 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Visual stream connectivity predicts assessments of image quality
Aug 16, 2020
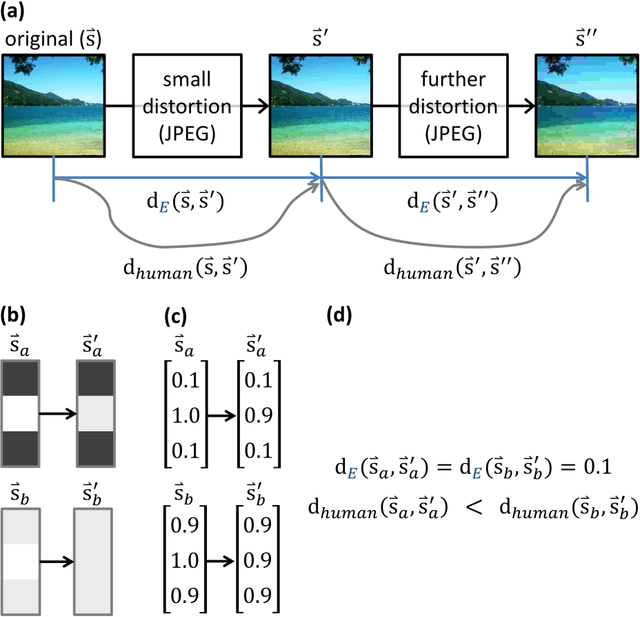
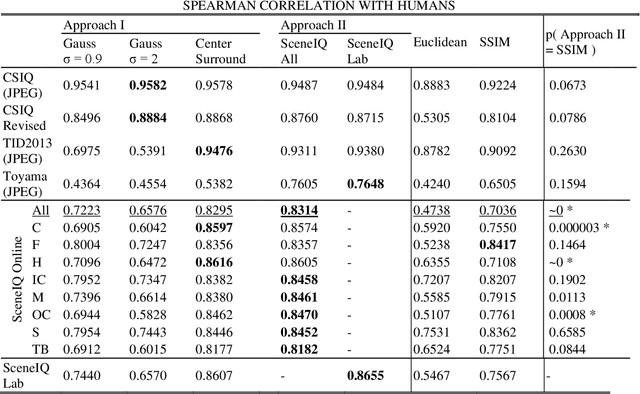
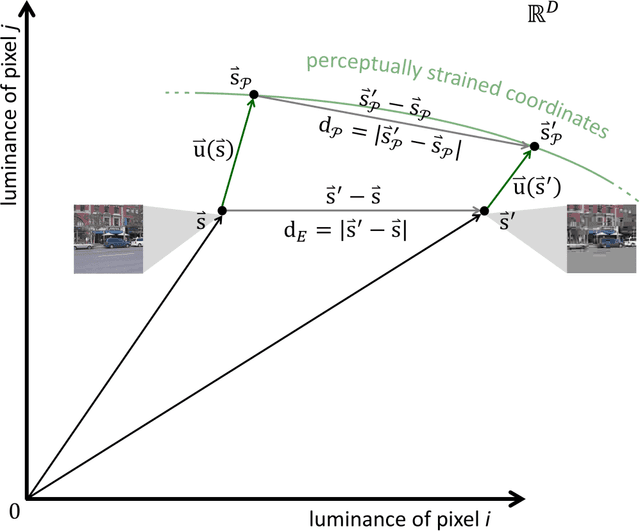
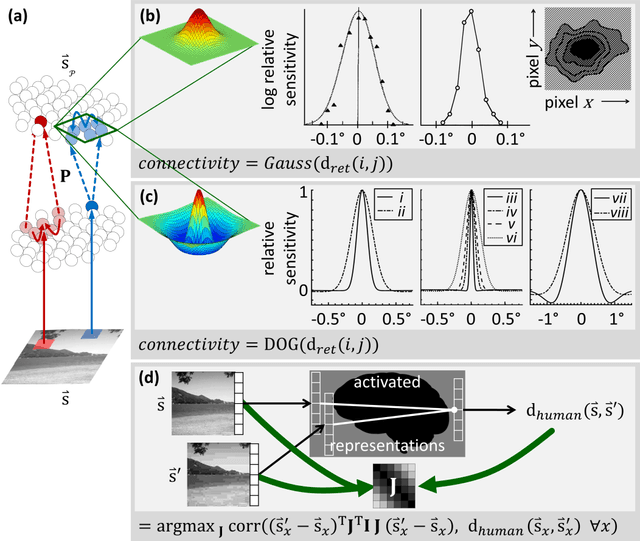
Some biological mechanisms of early vision are comparatively well understood, but they have yet to be evaluated for their ability to accurately predict and explain human judgments of image similarity. From well-studied simple connectivity patterns in early vision, we derive a novel formalization of the psychophysics of similarity, showing the differential geometry that provides accurate and explanatory accounts of perceptual similarity judgments. These predictions then are further improved via simple regression on human behavioral reports, which in turn are used to construct more elaborate hypothesized neural connectivity patterns. Both approaches outperform standard successful measures of perceived image fidelity from the literature, as well as providing explanatory principles of similarity perception.
