 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Empirical Study on the Robustness of the Segment Anything Model (SAM)
May 10, 2023
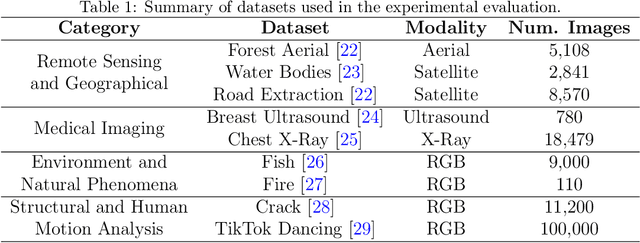
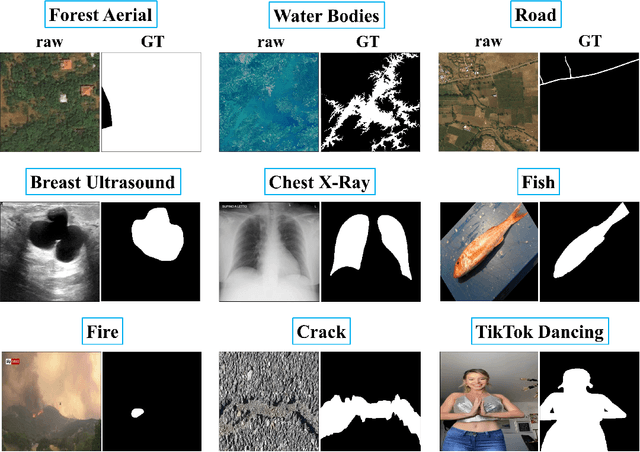
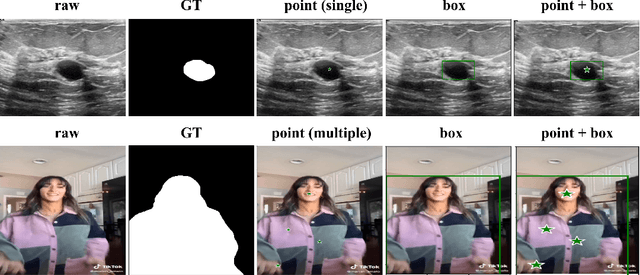
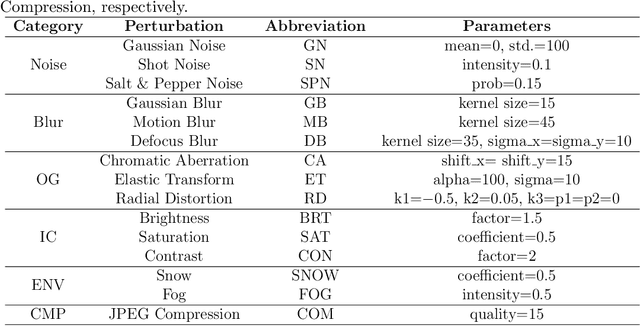
The Segment Anything Model (SAM) is a foundation model for general image segmentation. Although it exhibits impressive performance predominantly on natural images, understanding its robustness against various image perturbations and domains is critical for real-world applications where such challenges frequently arise. In this study we conduct a comprehensive robustness investigation of SAM under diverse real-world conditions. Our experiments encompass a wide range of image perturbations. Our experimental results demonstrate that SAM's performance generally declines under perturbed images, with varying degrees of vulnerability across different perturbations. By customizing prompting techniques and leveraging domain knowledge based on the unique characteristics of each dataset, the model's resilience to these perturbations can be enhanced, addressing dataset-specific challenges. This work sheds light on the limitations and strengths of SAM in real-world applications, promoting the development of more robust and versatile image segmentation solutions.
