 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Face Attribute Editing with Disentangled Latent Vectors
Jan 11, 2023

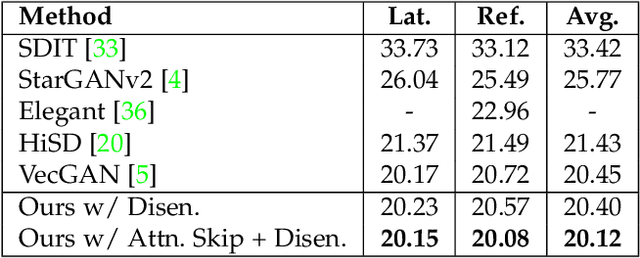
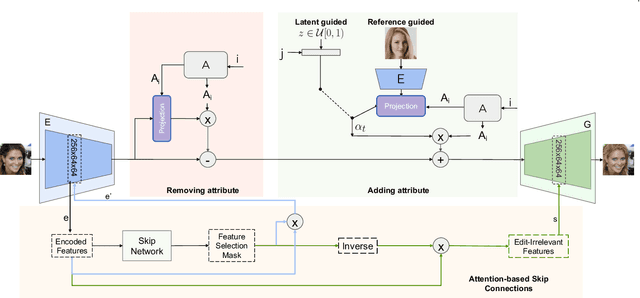
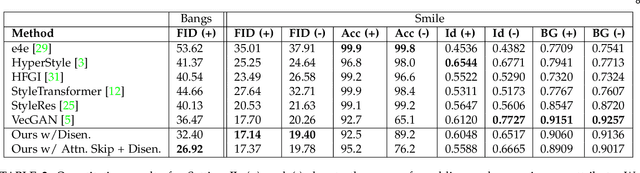
We propose an image-to-image translation framework for facial attribute editing with disentangled interpretable latent directions. Facial attribute editing task faces the challenges of targeted attribute editing with controllable strength and disentanglement in the representations of attributes to preserve the other attributes during edits. For this goal, inspired by the latent space factorization works of fixed pretrained GANs, we design the attribute editing by latent space factorization, and for each attribute, we learn a linear direction that is orthogonal to the others. We train these directions with orthogonality constraints and disentanglement losses. To project images to semantically organized latent spaces, we set an encoder-decoder architecture with attention-based skip connections. We extensively compare with previous image translation algorithms and editing with pretrained GAN works. Our extensive experiments show that our method significantly improves over the state-of-the-arts. Project page: https://yusufdalva.github.io/vecgan
Optimising Different Feature Types for Inpainting-based Image Representations
Oct 26, 2022


Inpainting-based image compression is a promising alternative to classical transform-based lossy codecs. Typically it stores a carefully selected subset of all pixel locations and their colour values. In the decoding phase the missing information is reconstructed by an inpainting process such as homogeneous diffusion inpainting. Optimising the stored data is the key for achieving good performance. A few heuristic approaches also advocate alternative feature types such as derivative data and construct dedicated inpainting concepts. However, one still lacks a general approach that allows to optimise and inpaint the data simultaneously w.r.t. a collection of different feature types, their locations, and their values. Our paper closes this gap. We introduce a generalised inpainting process that can handle arbitrary features which can be expressed as linear equality constraints. This includes e.g. colour values and derivatives of any order. We propose a fully automatic algorithm that aims at finding the optimal features from a given collection as well as their locations and their function values within a specified total feature density. Its performance is demonstrated with a novel set of features that also includes local averages. Our experiments show that it clearly outperforms the popular inpainting with optimised colour data with the same density.
