 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Implicit and Explicit Attention for Zero-Shot Learning
Oct 02, 2021
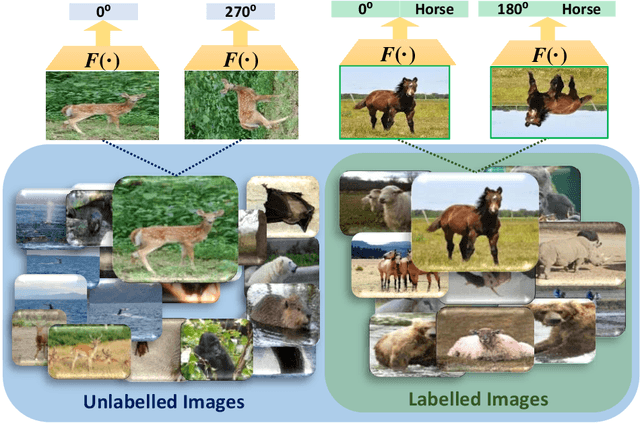
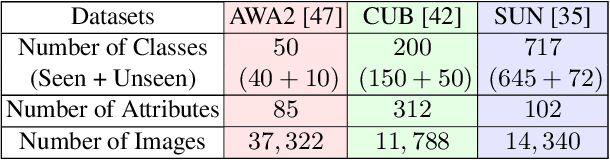
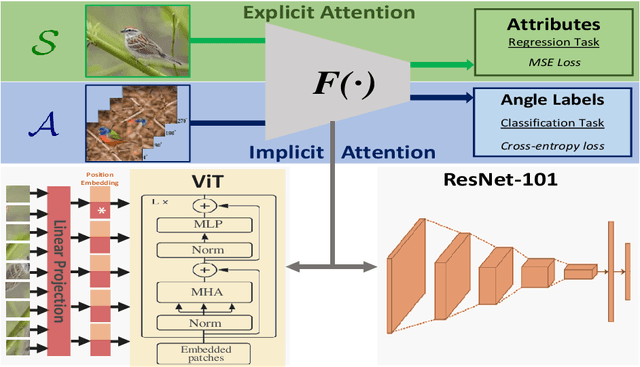
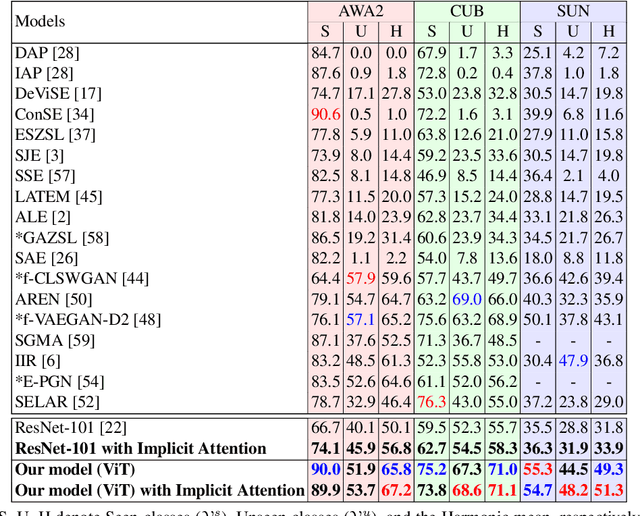
Most of the existing Zero-Shot Learning (ZSL) methods focus on learning a compatibility function between the image representation and class attributes. Few others concentrate on learning image representation combining local and global features. However, the existing approaches still fail to address the bias issue towards the seen classes. In this paper, we propose implicit and explicit attention mechanisms to address the existing bias problem in ZSL models. We formulate the implicit attention mechanism with a self-supervised image angle rotation task, which focuses on specific image features aiding to solve the task. The explicit attention mechanism is composed with the consideration of a multi-headed self-attention mechanism via Vision Transformer model, which learns to map image features to semantic space during the training stage. We conduct comprehensive experiments on three popular benchmarks: AWA2, CUB and SUN. The performance of our proposed attention mechanisms has proved its effectiveness, and has achieved the state-of-the-art harmonic mean on all the three datasets.
