 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ALAP-AE: As-Lite-as-Possible Auto-Encoder
Mar 19, 2022
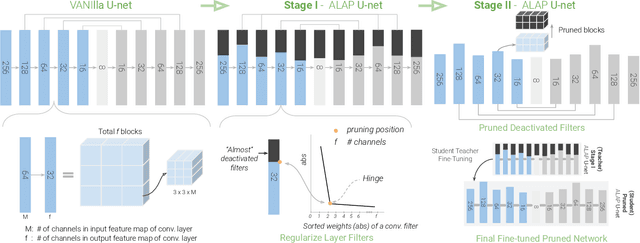
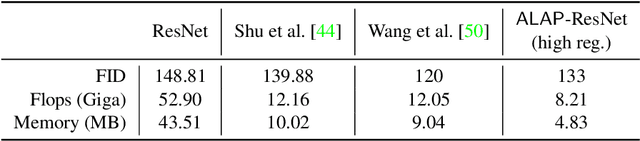
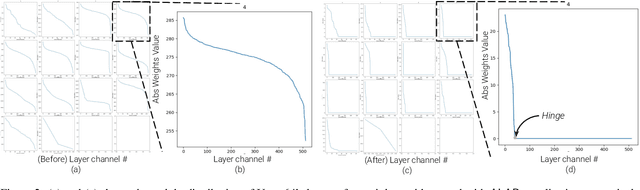
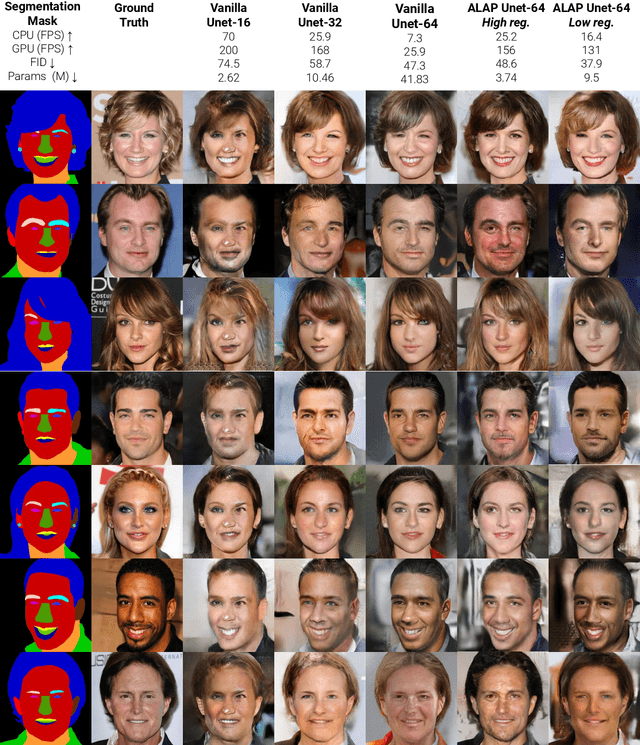
We present a novel algorithm to reduce tensor compute required by a conditional image generation autoencoder and make it as-lite-as-possible, without sacrificing quality of photo-realistic image generation. Our method is device agnostic, and can optimize an autoencoder for a given CPU-only, GPU compute device(s) in about normal time it takes to train an autoencoder on a generic workstation. We achieve this via a two-stage novel strategy where, first, we condense the channel weights, such that, as few as possible channels are used. Then, we prune the nearly zeroed out weight activations, and fine-tune this lite autoencoder. To maintain image quality, fine-tuning is done via student-teacher training, where we reuse the condensed autoencoder as the teacher. We show performance gains for various conditional image generation tasks: segmentation mask to face images, face images to cartoonization, and finally CycleGAN-based model on horse to zebra dataset over multiple compute devices. We perform various ablation studies to justify the claims and design choices, and achieve real-time versions of various autoencoders on CPU-only devices while maintaining image quality, thus enabling at-scale deployment of such autoencoders.
