 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Spatio-Temporal Deep Learning Methods for Motion Estimation Using 4D OCT Image Data
Apr 21, 2020
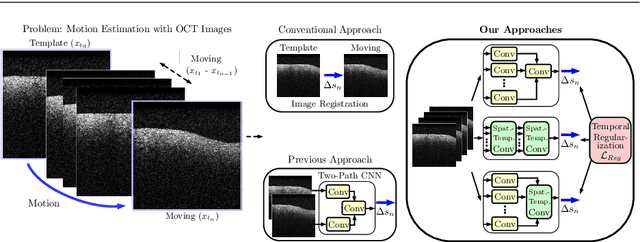
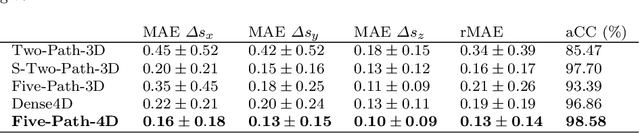
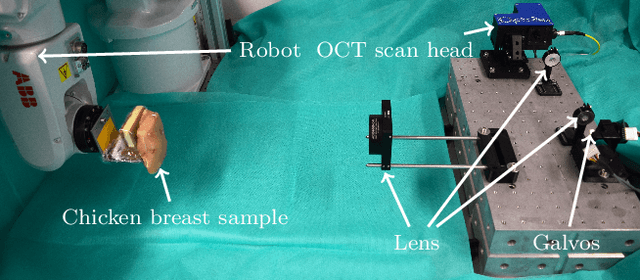
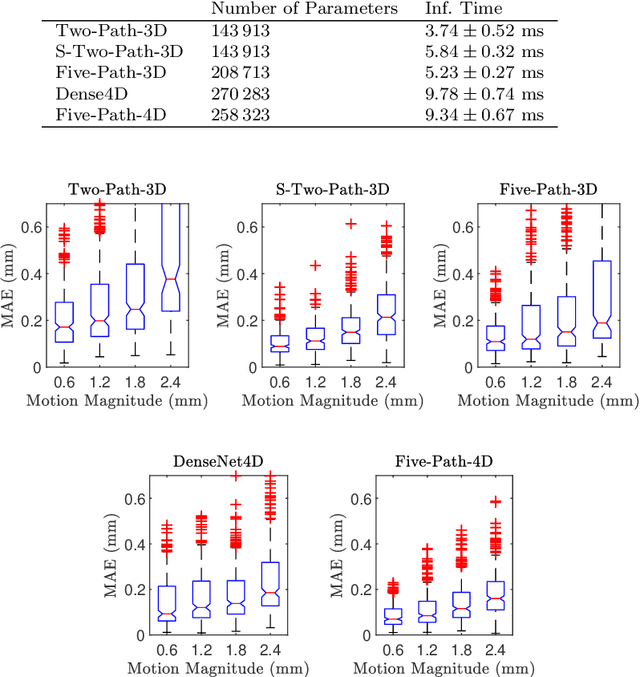
Purpose. Localizing structures and estimating the motion of a specific target region are common problems for navigation during surgical interventions. Optical coherence tomography (OCT) is an imaging modality with a high spatial and temporal resolution that has been used for intraoperative imaging and also for motion estimation, for example, in the context of ophthalmic surgery or cochleostomy. Recently, motion estimation between a template and a moving OCT image has been studied with deep learning methods to overcome the shortcomings of conventional, feature-based methods. Methods. We investigate whether using a temporal stream of OCT image volumes can improve deep learning-based motion estimation performance. For this purpose, we design and evaluate several 3D and 4D deep learning methods and we propose a new deep learning approach. Also, we propose a temporal regularization strategy at the model output. Results. Using a tissue dataset without additional markers, our deep learning methods using 4D data outperform previous approaches. The best performing 4D architecture achieves an correlation coefficient (aCC) of 98.58% compared to 85.0% of a previous 3D deep learning method. Also, our temporal regularization strategy at the output further improves 4D model performance to an aCC of 99.06%. In particular, our 4D method works well for larger motion and is robust towards image rotations and motion distortions. Conclusions. We propose 4D spatio-temporal deep learning for OCT-based motion estimation. On a tissue dataset, we find that using 4D information for the model input improves performance while maintaining reasonable inference times. Our regularization strategy demonstrates that additional temporal information is also beneficial at the model output.
