 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Audio-Visual Face Reenactment
Oct 06, 2022
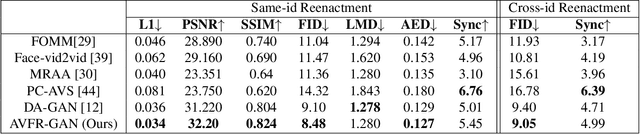
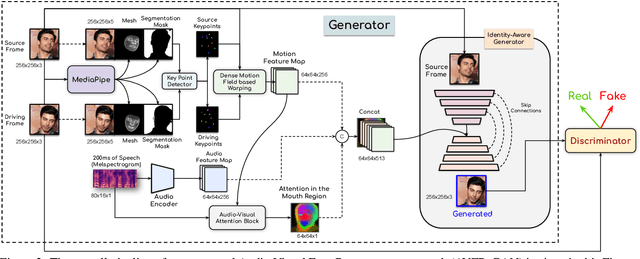
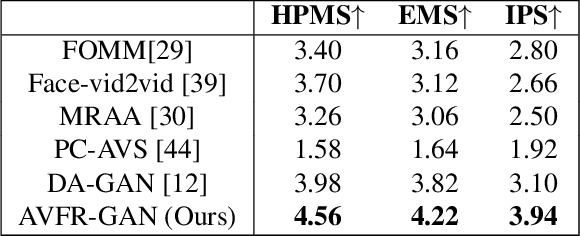

This work proposes a novel method to generate realistic talking head videos using audio and visual streams. We animate a source image by transferring head motion from a driving video using a dense motion field generated using learnable keypoints. We improve the quality of lip sync using audio as an additional input, helping the network to attend to the mouth region. We use additional priors using face segmentation and face mesh to improve the structure of the reconstructed faces. Finally, we improve the visual quality of the generations by incorporating a carefully designed identity-aware generator module. The identity-aware generator takes the source image and the warped motion features as input to generate a high-quality output with fine-grained details. Our method produces state-of-the-art results and generalizes well to unseen faces, languages, and voices. We comprehensively evaluate our approach using multiple metrics and outperforming the current techniques both qualitative and quantitatively. Our work opens up several applications, including enabling low bandwidth video calls. We release a demo video and additional information at http://cvit.iiit.ac.in/research/projects/cvit-projects/avfr.
Learning Equivariant Segmentation with Instance-Unique Querying
Oct 03, 2022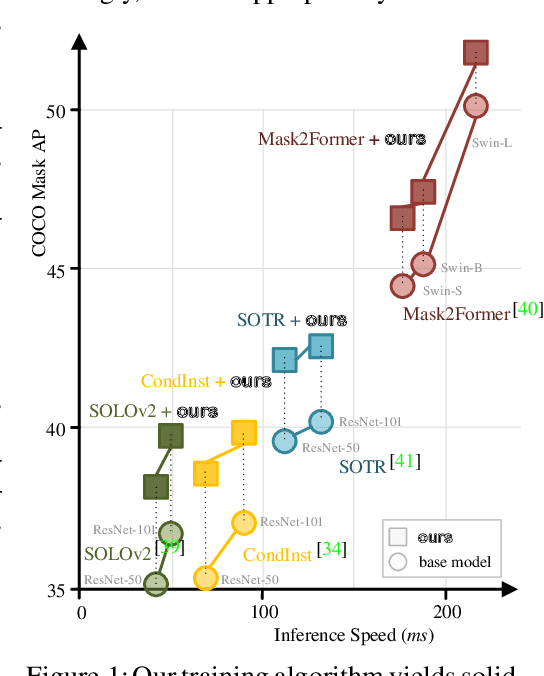
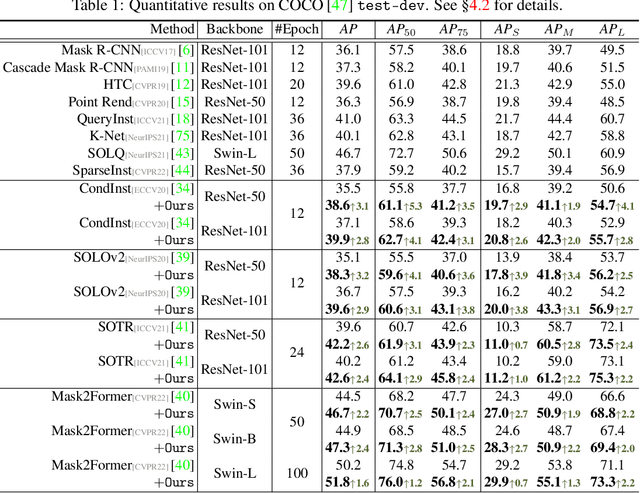
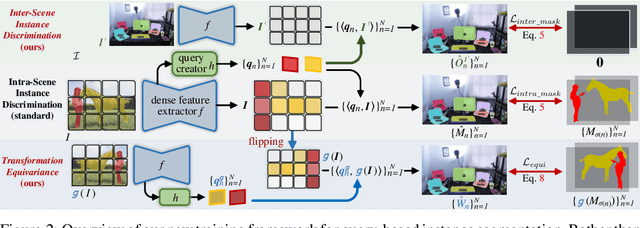

Prevalent state-of-the-art instance segmentation methods fall into a query-based scheme, in which instance masks are derived by querying the image feature using a set of instance-aware embeddings. In this work, we devise a new training framework that boosts query-based models through discriminative query embedding learning. It explores two essential properties, namely dataset-level uniqueness and