Importance Weighting Approach in Kernel Bayes' Rule
Feb 05, 2022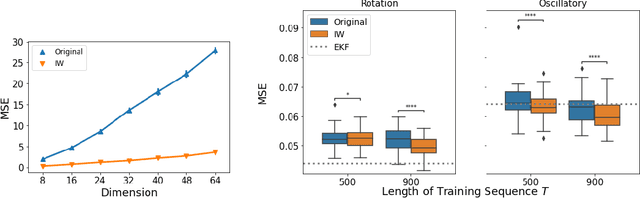
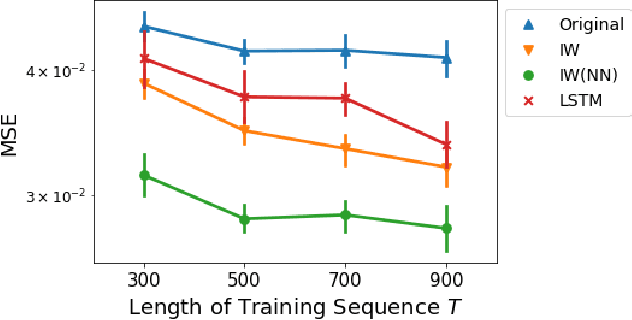
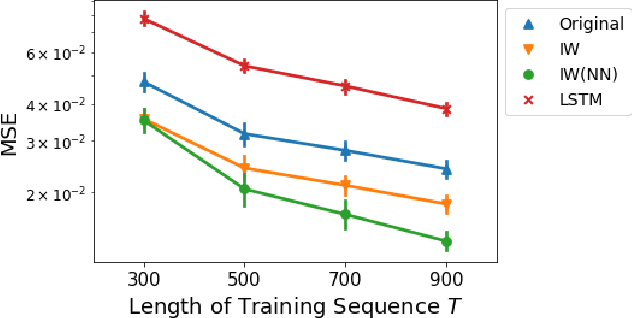
We study a nonparametric approach to Bayesian computation via feature means, where the expectation of prior features is updated to yield expected posterior features, based on regression from kernel or neural net features of the observations. All quantities involved in the Bayesian update are learned from observed data, making the method entirely model-free. The resulting algorithm is a novel instance of a kernel Bayes' rule (KBR). Our approach is based on importance weighting, which results in superior numerical stability to the existing approach to KBR, which requires operator inversion. We show the convergence of the estimator using a novel consistency analysis on the importance weighting estimator in the infinity norm. We evaluate our KBR on challenging synthetic benchmarks, including a filtering problem with a state-space model involving high dimensional image observations. The proposed method yields uniformly better empirical performance than the existing KBR, and competitive performance with other competing methods.