COCO-FUNIT: Few-Shot Unsupervised Image Translation with a Content Conditioned Style Encoder
Jul 15, 2020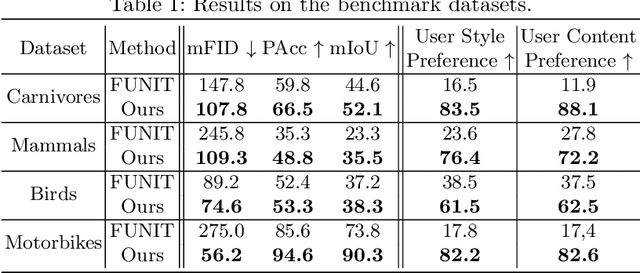
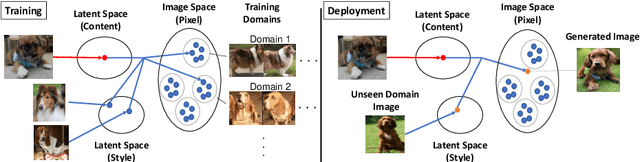
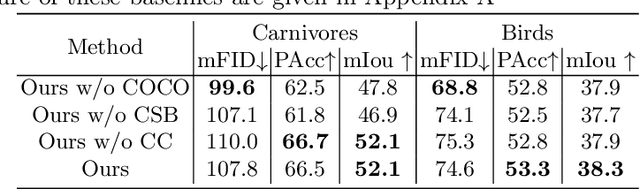

Unsupervised image-to-image translation intends to learn a mapping of an image in a given domain to an analogous image in a different domain, without explicit supervision of the mapping. Few-shot unsupervised image-to-image translation further attempts to generalize the model to an unseen domain by leveraging example images of the unseen domain provided at inference time. While remarkably successful, existing few-shot image-to-image translation models find it difficult to preserve the structure of the input image while emulating the appearance of the unseen domain, which we refer to as the \textit{content loss} problem. This is particularly severe when the poses of the objects in the input and example images are very different. To address the issue, we propose a new few-shot image translation model, \cocofunit, which computes the style embedding of the example images conditioned on the input image and a new module called the constant style bias. Through extensive experimental validations with comparison to the state-of-the-art, our model shows effectiveness in addressing the content loss problem. Code and pretrained models are available at https://nvlabs.github.io/COCO-FUNIT/ .