transformation equivariance, of the relation between queries and instances. First, our algorithm uses the queries to retrieve the corresponding instances from the whole training dataset, instead of only searching within individual scenes. As querying instances across scenes is more challenging, the segmenters are forced to learn more discriminative queries for effective instance separation. Second, our algorithm encourages both image (instance) representations and queries to be equivariant against geometric transformations, leading to more robust, instance-query matching. On top of four famous, query-based models ($i.e.,$ CondInst, SOLOv2, SOTR, and Mask2Former), our training algorithm provides significant performance gains ($e.g.,$ +1.6 - 3.2 AP) on COCO dataset. In addition, our algorithm promotes the performance of SOLOv2 by 2.7 AP, on LVISv1 dataset.
Multipod Convolutional Network
Oct 03, 2022


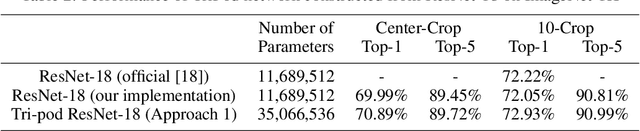
In this paper, we introduce a convolutional network which we call MultiPodNet consisting of a combination of two or more convolutional networks which process the input image in parallel to achieve the same goal. Output feature maps of parallel convolutional networks are fused at the fully connected layer of the network. We experimentally observed that three parallel pod networks (TripodNet) produce the best results in commonly used object recognition datasets. Baseline pod networks can be of any type. In this paper, we use ResNets as baseline networks and their inputs are augmented image patches. The number of parameters of the TripodNet is about three times that of a single ResNet. We train the TripodNet using the standard backpropagation type algorithms. In each individual ResNet, parameters are initialized with different random numbers during training. The TripodNet achieved state-of-the-art performance on CIFAR-10 and ImageNet datasets. For example, it improved the accuracy of a single ResNet from 91.66% to 92.47% under the same training process on the CIFAR-10 dataset.
