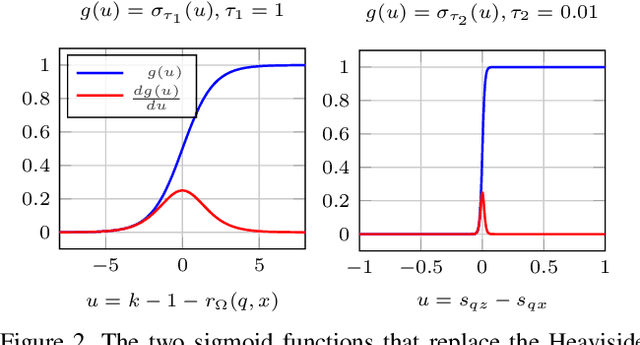
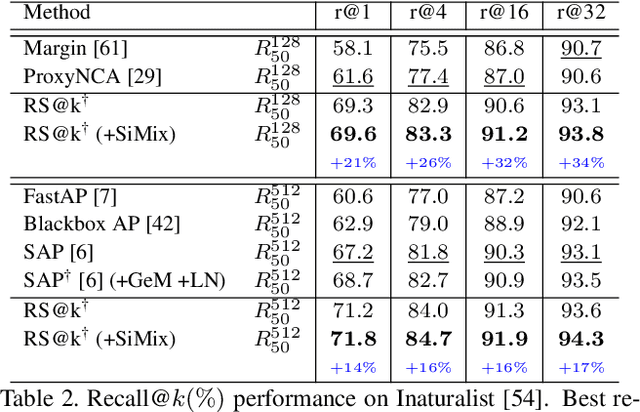
Direct optimization, by gradient descent, of an evaluation metric, is not possible when it is non-differentiable, which is the case for recall in retrieval. In this work, a differentiable surrogate loss for the recall is proposed. Using an implementation that sidesteps the hardware constraints of the GPU memory, the method trains with a very large batch size, which is essential for metrics computed on the entire retrieval database. It is assisted by an efficient mixup approach that operates on pairwise scalar similarities and virtually increases the batch size further. When used for deep metric learning, the proposed method achieves state-of-the-art results in several image retrieval benchmarks. For instance-level recognition, the method outperforms similar approaches that train using an approximation of average precision. The implementation will be made public.
Identifying partial mouse brain microscopy images from Allen reference atlas using a contrastively learned semantic space
Sep 15, 2021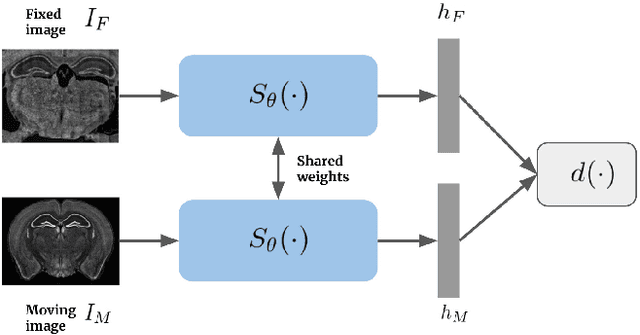
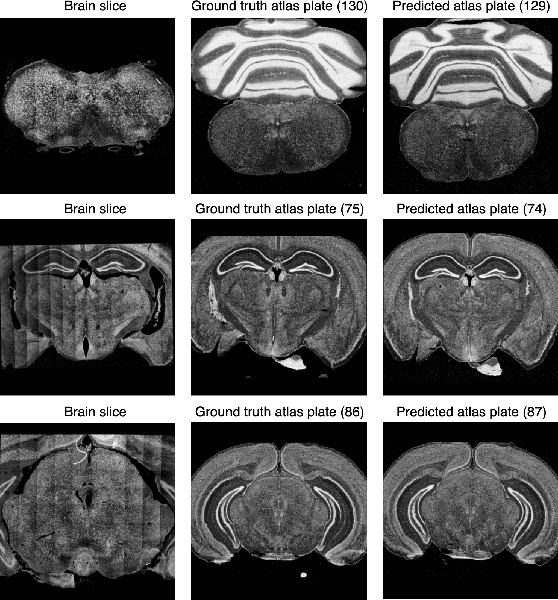

Precise identification of mouse brain microscopy images is a crucial first step when anatomical structures in the mouse brain are to be registered to a reference atlas. Practitioners usually rely on manual comparison of images or tools that assume the presence of complete images. This work explores Siamese Networks as the method for finding corresponding 2D reference atlas plates for given partial 2D mouse brain images. Siamese networks are a class of convolutional neural networks (CNNs) that use weight-shared paths to obtain low dimensional embeddings of pairs of input images. The correspondence between the partial mouse brain image and reference atlas plate is determined based on the distance between low dimensional embeddings of brain slices and atlas plates that are obtained from Siamese networks using contrastive learning. Experiments showed that Siamese CNNs can precisely identify brain slices using the Allen mouse brain atlas when training and testing images come from the same source. They achieved TOP-1 and TOP-5 accuracy of 25% and 100%, respectively, taking only 7.2 seconds to identify 29 images.
