 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
End-to-End Trainable Deep Active Contour Models for Automated Image Segmentation: Delineating Buildings in Aerial Imagery
Jul 22, 2020
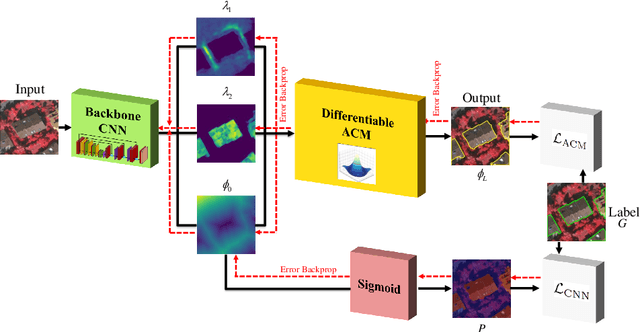


The automated segmentation of buildings in remote sensing imagery is a challenging task that requires the accurate delineation of multiple building instances over typically large image areas. Manual methods are often laborious and current deep-learning-based approaches fail to delineate all building instances and do so with adequate accuracy. As a solution, we present Trainable Deep Active Contours (TDACs), an automatic image segmentation framework that intimately unites Convolutional Neural Networks (CNNs) and Active Contour Models (ACMs). The Eulerian energy functional of the ACM component includes per-pixel parameter maps that are predicted by the backbone CNN, which also initializes the ACM. Importantly, both the ACM and CNN components are fully implemented in TensorFlow and the entire TDAC architecture is end-to-end automatically differentiable and backpropagation trainable without user intervention. TDAC yields fast, accurate, and fully automatic simultaneous delineation of arbitrarily many buildings in the image. We validate the model on two publicly available aerial image datasets for building segmentation, and our results demonstrate that TDAC establishes a new state-of-the-art performance.
Graph Embedding via High Dimensional Model Representation for Hyperspectral Images
