 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Patch-Craft Self-Supervised Training for Correlated Image Denoising
Nov 17, 2022
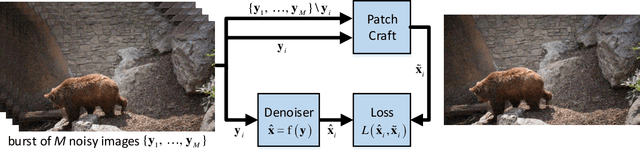
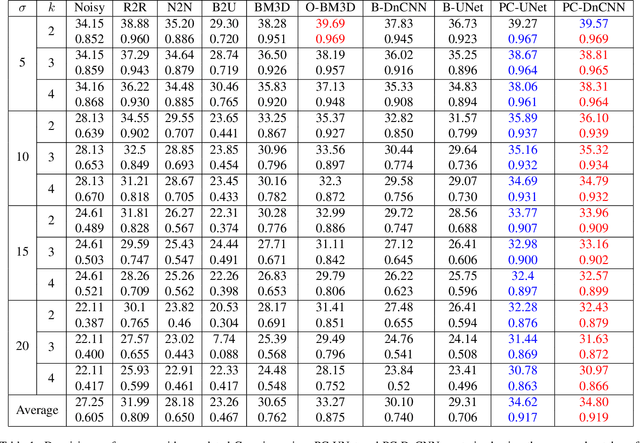
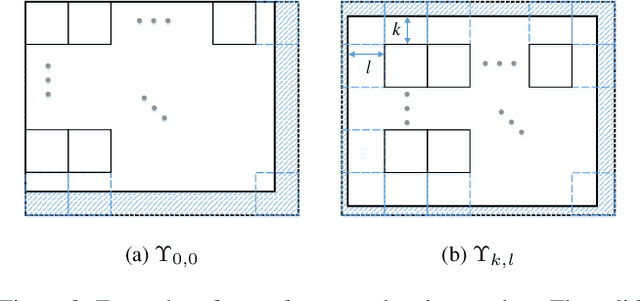
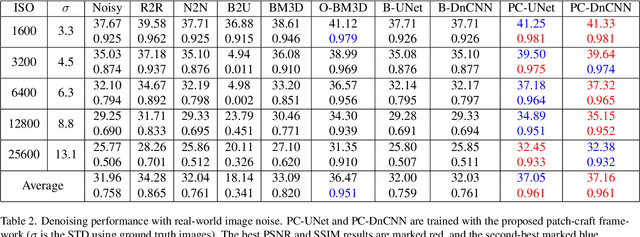
Supervised neural networks are known to achieve excellent results in various image restoration tasks. However, such training requires datasets composed of pairs of corrupted images and their corresponding ground truth targets. Unfortunately, such data is not available in many applications. For the task of image denoising in which the noise statistics is unknown, several self-supervised training methods have been proposed for overcoming this difficulty. Some of these require knowledge of the noise model, while others assume that the contaminating noise is uncorrelated, both assumptions are too limiting for many practical needs. This work proposes a novel self-supervised training technique suitable for the removal of unknown correlated noise. The proposed approach neither requires knowledge of the noise model nor access to ground truth targets. The input to our algorithm consists of easily captured bursts of noisy shots. Our algorithm constructs artificial patch-craft images from these bursts by patch matching and stitching, and the obtained crafted images are used as targets for the training. Our method does not require registration of the images within the burst. We evaluate the proposed framework through extensive experiments with synthetic and real image noise.