Blind Super-Resolution for Remote Sensing Images via Conditional Stochastic Normalizing Flows
Oct 14, 2022
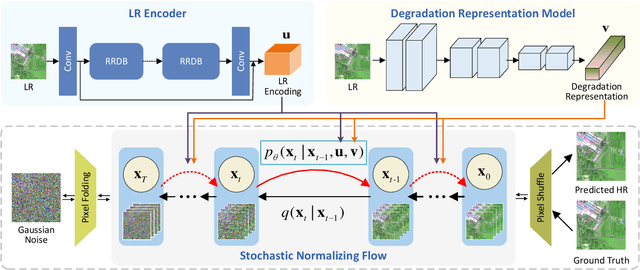
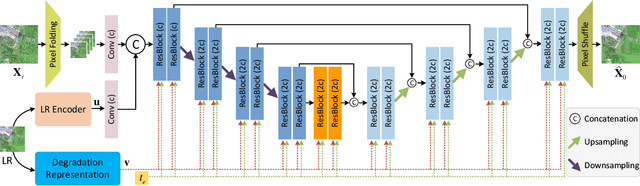
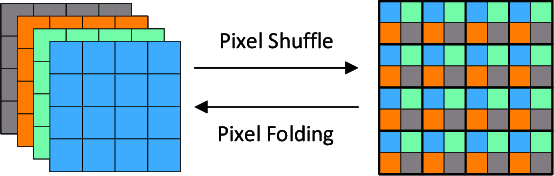
Remote sensing images (RSIs) in real scenes may be disturbed by multiple factors such as optical blur, undersampling, and additional noise, resulting in complex and diverse degradation models. At present, the mainstream SR algorithms only consider a single and fixed degradation (such as bicubic interpolation) and cannot flexibly handle complex degradations in real scenes. Therefore, designing a super-resolution (SR) model that can cope with various degradations is gradually attracting the attention of researchers. Some studies first estimate the degradation kernels and then perform degradation-adaptive SR but face the problems of estimation error amplification and insufficient high-frequency details in the results. Although blind SR algorithms based on generative adversarial networks (GAN) have greatly improved visual quality, they still suffer from pseudo-texture, mode collapse, and poor training stability. In this article, we propose a novel blind SR framework based on the stochastic normalizing flow (BlindSRSNF) to address the above problems. BlindSRSNF learns the conditional probability distribution over the high-resolution image space given a low-resolution (LR) image by explicitly optimizing the variational bound on the likelihood. BlindSRSNF is easy to train and can generate photo-realistic SR results that outperform GAN-based models. Besides, we introduce a degradation representation strategy based on contrastive learning to avoid the error amplification problem caused by the explicit degradation estimation. Comprehensive experiments show that the proposed algorithm can obtain SR results with excellent visual perception quality on both simulated LR and real-world RSIs.
BLADERUNNER: Rapid Countermeasure for Synthetic (AI-Generated) StyleGAN Faces
Oct 14, 2022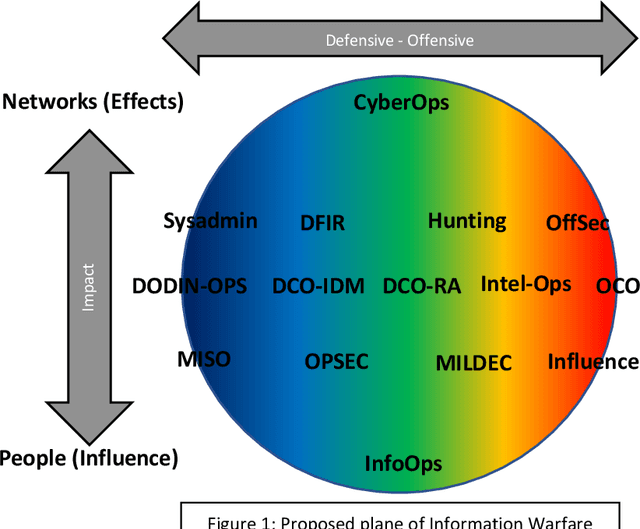
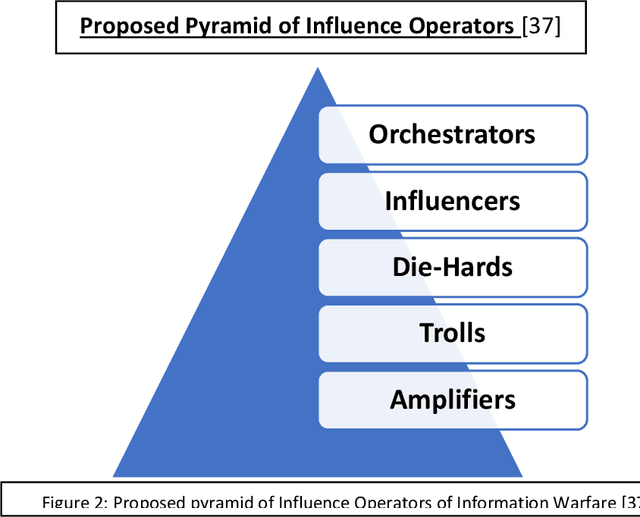


StyleGAN is the open-sourced TensorFlow implementation made by NVIDIA. It has revolutionized high quality facial image generation. However, this democratization of Artificial Intelligence / Machine Learning (AI/ML) algorithms has enabled hostile threat actors to establish cyber personas or sock-puppet accounts in social media platforms. These ultra-realistic synthetic faces. This report surveys the relevance of AI/ML with respect to Cyber & Information Operations. The proliferation of AI/ML algorithms has led to a rise in DeepFakes and inauthentic social media accounts. Threats are analyzed within the Strategic and Operational Environments. Existing methods of identifying synthetic faces exists, but they rely on human beings to