Nov 29, 2021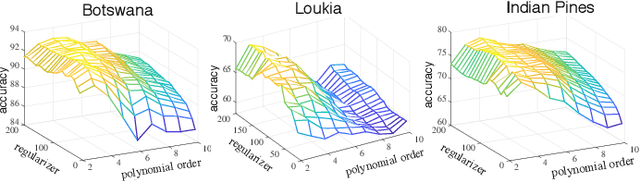
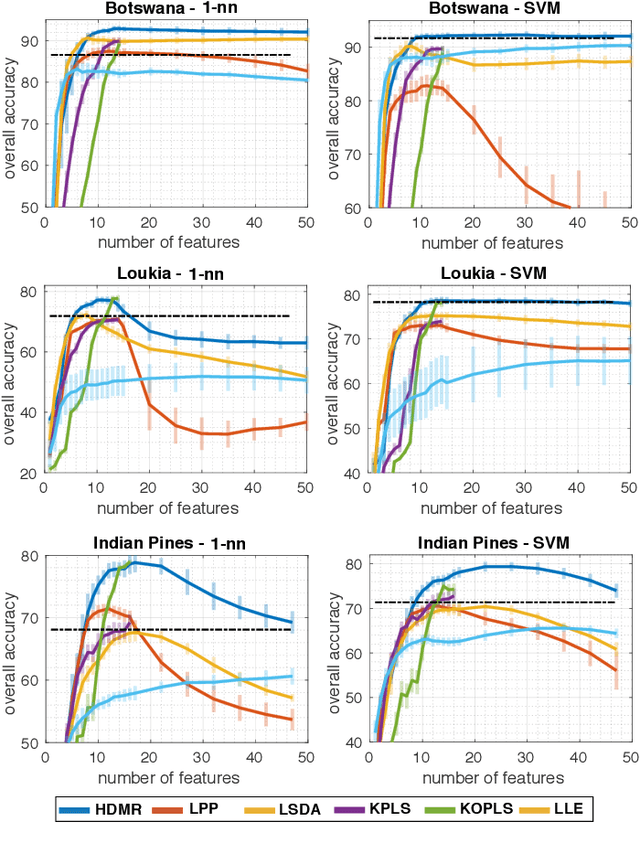
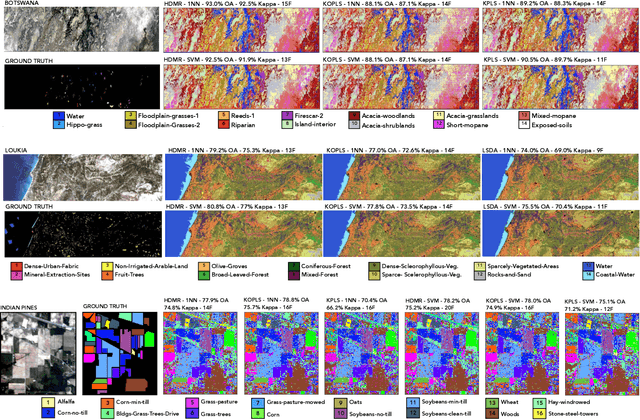
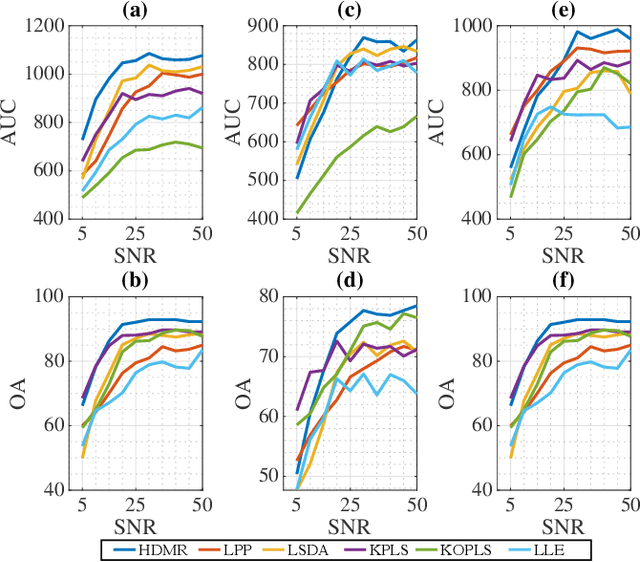
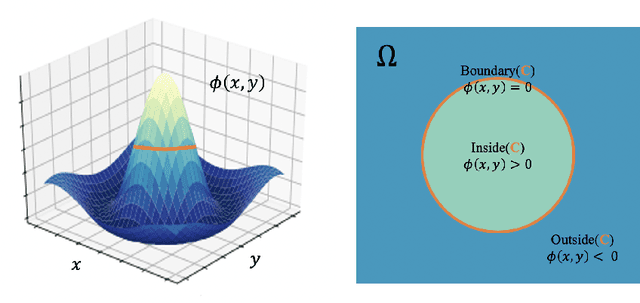
Learning the manifold structure of remote sensing images is of paramount relevance for modeling and understanding processes, as well as to encapsulate the high dimensionality in a reduced set of informative features for subsequent classification, regression, or unmixing. Manifold learning methods have shown excellent performance to deal with hyperspectral image (HSI) analysis but, unless specifically designed, they cannot provide an explicit embedding map readily applicable to out-of-sample data. A common assumption to deal with the problem is that the transformation between the high-dimensional input space and the (typically low) latent space is linear. This is a particularly strong assumption, especially when dealing with hyperspectral images due to the well-known nonlinear nature of the data. To address this problem, a manifold learning method based on High Dimensional Model Representation (HDMR) is proposed, which enables to present a nonlinear embedding function to project out-of-sample samples into the latent space. The proposed method is compared to manifold learning methods along with its linear counterparts and achieves promising performance in terms of classification accuracy of a representative set of hyperspectral images.