MuMIC -- Multimodal Embedding for Multi-label Image Classification with Tempered Sigmoid
Nov 02, 2022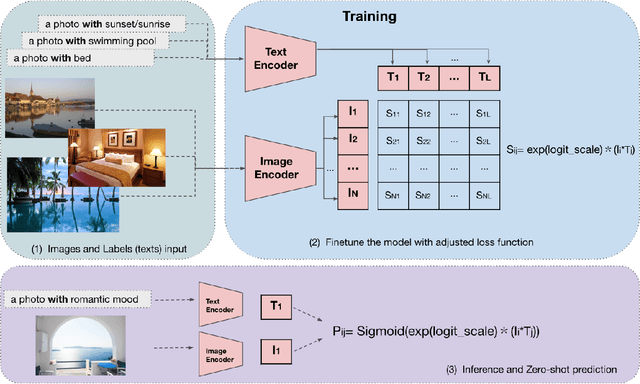

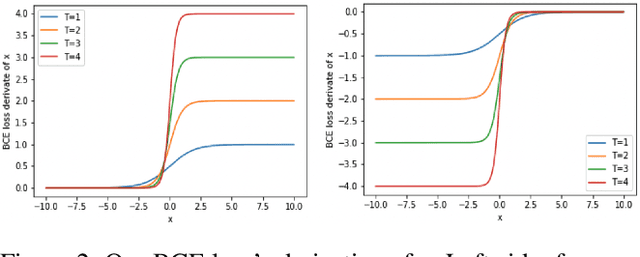
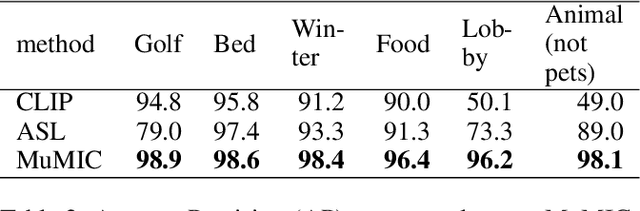
Multi-label image classification is a foundational topic in various domains. Multimodal learning approaches have recently achieved outstanding results in image representation and single-label image classification. For instance, Contrastive Language-Image Pretraining (CLIP) demonstrates impressive image-text representation learning abilities and is robust to natural distribution shifts. This success inspires us to leverage multimodal learning for multi-label classification tasks, and benefit from contrastively learnt pretrained models. We propose the Multimodal Multi-label Image Classification (MuMIC) framework, which utilizes a hardness-aware tempered sigmoid based Binary Cross Entropy loss function, thus enables the optimization on multi-label objectives and transfer learning on CLIP. MuMIC is capable of providing high classification performance, handling real-world noisy data, supporting zero-shot predictions, and producing domain-specific image embeddings. In this study, a total of 120 image classes are defined, and more than 140K positive annotations are collected on approximately 60K Booking.com images. The final MuMIC model is deployed on Booking.com Content Intelligence Platform, and it outperforms other state-of-the-art models with 85.6% GAP@10 and 83.8% GAP on all 120 classes, as well as a 90.1% macro mAP score across 32 majority classes. We summarize the modeling choices which are extensively tested through ablation studies. To the best of our knowledge, we are the first to adapt contrastively learnt multimodal pretraining for real-world multi-label image classification problems, and the innovation can be transferred to other domains.