Geometry-Complete Diffusion for 3D Molecule Generation
Feb 15, 2023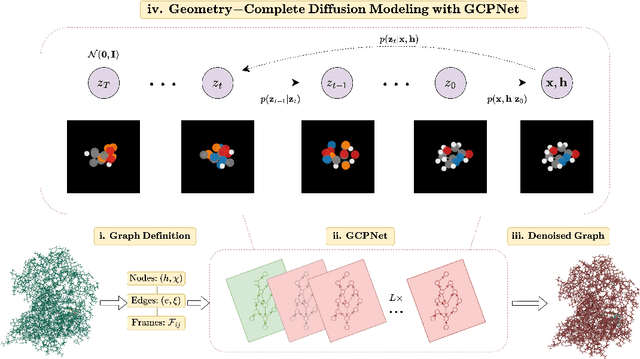
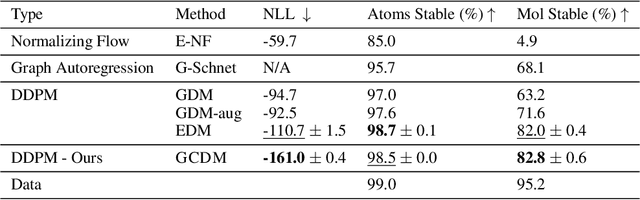
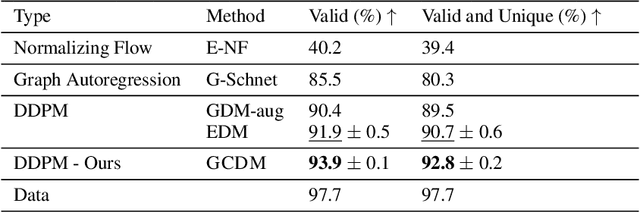
Denoising diffusion probabilistic models (DDPMs) have recently taken the field of generative modeling by storm, pioneering new state-of-the-art results in disciplines such as computer vision and computational biology for diverse tasks ranging from text-guided image generation to structure-guided protein design. Along this latter line of research, methods such as those of Hoogeboom et al. 2022 have been proposed for unconditionally generating 3D molecules using equivariant graph neural networks (GNNs) within a DDPM framework. Toward this end, we propose GCDM, a geometry-complete diffusion model that achieves new state-of-the-art results for 3D molecule diffusion generation by leveraging the representation learning strengths offered by GNNs that perform geometry-complete message-passing. Our results with GCDM also offer preliminary insights into how physical inductive biases impact the generative dynamics of molecular DDPMs. The source code, data, and instructions to train new models or reproduce our results are freely available at https://github.com/BioinfoMachineLearning/bio-diffusion.
Improved Online Conformal Prediction via Strongly Adaptive Online Learning
Feb 15, 2023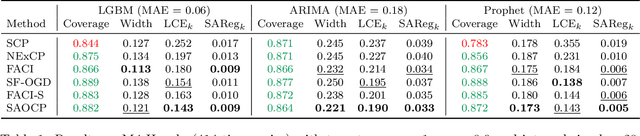
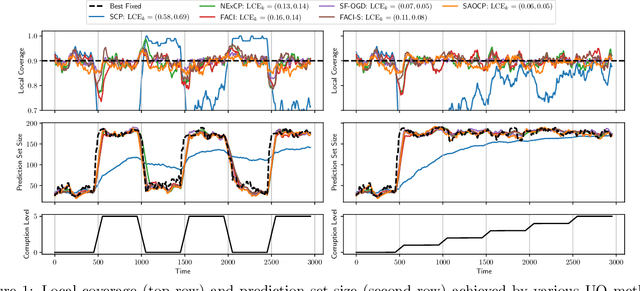

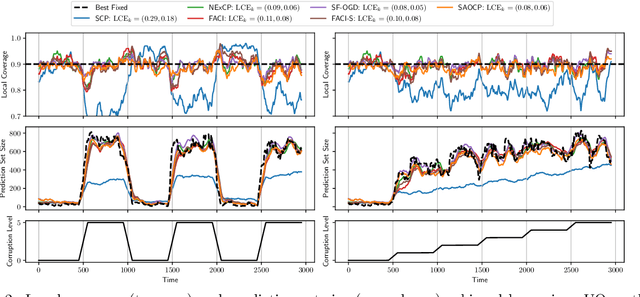
We study the problem of uncertainty quantification via prediction sets, in an online setting where the data distribution may vary arbitrarily over time. Recent work develops online conformal prediction techniques that leverage regret minimization algorithms from the online learning literature to learn prediction sets with approximately valid coverage and small regret. However, standard regret minimization could be insufficient for handling changing environments, where performance guarantees may be desired not only over the full time horizon but also in all (sub-)intervals of time. We develop new online conformal prediction methods that minimize the strongly adaptive regret, which measures the worst-case regret over all intervals of a fixed length. We prove that our methods achieve near-optimal strongly adaptive regret for all interval lengths simultaneously, and approximately valid coverage. Experiments show that our methods consistently obtain better coverage and smaller prediction sets than existing methods on real-world tasks, such as time series forecasting and image classification under distribution shift.