Urban Radiance Fields
Nov 29, 2021
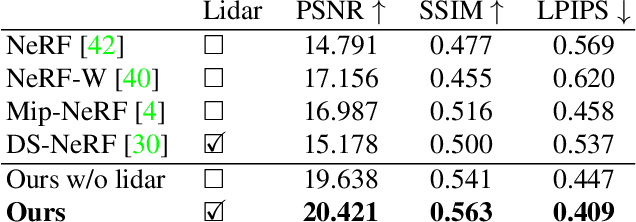


The goal of this work is to perform 3D reconstruction and novel view synthesis from data captured by scanning platforms commonly deployed for world mapping in urban outdoor environments (e.g., Street View). Given a sequence of posed RGB images and lidar sweeps acquired by cameras and scanners moving through an outdoor scene, we produce a model from which 3D surfaces can be extracted and novel RGB images can be synthesized. Our approach extends Neural Radiance Fields, which has been demonstrated to synthesize realistic novel images for small scenes in controlled settings, with new methods for leveraging asynchronously captured lidar data, for addressing exposure variation between captured images, and for leveraging predicted image segmentations to supervise densities on rays pointing at the sky. Each of these three extensions provides significant performance improvements in experiments on Street View data. Our system produces state-of-the-art 3D surface reconstructions and synthesizes higher quality novel views in comparison to both traditional methods (e.g.~COLMAP) and recent neural representations (e.g.~Mip-NeRF).
Exploring constraints on CycleGAN-based CBCT enhancement for adaptive radiotherapy
Oct 12, 2021
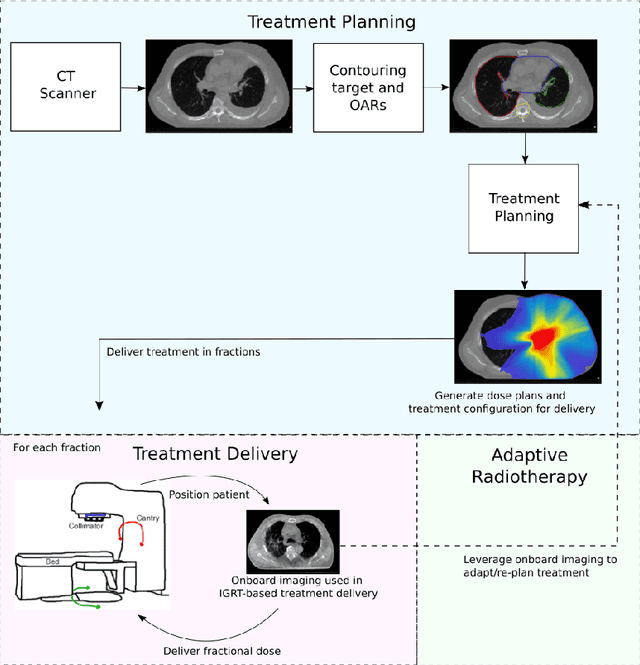
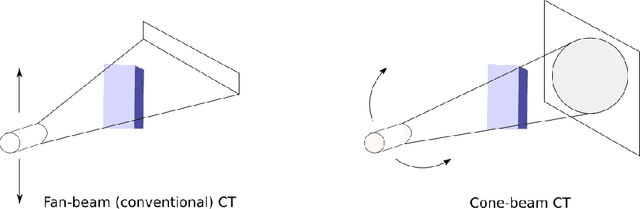
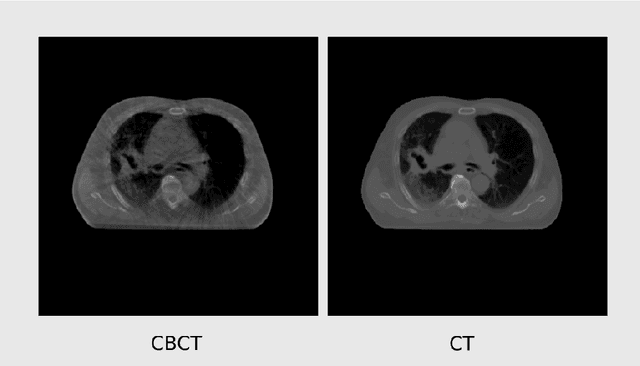
Research exploring CycleGAN-based synthetic image generation has recently accelerated in the medical community, as it is able to leverage unpaired datasets effectively. However, clinical acceptance of these synthetic images pose a significant challenge as they are subject to strict evaluation protocols. A commonly established drawback of the CycleGAN, the introduction of artifacts in generated images is unforgivable in the case of medical images. In an attempt to alleviate this drawback, we explore different constraints of the CycleGAN along with investigation of adaptive control of these constraints. The benefits of imposing additional constraints on the CycleGAN, in the form of structure retaining losses is also explored. A generalized frequency loss inspired by arxiv:2012.12821 that preserves content in the frequency domain between source and target is investigated