Hamilton-Jacobi equations on graphs with applications to semi-supervised learning and data depth
Feb 17, 2022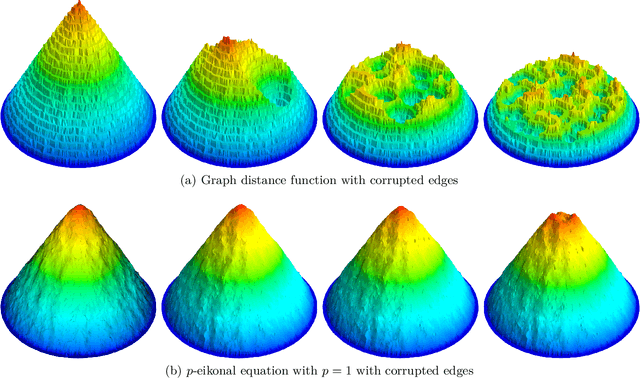
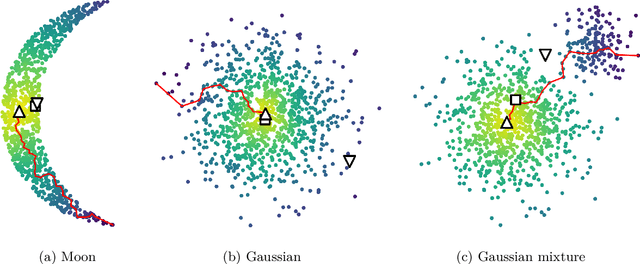
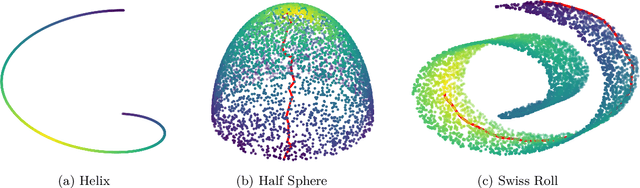
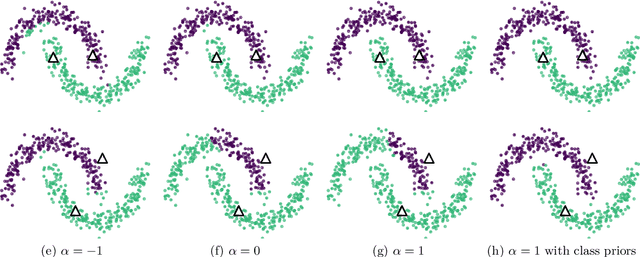
Shortest path graph distances are widely used in data science and machine learning, since they can approximate the underlying geodesic distance on the data manifold. However, the shortest path distance is highly sensitive to the addition of corrupted edges in the graph, either through noise or an adversarial perturbation. In this paper we study a family of Hamilton-Jacobi equations on graphs that we call the $p$-eikonal equation. We show that the $p$-eikonal equation with $p=1$ is a provably robust distance-type function on a graph, and the $p\to \infty$ limit recovers shortest path distances. While the $p$-eikonal equation does not correspond to a shortest-path graph distance, we nonetheless show that the continuum limit of the $p$-eikonal equation on a random geometric graph recovers a geodesic density weighted distance in the continuum. We consider applications of the $p$-eikonal equation to data depth and semi-supervised learning, and use the continuum limit to prove asymptotic consistency results for both applications. Finally, we show the results of experiments with data depth and semi-supervised learning on real image datasets, including MNIST, FashionMNIST and CIFAR-10, which show that the $p$-eikonal equation offers significantly better results compared to shortest path distances.
Supervised learning of sheared distributions using linearized optimal transport
Jan 25, 2022In this paper we study supervised learning tasks on the space of probability measures. We approach this problem by embedding the space of probability measures into $L^2$ spaces using the optimal transport framework. In the embedding spaces, regular machine learning techniques are used to achieve linear separability. This idea has proved successful in applications and when the classes to be separated are generated by shifts and scalings of a fixed measure. This paper extends the class of elementary transformations suitable for the framework to families of shearings, describing conditions under which two classes of sheared distributions can be linearly separated. We furthermore give necessary bounds on the transformations to achieve a pre-specified separation level, and show how multiple embeddings can be used to allow for larger families of transformations. We demonstrate our results on image classification tasks.