Peripheral Vision Transformer
Jun 14, 2022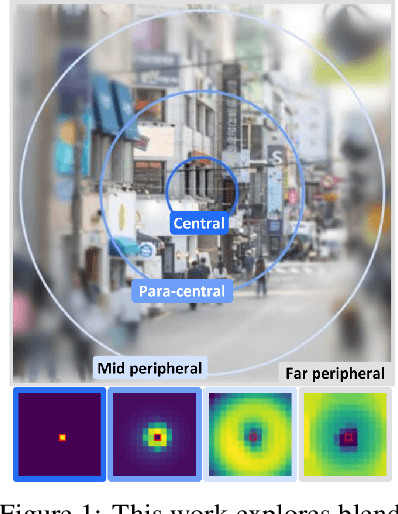
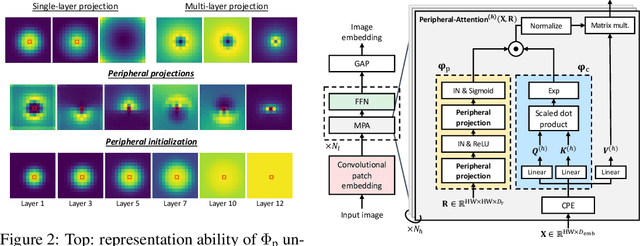

Human vision possesses a special type of visual processing systems called peripheral vision. Partitioning the entire visual field into multiple contour regions based on the distance to the center of our gaze, the peripheral vision provides us the ability to perceive various visual features at different regions. In this work, we take a biologically inspired approach and explore to model peripheral vision in deep neural networks for visual recognition. We propose to incorporate peripheral position encoding to the multi-head self-attention layers to let the network learn to partition the visual field into diverse peripheral regions given training data. We evaluate the proposed network, dubbed PerViT, on the large-scale ImageNet dataset and systematically investigate the inner workings of the model for machine perception, showing that the network learns to perceive visual data similarly to the way that human vision does. The state-of-the-art performance in image classification task across various model sizes demonstrates the efficacy of the proposed method.
Investigating Shift-Variance of Convolutional Neural Networks in Ultrasound Image Segmentation
Jul 22, 2021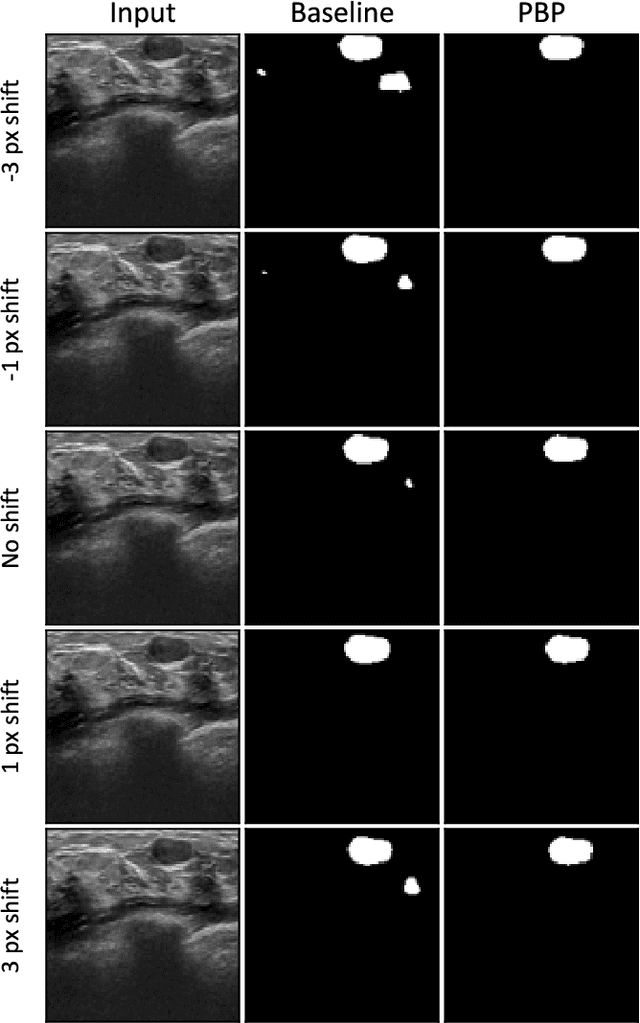
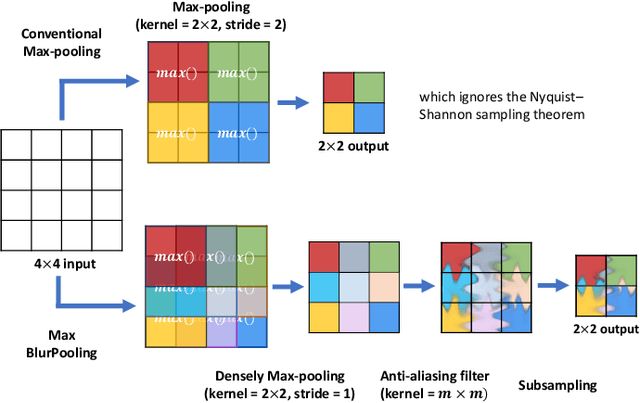
