 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Pose Adaptive Dual Mixup for Few-Shot Single-View 3D Reconstruction
Dec 23, 2021
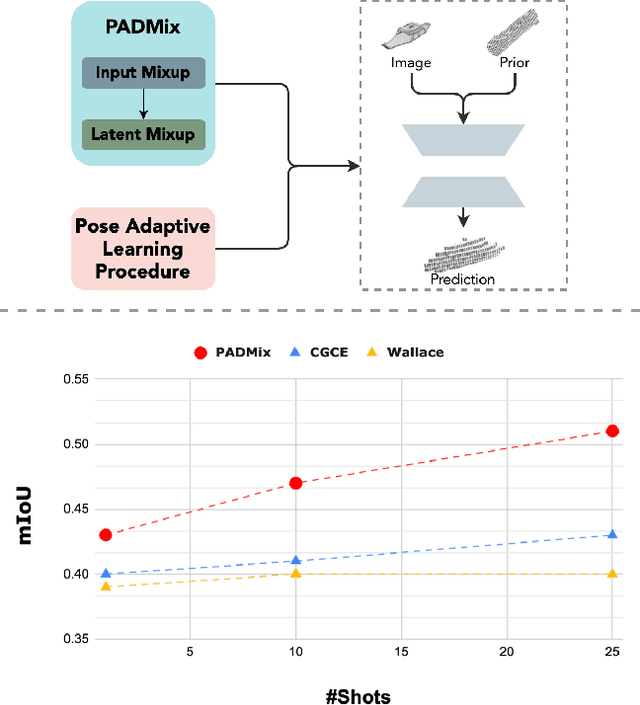
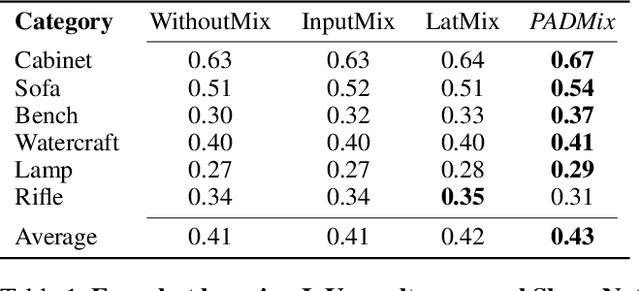
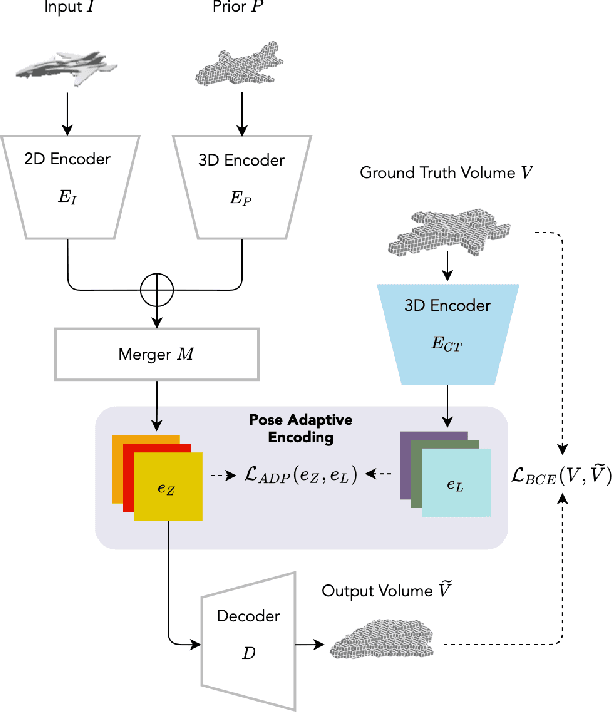
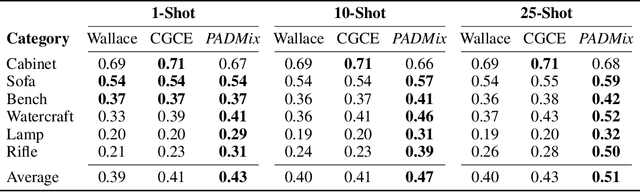
We present a pose adaptive few-shot learning procedure and a two-stage data interpolation regularization, termed Pose Adaptive Dual Mixup (PADMix), for single-image 3D reconstruction. While augmentations via interpolating feature-label pairs are effective in classification tasks, they fall short in shape predictions potentially due to inconsistencies between interpolated products of two images and volumes when rendering viewpoints are unknown. PADMix targets this issue with two sets of mixup procedures performed sequentially. We first perform an input mixup which, combined with a pose adaptive learning procedure, is helpful in learning 2D feature extraction and pose adaptive latent encoding. The stagewise training allows us to build upon the pose invariant representations to perform a follow-up latent mixup under one-to-one correspondences between features and ground-truth volumes. PADMix significantly outperforms previous literature on few-shot settings over the ShapeNet dataset and sets new benchmarks on the more challenging real-world Pix3D dataset.