and compared with existing losses such as the MIND loss arXiv:1809.04536. CycleGAN implementations from the ganslate framework (https://github.com/ganslate-team/ganslate) are used for experimentation in this thesis. Synthetic images generated from our methods are quantitatively and qualitatively investigated and outperform the baseline CycleGAN and other approaches. Furthermore, no observable artifacts or loss in image quality is found, which is critical for acceptance of these synthetic images. The synthetic medical images thus generated are also evaluated using domain-specific evaluation and using segmentation as a downstream task, in order to clearly highlight their applicability to clinical workflows.
Curvature-guided dynamic scale networks for Multi-view Stereo
Dec 11, 2021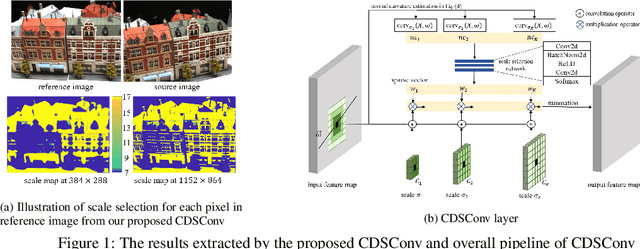
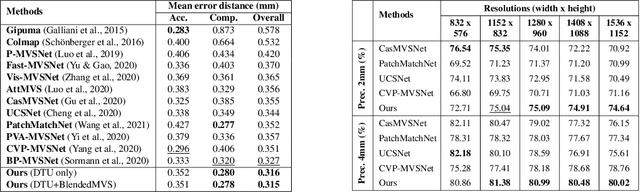
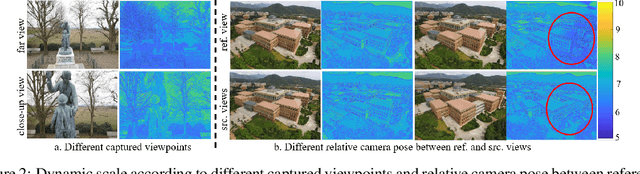
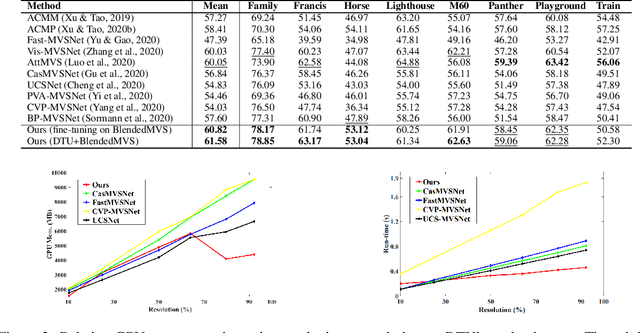
Multi-view stereo (MVS) is a crucial task for precise 3D reconstruction. Most recent studies tried to improve the performance of matching cost volume in MVS by designing aggregated 3D cost volumes and their regularization. This paper focuses on learning a robust feature extraction network to enhance the performance of matching costs without heavy computation in the other steps. In particular, we present a dynamic scale feature extraction network, namely, CDSFNet. It is composed of multiple novel convolution layers, each of which can select a proper patch scale for each pixel guided by the normal curvature of the image surface. As a result, CDFSNet can estimate the optimal patch scales to learn discriminative features for accurate matching computation between reference and source images. By combining the robust extracted features with an appropriate cost formulation strategy, our resulting MVS architecture can estimate depth maps more precisely. Extensive experiments showed that the proposed method outperforms other state-of-the-art methods on complex outdoor scenes. It significantly improves the completeness of reconstructed models. As a result, the method can process higher resolution inputs within faster run-time and lower memory than other MVS methods. Our source code is available at url{https://github.com/TruongKhang/cds-mvsnet}.