Exposing and Correcting the Gender Bias in Image Captioning Datasets and Models
Dec 02, 2019


The task of image captioning implicitly involves gender identification. However, due to the gender bias in data, gender identification by an image captioning model suffers. Also, the gender-activity bias, owing to the word-by-word prediction, influences other words in the caption prediction, resulting in the well-known problem of label bias. In this work, we investigate gender bias in the COCO captioning dataset and show that it engenders not only from the statistical distribution of genders with contexts but also from the flawed annotation by the human annotators. We look at the issues created by this bias in the trained models. We propose a technique to get rid of the bias by splitting the task into 2 subtasks: gender-neutral image captioning and gender classification. By this decoupling, the gender-context influence can be eradicated. We train the gender-neutral image captioning model, which gives comparable results to a gendered model even when evaluating against a dataset that possesses a similar bias as the training data. Interestingly, the predictions by this model on images with no humans, are also visibly different from the one trained on gendered captions. We train gender classifiers using the available bounding box and mask-based annotations for the person in the image. This allows us to get rid of the context and focus on the person to predict the gender. By substituting the genders into the gender-neutral captions, we get the final gendered predictions. Our predictions achieve similar performance to a model trained with gender, and at the same time are devoid of gender bias. Finally, our main result is that on an anti-stereotypical dataset, our model outperforms a popular image captioning model which is trained with gender.