Few-Shot Domain Adaptation for Low Light RAW Image Enhancement
Mar 27, 2023
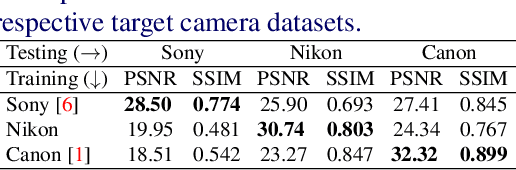
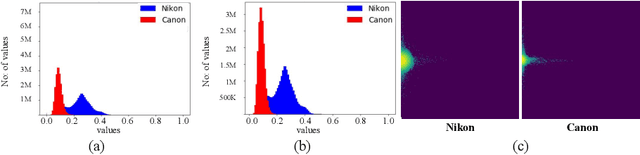
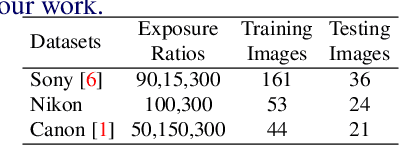
Enhancing practical low light raw images is a difficult task due to severe noise and color distortions from short exposure time and limited illumination. Despite the success of existing Convolutional Neural Network (CNN) based methods, their performance is not adaptable to different camera domains. In addition, such methods also require large datasets with short-exposure and corresponding long-exposure ground truth raw images for each camera domain, which is tedious to compile. To address this issue, we present a novel few-shot domain adaptation method to utilize the existing source camera labeled data with few labeled samples from the target camera to improve the target domain's enhancement quality in extreme low-light imaging. Our experiments show that only ten or fewer labeled samples from the target camera domain are sufficient to achieve similar or better enhancement performance than training a model with a large labeled target camera dataset. To support research in this direction, we also present a new low-light raw image dataset captured with a Nikon camera, comprising short-exposure and their corresponding long-exposure ground truth images.
* BMVC 2021 Best Student Paper Award (Runner-Up). Project Page: https://val.cds.iisc.ac.in/HDR/BMVC21/index.html
RGI: robust GAN-inversion for mask-free image inpainting and unsupervised pixel-wise anomaly detection
Feb 24, 2023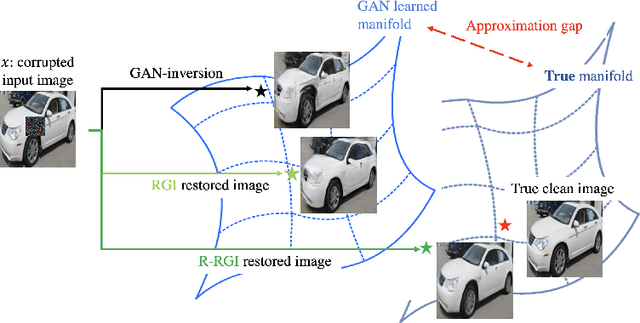
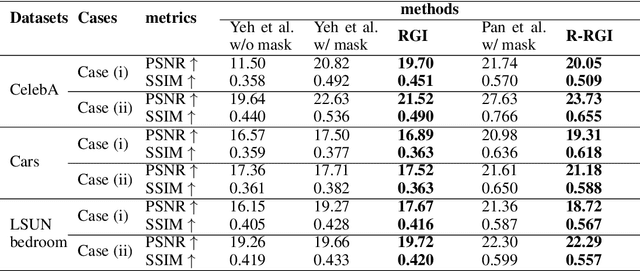
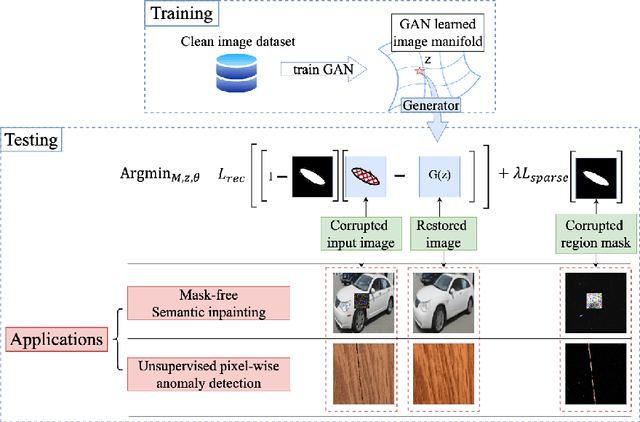
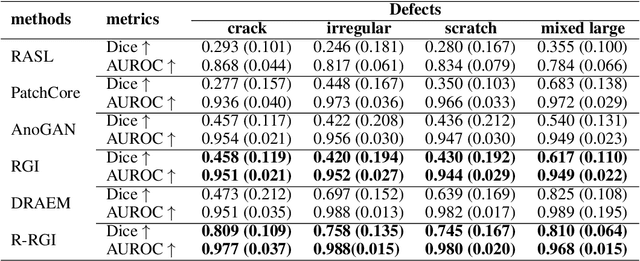
