 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti View Subspace Clustering
Multi-view subspace clustering is the process of clustering data points from multiple views or modalities into subspaces.
Papers and Code
Subspace Clustering in Wavelet Packets Domain
Jun 06, 2024



Subspace clustering (SC) algorithms utilize the union of subspaces model to cluster data points according to the subspaces from which they are drawn. To better address separability of subspaces and robustness to noise we propose a wavelet packet (WP) based transform domain subspace clustering. Depending on the number of resolution levels, WP yields several representations instantiated in terms of subbands. The first approach combines original and subband data into one complementary multi-view representation. Afterward, we formulate joint representation learning as a low-rank MERA tensor network approximation problem. That is motivated by the strong representation power of the MERA network to capture complex intra/inter-view dependencies in corresponding self-representation tensor. In the second approach, we use a self-stopping computationally efficient method to select the subband with the smallest clustering error on the validation set. When existing SC algorithms are applied to the chosen subband, their performance is expected to improve. Consequently, both approaches enable the re-use of SC algorithms developed so far. Improved clustering performance is due to the dual nature of subbands as representations and filters, which is essential for noise suppression. We exemplify the proposed WP domain approach to SC on the MERA tensor network and eight other well-known linear SC algorithms using six well-known image datasets representing faces, digits, and objects. Although WP domain-based SC is a linear method, it achieved clustering performance comparable with some best deep SC algorithms and outperformed many other deep SC algorithms by a significant margin. That is in particular case for the WP MERA SC algorithm. On the COIL100 dataset, it achieves an accuracy of 87.45% and outperforms the best deep SC competitor in the amount of 14.75%.
Multi-level Graph Subspace Contrastive Learning for Hyperspectral Image Clustering
Apr 08, 2024Hyperspectral image (HSI) clustering is a challenging task due to its high complexity. Despite subspace clustering shows impressive performance for HSI, traditional methods tend to ignore the global-local interaction in HSI data. In this study, we proposed a multi-level graph subspace contrastive learning (MLGSC) for HSI clustering. The model is divided into the following main parts. Graph convolution subspace construction: utilizing spectral and texture feautures to construct two graph convolution views. Local-global graph representation: local graph representations were obtained by step-by-step convolutions and a more representative global graph representation was obtained using an attention-based pooling strategy. Multi-level graph subspace contrastive learning: multi-level contrastive learning was conducted to obtain local-global joint graph representations, to improve the consistency of the positive samples between views, and to obtain more robust graph embeddings. Specifically, graph-level contrastive learning is used to better learn global representations of HSI data. Node-level intra-view and inter-view contrastive learning is designed to learn joint representations of local regions of HSI. The proposed model is evaluated on four popular HSI datasets: Indian Pines, Pavia University, Houston, and Xu Zhou. The overall accuracies are 97.75%, 99.96%, 92.28%, and 95.73%, which significantly outperforms the current state-of-the-art clustering methods.
Adaptively Topological Tensor Network for Multi-view Subspace Clustering
May 01, 2023Multi-view subspace clustering methods have employed learned self-representation tensors from different tensor decompositions to exploit low rank information. However, the data structures embedded with self-representation tensors may vary in different multi-view datasets. Therefore, a pre-defined tensor decomposition may not fully exploit low rank information for a certain dataset, resulting in sub-optimal multi-view clustering performance. To alleviate the aforementioned limitations, we propose the adaptively topological tensor network (ATTN) by determining the edge ranks from the structural information of the self-representation tensor, and it can give a better tensor representation with the data-driven strategy. Specifically, in multi-view tensor clustering, we analyze the higher-order correlations among different modes of a self-representation tensor, and prune the links of the weakly correlated ones from a fully connected tensor network. Therefore, the newly obtained tensor networks can efficiently explore the essential clustering information with self-representation with different tensor structures for various datasets. A greedy adaptive rank-increasing strategy is further applied to improve the capture capacity of low rank structure. We apply ATTN on multi-view subspace clustering and utilize the alternating direction method of multipliers to solve it. Experimental results show that multi-view subspace clustering based on ATTN outperforms the counterparts on six multi-view datasets.