visually scrutinize each photo for inconsistencies. However, through use of the DLIB 68-landmark pre-trained file, it is possible to analyze and detect synthetic faces by exploiting repetitive behaviors in StyleGAN images. Project Blade Runner encompasses two scripts necessary to counter StyleGAN images. Through PapersPlease acting as the analyzer, it is possible to derive indicators-of-attack (IOA) from scraped image samples. These IOAs can be fed back into Among_Us acting as the detector to identify synthetic faces from live operational samples. The opensource copy of Blade Runner may lack additional unit tests and some functionality, but the open-source copy is a redacted version, far leaner, better optimized, and a proof-of-concept for the information security community. The desired end-state will be to incrementally add automation to stay on-par with its closed-source predecessor.
SAR-based landslide classification pretraining leads to better segmentation
Nov 17, 2022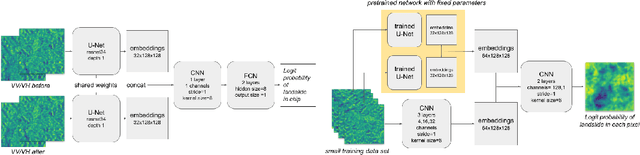
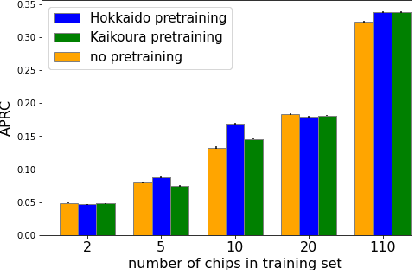
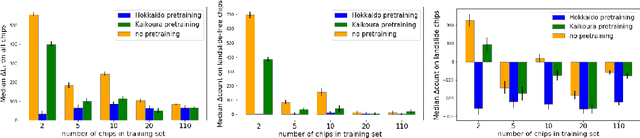
Rapid assessment after a natural disaster is key for prioritizing emergency resources. In the case of landslides, rapid assessment involves determining the extent of the area affected and measuring the size and location of individual landslides. Synthetic Aperture Radar (SAR) is an active remote sensing technique that is unaffected by weather conditions. Deep Learning algorithms can be applied to SAR data, but training them requires large labeled datasets. In the case of landslides, these datasets are laborious to produce for segmentation, and often they are not available for the specific region in which the event occurred. Here, we study how deep learning algorithms for landslide segmentation on SAR products can benefit from pretraining on a simpler task and from data from different regions. The method we explore consists of two training stages. First, we learn the task of identifying whether a SAR image contains any landslides or not. Then, we learn to segment in a sparsely labeled scenario where half of the data do not contain landslides. We test whether the inclusion of feature embeddings derived from stage-1 helps with landslide detection in stage-2. We find that it leads to minor improvements in the Area Under the Precision-Recall Curve, but also to a significantly lower false positive rate in areas without landslides and an improved estimate of the average number of landslide pixels in a chip. A more accurate pixel count allows to identify the most affected areas with higher confidence. This could be valuable in rapid response scenarios where prioritization of resources at a global scale is important. We make our code publicly available at https://github.com/VMBoehm/SAR-landslide-detection-pretraining.