Multiclass Burn Wound Image Classification Using Deep Convolutional Neural Networks
Mar 01, 2021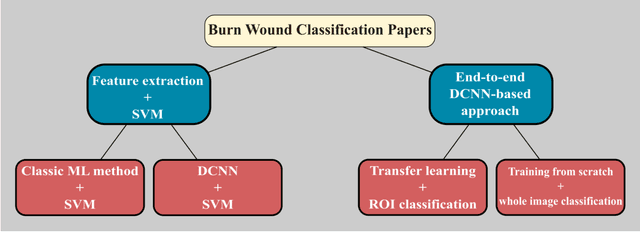
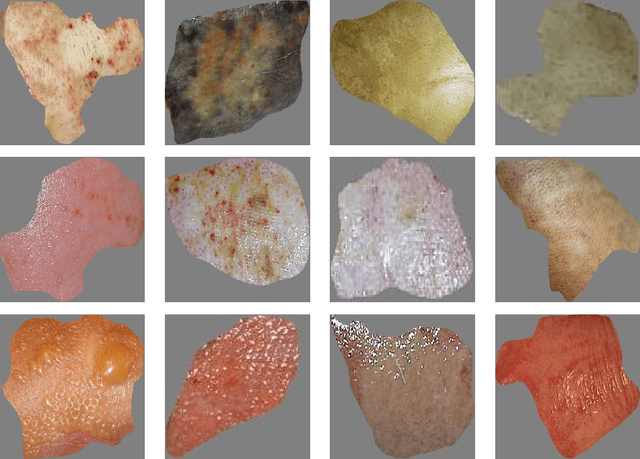
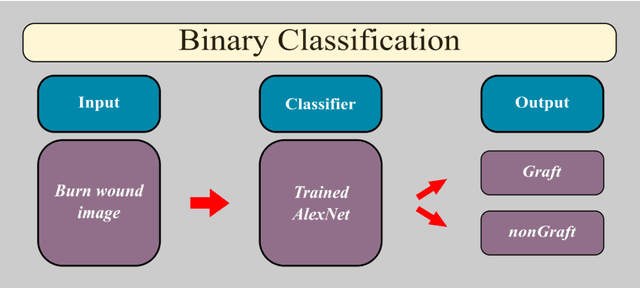
Millions of people are affected by acute and chronic wounds yearly across the world. Continuous wound monitoring is important for wound specialists to allow more accurate diagnosis and optimization of management protocols. Machine Learning-based classification approaches provide optimal care strategies resulting in more reliable outcomes, cost savings, healing time reduction, and improved patient satisfaction. In this study, we use a deep learning-based method to classify burn wound images into two or three different categories based on the wound conditions. A pre-trained deep convolutional neural network, AlexNet, is fine-tuned using a burn wound image dataset and utilized as the classifier. The classifier's performance is evaluated using classification metrics such as accuracy, precision, and recall as well as confusion matrix. A comparison with previous works that used the same dataset showed that our designed classifier improved the classification accuracy by more than 8%.
Controllable Animation of Fluid Elements in Still Images
Dec 06, 2021
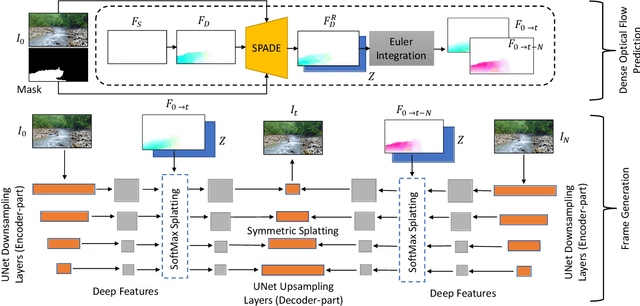
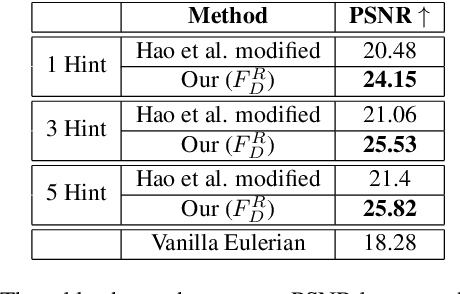

We propose a method to interactively control the animation of fluid elements in still images to generate cinemagraphs. Specifically, we focus on the animation of fluid elements like water, smoke, fire, which have the properties of repeating textures and continuous fluid motion. Taking inspiration from prior works, we represent the motion of such fluid elements in the image in the form of a constant 2D optical flow map. To this end, we allow the user to provide any number of arrow directions and their associated speeds along with a mask of the regions the user wants to animate. The user-provided input arrow directions, their corresponding speed values, and the mask are then converted into a dense flow map representing a constant optical flow map (FD). We observe that FD, obtained using simple exponential operations can closely approximate the plausible motion of elements in the image. We further refine computed dense optical flow map FD using a generative-adversarial network (GAN) to obtain a more realistic flow map. We devise a novel UNet based architecture to autoregressively generate future frames using the refined optical flow map by forward-warping the input image features at different resolutions. We conduct extensive experiments on a publicly available dataset and show that our method is superior to the baselines in terms of qualitative and quantitative metrics. In addition, we show the qualitative animations of the objects in directions that did not exist in the training set and provide a way to synthesize videos that otherwise would not exist in the real world.