Generative adversarial networks (GANs), trained on a large-scale image dataset, can be a good approximator of the natural image manifold. GAN-inversion, using a pre-trained generator as a deep generative prior, is a promising tool for image restoration under corruptions. However, the performance of GAN-inversion can be limited by a lack of robustness to unknown gross corruptions, i.e., the restored image might easily deviate from the ground truth. In this paper, we propose a Robust GAN-inversion (RGI) method with a provable robustness guarantee to achieve image restoration under unknown \textit{gross} corruptions, where a small fraction of pixels are completely corrupted. Under mild assumptions, we show that the restored image and the identified corrupted region mask converge asymptotically to the ground truth. Moreover, we extend RGI to Relaxed-RGI (R-RGI) for generator fine-tuning to mitigate the gap between the GAN learned manifold and the true image manifold while avoiding trivial overfitting to the corrupted input image, which further improves the image restoration and corrupted region mask identification performance. The proposed RGI/R-RGI method unifies two important applications with state-of-the-art (SOTA) performance: (i) mask-free semantic inpainting, where the corruptions are unknown missing regions, the restored background can be used to restore the missing content; (ii) unsupervised pixel-wise anomaly detection, where the corruptions are unknown anomalous regions, the retrieved mask can be used as the anomalous region's segmentation mask.
Interpretable Alzheimer's Disease Classification Via a Contrastive Diffusion Autoencoder
Jun 05, 2023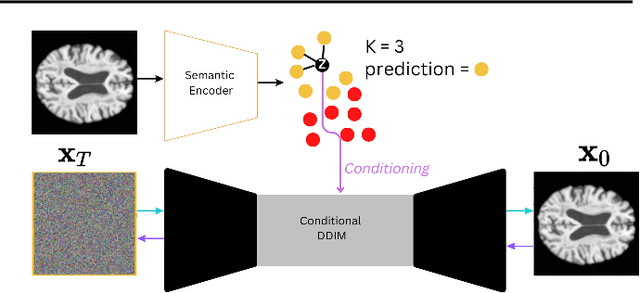
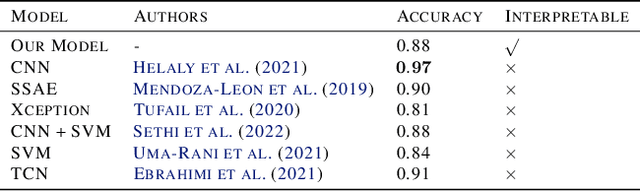
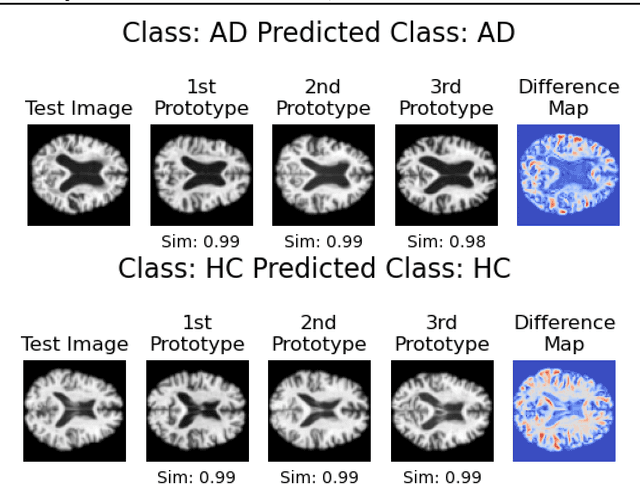
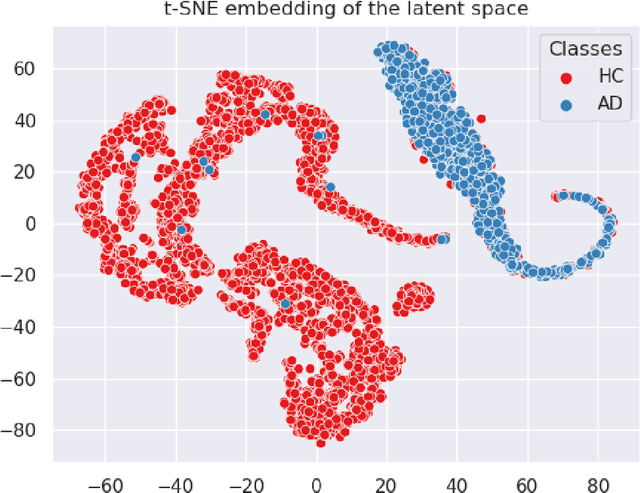
In visual object classification, humans often justify their choices by comparing objects to prototypical examples within that class. We may therefore increase the interpretability of deep learning models by imbuing them with a similar style of reasoning. In this work, we apply this principle by classifying Alzheimer's Disease based on the similarity of images to training examples