Incremental Self-Supervised Learning Based on Transformer for Anomaly Detection and Localization
Apr 05, 2023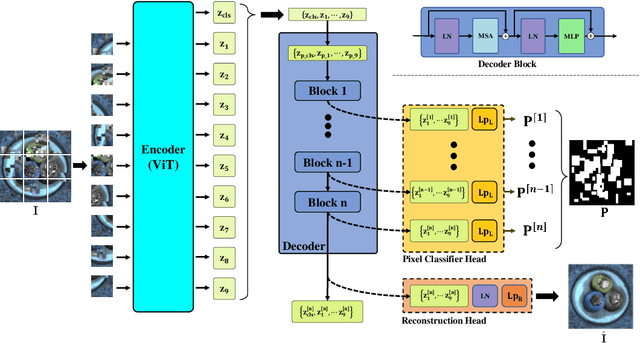
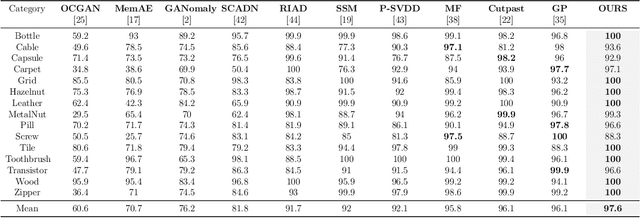
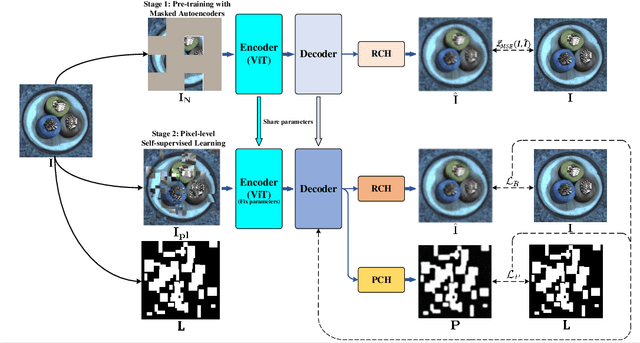
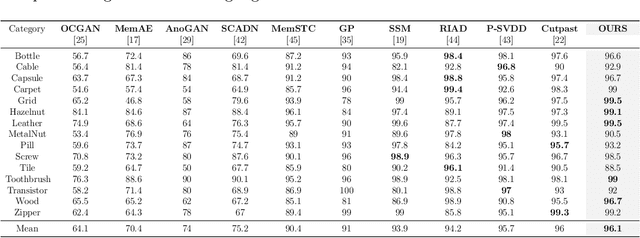
In the machine learning domain, research on anomaly detection and localization within image data has garnered significant attention, particularly in practical applications such as industrial defect detection. While existing approaches predominantly rely on Convolutional Neural Networks (CNN) as their backbone network, we propose an innovative method based on the Transformer backbone network. Our approach employs a two-stage incremental learning strategy. In the first stage, we train a Masked Autoencoder (MAE) model exclusively on normal images. Subsequently, in the second stage, we implement pixel-level data augmentation techniques to generate corrupted normal images and their corresponding pixel labels. This process enables the model to learn how to repair corrupted regions and classify the state of each pixel. Ultimately, the model produces a pixel reconstruction error matrix and a pixel anomaly probability matrix, which are combined to create an anomaly scoring matrix that effectively identifies abnormal regions. When compared to several state-of-the-art CNN-based techniques, our method demonstrates superior performance on the MVTec AD dataset, achieving an impressive 97.6% AUC.
Self-Supervised Siamese Autoencoders
Apr 05, 2023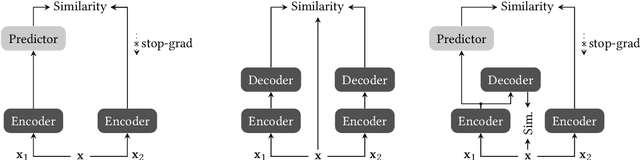

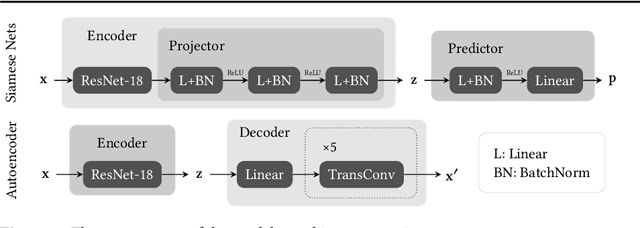
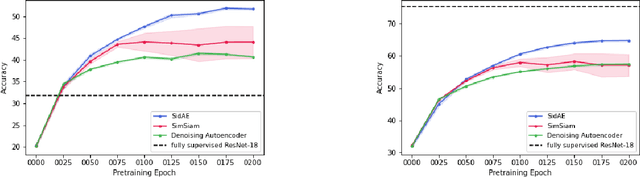
Fully supervised models often require large amounts of labeled training data, which tends to be costly and hard to acquire. In contrast, self-supervised representation learning reduces the amount of labeled data needed for achieving the same or even higher downstream performance. The goal is to pre-train deep neural networks on a self-supervised task such that afterwards the networks are able to extract meaningful features from raw input data. These features are then used as inputs in downstream tasks, such as image classification. Previously, autoencoders and Siamese networks such as SimSiam have been successfully employed in those tasks. Yet, challenges remain, such as matching characteristics of the features (e.g., level of detail) to the given task and data set. In this paper, we present a new self-supervised method that combines the benefits of Siamese architectures and denoising autoencoders. We show that our model, called SidAE (Siamese denoising autoencoder), outperforms two self-supervised baselines across multiple data sets, settings, and scenarios. Crucially, this includes conditions in which only a small amount of labeled data is available.