Automatic Plant Image Identification of Vietnamese species using Deep Learning Models
May 05, 2020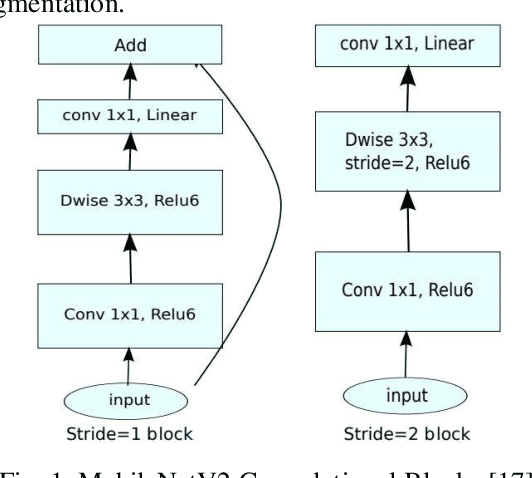

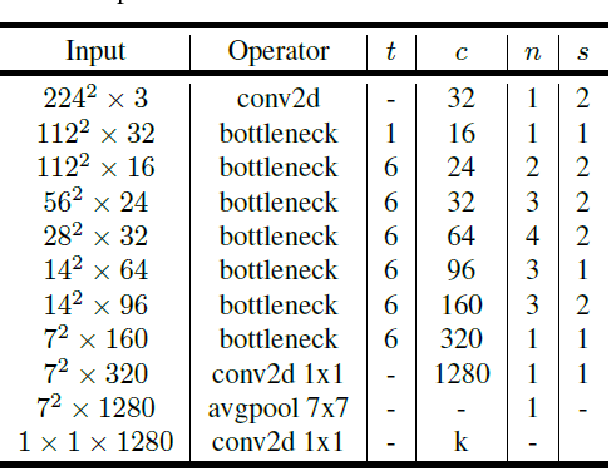
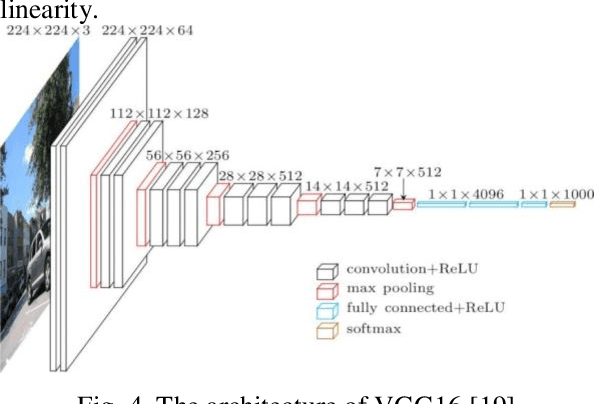
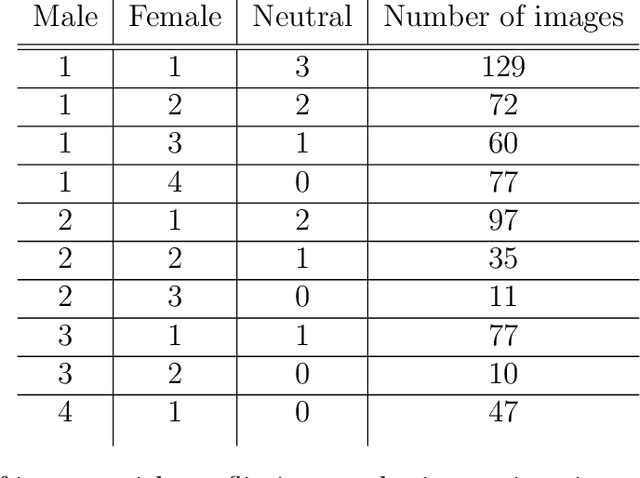
It is complicated to distinguish among thousands of plant species in the natural ecosystem, and many efforts have been investigated to address the issue. In Vietnam, the task of identifying one from 12,000 species requires specialized experts in flora management, with thorough training skills and in-depth knowledge. Therefore, with the advance of machine learning, automatic plant identification systems have been proposed to benefit various stakeholders, including botanists, pharmaceutical laboratories, taxonomists, forestry services, and organizations. The concept has fueled an interest in research and application from global researchers and engineers in both fields of machine learning and computer vision. In this paper, the Vietnamese plant image dataset was collected from an online encyclopedia of Vietnamese organisms, together with the Encyclopedia of Life, to generate a total of 28,046 environmental images of 109 plant species in Vietnam. A comparative evaluation of four deep convolutional feature extraction models, which are MobileNetV2, VGG16, ResnetV2, and Inception Resnet V2, is presented. Those models have been tested on the Support Vector Machine (SVM) classifier to experiment with the purpose of plant image identification. The proposed models achieve promising recognition rates, and MobilenetV2 attained the highest with 83.9%. This result demonstrates that machine learning models are potential for plant species identification in the natural environment, and future works need to examine proposing higher accuracy systems on a larger dataset to meet the current application demand.