Beyond Fixed Grid: Learning Geometric Image Representation with a Deformable Grid
Aug 21, 2020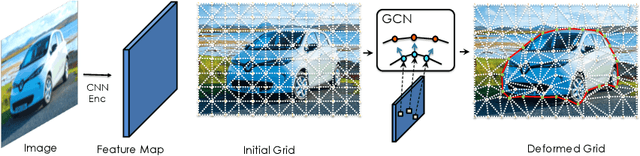

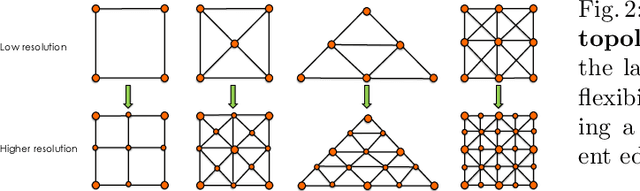

In modern computer vision, images are typically represented as a fixed uniform grid with some stride and processed via a deep convolutional neural network. We argue that deforming the grid to better align with the high-frequency image content is a more effective strategy. We introduce \emph{Deformable Grid} DefGrid, a learnable neural network module that predicts location offsets of vertices of a 2-dimensional triangular grid, such that the edges of the deformed grid align with image boundaries. We showcase our DefGrid in a variety of use cases, i.e., by inserting it as a module at various levels of processing. We utilize DefGrid as an end-to-end \emph{learnable geometric downsampling} layer that replaces standard pooling methods for reducing feature resolution when feeding images into a deep CNN. We show significantly improved results at the same grid resolution compared to using CNNs on uniform grids for the task of semantic segmentation. We also utilize DefGrid at the output layers for the task of object mask annotation, and show that reasoning about object boundaries on our predicted polygonal grid leads to more accurate results over existing pixel-wise and curve-based approaches. We finally showcase DefGrid as a standalone module for unsupervised image partitioning, showing superior performance over existing approaches. Project website: http://www.cs.toronto.edu/~jungao/def-grid
On the human-recognizability phenomenon of adversarially trained deep image classifiers
Dec 18, 2020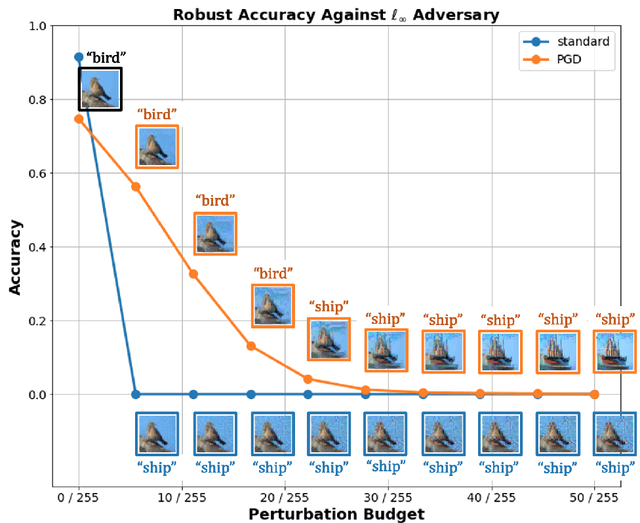
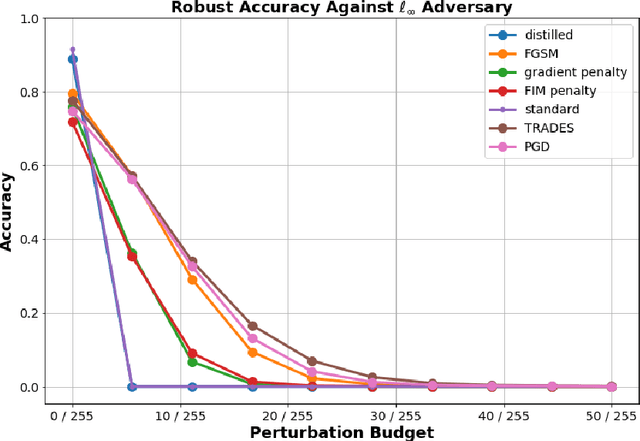

In this work, we investigate the phenomenon that robust image classifiers have human-recognizable features -- often referred to as interpretability -- as revealed through the input gradients of their score functions and their subsequent adversarial perturbations. In particular, we demonstrate that state-of-the-art methods for adversarial training incorporate two terms -- one that orients the decision boundary via minimizing the expected loss, and another that induces smoothness of the classifier's decision surface by penalizing the local Lipschitz