within the latent space. We use a contrastive loss combined with a diffusion autoencoder backbone, to produce a semantically meaningful latent space, such that neighbouring latents have similar image-level features. We achieve a classification accuracy comparable to black box approaches on a dataset of 2D MRI images, whilst producing human interpretable model explanations. Therefore, this work stands as a contribution to the pertinent development of accurate and interpretable deep learning within medical imaging.
CG-3DSRGAN: A classification guided 3D generative adversarial network for image quality recovery from low-dose PET images
Apr 03, 2023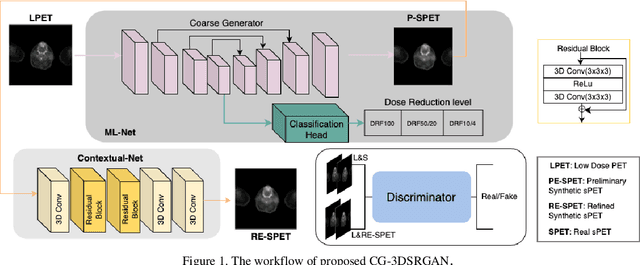
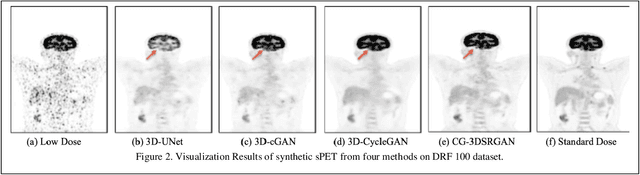
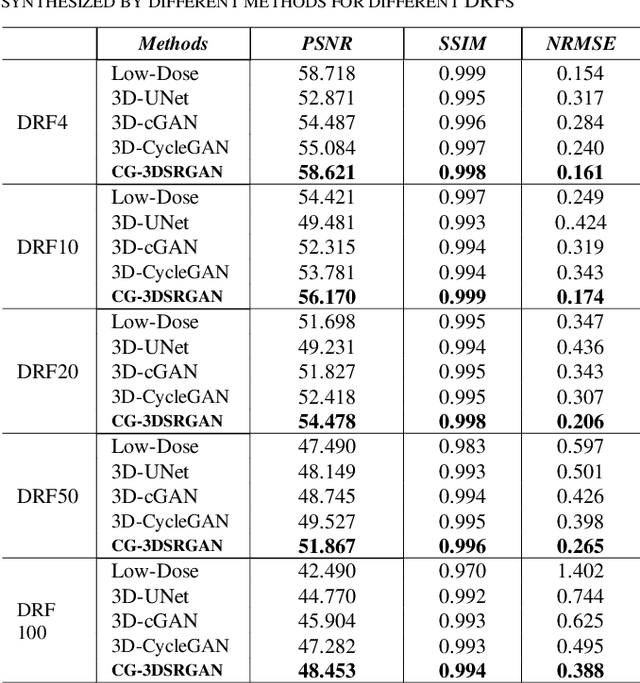
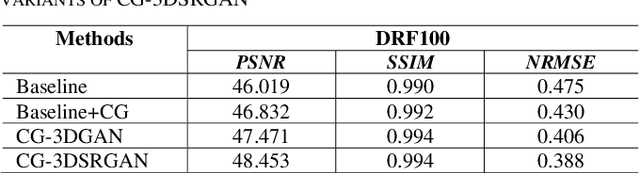
Positron emission tomography (PET) is the most sensitive molecular imaging modality routinely applied in our modern healthcare. High radioactivity caused by the injected tracer dose is a major concern in PET imaging and limits its clinical applications. However, reducing the dose leads to inadequate image quality for diagnostic practice. Motivated by the need to produce high quality images with minimum low-dose, Convolutional Neural Networks (CNNs) based methods have been developed for high quality PET synthesis from its low-dose counterparts. Previous CNNs-based studies usually directly map low-dose PET into features space without consideration of different dose reduction level. In this study, a novel approach named CG-3DSRGAN (Classification-Guided Generative Adversarial Network with Super Resolution Refinement) is presented. Specifically, a multi-tasking coarse generator, guided by a classification head, allows for a more comprehensive understanding of the noise-level features present in the low-dose data, resulting in improved image synthesis. Moreover, to recover spatial details of standard PET, an auxiliary super resolution network - Contextual-Net - is proposed as a second-stage training to narrow the gap between coarse prediction and standard PET. We compared our method to the state-of-the-art methods on whole-body PET with different dose reduction factors (DRFs). Experiments demonstrate our method can outperform others on all DRF.