* 7 pages, 8 figures, 2 tables, Published with International Journal of Engineering Trends and Technology (IJETT)
DeepSteal: Advanced Model Extractions Leveraging Efficient Weight Stealing in Memories
Nov 08, 2021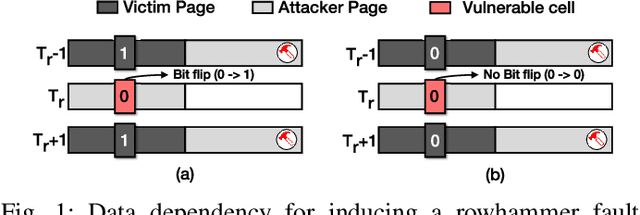
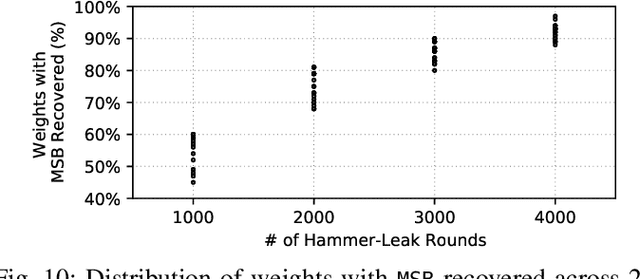
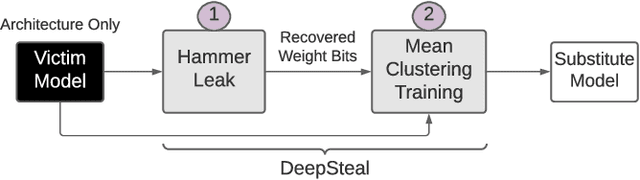
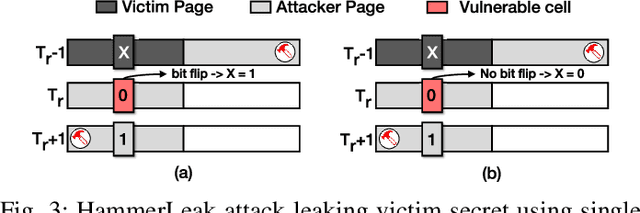
Recent advancements of Deep Neural Networks (DNNs) have seen widespread deployment in multiple security-sensitive domains. The need of resource-intensive training and use of valuable domain-specific training data have made these models a top intellectual property (IP) for model owners. One of the major threats to the DNN privacy is model extraction attacks where adversaries attempt to steal sensitive information in DNN models. Recent studies show hardware-based side channel attacks can reveal internal knowledge about DNN models (e.g., model architectures) However, to date, existing attacks cannot extract detailed model parameters (e.g., weights/biases). In this work, for the first time, we propose an advanced model extraction attack framework DeepSteal that effectively steals DNN weights with the aid of memory side-channel attack. Our proposed DeepSteal comprises two key stages. Firstly, we develop a new weight bit information extraction method, called HammerLeak, through adopting the rowhammer based hardware fault technique as the information leakage vector. HammerLeak leverages several novel system-level techniques tailed for DNN applications to enable fast and efficient weight stealing. Secondly, we propose a novel substitute model training algorithm with Mean Clustering weight penalty, which leverages the partial leaked bit information effectively and generates a substitute prototype of the target victim model. We evaluate this substitute model extraction method on three popular image datasets (e.g., CIFAR-10/100/GTSRB) and four DNN architectures (e.g., ResNet-18/34/Wide-ResNet/VGG-11). The extracted substitute model has successfully achieved more than 90 % test accuracy on deep residual networks for the CIFAR-10 dataset. Moreover, our extracted substitute model could also generate effective adversarial input samples to fool the victim model.