constant. Through this demonstration, we provide a unified discussion of gradient and Jacobian-based regularizers that have been used to encourage adversarial robustness in prior works. Following this discussion, we give qualitative evidence that the coupling of smoothness and orientation of the decision boundary is sufficient to induce the aforementioned human-recognizability phenomenon.
A Method for Evaluating the Capacity of Generative Adversarial Networks to Reproduce High-order Spatial Context
Nov 24, 2021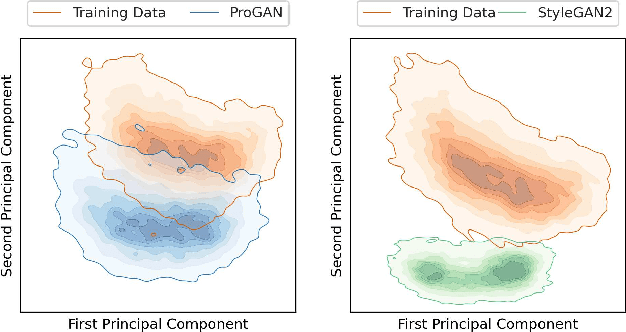
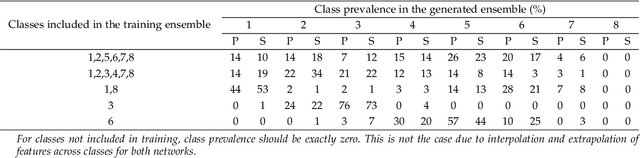

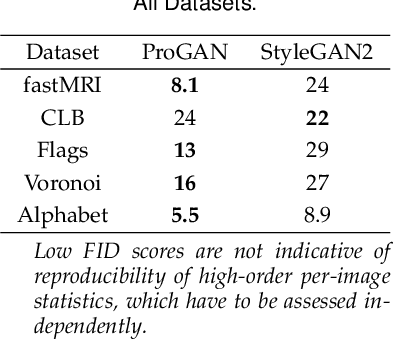
Generative adversarial networks are a kind of deep generative model with the potential to revolutionize biomedical imaging. This is because GANs have a learned capacity to draw whole-image variates from a lower-dimensional representation of an unknown, high-dimensional distribution that fully describes the input training images. The overarching problem with GANs in clinical applications is that there is not adequate or automatic means of assessing the diagnostic quality of images generated by GANs. In this work, we demonstrate several tests of the statistical accuracy of images output by two popular GAN architectures. We designed several stochastic object models (SOMs) of distinct features that can be recovered after generation by a trained GAN. Several of these features are high-order, algorithmic pixel-arrangement rules which are not readily expressed in covariance matrices. We designed and validated statistical classifiers to detect the known arrangement rules. We then tested the rates at which the different GANs correctly reproduced the rules under a variety of training scenarios and degrees of feature-class similarity. We found that ensembles of generated images can appear accurate visually, and correspond to low Frechet Inception Distance scores (FID), while not exhibiting the known spatial arrangements. Furthermore, GANs trained on a spectrum of distinct spatial orders did not respect the given prevalence of those orders in the training data. The main conclusion is that while low-order ensemble statistics are largely correct, there are numerous quantifiable errors per image that plausibly can affect subsequent use of the GAN-generated images.
