 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinynet
Papers and Code
RS-TinyNet: Stage-wise Feature Fusion Network for Detecting Tiny Objects in Remote Sensing Images
Jul 17, 2025Detecting tiny objects in remote sensing (RS) imagery has been a long-standing challenge due to their extremely limited spatial information, weak feature representations, and dense distributions across complex backgrounds. Despite numerous efforts devoted, mainstream detectors still underperform in such scenarios. To bridge this gap, we introduce RS-TinyNet, a multi-stage feature fusion and enhancement model explicitly tailored for RS tiny object detection in various RS scenarios. RS-TinyNet comes with two novel designs: tiny object saliency modeling and feature integrity reconstruction. Guided by these principles, we design three step-wise feature enhancement modules. Among them, the multi-dimensional collaborative attention (MDCA) module employs multi-dimensional attention to enhance the saliency of tiny objects. Additionally, the auxiliary reversible branch (ARB) and a progressive fusion detection head (PFDH) module are introduced to preserve information flow and fuse multi-level features to bridge semantic gaps and retain structural detail. Comprehensive experiments on public RS dataset AI-TOD show that our RS-TinyNet surpasses existing state-of-the-art (SOTA) detectors by 4.0% AP and 6.5% AP75. Evaluations on DIOR benchmark dataset further validate its superior detection performance in diverse RS scenarios. These results demonstrate that the proposed multi-stage feature fusion strategy offers an effective and practical solution for tiny object detection in complex RS environments.
Image Classification with Classic and Deep Learning Techniques
May 11, 2021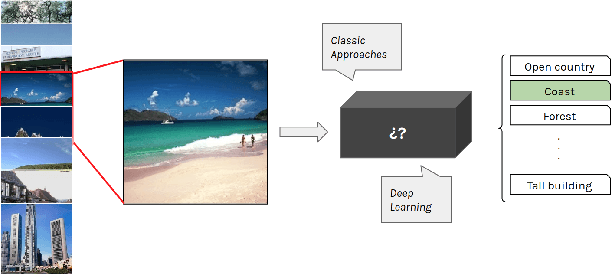
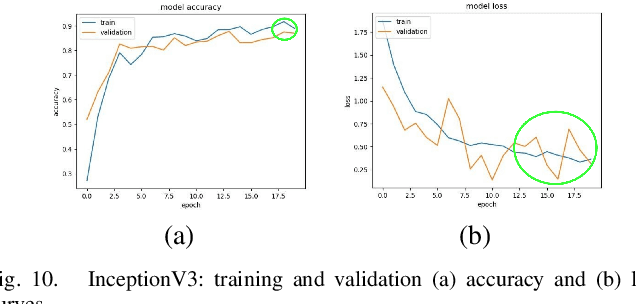
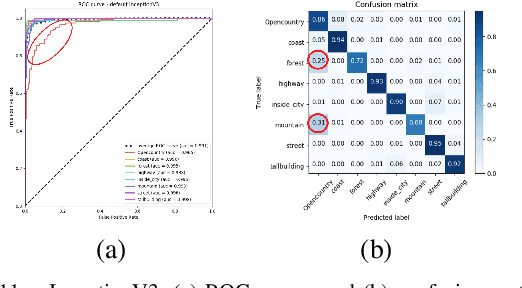
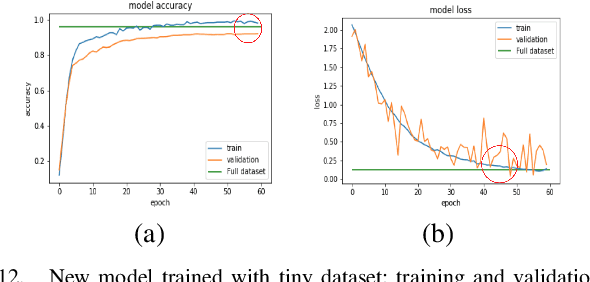
To classify images based on their content is one of the most studied topics in the field of computer vision. Nowadays, this problem can be addressed using modern techniques such as Convolutional Neural Networks (CNN), but over the years different classical methods have been developed. In this report, we implement an image classifier using both classic computer vision and deep learning techniques. Specifically, we study the performance of a Bag of Visual Words classifier using Support Vector Machines, a Multilayer Perceptron, an existing architecture named InceptionV3 and our own CNN, TinyNet, designed from scratch. We evaluate each of the cases in terms of accuracy and loss, and we obtain results that vary between 0.6 and 0.96 depending on the model and configuration used.