Unsupervised Hashing via Similarity Distribution Calibration
Feb 15, 2023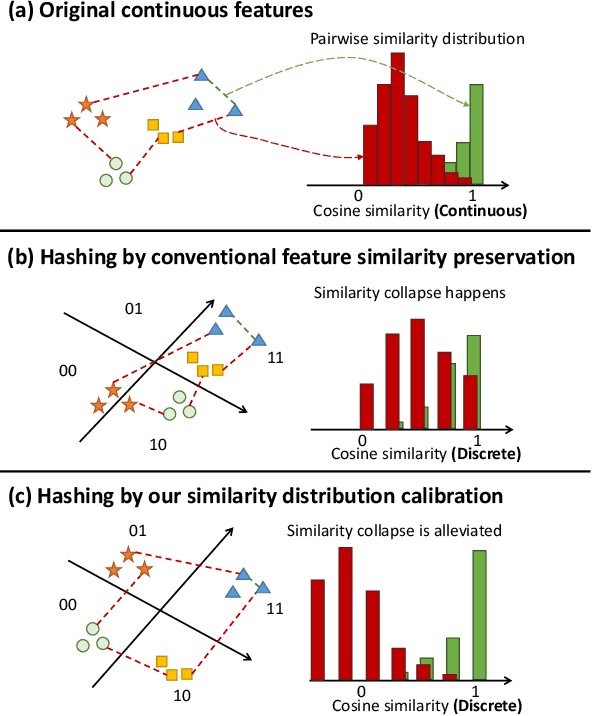
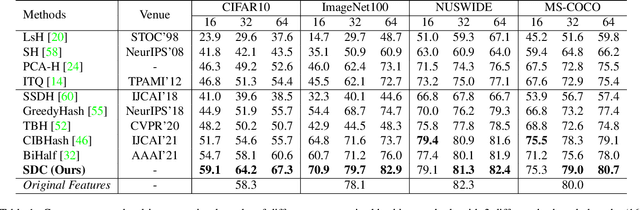
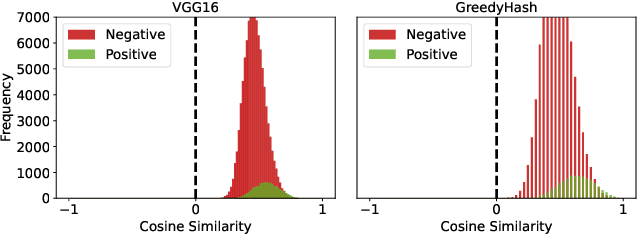

Existing unsupervised hashing methods typically adopt a feature similarity preservation paradigm. As a result, they overlook the intrinsic similarity capacity discrepancy between the continuous feature and discrete hash code spaces. Specifically, since the feature similarity distribution is intrinsically biased (e.g., moderately positive similarity scores on negative pairs), the hash code similarities of positive and negative pairs often become inseparable (i.e., the similarity collapse problem). To solve this problem, in this paper a novel Similarity Distribution Calibration (SDC) method is introduced. Instead of matching individual pairwise similarity scores, SDC aligns the hash code similarity distribution towards a calibration distribution (e.g., beta distribution) with sufficient spread across the entire similarity capacity/range, to alleviate the similarity collapse problem. Extensive experiments show that our SDC outperforms the state-of-the-art alternatives on both coarse category-level and instance-level image retrieval tasks, often by a large margin. Code is available at https://github.com/kamwoh/sdc.