XrayGPT: Chest Radiographs Summarization using Medical Vision-Language Models
Jun 13, 2023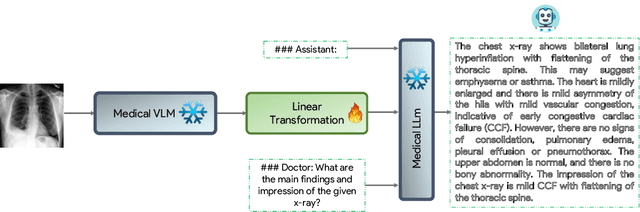
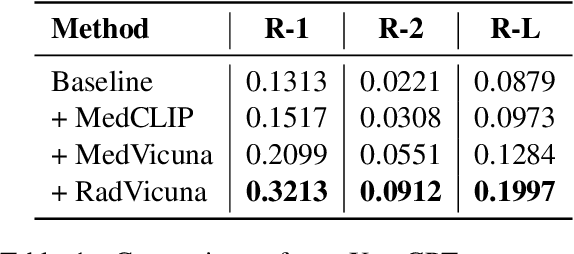


The latest breakthroughs in large vision-language models, such as Bard and GPT-4, have showcased extraordinary abilities in performing a wide range of tasks. Such models are trained on massive datasets comprising billions of public image-text pairs with diverse tasks. However, their performance on task-specific domains, such as radiology, is still under-investigated and potentially limited due to a lack of sophistication in understanding biomedical images. On the other hand, conversational medical models have exhibited remarkable success but have mainly focused on text-based analysis. In this paper, we introduce XrayGPT, a novel conversational medical vision-language model that can analyze and answer open-ended questions about chest radiographs. Specifically, we align both medical visual encoder (MedClip) with a fine-tuned large language model (Vicuna), using a simple linear transformation. This alignment enables our model to possess exceptional visual conversation abilities, grounded in a deep understanding of radiographs and medical domain knowledge. To enhance the performance of LLMs in the medical context, we generate ~217k interactive and high-quality summaries from free-text radiology reports. These summaries serve to enhance the performance of LLMs through the fine-tuning process. Our approach opens up new avenues the research for advancing the automated analysis of chest radiographs. Our open-source demos, models, and instruction sets are available at: https://github.com/mbzuai-oryx/XrayGPT.