Trivial or impossible -- dichotomous data difficulty masks model differences (on ImageNet and beyond)
Oct 12, 2021

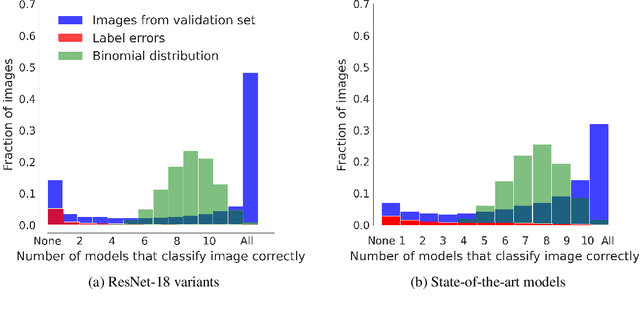
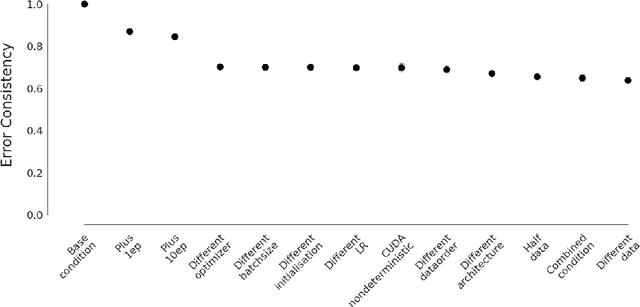
"The power of a generalization system follows directly from its biases" (Mitchell 1980). Today, CNNs are incredibly powerful generalisation systems -- but to what degree have we understood how their inductive bias influences model decisions? We here attempt to disentangle the various aspects that determine how a model decides. In particular, we ask: what makes one model decide differently from another? In a meticulously controlled setting, we find that (1.) irrespective of the network architecture or objective (e.g. self-supervised, semi-supervised, vision transformers, recurrent models) all models end up with a similar decision boundary. (2.) To understand these findings, we analysed model decisions on the ImageNet validation set from epoch to epoch and image by image. We find that the ImageNet validation set, among others, suffers from dichotomous data difficulty (DDD): For the range of investigated models and their accuracies, it is dominated by 46.0% "trivial" and 11.5% "impossible" images (beyond label errors). Only 42.5% of the images could possibly be responsible for the differences between two models' decision boundaries. (3.) Only removing the "impossible" and "trivial" images allows us to see pronounced differences between models. (4.) Humans are highly accurate at predicting which images are "trivial" and "impossible" for CNNs (81.4%). This implies that in future comparisons of brains, machines and behaviour, much may be gained from investigating the decisive role of images and the distribution of their difficulties.