Deepfake Detection of Occluded Images Using a Patch-based Approach
Apr 10, 2023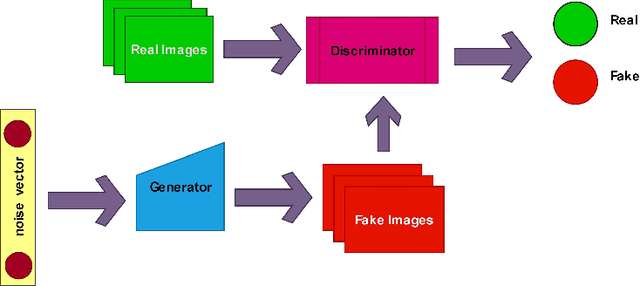

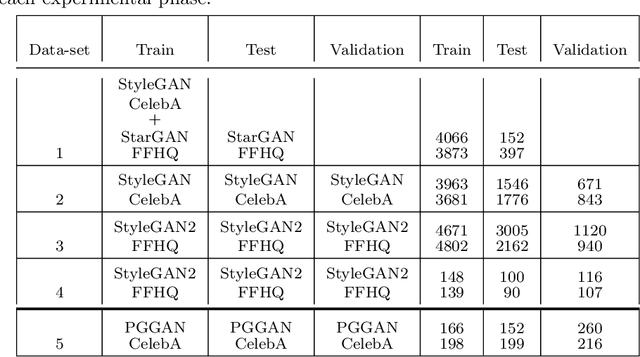
DeepFake involves the use of deep learning and artificial intelligence techniques to produce or change video and image contents typically generated by GANs. Moreover, it can be misused and leads to fictitious news, ethical and financial crimes, and also affects the performance of facial recognition systems. Thus, detection of real or fake images is significant specially to authenticate originality of people's images or videos. One of the most important challenges in this topic is obstruction that decreases the system precision. In this study, we present a deep learning approach using the entire face and face patches to distinguish real/fake images in the presence of obstruction with a three-path decision: first entire-face reasoning, second a decision based on the concatenation of feature vectors of face patches, and third a majority vote decision based on these features. To test our approach, new datasets including real and fake images are created. For producing fake images, StyleGAN and StyleGAN2 are trained by FFHQ images and also StarGAN and PGGAN are trained by CelebA images. The CelebA and FFHQ datasets are used as real images. The proposed approach reaches higher results in early epochs than other methods and increases the SoTA results by 0.4\%-7.9\% in the different built data-sets. Also, we have shown in experimental results that weighing the patches may improve accuracy.