Syn2Real Transfer Learning for Image Deraining using Gaussian Processes
Jun 10, 2020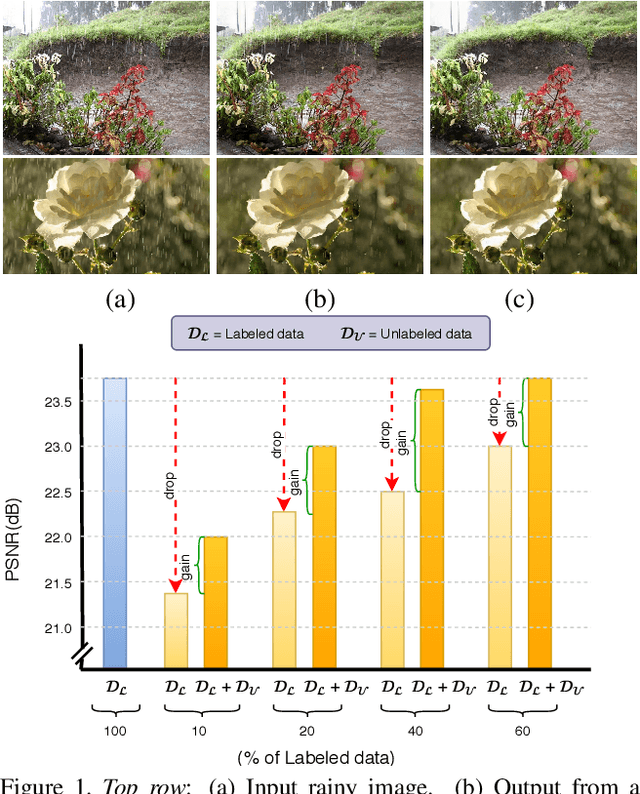


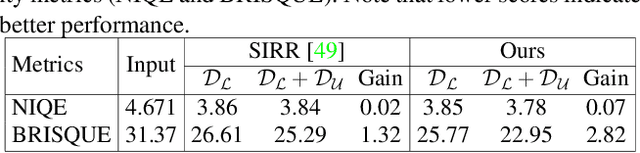
Recent CNN-based methods for image deraining have achieved excellent performance in terms of reconstruction error as well as visual quality. However, these methods are limited in the sense that they can be trained only on fully labeled data. Due to various challenges in obtaining real world fully-labeled image deraining datasets, existing methods are trained only on synthetically generated data and hence, generalize poorly to real-world images. The use of real-world data in training image deraining networks is relatively less explored in the literature. We propose a Gaussian Process-based semi-supervised learning framework which enables the network in learning to derain using synthetic dataset while generalizing better using unlabeled real-world images. Through extensive experiments and ablations on several challenging datasets (such as Rain800, Rain200H and DDN-SIRR), we show that the proposed method, when trained on limited labeled data, achieves on-par performance with fully-labeled training. Additionally, we demonstrate that using unlabeled real-world images in the proposed GP-based framework results in superior performance as compared to existing methods. Code is available at: https://github.com/rajeevyasarla/Syn2Real
Bombus Species Image Classification