Deep Multi-View Subspace Clustering with Anchor Graph
May 11, 2023



Deep multi-view subspace clustering (DMVSC) has recently attracted increasing attention due to its promising performance. However, existing DMVSC methods still have two issues: (1) they mainly focus on using autoencoders to nonlinearly embed the data, while the embedding may be suboptimal for clustering because the clustering objective is rarely considered in autoencoders, and (2) existing methods typically have a quadratic or even cubic complexity, which makes it challenging to deal with large-scale data. To address these issues, in this paper we propose a novel deep multi-view subspace clustering method with anchor graph (DMCAG). To be specific, DMCAG firstly learns the embedded features for each view independently, which are used to obtain the subspace representations. To significantly reduce the complexity, we construct an anchor graph with small size for each view. Then, spectral clustering is performed on an integrated anchor graph to obtain pseudo-labels. To overcome the negative impact caused by suboptimal embedded features, we use pseudo-labels to refine the embedding process to make it more suitable for the clustering task. Pseudo-labels and embedded features are updated alternately. Furthermore, we design a strategy to keep the consistency of the labels based on contrastive learning to enhance the clustering performance. Empirical studies on real-world datasets show that our method achieves superior clustering performance over other state-of-the-art methods.
Multilayer Graph Approach to Deep Subspace Clustering
Jan 30, 2024Deep subspace clustering (DSC) networks based on self-expressive model learn representation matrix, often implemented in terms of fully connected network, in the embedded space. After the learning is finished, representation matrix is used by spectral clustering module to assign labels to clusters. However, such approach ignores complementary information that exist in other layers of the encoder (including the input data themselves). Herein, we apply selected linear subspace clustering algorithm to learn representation matrices from representations learned by all layers of encoder network including the input data. Afterward, we learn a multilayer graph that in a multi-view like manner integrates information from graph Laplacians of all used layers. That improves further performance of selected DSC network. Furthermore, we also provide formulation of our approach to cluster out-of-sample/test data points. We validate proposed approach on four well-known datasets with two DSC networks as baseline models. In almost all the cases, proposed approach achieved statistically significant improvement in three performance metrics. MATLAB code of proposed algorithm is posted on https://github.com/lovro-sinda/MLG-DSC.
Multi-view MERA Subspace Clustering
May 16, 2023Tensor-based multi-view subspace clustering (MSC) can capture high-order correlation in the self-representation tensor. Current tensor decompositions for MSC suffer from highly unbalanced unfolding matrices or rotation sensitivity, failing to fully explore inter/intra-view information. Using the advanced tensor network, namely, multi-scale entanglement renormalization ansatz (MERA), we propose a low-rank MERA based MSC (MERA-MSC) algorithm, where MERA factorizes a tensor into contractions of one top core factor and the rest orthogonal/semi-orthogonal factors. Benefiting from multiple interactions among orthogonal/semi-orthogonal (low-rank) factors, the low-rank MERA has a strong representation power to capture the complex inter/intra-view information in the self-representation tensor. The alternating direction method of multipliers is adopted to solve the optimization model. Experimental results on five multi-view datasets demonstrate MERA-MSC has superiority against the compared algorithms on six evaluation metrics. Furthermore, we extend MERA-MSC by incorporating anchor learning to develop a scalable low-rank MERA based multi-view clustering method (sMREA-MVC). The effectiveness and efficiency of sMERA-MVC have been validated on three large-scale multi-view datasets. To our knowledge, this is the first work to introduce MERA to the multi-view clustering topic. The codes of MERA-MSC and sMERA-MVC are publicly available at https://github.com/longzhen520/MERA-MSC.
Hyper-Laplacian Regularized Concept Factorization in Low-rank Tensor Space for Multi-view Clustering
Apr 22, 2023Tensor-oriented multi-view subspace clustering has achieved significant strides in assessing high-order correlations and improving clustering analysis of multi-view data. Nevertheless, most of existing investigations are typically hampered by the two flaws. First, self-representation based tensor subspace learning usually induces high time and space complexity, and is limited in perceiving nonlinear local structure in the embedding space. Second, the tensor singular value decomposition (t-SVD) model redistributes each singular value equally without considering the diverse importance among them. To well cope with the issues, we propose a hyper-Laplacian regularized concept factorization (HLRCF) in low-rank tensor space for multi-view clustering. Specifically, we adopt the concept factorization to explore the latent cluster-wise representation of each view. Further, the hypergraph Laplacian regularization endows the model with the capability of extracting the nonlinear local structures in the latent space. Considering that different tensor singular values associate structural information with unequal importance, we develop a self-weighted tensor Schatten p-norm to constrain the tensor comprised of all cluster-wise representations. Notably, the tensor with smaller size greatly decreases the time and space complexity in the low-rank optimization. Finally, experimental results on eight benchmark datasets exhibit that HLRCF outperforms other multi-view methods, showingcasing its superior performance.