4D iterative reconstruction of brain fMRI in the moving fetus
Nov 22, 2021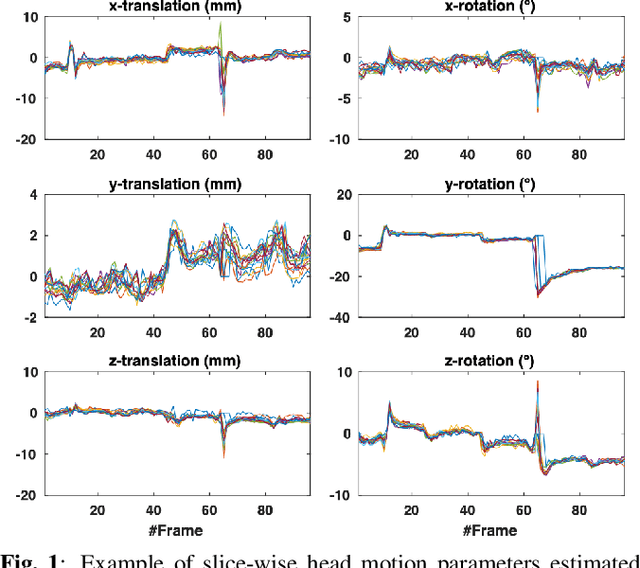
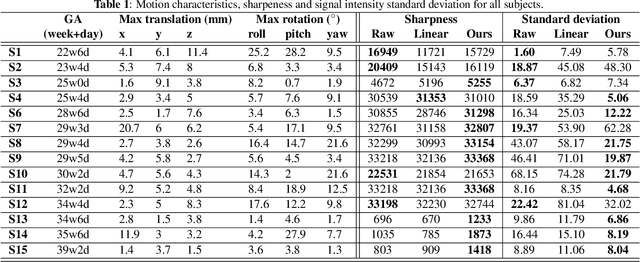
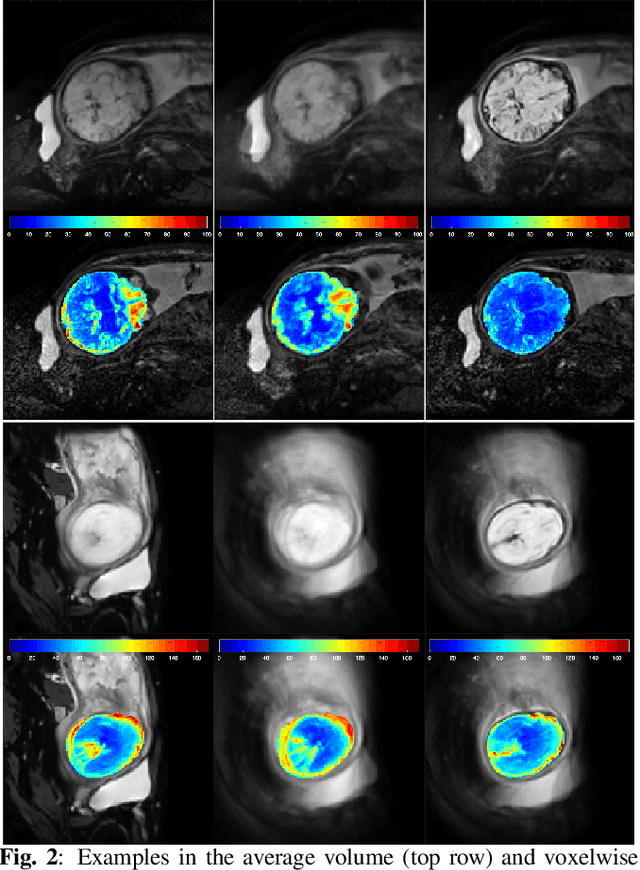
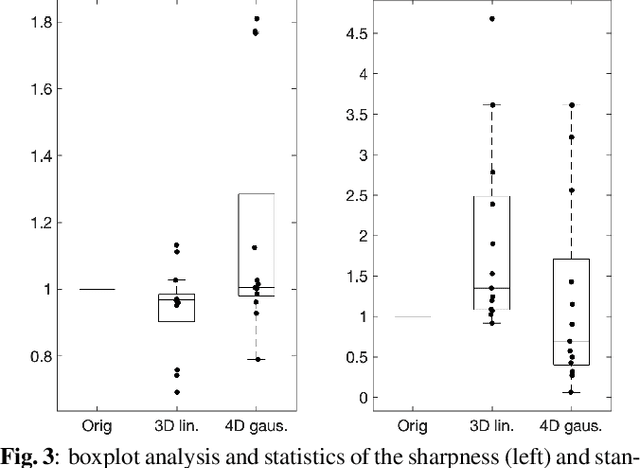
Resting-state functional Magnetic Resonance Imaging (fMRI) is a powerful imaging technique for studying functional development of the brain in utero. However, unpredictable and excessive movement of fetuses has limited clinical application since it causes substantial signal fluctuations which can systematically alter observed patterns of functional connectivity. Previous studies have focused on the accurate estimation of the motion parameters in case of large fetal head movement and used a 3D single step interpolation approach at each timepoint to recover motion-free fMRI images. This does not guarantee that the reconstructed image corresponds to the minimum error representation of fMRI time series given the acquired data. Here, we propose a novel technique based on four dimensional iterative reconstruction of the scattered slices acquired during fetal fMRI. The accuracy of the proposed method was quantitatively evaluated on a group of real clinical fMRI fetuses. The results indicate improvements of reconstruction quality compared to the conventional 3D interpolation approach.