Jun 09, 2020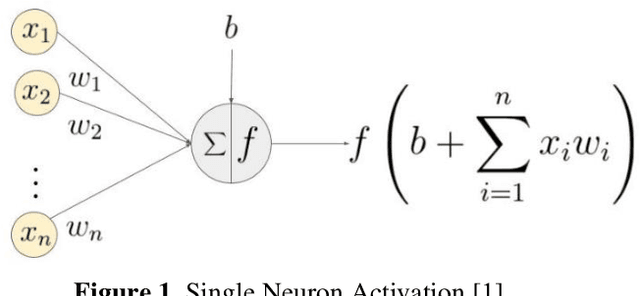
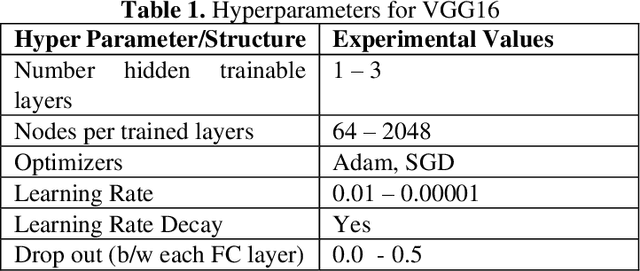
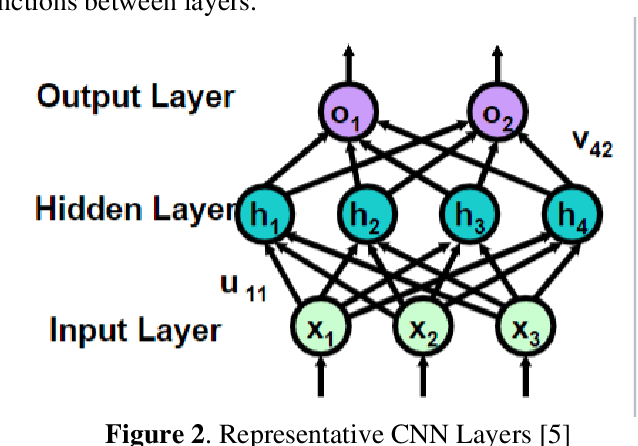
Entomologists, ecologists and others struggle to rapidly and accurately identify the species of bumble bees they encounter in their field work and research. The current process requires the bees to be mounted, then physically shipped to a taxonomic expert for proper categorization. We investigated whether an image classification system derived from transfer learning can do this task. We used Google Inception, Oxford VGG16 and VGG19 and Microsoft ResNet 50. We found Inception and VGG classifiers were able to make some progress at identifying bumble bee species from the available data, whereas ResNet was not. Individual classifiers achieved accuracies of up to 23% for single species identification and 44% top-3 labels, where a composite model performed better, 27% and 50%. We feel the performance was most hampered by our limited data set of 5,000-plus labeled images of 29 species, with individual species represented by 59 -315 images.
Unsupervised Domain Adaptation for Cross-Modality Retinal Vessel Segmentation via Disentangling Representation Style Transfer and Collaborative Consistency Learning
Jan 15, 2022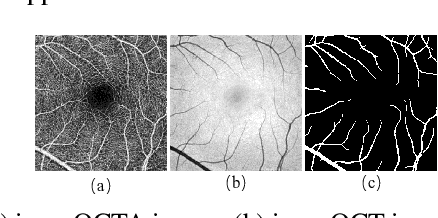
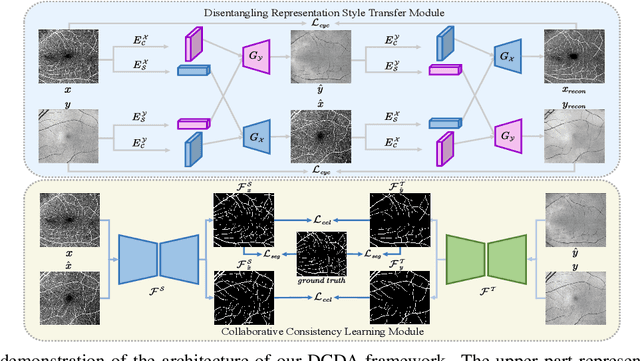
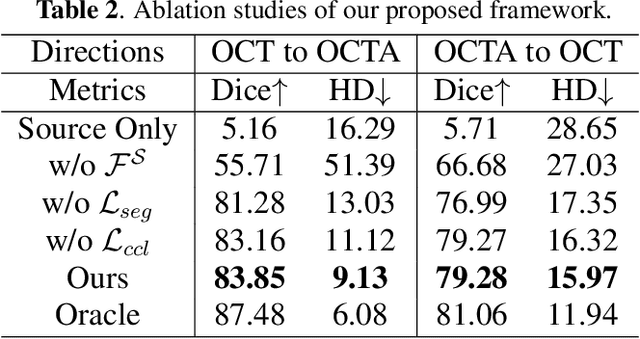
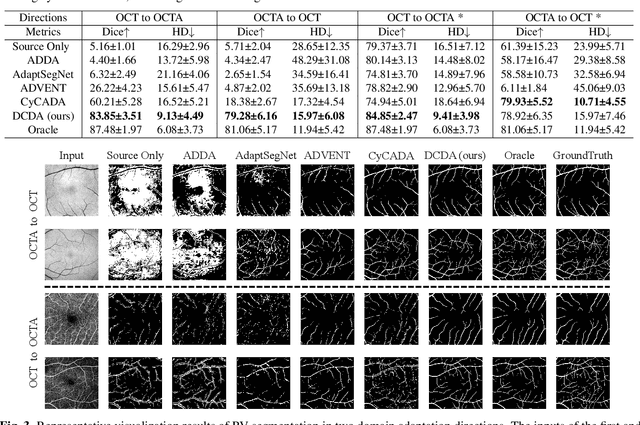
Various deep learning models have been developed to segment anatomical structures from medical images, but they typically have poor performance when tested on another target domain with different data distribution. Recently, unsupervised domain adaptation methods have been proposed to alleviate this so-called domain shift issue, but most of them are designed for scenarios with relatively small domain shifts and are likely to fail when encountering a large domain gap. In this paper, we propose DCDA, a novel cross-modality unsupervised domain adaptation framework for tasks with large domain shifts, e.g., segmenting retinal vessels from OCTA and OCT images. DCDA mainly consists of a disentangling representation style transfer (DRST) module and a collaborative consistency learning (CCL) module. DRST decomposes images into content components and style codes and performs style transfer and image reconstruction. CCL contains two segmentation models, one for source domain and the other for target domain. The two models use labeled data (together with the corresponding transferred images) for supervised learning and perform collaborative consistency learning on unlabeled data. Each model focuses on the corresponding single domain and aims to yield an expertized domain-specific segmentation model. Through extensive experiments on retinal vessel segmentation, our framework achieves Dice scores close to target-trained oracle both from OCTA to OCT and from OCT to OCTA, significantly outperforming other state-of-the-art methods.