Grid Anchor based Image Cropping: A New Benchmark and An Efficient Model
Sep 18, 2019
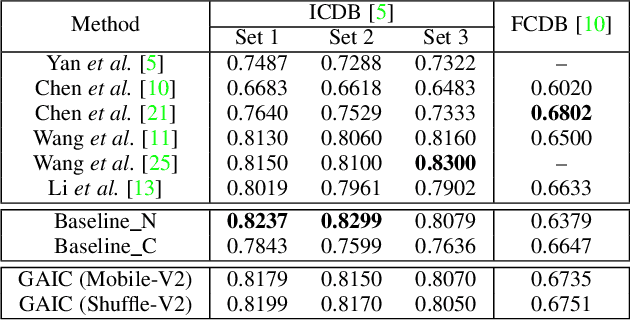

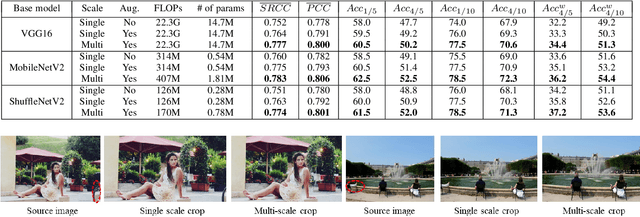
Image cropping aims to improve the composition as well as aesthetic quality of an image by removing extraneous content from it. Most of the existing image cropping databases provide only one or several human-annotated bounding boxes as the groundtruths, which can hardly reflect the non-uniqueness and flexibility of image cropping in practice. The employed evaluation metrics such as intersection-over-union cannot reliably reflect the real performance of a cropping model, either. This work revisits the problem of image cropping, and presents a grid anchor based formulation by considering the special properties and requirements (e.g., local redundancy, content preservation, aspect ratio) of image cropping. Our formulation reduces the searching space of candidate crops from millions to no more than ninety. Consequently, a grid anchor based cropping benchmark is constructed, where all crops of each image are annotated and more reliable evaluation metrics are defined. To meet the practical demands of robust performance and high efficiency, we also design an effective and lightweight cropping model. By simultaneously considering the region of interest and region of discard, and leveraging multi-scale information, our model can robustly output visually pleasing crops for images of different scenes. With less than 2.5M parameters, our model runs at a speed of 200 FPS on one single GTX 1080Ti GPU and 12 FPS on one i7-6800K CPU. The code is available at: \url{https://github.com/HuiZeng/Grid-Anchor-based-Image-Cropping-Pytorch}.
Structured Bird's-Eye-View Traffic Scene Understanding from Onboard Images
Oct 05, 2021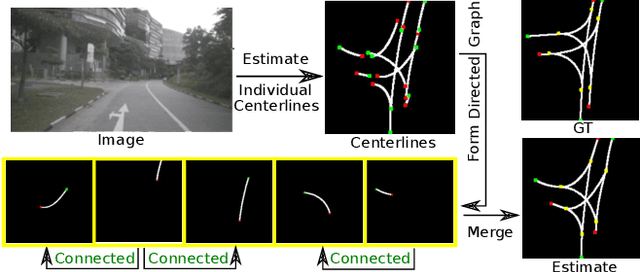
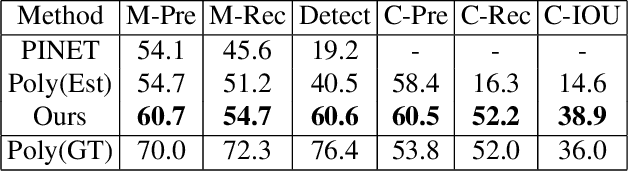
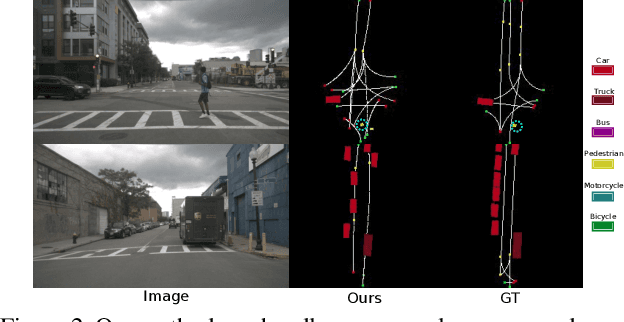
