 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial Media Image Tagging
Papers and Code
Enhancing Ground-to-Aerial Image Matching for Visual Misinformation Detection Using Semantic Segmentation
Feb 10, 2025



The recent advancements in generative AI techniques, which have significantly increased the online dissemination of altered images and videos, have raised serious concerns about the credibility of digital media available on the Internet and distributed through information channels and social networks. This issue particularly affects domains that rely heavily on trustworthy data, such as journalism, forensic analysis, and Earth observation. To address these concerns, the ability to geolocate a non-geo-tagged ground-view image without external information, such as GPS coordinates, has become increasingly critical. This study tackles the challenge of linking a ground-view image, potentially exhibiting varying fields of view (FoV), to its corresponding satellite image without the aid of GPS data. To achieve this, we propose a novel four-stream Siamese-like architecture, the Quadruple Semantic Align Net (SAN-QUAD), which extends previous state-of-the-art (SOTA) approaches by leveraging semantic segmentation applied to both ground and satellite imagery. Experimental results on a subset of the CVUSA dataset demonstrate significant improvements of up to 9.8\% over prior methods across various FoV settings.
MM-Soc: Benchmarking Multimodal Large Language Models in Social Media Platforms
Feb 21, 2024



Social media platforms are hubs for multimodal information exchange, encompassing text, images, and videos, making it challenging for machines to comprehend the information or emotions associated with interactions in online spaces. Multimodal Large Language Models (MLLMs) have emerged as a promising solution to address these challenges, yet struggle with accurately interpreting human emotions and complex contents like misinformation. This paper introduces MM-Soc, a comprehensive benchmark designed to evaluate MLLMs' understanding of multimodal social media content. MM-Soc compiles prominent multimodal datasets and incorporates a novel large-scale YouTube tagging dataset, targeting a range of tasks from misinformation detection, hate speech detection, and social context generation. Through our exhaustive evaluation on ten size-variants of four open-source MLLMs, we have identified significant performance disparities, highlighting the need for advancements in models' social understanding capabilities. Our analysis reveals that, in a zero-shot setting, various types of MLLMs generally exhibit difficulties in handling social media tasks. However, MLLMs demonstrate performance improvements post fine-tuning, suggesting potential pathways for improvement.
Leveraging Selective Prediction for Reliable Image Geolocation
Nov 23, 2021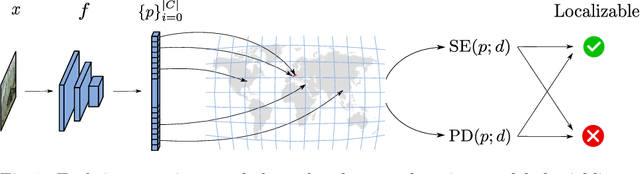
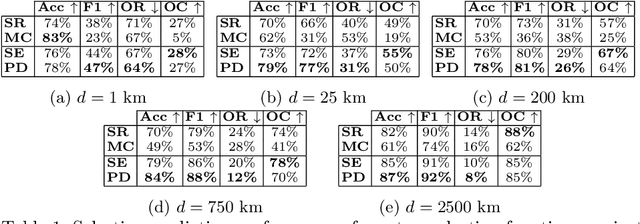