Model Rubik's Cube: Twisting Resolution, Depth and Width for TinyNets
Oct 28, 2020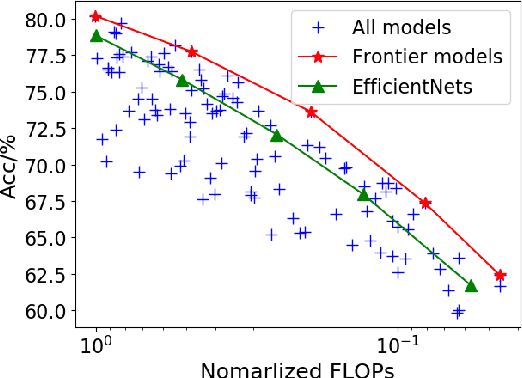

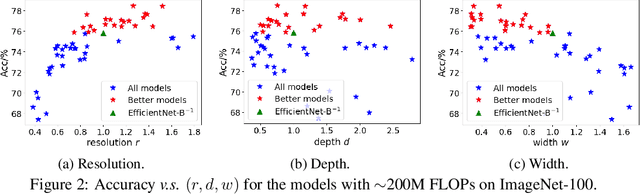
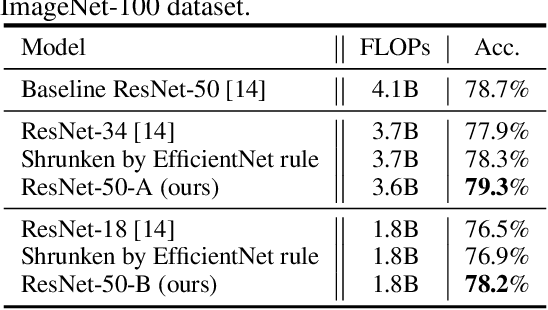
To obtain excellent deep neural architectures, a series of techniques are carefully designed in EfficientNets. The giant formula for simultaneously enlarging the resolution, depth and width provides us a Rubik's cube for neural networks. So that we can find networks with high efficiency and excellent performance by twisting the three dimensions. This paper aims to explore the twisting rules for obtaining deep neural networks with minimum model sizes and computational costs. Different from the network enlarging, we observe that resolution and depth are more important than width for tiny networks. Therefore, the original method, i.e., the compound scaling in EfficientNet is no longer suitable. To this end, we summarize a tiny formula for downsizing neural architectures through a series of smaller models derived from the EfficientNet-B0 with the FLOPs constraint. Experimental results on the ImageNet benchmark illustrate that our TinyNet performs much better than the smaller version of EfficientNets using the inversed giant formula. For instance, our TinyNet-E achieves a 59.9% Top-1 accuracy with only 24M FLOPs, which is about 1.9% higher than that of the previous best MobileNetV3 with similar computational cost. Code will be available at https://github.com/huawei-noah/CV-Backbones/tree/main/tinynet, and https://gitee.com/mindspore/mindspore/tree/master/model_zoo/research/cv/tinynet.
Dynamic Runtime Feature Map Pruning
Dec 24, 2018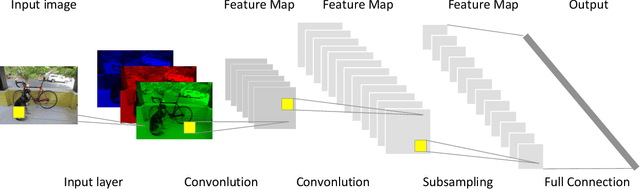
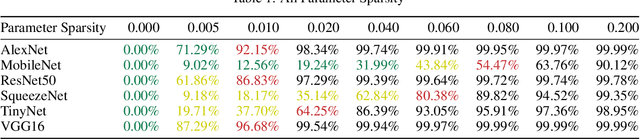
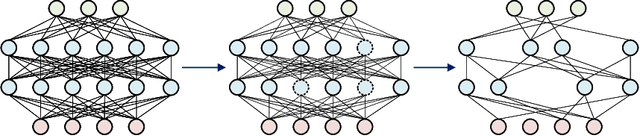
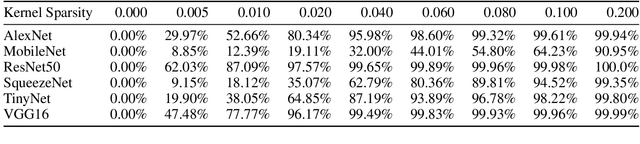
High bandwidth requirements are an obstacle for accelerating the training and inference of deep neural networks. Most previous research focuses on reducing the size of kernel maps for inference. We analyze parameter sparsity of six popular convolutional neural networks - AlexNet, MobileNet, ResNet-50, SqueezeNet, TinyNet, and VGG16. Of the networks considered, those using ReLU (AlexNet, SqueezeNet, VGG16) contain a high percentage of 0-valued parameters and can be statically pruned. Networks with Non-ReLU activation functions in some cases may not contain any 0-valued parameters (ResNet-50, TinyNet). We also investigate runtime feature map usage and find that input feature maps comprise the majority of bandwidth requirements when depth-wise convolution and point-wise convolutions used. We introduce dynamic runtime pruning of feature maps and show that 10% of dynamic feature map execution can be removed without loss of accuracy. We then extend dynamic pruning to allow for values within an epsilon of zero and show a further 5% reduction of feature map loading with a 1% loss of accuracy in top-1.