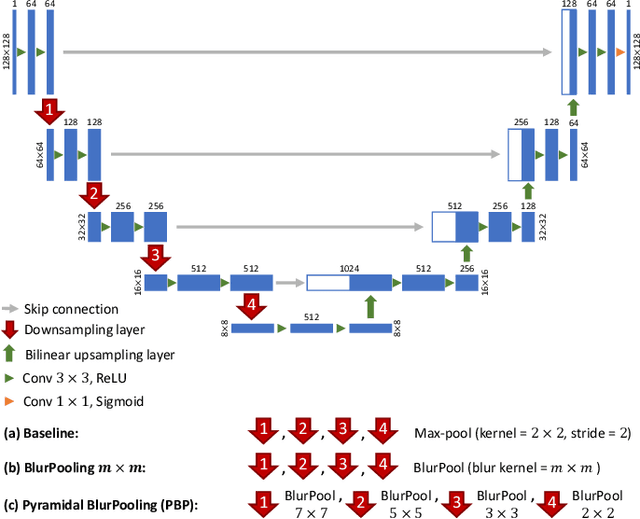
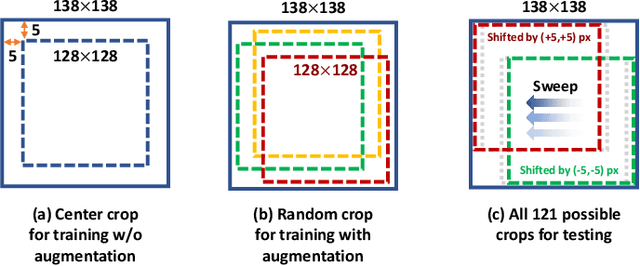
While accuracy is an evident criterion for ultrasound image segmentation, output consistency across different tests is equally crucial for tracking changes in regions of interest in applications such as monitoring the patients' response to treatment, measuring the progression or regression of the disease, reaching a diagnosis, or treatment planning. Convolutional neural networks (CNNs) have attracted rapidly growing interest in automatic ultrasound image segmentation recently. However, CNNs are not shift-equivariant, meaning that if the input translates, e.g., in the lateral direction by one pixel, the output segmentation may drastically change. To the best of our knowledge, this problem has not been studied in ultrasound image segmentation or even more broadly in ultrasound images. Herein, we investigate and quantify the shift-variance problem of CNNs in this application and further evaluate the performance of a recently published technique, called BlurPooling, for addressing the problem. In addition, we propose the Pyramidal BlurPooling method that outperforms BlurPooling in both output consistency and segmentation accuracy. Finally, we demonstrate that data augmentation is not a replacement for the proposed method. Source code is available at https://git.io/pbpunet and http://code.sonography.ai.