Multi-view Gradient Consistency for SVBRDF Estimation of Complex Scenes under Natural Illumination
Feb 25, 2022
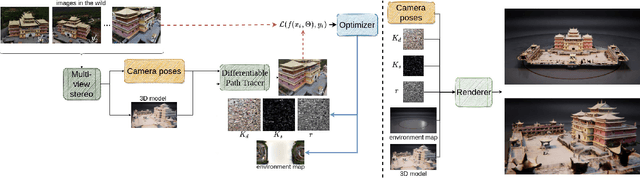


This paper presents a process for estimating the spatially varying surface reflectance of complex scenes observed under natural illumination. In contrast to previous methods, our process is not limited to scenes viewed under controlled lighting conditions but can handle complex indoor and outdoor scenes viewed under arbitrary illumination conditions. An end-to-end process uses a model of the scene's geometry and several images capturing the scene's surfaces from arbitrary viewpoints and under various natural illumination conditions. We develop a differentiable path tracer that leverages least-square conformal mapping for handling multiple disjoint objects appearing in the scene. We follow a two-step optimization process and introduce a multi-view gradient consistency loss which results in up to 30-50% improvement in the image reconstruction loss and can further achieve better disentanglement of the diffuse and specular BRDFs compared to other state-of-the-art. We demonstrate the process in real-world indoor and outdoor scenes from images in the wild and show that we can produce realistic renders consistent with actual images using the estimated reflectance properties. Experiments show that our technique produces realistic results for arbitrary outdoor scenes with complex geometry. The source code is publicly available at: https://gitlab.com/alen.joy/multi-view-gradient-consistency-for-svbrdf-estimation-of-complex-scenes-under-natural-illumination
Generalized Closed-form Formulae for Feature-based Subpixel Alignment in Patch-based Matching
Dec 02, 2021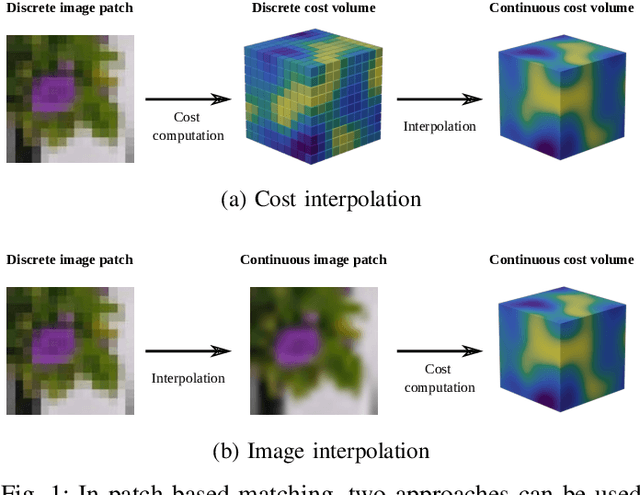

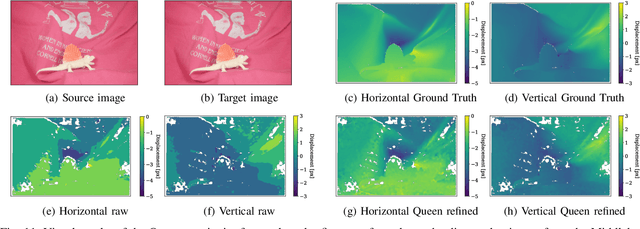
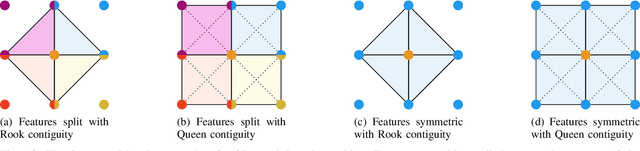
Cost-based image patch matching is at the core of various techniques in computer vision, photogrammetry and remote sensing. When the subpixel disparity between the reference patch in the source and target images is required, either the cost function or the target image have to be interpolated. While cost-based interpolation is the easiest to implement, multiple works have shown that image based interpolation can increase the accuracy of the subpixel matching, but usually at the cost of expensive search procedures. This, however, is problematic, especially for very computation intensive applications such as stereo matching or optical flow computation. In this paper, we show that closed form formulae for subpixel disparity computation for the case of one dimensional matching, e.g., in the case of rectified stereo images where the search space is of one