Signal Reconstruction from Quantized Noisy Samples of the Discrete Fourier Transform
Jan 09, 2022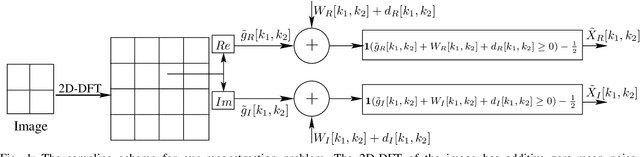

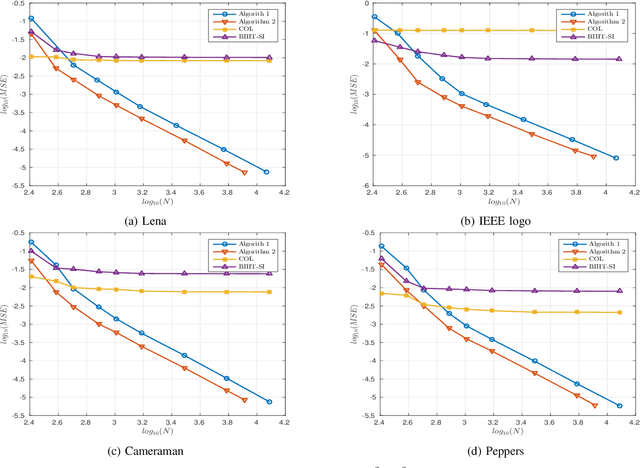

In this paper, we present two variations of an algorithm for signal reconstruction from one-bit or two-bit noisy observations of the discrete Fourier transform (DFT). The one-bit observations of the DFT correspond to the sign of its real part, whereas, the two-bit observations of the DFT correspond to the signs of both the real and imaginary parts of the DFT. We focus on images for analysis and simulations, thus using the sign of the 2D-DFT. This choice of the class of signals is inspired by previous works on this problem. For our algorithm, we show that the expected mean squared error (MSE) in signal reconstruction is asymptotically proportional to the inverse of the sampling rate. The samples are affected by additive zero-mean noise of known distribution. We solve this signal estimation problem by designing an algorithm that uses contraction mapping, based on the Banach fixed point theorem. Numerical tests with four benchmark images are provided to show the effectiveness of our algorithm. Various metrics for image reconstruction quality assessment such as PSNR, SSIM, ESSIM, and MS-SSIM are employed. On all four benchmark images, our algorithm outperforms the state-of-the-art in all of these metrics by a significant margin.
IVS3D: An Open Source Framework for Intelligent Video Sampling and Preprocessing to Facilitate 3D Reconstruction
Oct 22, 2021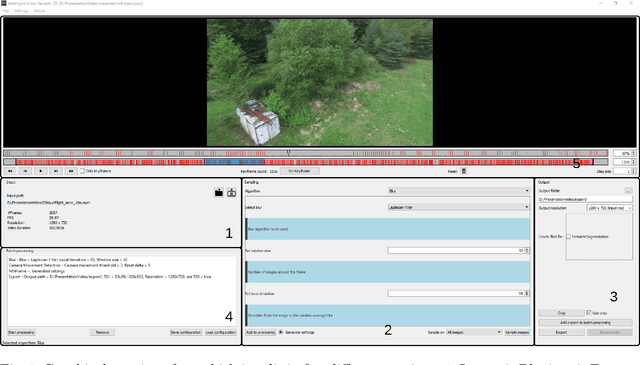
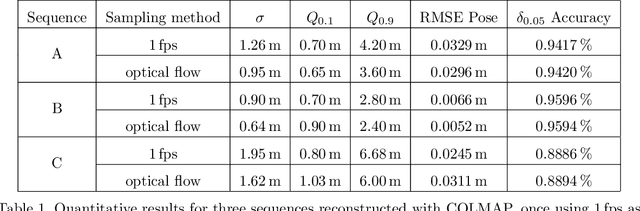

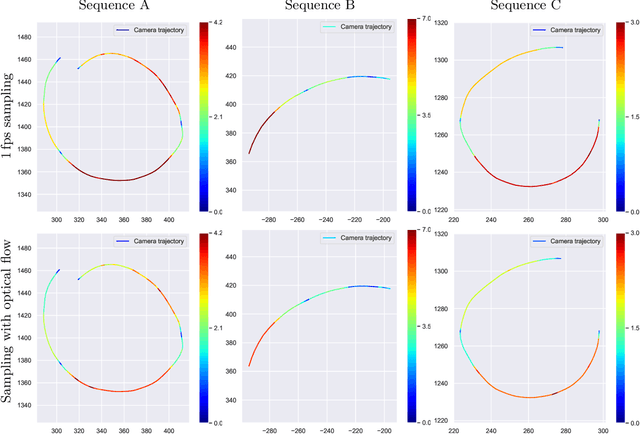
The creation of detailed 3D models is relevant for a wide range of applications such as navigation in three-dimensional space, construction planning or disaster assessment. However, the complex processing and long execution time for detailed 3D reconstructions require the original database to be reduced in order to obtain a result in reasonable time. In this paper we therefore present our framework iVS3D for intelligent pre-processing of image sequences. Our software is able to down sample entire videos to a specific frame rate, as well as to resize and crop the individual images. Furthermore, thanks to our modular architecture, it is easy to develop and integrate plugins with additional algorithms. We provide three plugins as baseline methods that enable an intelligent selection of suitable images and can enrich them with additional information. To filter out images affected by motion blur, we developed a plugin that detects these frames and also searches the spatial neighbourhood for suitable images as replacements. The second plugin uses optical flow to detect redundant images caused by a temporarily stationary camera. In our experiments, we show how this approach leads to a more balanced image sampling if the camera speed varies, and that excluding such redundant images leads to a time saving of 8.1\percent for our sequences. A third plugin makes it possible to exclude challenging image regions from the 3D reconstruction by performing semantic segmentation. As we think that the community can greatly benefit from such an approach, we will publish our framework and the developed plugins open source using the MIT licence to allow co-development and easy extension.