On Measuring and Controlling the Spectral Bias of the Deep Image Prior
Jul 02, 2021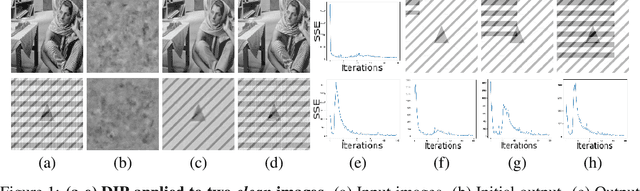

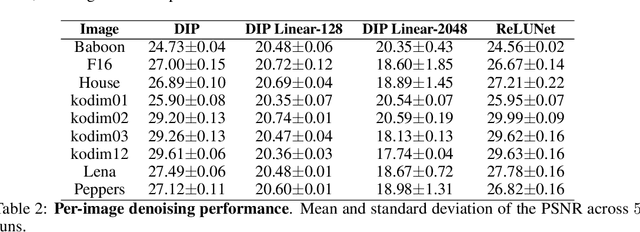
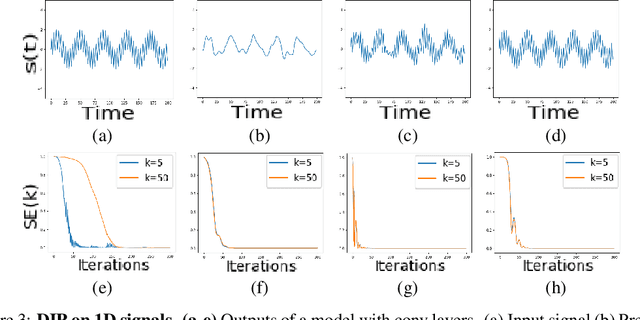
The deep image prior has demonstrated the remarkable ability that untrained networks can address inverse imaging problems, such as denoising, inpainting and super-resolution, by optimizing on just a single degraded image. Despite its promise, it suffers from two limitations. First, it remains unclear how one can control the prior beyond the choice of the network architecture. Second, it requires an oracle to determine when to stop the optimization as the performance degrades after reaching a peak. In this paper, we study the deep image prior from a spectral bias perspective to address these problems. By introducing a frequency-band correspondence measure, we observe that deep image priors for inverse imaging exhibit a spectral bias during optimization, where low-frequency image signals are learned faster and better than high-frequency noise signals. This pinpoints why degraded images can be denoised or inpainted when the optimization is stopped at the right time. Based on our observations, we propose to control the spectral bias in the deep image prior to prevent performance degradation and to speed up optimization convergence. We do so in the two core layer types of inverse imaging networks: the convolution layer and the upsampling layer. We present a Lipschitz-controlled approach for the convolution and a Gaussian-controlled approach for the upsampling layer. We further introduce a stopping criterion to avoid superfluous computation. The experiments on denoising, inpainting and super-resolution show that our method no longer suffers from performance degradation during optimization, relieving us from the need for an oracle criterion to stop early. We further outline a stopping criterion to avoid superfluous computation. Finally, we show that our approach obtains favorable restoration results compared to current approaches, across all tasks.