Data-Centric Debugging: mitigating model failures via targeted data collection
Nov 17, 2022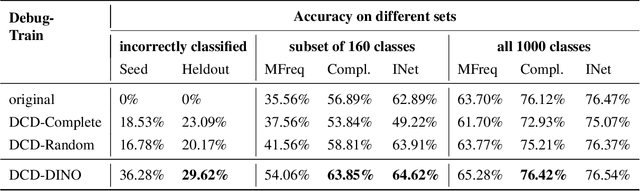
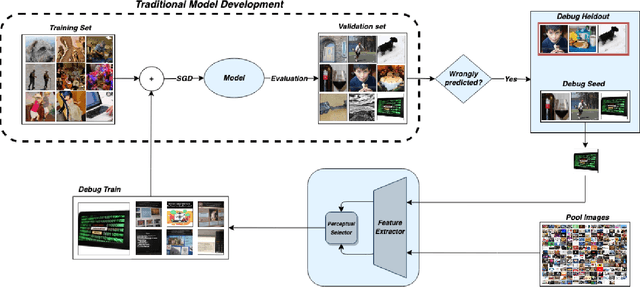

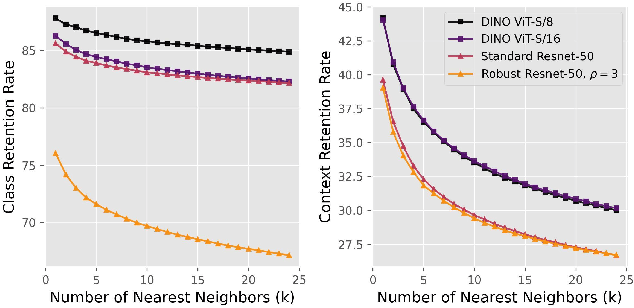
Deep neural networks can be unreliable in the real world when the training set does not adequately cover all the settings where they are deployed. Focusing on image classification, we consider the setting where we have an error distribution $\mathcal{E}$ representing a deployment scenario where the model fails. We have access to a small set of samples $\mathcal{E}_{sample}$ from $\mathcal{E}$ and it can be expensive to obtain additional samples. In the traditional model development framework, mitigating failures of the model in $\mathcal{E}$ can be challenging and is often done in an ad hoc manner. In this paper, we propose a general methodology for model debugging that can systemically improve model performance on $\mathcal{E}$ while maintaining its performance on the original test set. Our key assumption is that we have access to a large pool of weakly (noisily) labeled data $\mathcal{F}$. However, naively adding $\mathcal{F}$ to the training would hurt model performance due to the large extent of label noise. Our Data-Centric Debugging (DCD) framework carefully creates a debug-train set by selecting images from $\mathcal{F}$ that are perceptually similar to the images in $\mathcal{E}_{sample}$. To do this, we use the $\ell_2$ distance in the feature space (penultimate layer activations) of various models including ResNet, Robust ResNet and DINO where we observe DINO ViTs are significantly better at discovering similar images compared to Resnets. Compared to LPIPS, we find that our method reduces compute and storage requirements by 99.58\%. Compared to the baselines that maintain model performance on the test set, we achieve significantly (+9.45\%) improved results on the debug-heldout sets.