BioLCNet: Reward-modulated Locally Connected Spiking Neural Networks
Sep 12, 2021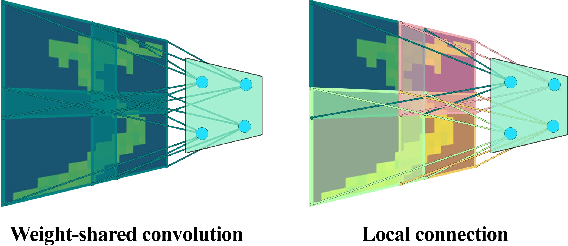
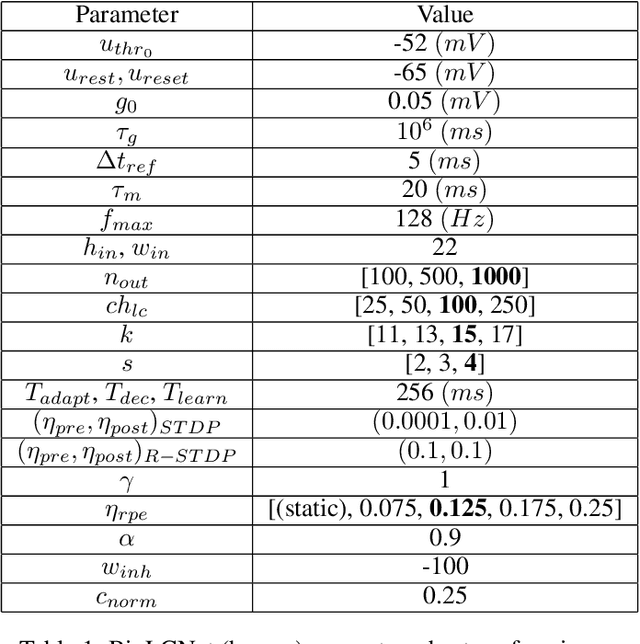
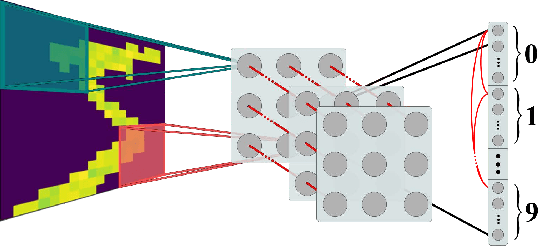

Recent studies have shown that convolutional neural networks (CNNs) are not the only feasible solution for image classification. Furthermore, weight sharing and backpropagation used in CNNs do not correspond to the mechanisms present in the primate visual system. To propose a more biologically plausible solution, we designed a locally connected spiking neural network (SNN) trained using spike-timing-dependent plasticity (STDP) and its reward-modulated variant (R-STDP) learning rules. The use of spiking neurons and local connections along with reinforcement learning (RL) led us to the nomenclature BioLCNet for our proposed architecture. Our network consists of a rate-coded input layer followed by a locally connected hidden layer and a decoding output layer. A spike population-based voting scheme is adopted for decoding in the output layer. We used the MNIST dataset to obtain image classification accuracy and to assess the robustness of our rewarding system to varying target responses.