NP-DRAW: A Non-Parametric Structured Latent Variable Modelfor Image Generation
Jun 25, 2021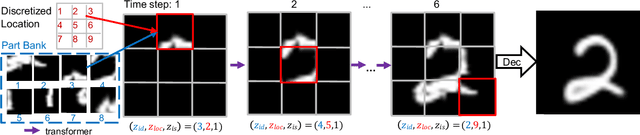
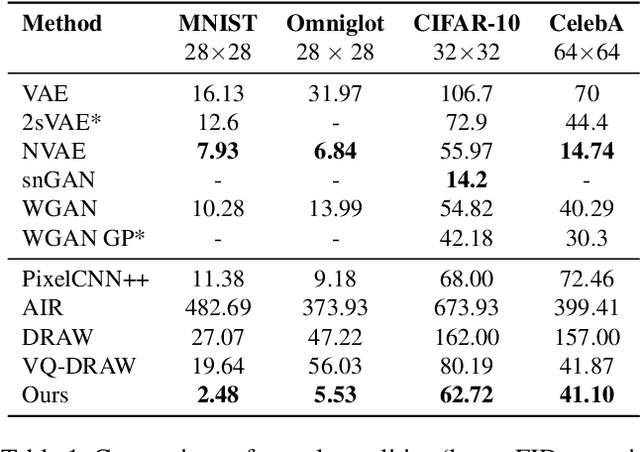
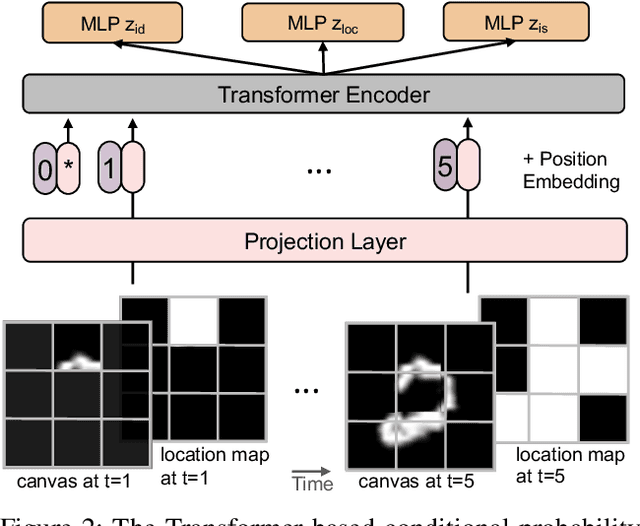
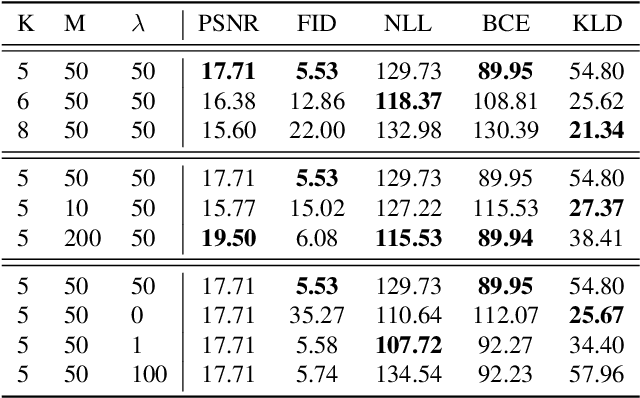
In this paper, we present a non-parametric structured latent variable model for image generation, called NP-DRAW, which sequentially draws on a latent canvas in a part-by-part fashion and then decodes the image from the canvas. Our key contributions are as follows. 1) We propose a non-parametric prior distribution over the appearance of image parts so that the latent variable ``what-to-draw'' per step becomes a categorical random variable. This improves the expressiveness and greatly eases the learning compared to Gaussians used in the literature. 2) We model the sequential dependency structure of parts via a Transformer, which is more powerful and easier to train compared to RNNs used in the literature. 3) We propose an effective heuristic parsing algorithm to pre-train the prior. Experiments on MNIST, Omniglot, CIFAR-10, and CelebA show that our method significantly outperforms previous structured image models like DRAW and AIR and is competitive to other generic generative models. Moreover, we show that our model's inherent compositionality and interpretability bring significant benefits in the low-data learning regime and latent space editing. Code is available at \url{https://github.com/ZENGXH/NPDRAW}.