dimension, exists when using the standard NCC, SSD and SAD cost functions. We then demonstrate how to generalize the proposed formulae to the case of high dimensional search spaces, which is required for unrectified stereo matching and optical flow extraction. We also compare our results with traditional cost volume interpolation formulae as well as with state-of-the-art cost-based refinement methods, and show that the proposed formulae bring a small improvement over the state-of-the-art cost-based methods in the case of one dimensional search spaces, and a significant improvement when the search space is two dimensional.
Local Feature Matching with Transformers for low-end devices
Feb 01, 2022LoFTR arXiv:2104.00680 is an efficient deep learning method for finding appropriate local feature matches on image pairs. This paper reports on the optimization of this method to work on devices with low computational performance and limited memory. The original LoFTR approach is based on a ResNet arXiv:1512.03385 head and two modules based on Linear Transformer arXiv:2006.04768 architecture. In the presented work, only the coarse-matching block was left, the number of parameters was significantly reduced, and the network was trained using a knowledge distillation technique. The comparison showed that this approach allows to obtain an appropriate feature detection accuracy for the student model compared to the teacher model in the coarse matching block, despite the significant reduction of model size. Also, the paper shows additional steps required to make model compatible with NVIDIA TensorRT runtime, and shows an approach to optimize training method for low-end GPUs.
Shallow-UWnet : Compressed Model for Underwater Image Enhancement
Jan 06, 2021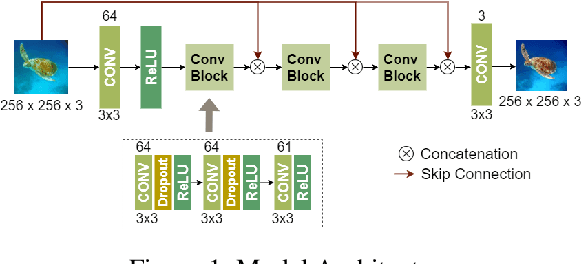
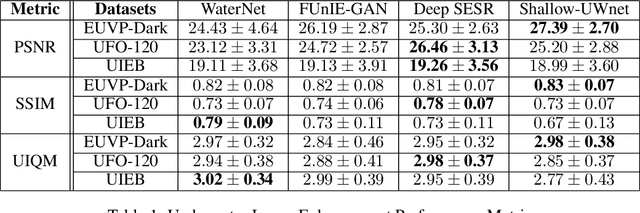


Over the past few decades, underwater image enhancement has attracted increasing amount of research effort due to its significance in underwater robotics and ocean engineering. Research has evolved from implementing physics-based solutions to using very deep CNNs and GANs. However, these state-of-art algorithms are computationally expensive and memory intensive. This hinders their deployment on portable devices for underwater exploration tasks. These models are trained on either synthetic or limited real world datasets making them less practical in real-world scenarios. In this paper we propose a shallow neural network architecture, \textbf{Shallow-UWnet} which maintains performance and has fewer parameters than the state-of-art models. We also demonstrated the generalization of our model by benchmarking its performance on combination of synthetic and real-world datasets.