Bayesian aggregation improves traditional single image crop classification approaches
Apr 07, 2020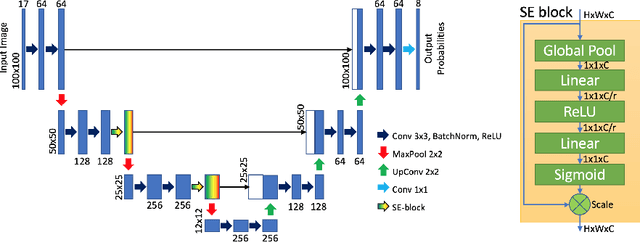
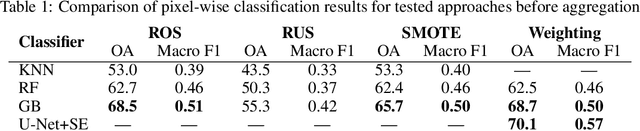
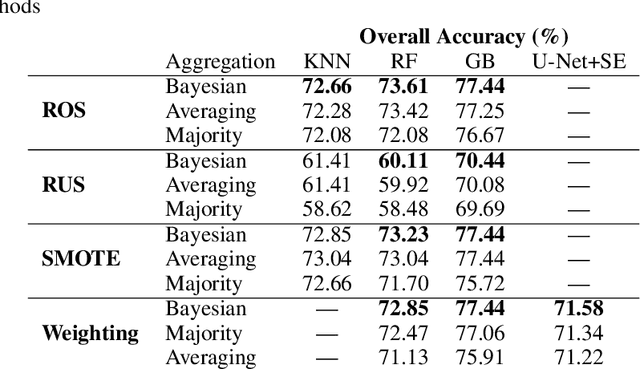

Machine learning (ML) methods and neural networks (NN) are widely implemented for crop types recognition and classification based on satellite images. However, most of these studies use several multi-temporal images which could be inapplicable for cloudy regions. We present a comparison between the classical ML approaches and U-Net NN for classifying crops with a single satellite image. The results show the advantages of using field-wise classification over pixel-wise approach. We first used a Bayesian aggregation for field-wise classification and improved on 1.5% results between majority voting aggregation. The best result for single satellite image crop classification is achieved for gradient boosting with an overall accuracy of 77.4% and macro F1-score 0.66.
Lossless White Balance For Improved Lossless CFA Image and Video Compression
Sep 19, 2020
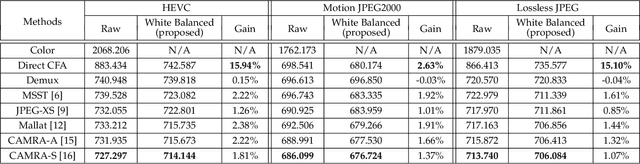


Color filter array is spatial multiplexing of pixel-sized filters placed over pixel detectors in camera sensors. The state-of-the-art lossless coding techniques of raw sensor data captured by such sensors leverage spatial or cross-color correlation using lifting schemes. In this paper, we propose a lifting-based lossless white balance algorithm. When applied to the raw sensor data, the spatial bandwidth of the implied chrominance signals decreases. We propose to use this white balance as a pre-processing step to lossless CFA subsampled image/video compression, improving the overall coding efficiency of the raw sensor data.