Autonomous navigation requires structured representation of the road network and instance-wise identification of the other traffic agents. Since the traffic scene is defined on the ground plane, this corresponds to scene understanding in the bird's-eye-view (BEV). However, the onboard cameras of autonomous cars are customarily mounted horizontally for a better view of the surrounding, making this task very challenging. In this work, we study the problem of extracting a directed graph representing the local road network in BEV coordinates, from a single onboard camera image. Moreover, we show that the method can be extended to detect dynamic objects on the BEV plane. The semantics, locations, and orientations of the detected objects together with the road graph facilitates a comprehensive understanding of the scene. Such understanding becomes fundamental for the downstream tasks, such as path planning and navigation. We validate our approach against powerful baselines and show that our network achieves superior performance. We also demonstrate the effects of various design choices through ablation studies. Code: https://github.com/ybarancan/STSU
Identification and Classification of Phenomena in Multispectral Satellite Imagery Using a New Image Smoother Method and its Applications in Environmental Remote Sensing
Mar 17, 2020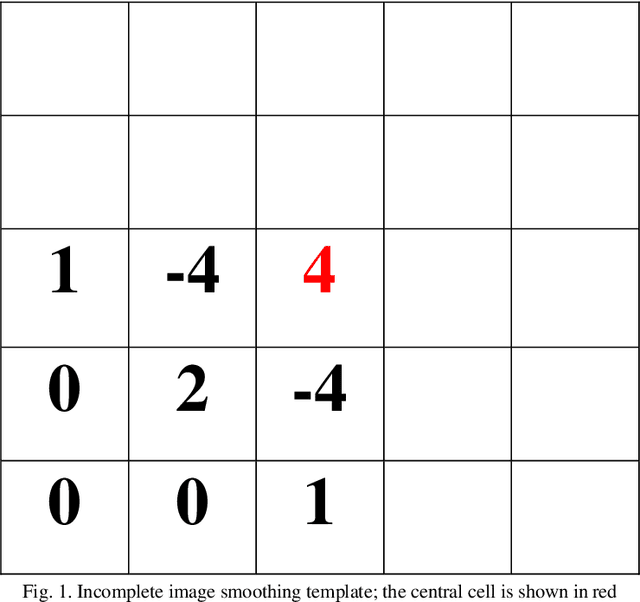
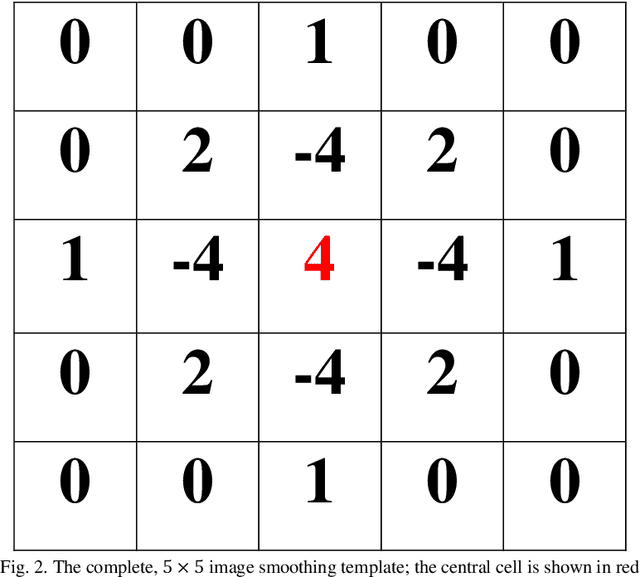


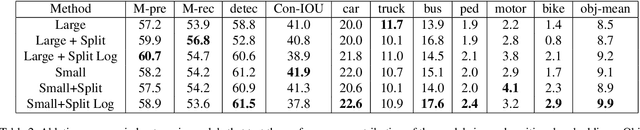
In this paper a new method of image smoothing for satellite imagery and its applications in environmental remote sensing are presented. This method is based on the global gradient minimization over the whole image. With respect to the image discrete identity, the continuous minimization problem is discretized. Using the finite difference numerical method of differentiation, a simple yet efficient 5*5-pixel template is derived. Convolution of the derived template with the image in different bands results in the discrimination of various image elements. This method is extremely fast, besides being highly precise. A case study is presented for the northern Iran, covering parts of the Caspian Sea. Comparison of the method with the usual Laplacian template reveals that it is more capable of distinguishing phenomena in the image.