Towards Generalized Multi-stage Clustering: Multi-view Self-distillation
Oct 29, 2023Existing multi-stage clustering methods independently learn the salient features from multiple views and then perform the clustering task. Particularly, multi-view clustering (MVC) has attracted a lot of attention in multi-view or multi-modal scenarios. MVC aims at exploring common semantics and pseudo-labels from multiple views and clustering in a self-supervised manner. However, limited by noisy data and inadequate feature learning, such a clustering paradigm generates overconfident pseudo-labels that mis-guide the model to produce inaccurate predictions. Therefore, it is desirable to have a method that can correct this pseudo-label mistraction in multi-stage clustering to avoid the bias accumulation. To alleviate the effect of overconfident pseudo-labels and improve the generalization ability of the model, this paper proposes a novel multi-stage deep MVC framework where multi-view self-distillation (DistilMVC) is introduced to distill dark knowledge of label distribution. Specifically, in the feature subspace at different hierarchies, we explore the common semantics of multiple views through contrastive learning and obtain pseudo-labels by maximizing the mutual information between views. Additionally, a teacher network is responsible for distilling pseudo-labels into dark knowledge, supervising the student network and improving its predictive capabilities to enhance the robustness. Extensive experiments on real-world multi-view datasets show that our method has better clustering performance than state-of-the-art methods.
Double Graphs Regularized Multi-view Subspace Clustering
Sep 30, 2022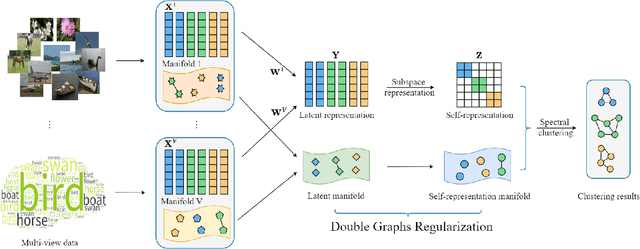

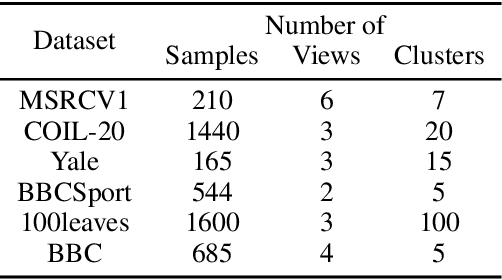
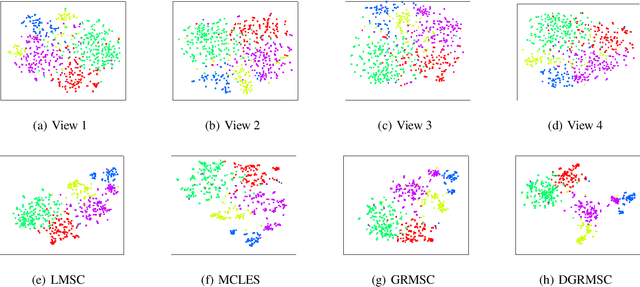
Recent years have witnessed a growing academic interest in multi-view subspace clustering. In this paper, we propose a novel Double Graphs Regularized Multi-view Subspace Clustering (DGRMSC) method, which aims to harness both global and local structural information of multi-view data in a unified framework. Specifically, DGRMSC firstly learns a latent representation to exploit the global complementary information of multiple views. Based on the learned latent representation, we learn a self-representation to explore its global cluster structure. Further, Double Graphs Regularization (DGR) is performed on both latent representation and self-representation to take advantage of their local manifold structures simultaneously. Then, we design an iterative algorithm to solve the optimization problem effectively. Extensive experimental results on real-world datasets demonstrate the effectiveness of the proposed method.
Tucker-O-Minus Decomposition for Multi-view Tensor Subspace Clustering
Oct 23, 2022



With powerful ability to exploit latent structure of self-representation information, different tensor decompositions have been employed into low rank multi-view clustering (LRMVC) models for achieving significant performance. However, current approaches suffer from a series of problems related to those tensor decomposition, such as the unbalanced matricization scheme, rotation sensitivity, deficient correlations capture and so forth. All these will lead to LRMVC having insufficient access to global information, which is contrary to the target of multi-view clustering. To alleviate these problems, we propose a new tensor decomposition called Tucker-O-Minus Decomposition (TOMD) for multi-view clustering. Specifically, based on the Tucker format, we additionally employ the O-minus structure, which consists of a circle with an efficient bridge linking two weekly correlated factors. In this way, the core tensor in Tucker format is replaced by the O-minus architecture with a more balanced structure, and the enhanced capacity of capturing the global low rank information will be achieved. The proposed TOMD also provides more compact and powerful representation abilities for the self-representation tensor, simultaneously. The alternating direction method of multipliers is used to solve the proposed model TOMD-MVC. Numerical experiments on six benchmark data sets demonstrate the superiority of our proposed method in terms of F-score, precision, recall, normalized mutual information, adjusted rand index, and accuracy.