Monocular 3D Human Pose Estimation for Sports Broadcasts using Partial Sports Field Registration
Apr 10, 2023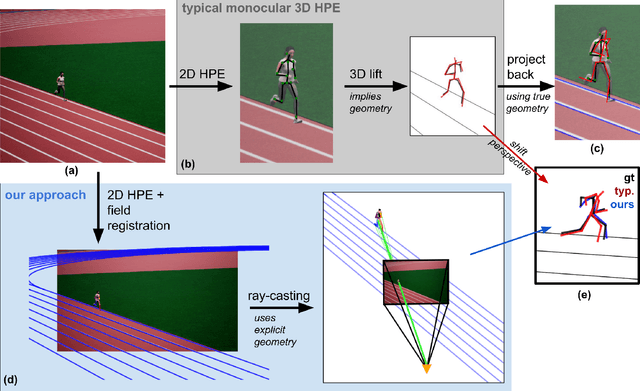
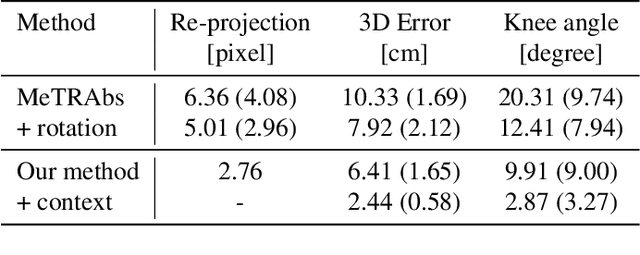
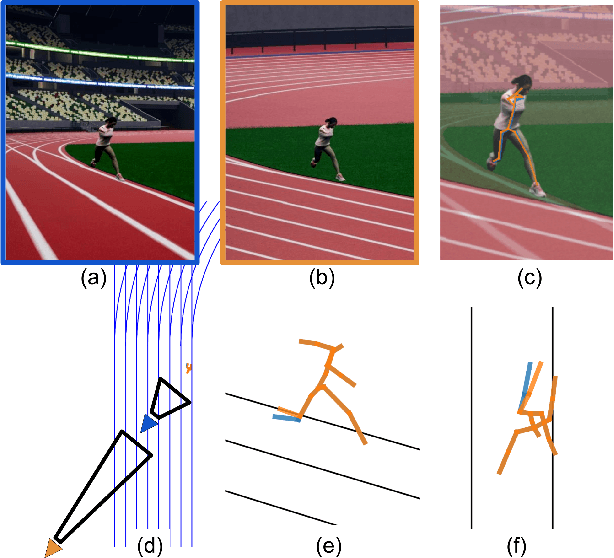

The filming of sporting events projects and flattens the movement of athletes in the world onto a 2D broadcast image. The pixel locations of joints in these images can be detected with high validity. Recovering the actual 3D movement of the limbs (kinematics) of the athletes requires lifting these 2D pixel locations back into a third dimension, implying a certain scene geometry. The well-known line markings of sports fields allow for the calibration of the camera and for determining the actual geometry of the scene. Close-up shots of athletes are required to extract detailed kinematics, which in turn obfuscates the pertinent field markers for camera calibration. We suggest partial sports field registration, which determines a set of scene-consistent camera calibrations up to a single degree of freedom. Through joint optimization of 3D pose estimation and camera calibration, we demonstrate the successful extraction of 3D running kinematics on a 400m track. In this work, we combine advances in 2D human pose estimation and camera calibration via partial sports field registration to demonstrate an avenue for collecting valid large-scale kinematic datasets. We generate a synthetic dataset of more than 10k images in Unreal Engine 5 with different viewpoints, running styles, and body types, to show the limitations of existing monocular 3D HPE methods. Synthetic data and code are available at https://github.com/tobibaum/PartialSportsFieldReg_3DHPE.