Accelerating Representation Learning with View-Consistent Dynamics in Data-Efficient Reinforcement Learning
Jan 18, 2022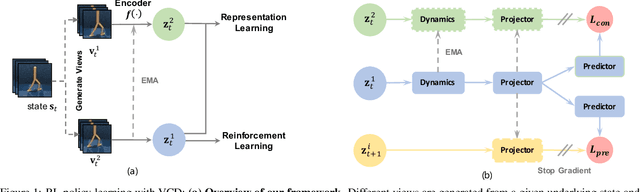
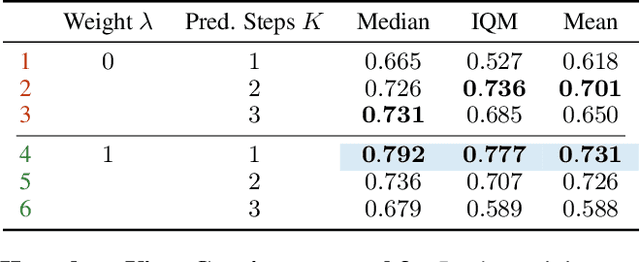
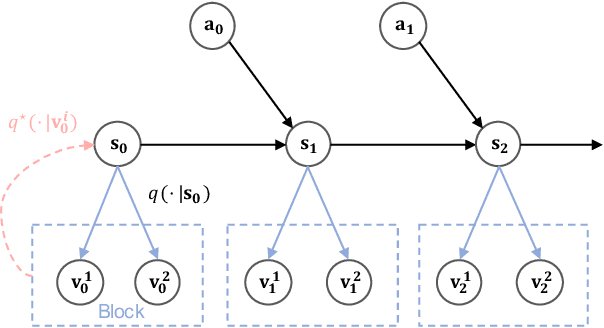
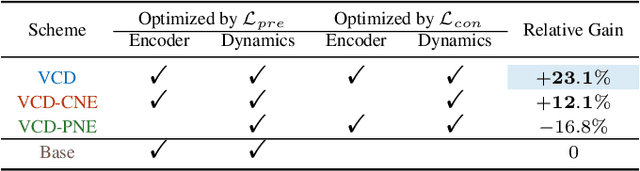
Learning informative representations from image-based observations is of fundamental concern in deep Reinforcement Learning (RL). However, data-inefficiency remains a significant barrier to this objective. To overcome this obstacle, we propose to accelerate state representation learning by enforcing view-consistency on the dynamics. Firstly, we introduce a formalism of Multi-view Markov Decision Process (MMDP) that incorporates multiple views of the state. Following the structure of MMDP, our method, View-Consistent Dynamics (VCD), learns state representations by training a view-consistent dynamics model in the latent space, where views are generated by applying data augmentation to states. Empirical evaluation on DeepMind Control Suite and Atari-100k demonstrates VCD to be the SoTA data-efficient algorithm on visual control tasks.
Segmentation of 2D Brain MR Images
Nov 05, 2021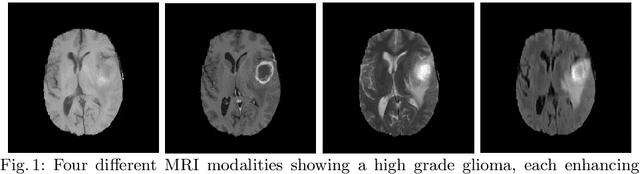

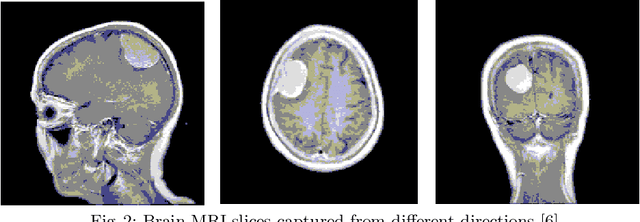
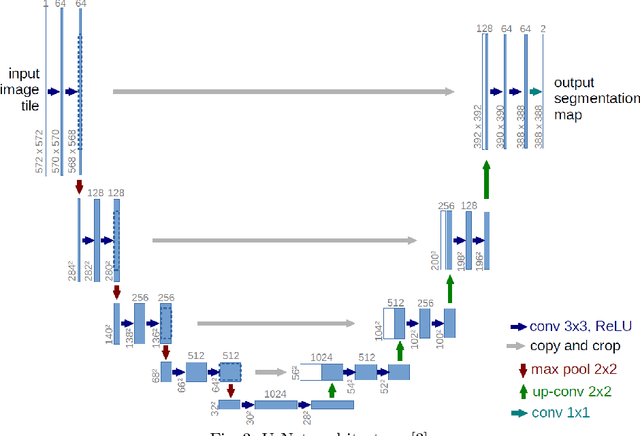
Brain tumour segmentation is an essential task in medical image processing. Early diagnosis of brain tumours plays a crucial role in improving treatment possibilities and increases the survival rate of the patients. Manual segmentation of the brain tumours for cancer diagnosis, from large number of MRI images, is both a difficult and time-consuming task. There is a need for automatic brain tumour image segmentation. The purpose of this project is to provide an automatic brain tumour segmentation method of MRI images to help locate the tumour accurately and quickly.