Multispectral Satellite Data Classification using Soft Computing Approach
Mar 21, 2022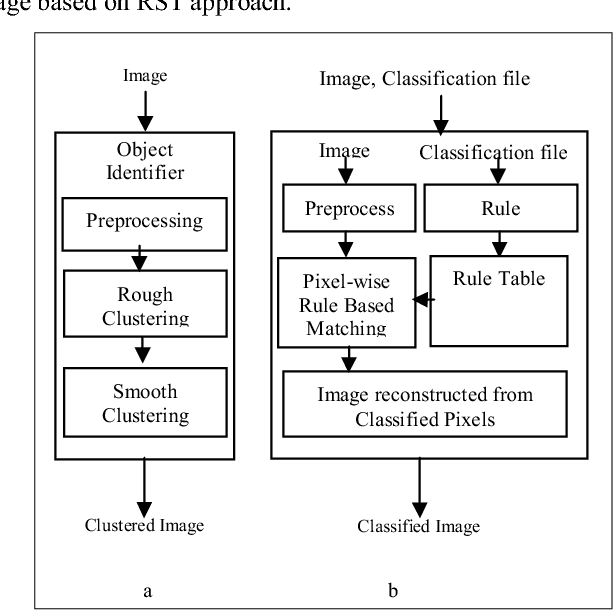

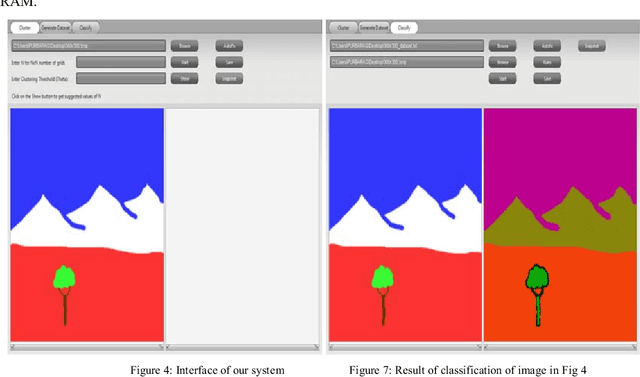

A satellite image is a remotely sensed image data, where each pixel represents a specific location on earth. The pixel value recorded is the reflection radiation from the earth's surface at that location. Multispectral images are those that capture image data at specific frequencies across the electromagnetic spectrum as compared to Panchromatic images which are sensitive to all wavelength of visible light. Because of the high resolution and high dimensions of these images, they create difficulties for clustering techniques to efficiently detect clusters of different sizes, shapes and densities as a trade off for fast processing time. In this paper we propose a grid-density based clustering technique for identification of objects. We also introduce an approach to classify a satellite image data using a rule induction based machine learning algorithm. The object identification and classification methods have been validated using several synthetic and benchmark datasets.
Improving Single-Image Defocus Deblurring: How Dual-Pixel Images Help Through Multi-Task Learning
Aug 11, 2021

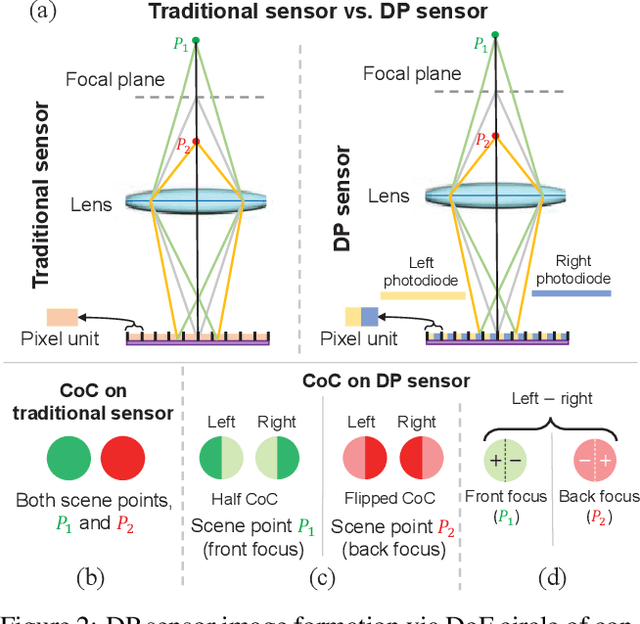
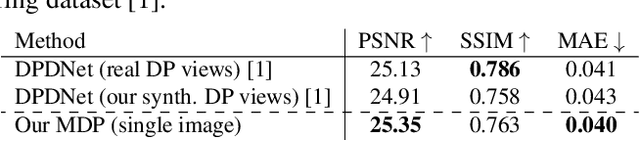
Many camera sensors use a dual-pixel (DP) design that operates as a rudimentary light field providing two sub-aperture views of a scene in a single capture. The DP sensor was developed to improve how cameras perform autofocus. Since the DP sensor's introduction, researchers have found additional uses for the DP data, such as depth estimation, reflection removal, and defocus deblurring. We are interested in the latter task of defocus deblurring. In particular, we propose a single-image deblurring network that incorporates the two sub-aperture views into a multi-task framework. Specifically, we show that jointly learning to predict the two DP views from a single blurry input image improves the network's ability to learn to deblur the image. Our experiments show this multi-task strategy achieves +1dB PSNR improvement over state-of-the-art defocus deblurring methods. In addition, our multi-task framework allows accurate DP-view synthesis (e.g., ~ 39dB PSNR) from the single input image. These high-quality DP views can be used for other DP-based applications, such as reflection removal. As part of this effort, we have captured a new dataset of 7,059 high-quality images to support our training for the DP-view synthesis task. Our dataset, code, and trained models will be made publicly available at https://github.com/Abdullah-Abuolaim/multi-task-defocus-deblurring-dual-pixel-nimat