Learning to Generate Image Embeddings with User-level Differential Privacy
Nov 20, 2022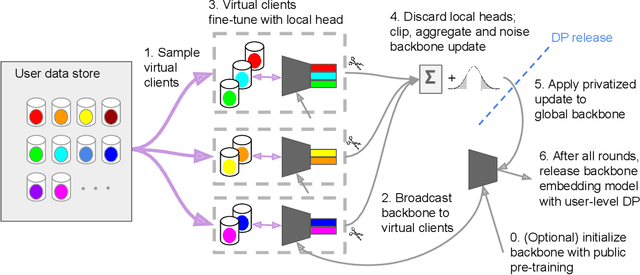
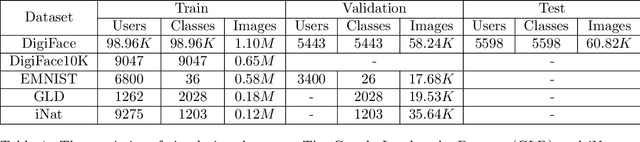

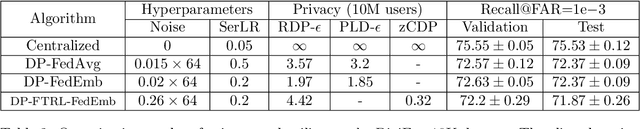
Small on-device models have been successfully trained with user-level differential privacy (DP) for next word prediction and image classification tasks in the past. However, existing methods can fail when directly applied to learn embedding models using supervised training data with a large class space. To achieve user-level DP for large image-to-embedding feature extractors, we propose DP-FedEmb, a variant of federated learning algorithms with per-user sensitivity control and noise addition, to train from user-partitioned data centralized in the datacenter. DP-FedEmb combines virtual clients, partial aggregation, private local fine-tuning, and public pretraining to achieve strong privacy utility trade-offs. We apply DP-FedEmb to train image embedding models for faces, landmarks and natural species, and demonstrate its superior utility under same privacy budget on benchmark datasets DigiFace, EMNIST, GLD and iNaturalist. We further illustrate it is possible to achieve strong user-level DP guarantees of $\epsilon<2$ while controlling the utility drop within 5%, when millions of users can participate in training.
Evaluating the Effectiveness of 2D and 3D Features for Predicting Tumor Response to Chemotherapy
Apr 14, 2023
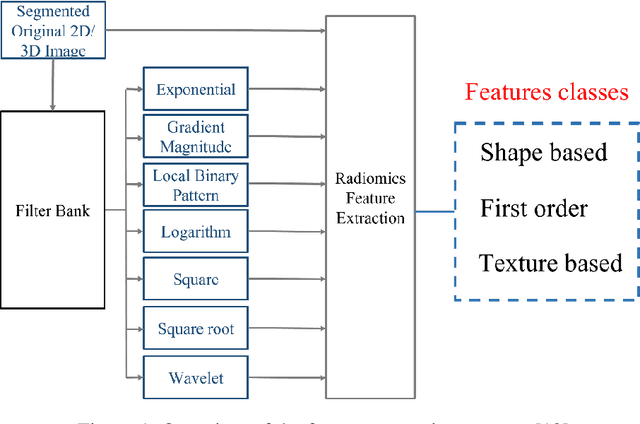

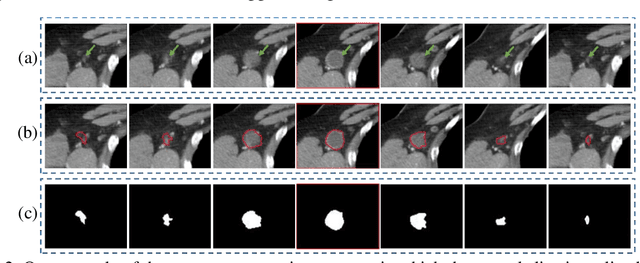
2D and 3D tumor features are widely used in a variety of medical image analysis tasks. However, for chemotherapy response prediction, the effectiveness between different kinds of 2D and 3D features are not comprehensively assessed, especially in ovarian cancer-related applications. This investigation aims to accomplish such a comprehensive evaluation. For this purpose, CT images were collected retrospectively from 188 advanced-stage ovarian cancer patients. All the metastatic tumors that occurred in each patient were segmented and then processed by a set of six filters. Next, three categories of features, namely geometric, density, and texture features, were calculated from both the filtered results and the original segmented tumors, generating a total of 1595 and 1403 features for the 3D and 2D tumors, respectively. In addition to the conventional single-slice 2D and full-volume 3D tumor features, we also computed the incomplete-3D tumor features, which were achieved by sequentially adding one individual CT slice and calculating the corresponding features. Support vector machine (SVM) based prediction models were developed and optimized for each feature set. 5-fold cross-validation was used to assess the performance of each individual model. The results show that the 2D feature-based model achieved an AUC (area under the ROC curve [receiver operating characteristic]) of 0.84+-0.02. When adding more slices, the AUC first increased to reach the maximum and then gradually decreased to 0.86+-0.02. The maximum AUC was yielded when adding two adjacent slices, with a value of 0.91+-0.01. This initial result provides meaningful information for optimizing machine learning-based decision-making support tools in the future.