DGSS : Domain Generalized Semantic Segmentation using Iterative Style Mining and Latent Representation Alignment
Feb 26, 2022

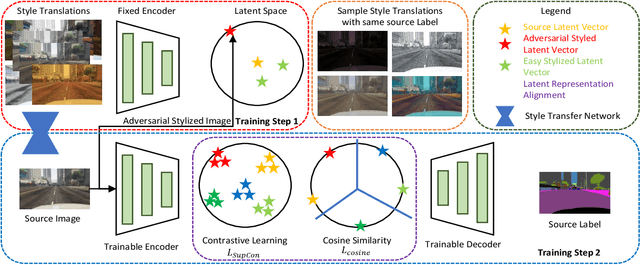

Semantic segmentation algorithms require access to well-annotated datasets captured under diverse illumination conditions to ensure consistent performance. However, poor visibility conditions at varying illumination conditions result in laborious and error-prone labeling. Alternatively, using synthetic samples to train segmentation algorithms has gained interest with the drawback of domain gap that results in sub-optimal performance. While current state-of-the-art (SoTA) have proposed different mechanisms to bridge the domain gap, they still perform poorly in low illumination conditions with an average performance drop of - 10.7 mIOU. In this paper, we focus upon single source domain generalization to overcome the domain gap and propose a two-step framework wherein we first identify an adversarial style that maximizes the domain gap between stylized and source images. Subsequently, these stylized images are used to categorically align features such that features belonging to the same class are clustered together in latent space, irrespective of domain gap. Furthermore, to increase intra-class variance while training, we propose a style mixing mechanism wherein the same objects from different styles are mixed to construct a new training image. This framework allows us to achieve a domain generalized semantic segmentation algorithm with consistent performance without prior information of the target domain while relying on a single source. Based on extensive experiments, we match SoTA performance on SYNTHIA $\to$ Cityscapes, GTAV $\to$ Cityscapes while setting new SoTA on GTAV $\to$ Dark Zurich and GTAV $\to$ Night Driving benchmarks without retraining.
Lossless Compression with Probabilistic Circuits
Nov 23, 2021
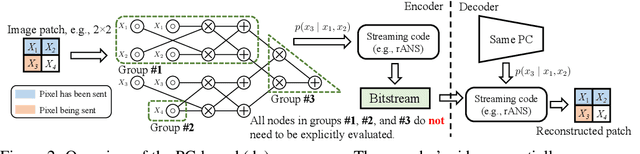
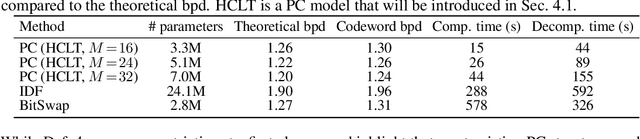
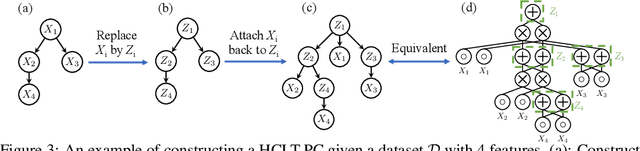
Despite extensive progress on image generation, deep generative models are suboptimal when applied to lossless compression. For example, models such as VAEs suffer from a compression cost overhead due to their latent variables that can only be partially eliminated with elaborated schemes such as bits-back coding, resulting in oftentimes poor single-sample compression rates. To overcome such problems, we establish a new class of tractable lossless compression models that permit efficient encoding and decoding: Probabilistic Circuits (PCs). These are a class of neural networks involving $|p|$ computational units that support efficient marginalization over arbitrary subsets of the $D$ feature dimensions, enabling efficient arithmetic coding. We derive efficient encoding and decoding schemes that both have time complexity $\mathcal{O} (\log(D) \cdot |p|)$, where a naive scheme would have linear costs in $D$ and $|p|$, making the approach highly scalable. Empirically, our PC-based (de)compression algorithm runs 5-20x faster than neural compression algorithms that achieve similar bitrates. By scaling up the traditional PC structure learning pipeline, we achieved state-of-the-art results on image datasets such as MNIST. Furthermore, PCs can be naturally integrated with existing neural compression algorithms to improve the performance of these base models on natural image datasets. Our results highlight the potential impact that non-standard learning architectures may have on neural data compression.