Zero Experience Required: Plug & Play Modular Transfer Learning for Semantic Visual Navigation
Feb 05, 2022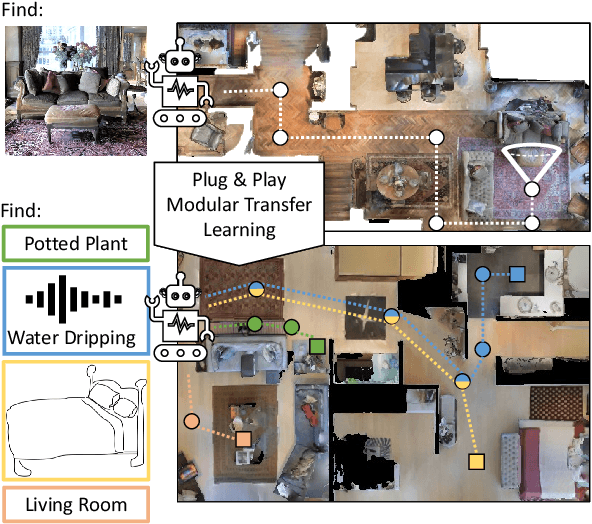
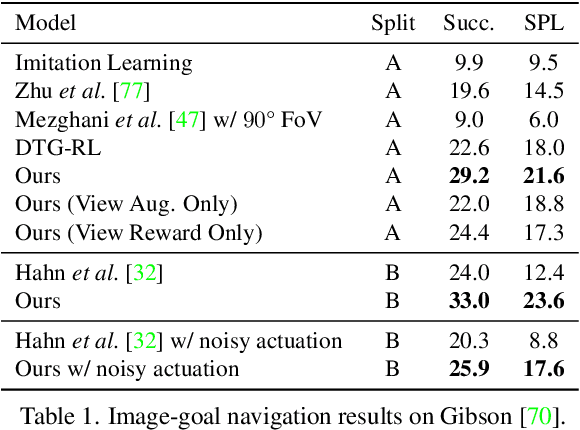
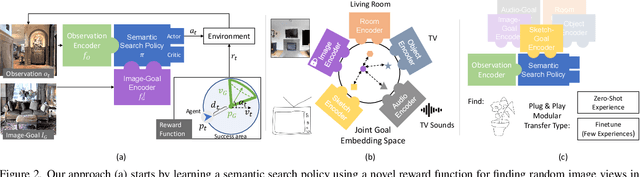
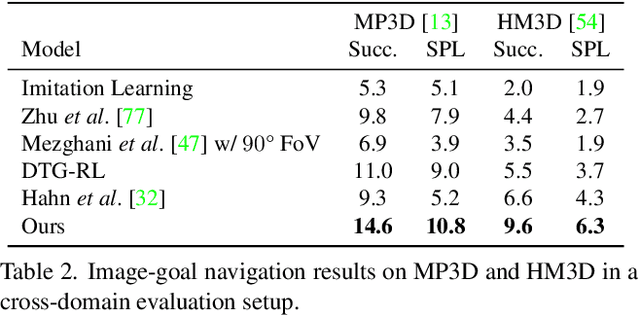
In reinforcement learning for visual navigation, it is common to develop a model for each new task, and train that model from scratch with task-specific interactions in 3D environments. However, this process is expensive; massive amounts of interactions are needed for the model to generalize well. Moreover, this process is repeated whenever there is a change in the task type or the goal modality. We present a unified approach to visual navigation using a novel modular transfer learning model. Our model can effectively leverage its experience from one source task and apply it to multiple target tasks (e.g., ObjectNav, RoomNav, ViewNav) with various goal modalities (e.g., image, sketch, audio, label). Furthermore, our model enables zero-shot experience learning, whereby it can solve the target tasks without receiving any task-specific interactive training. Our experiments on multiple photorealistic datasets and challenging tasks show that our approach learns faster, generalizes better, and outperforms SoTA models by a significant margin.