SpectFormer: Frequency and Attention is what you need in a Vision Transformer
Apr 14, 2023

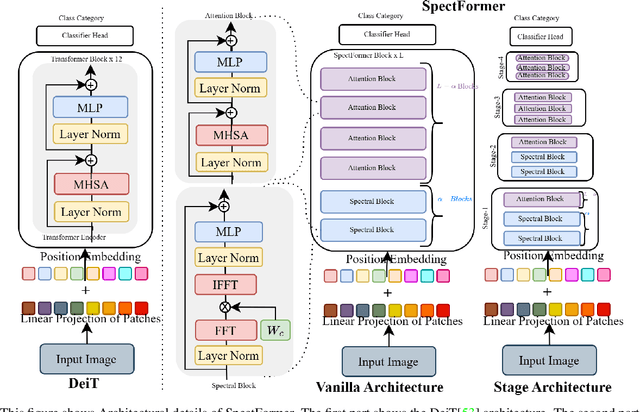
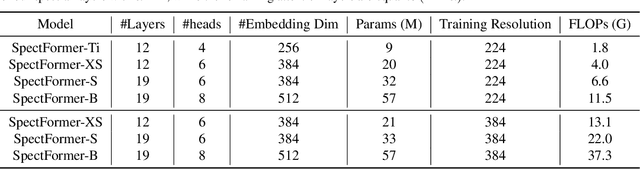
Vision transformers have been applied successfully for image recognition tasks. There have been either multi-headed self-attention based (ViT \cite{dosovitskiy2020image}, DeIT, \cite{touvron2021training}) similar to the original work in textual models or more recently based on spectral layers (Fnet\cite{lee2021fnet}, GFNet\cite{rao2021global}, AFNO\cite{guibas2021efficient}). We hypothesize that both spectral and multi-headed attention plays a major role. We investigate this hypothesis through this work and observe that indeed combining spectral and multi-headed attention layers provides a better transformer architecture. We thus propose the novel Spectformer architecture for transformers that combines spectral and multi-headed attention layers. We believe that the resulting representation allows the transformer to capture the feature representation appropriately and it yields improved performance over other transformer representations. For instance, it improves the top-1 accuracy by 2\% on ImageNet compared to both GFNet-H and LiT. SpectFormer-S reaches 84.25\% top-1 accuracy on ImageNet-1K (state of the art for small version). Further, Spectformer-L achieves 85.7\% that is the state of the art for the comparable base version of the transformers. We further ensure that we obtain reasonable results in other scenarios such as transfer learning on standard datasets such as CIFAR-10, CIFAR-100, Oxford-IIIT-flower, and Standford Car datasets. We then investigate its use in downstream tasks such of object detection and instance segmentation on the MS-COCO dataset and observe that Spectformer shows consistent performance that is comparable to the best backbones and can be further optimized and improved. Hence, we believe that combined spectral and attention layers are what are needed for vision transformers.