Visual Radial Basis Q-Network
Jun 14, 2022While reinforcement learning (RL) from raw images has been largely investigated in the last decade, existing approaches still suffer from a number of constraints. The high input dimension is often handled using either expert knowledge to extract handcrafted features or environment encoding through convolutional networks. Both solutions require numerous parameters to be optimized. In contrast, we propose a generic method to extract sparse features from raw images with few trainable parameters. We achieved this using a Radial Basis Function Network (RBFN) directly on raw image. We evaluate the performance of the proposed approach for visual extraction in Q-learning tasks in the Vizdoom environment. Then, we compare our results with two Deep Q-Network, one trained directly on images and another one trained on feature extracted by a pretrained auto-encoder. We show that the proposed approach provides similar or, in some cases, even better performances with fewer trainable parameters while being conceptually simpler.
Ensemble of CNN classifiers using Sugeno Fuzzy Integral Technique for Cervical Cytology Image Classification
Aug 21, 2021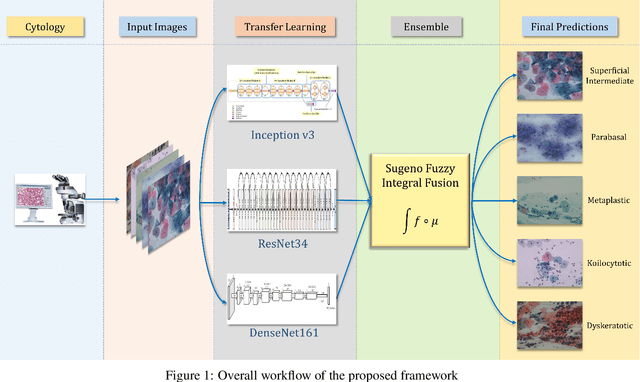
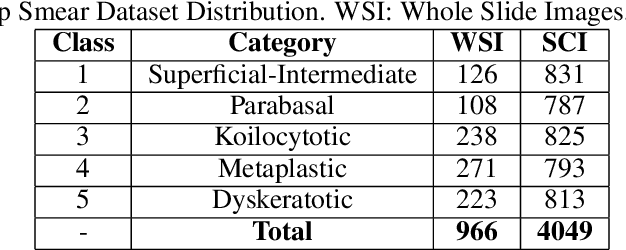
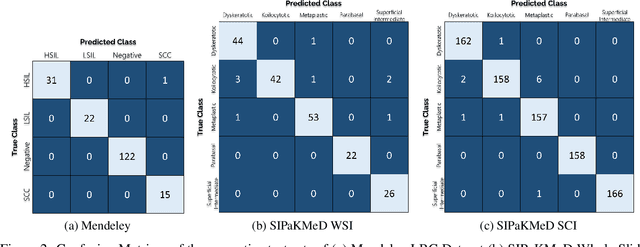
Cervical cancer is the fourth most common category of cancer, affecting more than 500,000 women annually, owing to the slow detection procedure. Early diagnosis can help in treating and even curing cancer, but the tedious, time-consuming testing process makes it impossible to conduct population-wise screening. To aid the pathologists in efficient and reliable detection, in this paper, we propose a fully automated computer-aided diagnosis tool for classifying single-cell and slide images of cervical cancer. The main concern in developing an automatic detection tool for biomedical image classification is the low availability of publicly accessible data. Ensemble Learning is a popular approach for image