Learning Unnormalized Statistical Models via Compositional Optimization
Jun 13, 2023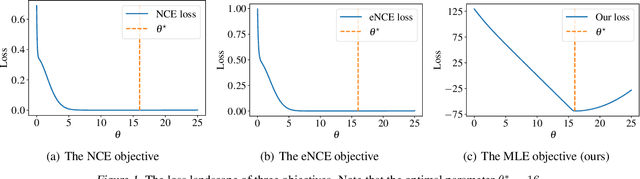
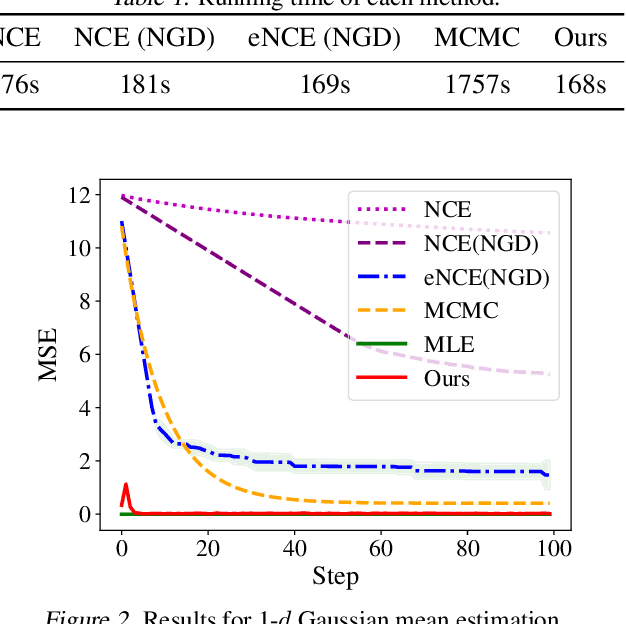
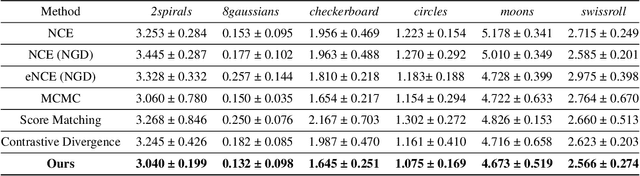

Learning unnormalized statistical models (e.g., energy-based models) is computationally challenging due to the complexity of handling the partition function. To eschew this complexity, noise-contrastive estimation~(NCE) has been proposed by formulating the objective as the logistic loss of the real data and the artificial noise. However, as found in previous works, NCE may perform poorly in many tasks due to its flat loss landscape and slow convergence. In this paper, we study it a direct approach for optimizing the negative log-likelihood of unnormalized models from the perspective of compositional optimization. To tackle the partition function, a noise distribution is introduced such that the log partition function can be written as a compositional function whose inner function can be estimated with stochastic samples. Hence, the objective can be optimized by stochastic compositional optimization algorithms. Despite being a simple method, we demonstrate that it is more favorable than NCE by (1) establishing a fast convergence rate and quantifying its dependence on the noise distribution through the variance of stochastic estimators; (2) developing better results for one-dimensional Gaussian mean estimation by showing our objective has a much favorable loss landscape and hence our method enjoys faster convergence; (3) demonstrating better performance on multiple applications, including density estimation, out-of-distribution detection, and real image generation.