Postdisaster image-based damage detection and repair cost estimation of reinforced concrete buildings using dual convolutional neural networks
Nov 16, 2021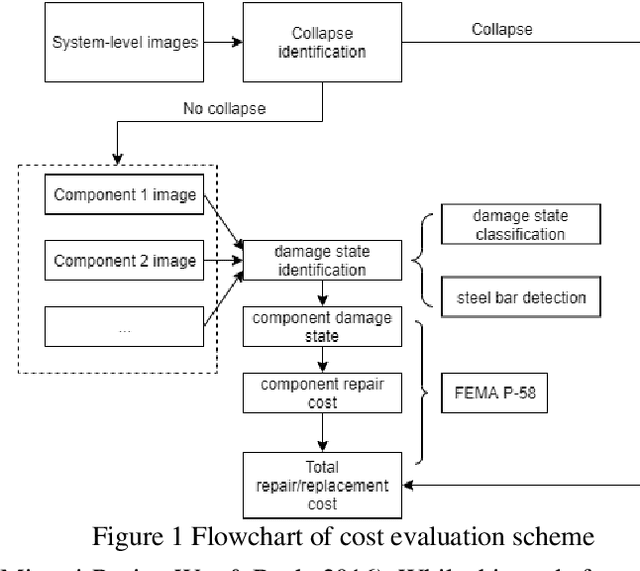

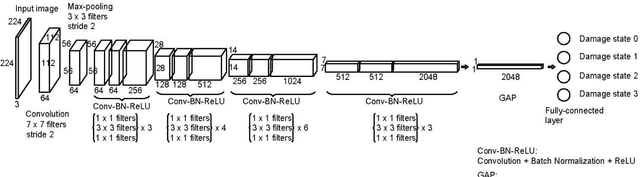
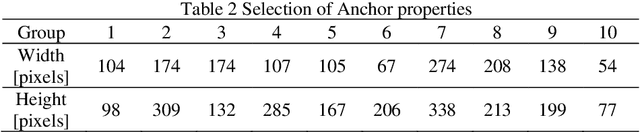
Reinforced concrete buildings are commonly used around the world. With recent earthquakes worldwide, rapid structural damage inspection and repair cost evaluation are crucial for building owners and policy makers to make informed risk management decisions. To improve the efficiency of such inspection, advanced computer vision techniques based on convolution neural networks have been adopted in recent research to rapidly quantify the damage state of structures. In this paper, an advanced object detection neural network, named YOLO-v2, is implemented which achieves 98.2% and 84.5% average precision in training and testing, respectively. The proposed YOLO-v2 is used in combination with the classification neural network, which improves the identification accuracy for critical damage state of reinforced concrete structures by 7.5%. The improved classification procedures allow engineers to rapidly and more accurately quantify the damage states of the structure, and also localize the critical damage features. The identified damage state can then be integrated with the state-of-the-art performance evaluation framework to quantify the financial losses of critical reinforced concrete buildings. The results can be used by the building owners and decision makers to make informed risk management decisions immediately after the strong earthquake shaking. Hence, resources can be allocated rapidly to improve the resiliency of the community.
* 16 pages, 21 figures