Tracking and Planning with Spatial World Models
Jan 25, 2022
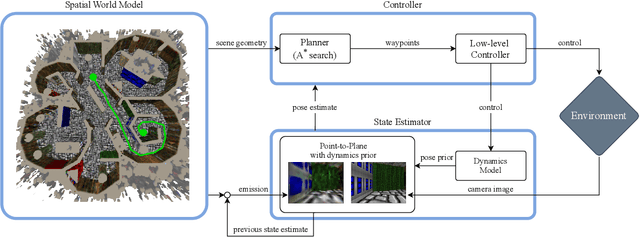
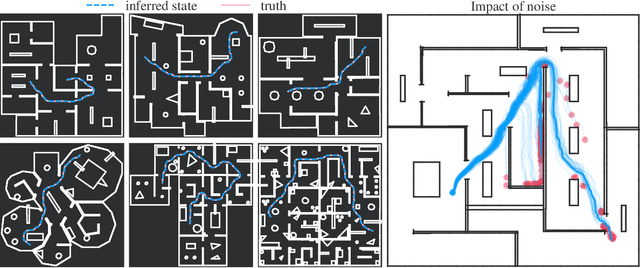
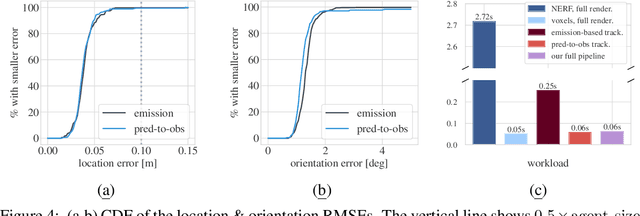
We introduce a method for real-time navigation and tracking with differentiably rendered world models. Learning models for control has led to impressive results in robotics and computer games, but this success has yet to be extended to vision-based navigation. To address this, we transfer advances in the emergent field of differentiable rendering to model-based control. We do this by planning in a learned 3D spatial world model, combined with a pose estimation algorithm previously used in the context of TSDF fusion, but now tailored to our setting and improved to incorporate agent dynamics. We evaluate over six simulated environments based on complex human-designed floor plans and provide quantitative results. We achieve up to 92% navigation success rate at a frequency of 15 Hz using only image and depth observations under stochastic, continuous dynamics.
Bridging the Gap: Point Clouds for Merging Neurons in Connectomics
Dec 10, 2021
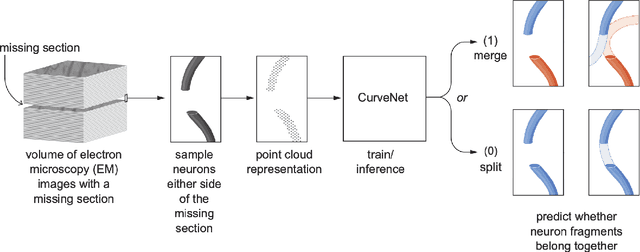

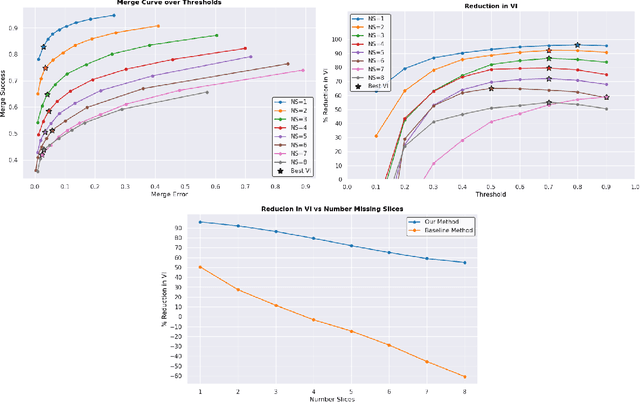
In the field of Connectomics, a primary problem is that of 3D neuron segmentation. Although deep learning-based methods have achieved remarkable accuracy, errors still exist, especially in regions with image defects. One common type of defect is that of consecutive missing image sections. Here, data is lost along some axis, and the resulting neuron segmentations are split across the gap. To address this problem, we propose a novel method based on point cloud representations of neurons. We formulate the problem as a classification problem and train CurveNet, a state-of-the-art point cloud classification model, to identify which neurons should be merged. We show that our method not only performs strongly but also scales reasonably to gaps well beyond what other methods have attempted to address. Additionally, our point cloud representations are highly efficient in terms of data, maintaining high performance with an amount of data that would be unfeasible for other methods. We believe that this is an indicator of the viability of using point cloud representations for other proofreading tasks.