Echocardiographic Image Quality Assessment Using Deep Neural Networks
Sep 02, 2022Echocardiography image quality assessment is not a trivial issue in transthoracic examination. As the in vivo examination of heart structures gained prominence in cardiac diagnosis, it has been affirmed that accurate diagnosis of the left ventricle functions is hugely dependent on the quality of echo images. Up till now, visual assessment of echo images is highly subjective and requires specific definition under clinical pathologies. While poor-quality images impair quantifications and diagnosis, the inherent variations in echocardiographic image quality standards indicates the complexity faced among different observers and provides apparent evidence for incoherent assessment under clinical trials, especially with less experienced cardiologists. In this research, our aim was to analyse and define specific quality attributes mostly discussed by experts and present a fully trained convolutional neural network model for assessing such quality features objectively.
Evaluation of FEM and MLFEM AI-explainers in Image Classification tasks with reference-based and no-reference metrics
Dec 02, 2022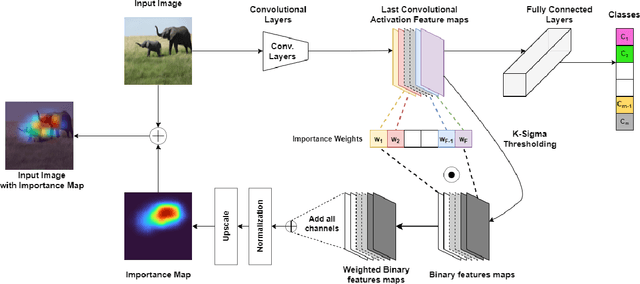
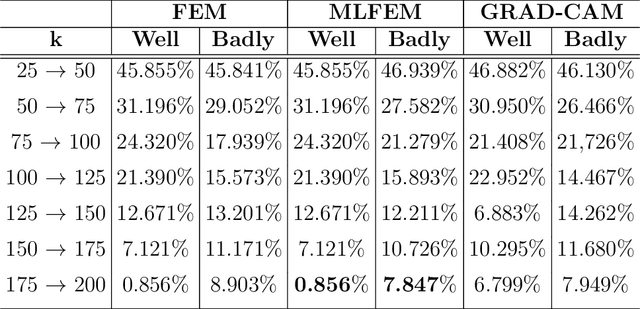

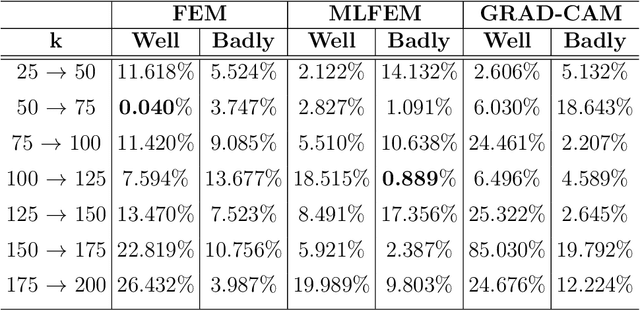
The most popular methods and algorithms for AI are, for the vast majority, black boxes. Black boxes can be an acceptable solution to unimportant problems (in the sense of the degree of impact) but have a fatal flaw for the rest. Therefore the explanation tools for them have been quickly developed. The evaluation of their quality remains an open research question. In this technical report, we remind recently proposed post-hoc explainers FEM and MLFEM which have been designed for explanations of CNNs in image and video classification tasks. We also propose their evaluation with reference-based and no-reference metrics. The reference-based metrics are Pearson Correlation coefficient and Similarity computed between the explanation maps and the ground truth, which is represented by Gaze Fixation Density Maps obtained due to a psycho-visual experiment. As a no-reference metric we use "stability" metric, proposed by Alvarez-Melis and Jaakkola. We study its behaviour, consensus with reference-based metrics and show that in case of several kind of degradations on input images, this metric is in agreement with reference-based ones. Therefore it can be used for evaluation of the quality of explainers when the ground truth is not available.