classification, but simplistic approaches that leverage pre-determined weights to classifiers fail to perform satisfactorily. In this research, we use the Sugeno Fuzzy Integral to ensemble the decision scores from three popular pretrained deep learning models, namely, Inception v3, DenseNet-161 and ResNet-34. The proposed Fuzzy fusion is capable of taking into consideration the confidence scores of the classifiers for each sample, and thus adaptively changing the importance given to each classifier, capturing the complementary information supplied by each, thus leading to superior classification performance. We evaluated the proposed method on three publicly available datasets, the Mendeley Liquid Based Cytology (LBC) dataset, the SIPaKMeD Whole Slide Image (WSI) dataset, and the SIPaKMeD Single Cell Image (SCI) dataset, and the results thus yielded are promising. Analysis of the approach using GradCAM-based visual representations and statistical tests, and comparison of the method with existing and baseline models in literature justify the efficacy of the approach.
Adapting CLIP For Phrase Localization Without Further Training
Apr 07, 2022
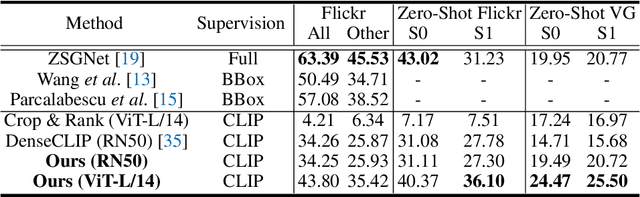
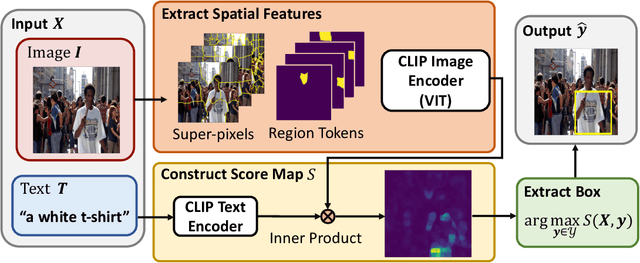
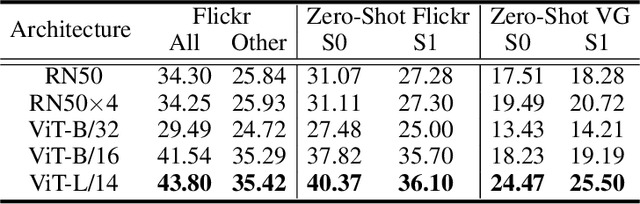
Supervised or weakly supervised methods for phrase localization (textual grounding) either rely on human annotations or some other supervised models, e.g., object detectors. Obtaining these annotations is labor-intensive and may be difficult to scale in practice. We propose to leverage recent advances in contrastive language-vision models, CLIP, pre-trained on image and caption pairs collected from the internet. In its original form, CLIP only outputs an image-level embedding without any spatial resolution. We adapt CLIP to generate high-resolution spatial feature maps. Importantly, we can extract feature maps from both ViT and ResNet CLIP model while maintaining the semantic properties of an image embedding. This provides a natural framework for phrase localization. Our method for phrase localization requires no human annotations or additional training. Extensive experiments show that our method outperforms existing no-training methods in zero-shot phrase localization, and in some cases, it even outperforms supervised methods. Code is available at https://github.com/pals-ttic/adapting-CLIP .