Dynamic Proximal Unrolling Network for Compressive Sensing Imaging
Jul 23, 2021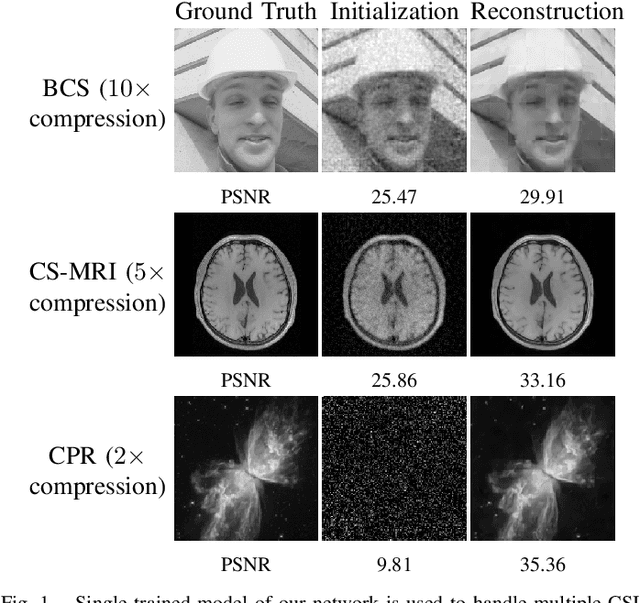
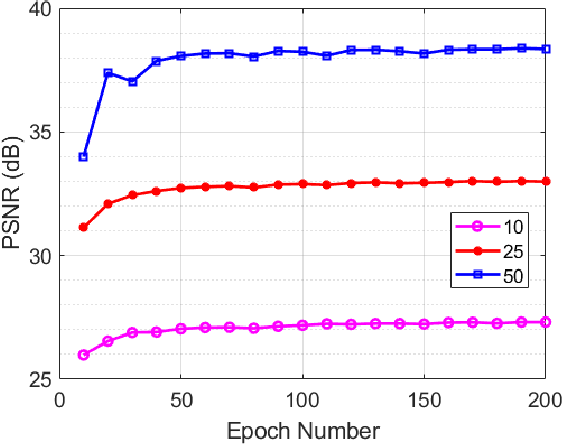
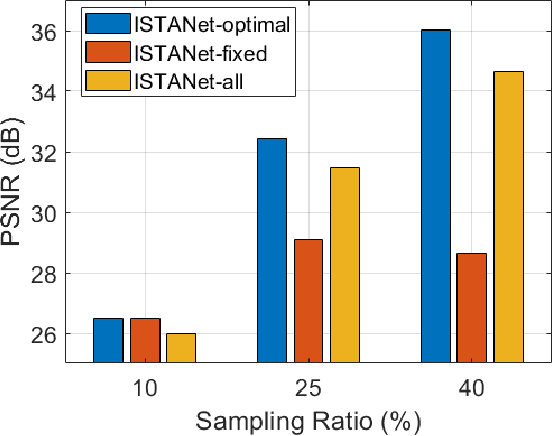
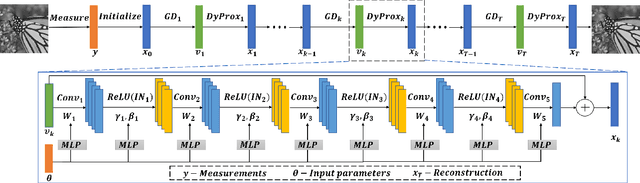
Recovering an underlying image from under-sampled measurements, Compressive Sensing Imaging (CSI) is a challenging problem and has many practical applications. Recently, deep neural networks have been applied to this problem with promising results, owing to its implicitly learned prior to alleviate the ill-poseness of CSI. However, existing neural network approaches require separate models for each imaging parameter like sampling ratios, leading to training difficulties and overfitting to specific settings. In this paper, we present a dynamic proximal unrolling network (dubbed DPUNet), which can handle a variety of measurement matrices via one single model without retraining. Specifically, DPUNet can exploit both embedded physical model via gradient descent and imposing image prior with learned dynamic proximal mapping leading to joint reconstruction. A key component of DPUNet is a dynamic proximal mapping module, whose parameters can be dynamically adjusted at inference stage and make it adapt to any given imaging setting. Experimental results demonstrate that the proposed DPUNet can effectively handle multiple CSI modalities under varying sampling ratios and noise levels with only one model, and outperform the state-of-the-art approaches.