Towards Reducing Severe Defocus Spread Effects for Multi-Focus Image Fusion via an Optimization Based Strategy
Dec 29, 2020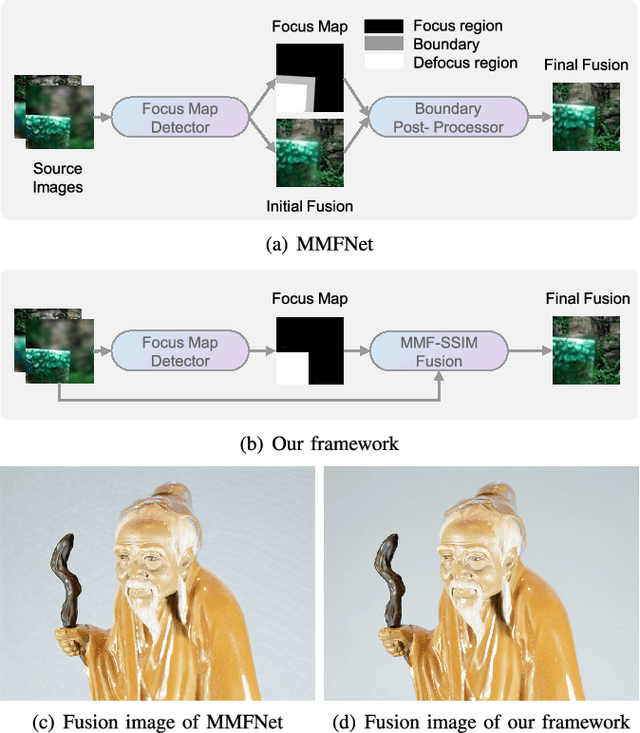
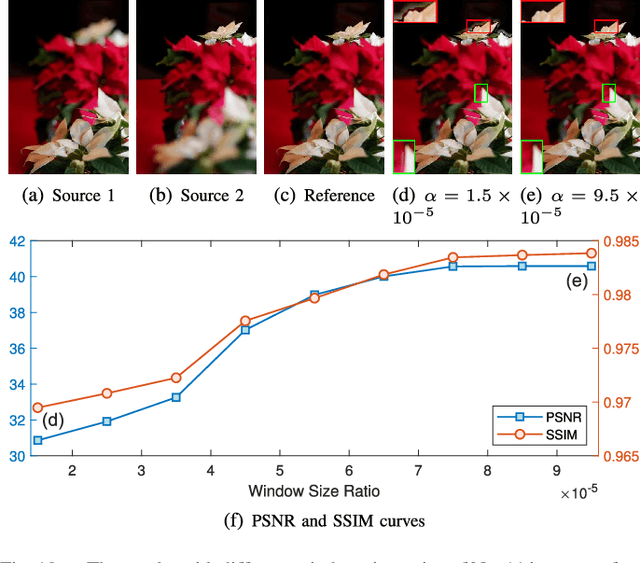


Multi-focus image fusion (MFF) is a popular technique to generate an all-in-focus image, where all objects in the scene are sharp. However, existing methods pay little attention to defocus spread effects of the real-world multi-focus images. Consequently, most of the methods perform badly in the areas near focus map boundaries. According to the idea that each local region in the fused image should be similar to the sharpest one among source images, this paper presents an optimization-based approach to reduce defocus spread effects. Firstly, a new MFF assessmentmetric is presented by combining the principle of structure similarity and detected focus maps. Then, MFF problem is cast into maximizing this metric. The optimization is solved by gradient ascent. Experiments conducted on the real-world dataset verify superiority of the proposed model. The codes are available at https://github.com/xsxjtu/MFF-SSIM.