TT-TFHE: a Torus Fully Homomorphic Encryption-Friendly Neural Network Architecture
Feb 03, 2023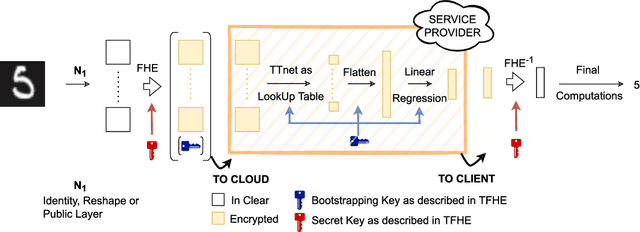
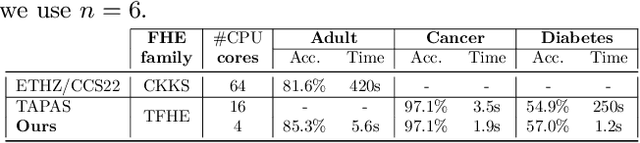
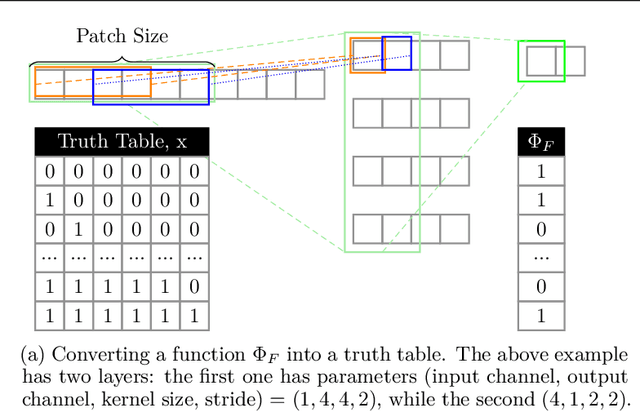
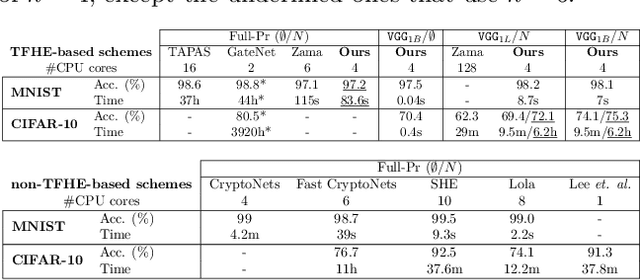
This paper presents TT-TFHE, a deep neural network Fully Homomorphic Encryption (FHE) framework that effectively scales Torus FHE (TFHE) usage to tabular and image datasets using a recent family of convolutional neural networks called Truth-Table Neural Networks (TTnet). The proposed framework provides an easy-to-implement, automated TTnet-based design toolbox with an underlying (python-based) open-source Concrete implementation (CPU-based and implementing lookup tables) for inference over encrypted data. Experimental evaluation shows that TT-TFHE greatly outperforms in terms of time and accuracy all Homomorphic Encryption (HE) set-ups on three tabular datasets, all other features being equal. On image datasets such as MNIST and CIFAR-10, we show that TT-TFHE consistently and largely outperforms other TFHE set-ups and is competitive against other HE variants such as BFV or CKKS (while maintaining the same level of 128-bit encryption security guarantees). In addition, our solutions present a very low memory footprint (down to dozens of MBs for MNIST), which is in sharp contrast with other HE set-ups that typically require tens to hundreds of GBs of memory per user (in addition to their communication overheads). This is the first work presenting a fully practical solution of private inference (i.e. a few seconds for inference time and a few dozens MBs of memory) on both tabular datasets and MNIST, that can easily scale to multiple threads and users on server side.