Wavelet Diffusion Models are fast and scalable Image Generators
Nov 29, 2022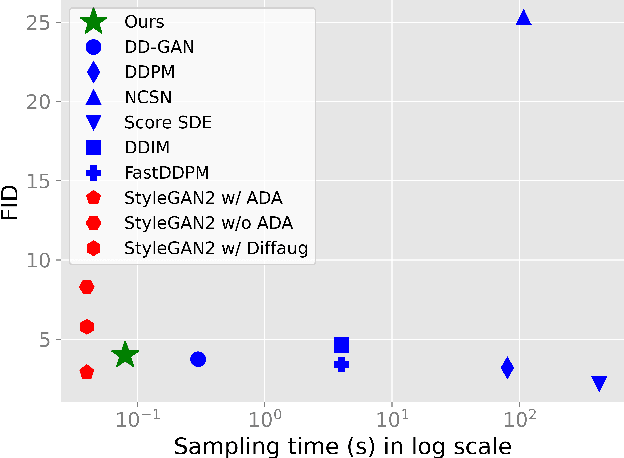
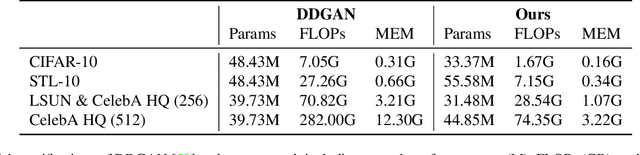
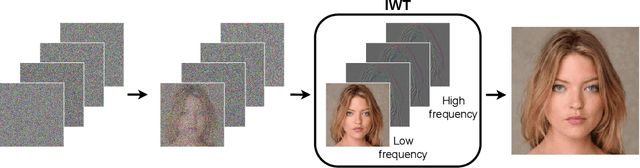
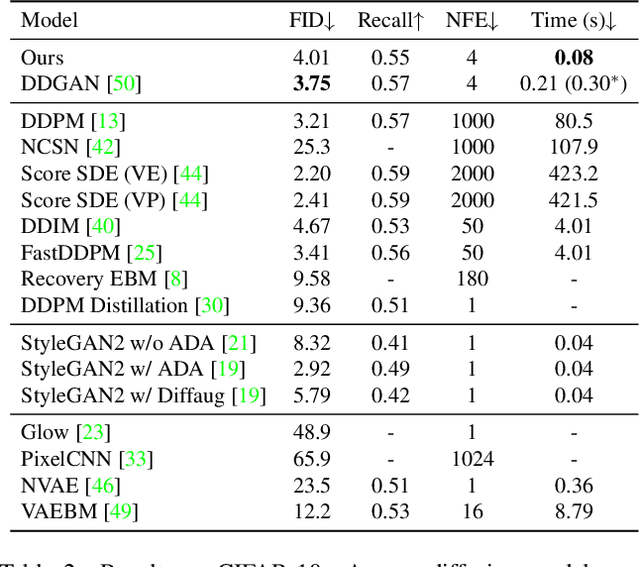
Diffusion models are rising as a powerful solution for high-fidelity image generation, which exceeds GANs in quality in many circumstances. However, their slow training and inference speed is a huge bottleneck, blocking them from being used in real-time applications. A recent DiffusionGAN method significantly decreases the models' running time by reducing the number of sampling steps from thousands to several, but their speeds still largely lag behind the GAN counterparts. This paper aims to reduce the speed gap by proposing a novel wavelet-based diffusion structure. We extract low-and-high frequency components from both image and feature levels via wavelet decomposition and adaptively handle these components for faster processing while maintaining good generation quality. Furthermore, we propose to use a reconstruction term, which effectively boosts the model training convergence. Experimental results on CelebA-HQ, CIFAR-10, LSUN-Church, and STL-10 datasets prove our solution is a stepping-stone to offering real-time and high-fidelity diffusion models. Our code and pre-trained checkpoints will be available at \url{https://github.com/VinAIResearch/WaveDiff.git}.