Object recognition in atmospheric turbulence scenes
Oct 25, 2022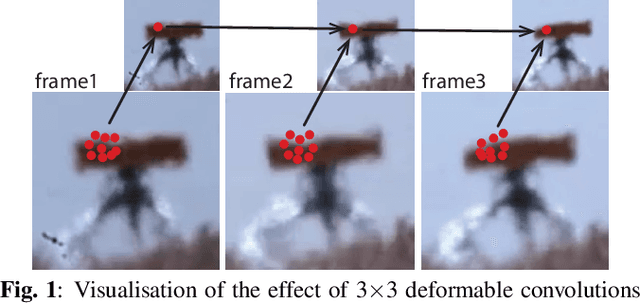
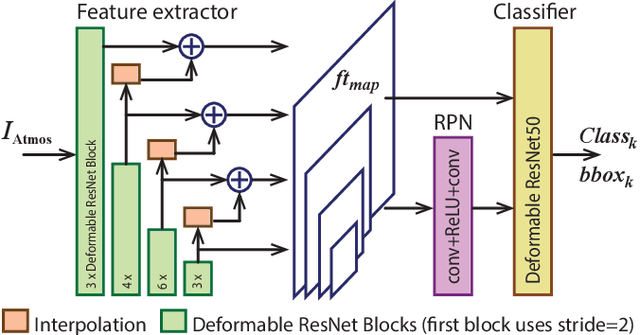
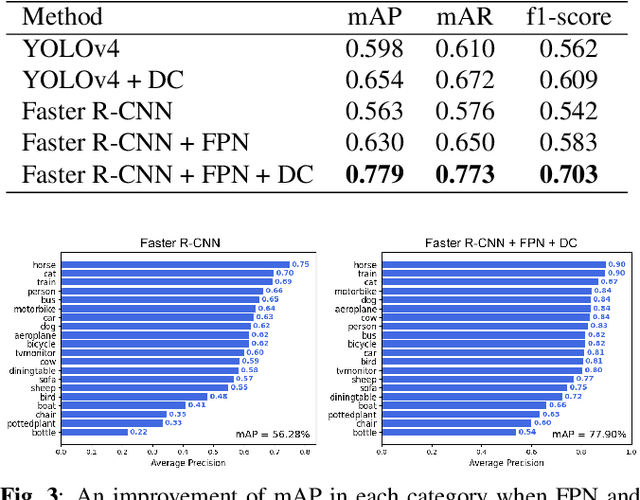

The influence of atmospheric turbulence on acquired surveillance imagery makes image interpretation and scene analysis extremely difficult. It also reduces the effectiveness of conventional approaches for classifying, and tracking targets in the scene. Whilst deep-learning based object detection is highly successful in normal conditions, these methods cannot directly be applied to the atmospheric turbulence sequences. This paper hence proposes a novel framework learning the distorted features to detect and classify object types. Specifically, deformable convolutions are exploited to deal with spatial turbulent displacement. The features are extracted via a feature pyramid network and Faster R-CNN is employed as a detector. Testing with synthetic VOC dataset, the results show that the proposed framework outperforms the benchmark with mean Average Precision (mAP) score of >30%. Subjective results on the real data are also significantly improved.