Double-Uncertainty Assisted Spatial and Temporal Regularization Weighting for Learning-based Registration
Jul 15, 2021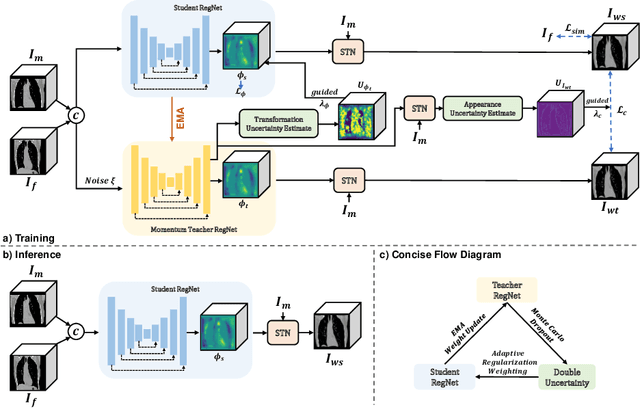
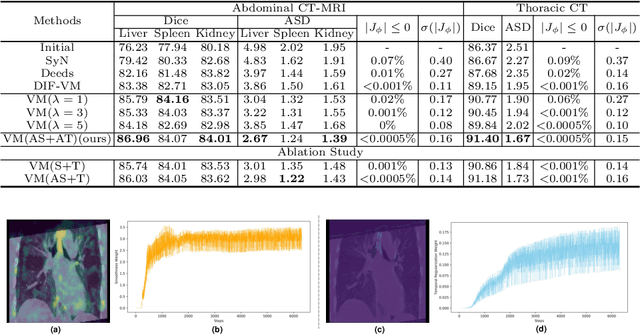
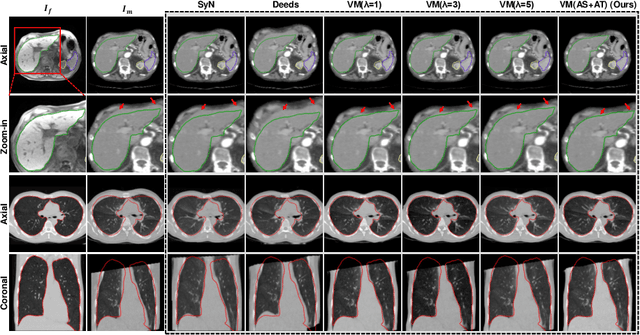
In order to tackle the difficulty associated with the ill-posed nature of the image registration problem, researchers use regularization to constrain the solution space. For most learning-based registration approaches, the regularization usually has a fixed weight and only constrains the spatial transformation. Such convention has two limitations: (1) The regularization strength of a specific image pair should be associated with the content of the images, thus the ``one value fits all'' scheme is not ideal; (2) Only spatially regularizing the transformation (but overlooking the temporal consistency of different estimations) may not be the best strategy to cope with the ill-posedness. In this study, we propose a mean-teacher based registration framework. This framework incorporates an additional \textit{temporal regularization} term by encouraging the teacher model's temporal ensemble prediction to be consistent with that of the student model. At each training step, it also automatically adjusts the weights of the \textit{spatial regularization} and the \textit{temporal regularization} by taking account of the transformation uncertainty and appearance uncertainty derived from the perturbed teacher model. We perform experiments on multi- and uni-modal registration tasks, and the results show that our strategy outperforms the traditional and learning-based benchmark methods.