GeometricImageNet: Extending convolutional neural networks to vector and tensor images
May 21, 2023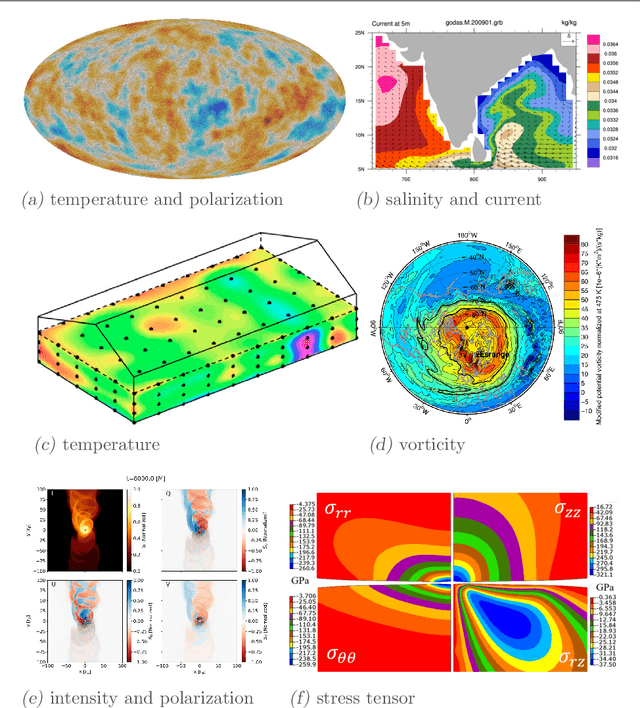
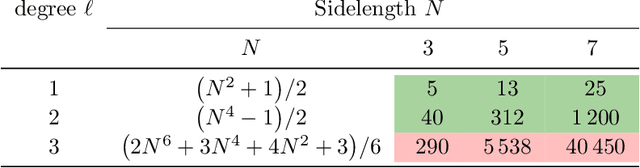
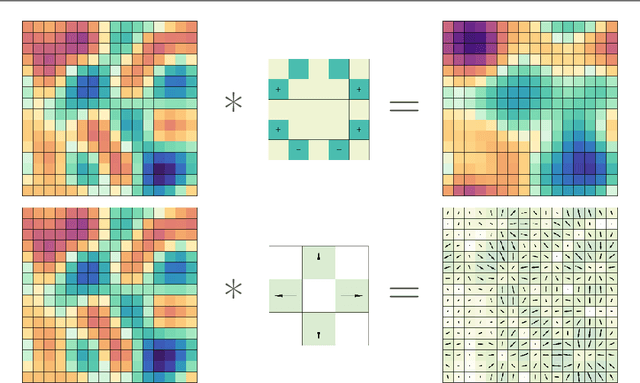

Convolutional neural networks and their ilk have been very successful for many learning tasks involving images. These methods assume that the input is a scalar image representing the intensity in each pixel, possibly in multiple channels for color images. In natural-science domains however, image-like data sets might have vectors (velocity, say), tensors (polarization, say), pseudovectors (magnetic field, say), or other geometric objects in each pixel. Treating the components of these objects as independent channels in a CNN neglects their structure entirely. Our formulation -- the GeometricImageNet -- combines a geometric generalization of convolution with outer products, tensor index contractions, and tensor index permutations to construct geometric-image functions of geometric images that use and benefit from the tensor structure. The framework permits, with a very simple adjustment, restriction to function spaces that are exactly equivariant to translations, discrete rotations, and reflections. We use representation theory to quantify the dimension of the space of equivariant polynomial functions on 2-dimensional vector images. We give partial results on the expressivity of GeometricImageNet on small images. In numerical experiments, we find that GeometricImageNet has good generalization for a small simulated physics system, even when trained with a small training set. We expect this tool will be valuable for scientific and engineering machine learning, for example in cosmology or ocean dynamics.