Search for Concepts: Discovering Visual Concepts Using Direct Optimization
Oct 25, 2022

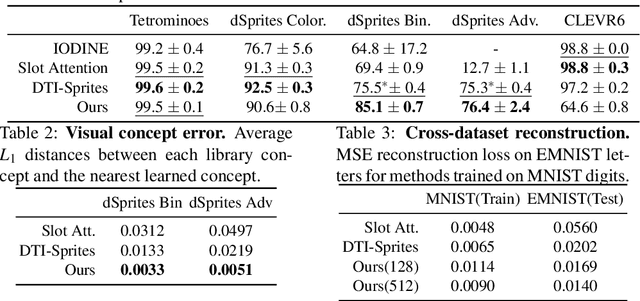
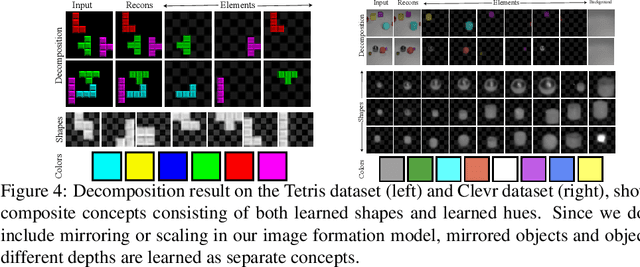
Finding an unsupervised decomposition of an image into individual objects is a key step to leverage compositionality and to perform symbolic reasoning. Traditionally, this problem is solved using amortized inference, which does not generalize beyond the scope of the training data, may sometimes miss correct decompositions, and requires large amounts of training data. We propose finding a decomposition using direct, unamortized optimization, via a combination of a gradient-based optimization for differentiable object properties and global search for non-differentiable properties. We show that using direct optimization is more generalizable, misses fewer correct decompositions, and typically requires less data than methods based on amortized inference. This highlights a weakness of the current prevalent practice of using amortized inference that can potentially be improved by integrating more direct optimization elements.
ASpanFormer: Detector-Free Image Matching with Adaptive Span Transformer
Aug 30, 2022
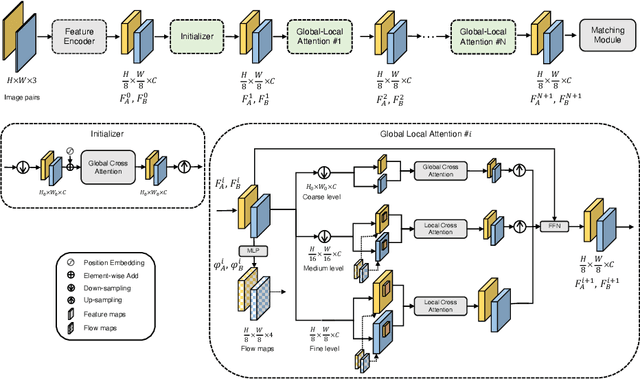
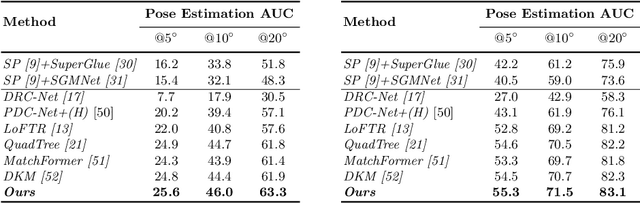

Generating robust and reliable correspondences across images is a fundamental task for a diversity of applications. To capture context at both global and local granularity, we propose ASpanFormer, a Transformer-based detector-free matcher that is built on hierarchical attention structure, adopting a novel attention operation which is capable of adjusting attention span in a self-adaptive manner. To achieve this goal, first, flow maps are regressed in each cross attention phase to locate the center of search region. Next, a sampling grid is generated around the center, whose size, instead of being empirically configured as fixed, is adaptively computed from a pixel uncertainty estimated along with the flow map. Finally, attention is computed across two images within derived regions, referred to as attention span. By these means, we are able to not only maintain long-range dependencies, but also enable fine-grained attention among pixels of high relevance that compensates essential locality and piece-wise smoothness in matching tasks. State-of-the-art accuracy on a wide range of evaluation benchmarks validates the strong matching capability of our method.