Segmentation-Aware Hyperspectral Image Classification
May 22, 2019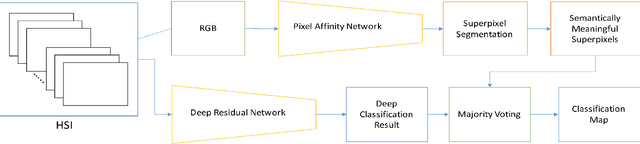


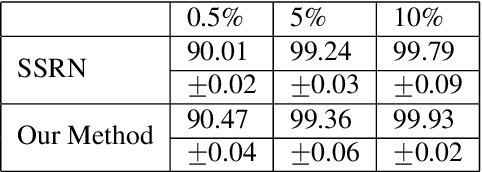
In this paper, we propose an unified hyperspectral image classification method which takes three-dimensional hyperspectral data cube as an input and produces a classification map. In the proposed method, a deep neural network which uses spectral and spatial information together with residual connections, and pixel affinity network based segmentation-aware superpixels are used together. In the architecture, segmentation-aware superpixels run on the initial classification map of deep residual network, and apply majority voting on obtained results. Experimental results show that our propoped method yields state-of-the-art results in two benchmark datasets. Moreover, we also show that the segmentation-aware superpixels have great contribution to the success of hyperspectral image classification methods in cases where training data is insufficient.
Model-based Behavioral Cloning with Future Image Similarity Learning
Oct 08, 2019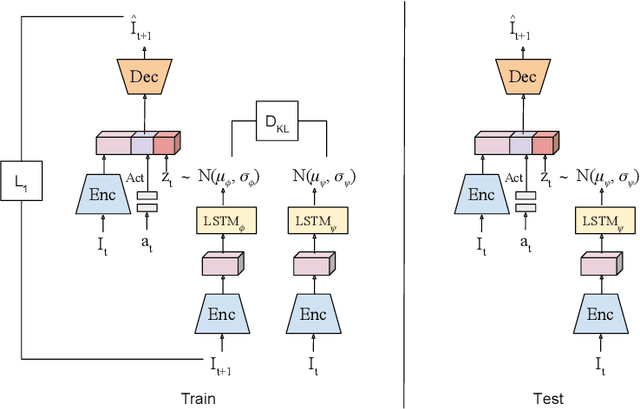


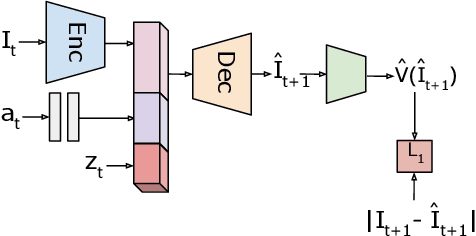
We present a visual imitation learning framework that enables learning of robot action policies solely based on expert samples without any robot trials. Robot exploration and on-policy trials in a real-world environment could often be expensive/dangerous. We present a new approach to address this problem by learning a future scene prediction model solely on a collection of expert trajectories consisting of unlabeled example videos and actions, and by enabling generalized action cloning using future image similarity. The robot learns to visually predict the consequences of taking an action, and obtains the policy by evaluating how similar the predicted future image is to an expert image. We develop a stochastic action-conditioned convolutional autoencoder, and present how we take advantage of future images for robot learning. We conduct experiments in simulated and real-life environments using a ground mobility robot with and without obstacles, and compare our models to multiple baseline methods.