Sorted Convolutional Network for Achieving Continuous Rotational Invariance
May 23, 2023

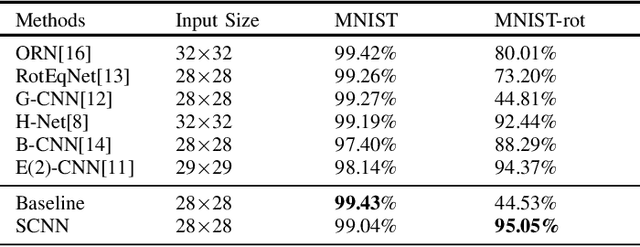
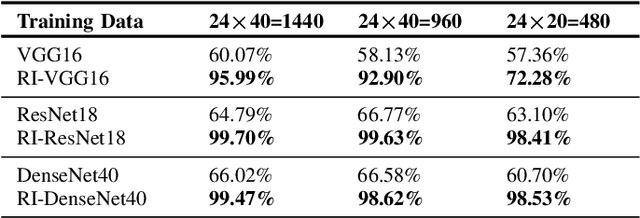
The topic of achieving rotational invariance in convolutional neural networks (CNNs) has gained considerable attention recently, as this invariance is crucial for many computer vision tasks such as image classification and matching. In this letter, we propose a Sorting Convolution (SC) inspired by some hand-crafted features of texture images, which achieves continuous rotational invariance without requiring additional learnable parameters or data augmentation. Further, SC can directly replace the conventional convolution operations in a classic CNN model to achieve its rotational invariance. Based on MNIST-rot dataset, we first analyze the impact of convolutional kernel sizes, different sampling and sorting strategies on SC's rotational invariance, and compare our method with previous rotation-invariant CNN models. Then, we combine SC with VGG, ResNet and DenseNet, and conduct classification experiments on popular texture and remote sensing image datasets. Our results demonstrate that SC achieves the best performance in the aforementioned tasks.
Multimodal Garment Designer: Human-Centric Latent Diffusion Models for Fashion Image Editing
Apr 04, 2023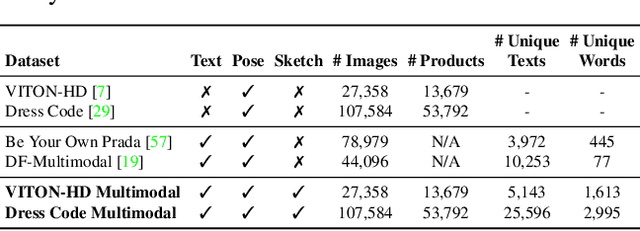
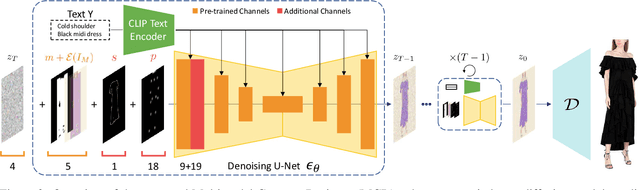
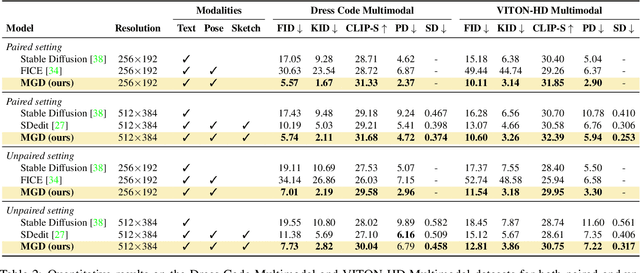

Fashion illustration is used by designers to communicate their vision and to bring the design idea from conceptualization to realization, showing how clothes interact with the human body. In this context, computer vision can thus be used to improve the fashion design process. Differently from previous works that mainly focused on the virtual try-on of garments, we propose the task of multimodal-conditioned fashion image editing, guiding the generation of human-centric fashion images by following multimodal prompts, such as text, human body poses, and garment sketches. We tackle this problem by proposing a new architecture based on latent diffusion models, an approach that has not been used before in the fashion domain. Given the lack of existing datasets suitable for the task, we also extend two existing fashion datasets, namely Dress Code and VITON-HD, with multimodal annotations collected in a semi-automatic manner. Experimental results on these new datasets demonstrate the effectiveness of our proposal, both in terms of realism and coherence with the given multimodal inputs. Source code and collected multimodal annotations will be publicly released at: https://github.com/aimagelab/multimodal-garment-designer.