A Survey on Causal Representation Learning and Future Work for Medical Image Analysis
Oct 28, 2022
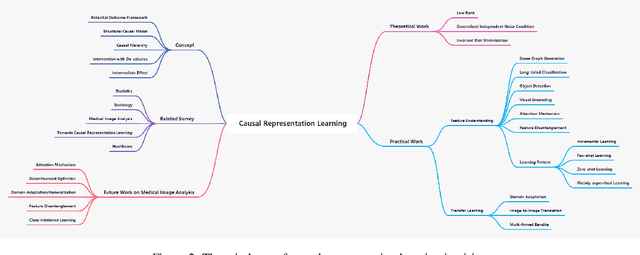
Statistical machine learning algorithms have achieved state-of-the-art results on benchmark datasets, outperforming humans in many tasks. However, the out-of-distribution data and confounder, which have an unpredictable causal relationship, significantly degrade the performance of the existing models. Causal Representation Learning (CRL) has recently been a promising direction to address the causal relationship problem in vision understanding. This survey presents recent advances in CRL in vision. Firstly, we introduce the basic concept of causal inference. Secondly, we analyze the CRL theoretical work, especially in invariant risk minimization, and the practical work in feature understanding and transfer learning. Finally, we propose a future research direction in medical image analysis and CRL general theory.
SIAN: Style-Guided Instance-Adaptive Normalization for Multi-Organ Histopathology Image Synthesis
Sep 02, 2022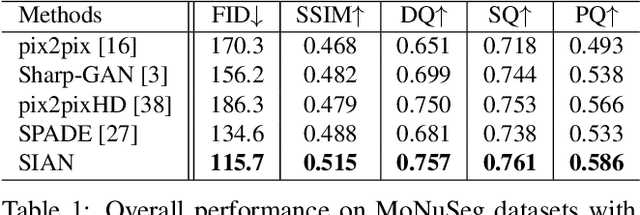

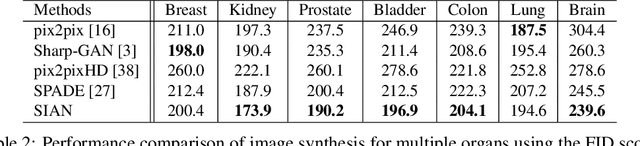
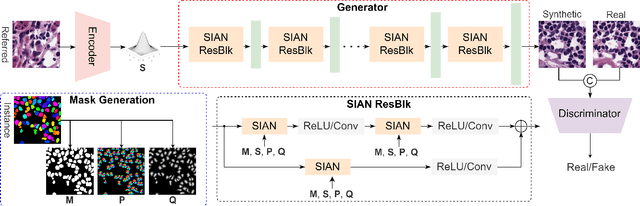
Existing deep networks for histopathology image synthesis cannot generate accurate boundaries for clustered nuclei and cannot output image styles that align with different organs. To address these issues, we propose a style-guided instance-adaptive normalization (SIAN) to synthesize realistic color distributions and textures for different organs. SIAN contains four phases, semantization, stylization, instantiation, and modulation. The four phases work together and are integrated into a generative network to embed image semantics, style, and instance-level boundaries. Experimental results demonstrate the effectiveness of all components in SIAN, and show that the proposed method outperforms the state-of-the-art conditional GANs for histopathology image synthesis using the Frechet Inception Distance (FID), structural similarity Index (SSIM), detection quality(DQ), segmentation quality(SQ), and panoptic quality(PQ). Furthermore, the performance of a segmentation network could be significantly improved by incorporating synthetic images generated using SIAN.