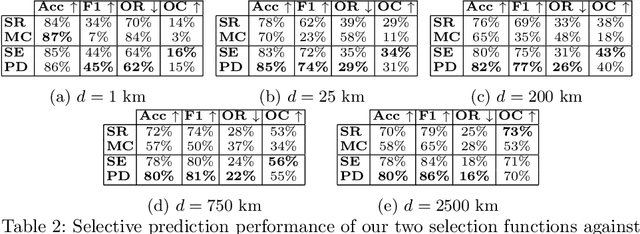
Reliable image geolocation is crucial for several applications, ranging from social media geo-tagging to fake news detection. State-of-the-art geolocation methods surpass human performance on the task of geolocation estimation from images. However, no method assesses the suitability of an image for this task, which results in unreliable and erroneous estimations for images containing no geolocation clues. In this paper, we define the task of image localizability, i.e. suitability of an image for geolocation, and propose a selective prediction methodology to address the task. In particular, we propose two novel selection functions that leverage the output probability distributions of geolocation models to infer localizability at different scales. Our selection functions are benchmarked against the most widely used selective prediction baselines, outperforming them in all cases. By abstaining from predicting non-localizable images, we improve geolocation accuracy from 27.8% to 70.5% at the city-scale, and thus make current geolocation models reliable for real-world applications.
GMFIM: A Generative Mask-guided Facial Image Manipulation Model for Privacy Preservation
Jan 10, 2022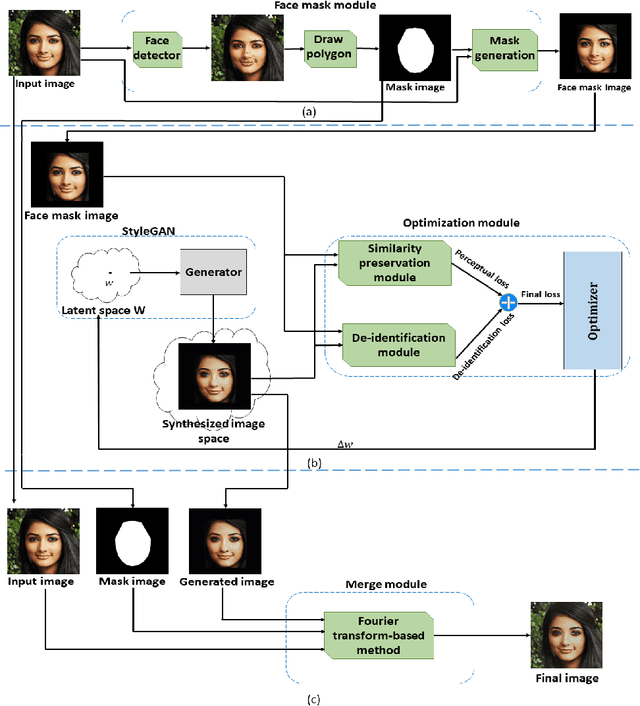



The use of social media websites and applications has become very popular and people share their photos on these networks. Automatic recognition and tagging of people's photos on these networks has raised privacy preservation issues and users seek methods for hiding their identities from these algorithms. Generative adversarial networks (GANs) are shown to be very powerful in generating face images in high diversity and also in editing face images. In this paper, we propose a Generative Mask-guided Face Image Manipulation (GMFIM) model based on GANs to apply imperceptible editing to the input face image to preserve the privacy of the person in the image. Our model consists of three main components: a) the face mask module to cut the face area out of the input image and omit the background, b) the GAN-based optimization module for manipulating the face image and hiding the identity and, c) the merge module for combining the background of the input image and the manipulated de-identified face image. Different criteria are considered in the loss function of the optimization step to produce high-quality images that are as similar as possible to the input image while they cannot be recognized by AFR systems. The results of the experiments on different datasets show that our model can achieve better performance against automated face recognition systems in comparison to the state-of-the-art methods and it catches a higher attack success rate in most experiments from a total of 18. Moreover, the generated images of our proposed model have the highest quality and are more pleasing to human eyes.
#PraCegoVer: A Large Dataset for Image Captioning in Portuguese
Mar 21, 2021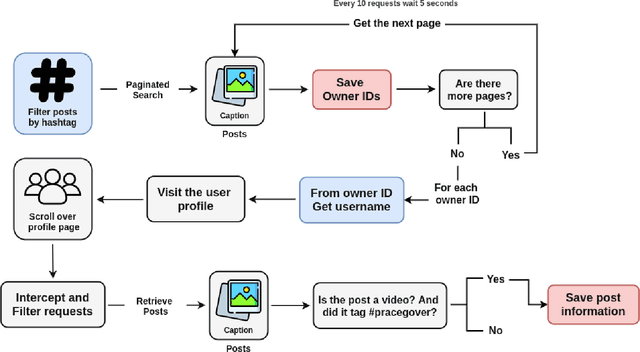


Automatically describing images using natural sentences is an important task to support visually impaired people's inclusion onto the Internet. It is still a big challenge that requires understanding the relation of the objects present in the image and their attributes and actions they are involved in. Then, visual interpretation methods are needed, but linguistic models are also necessary to verbally describe the semantic relations. This problem is known as Image Captioning. Although many datasets were proposed in the literature, the majority contains only English captions, whereas datasets with captions described in other languages are scarce. Recently, a movement called PraCegoVer arose on the Internet, stimulating users from social media to publish images, tag #PraCegoVer and add a short description of their content. Thus, inspired by this movement, we have proposed the #PraCegoVer, a multi-modal dataset with Portuguese captions based on posts from Instagram. It is the first large dataset for image captioning in Portuguese with freely annotated images. Further, the captions in our dataset bring additional challenges to the problem: first, in contrast to popular datasets such as MS COCO Captions, #PraCegoVer has only one reference to each image; also, both mean and variance of our reference sentence length are significantly greater than those in the MS COCO Captions. These two characteristics contribute to making our dataset interesting due to the linguistic aspect and the challenges that it introduces to the image captioning problem. We publicly-share the dataset at https://github.com/gabrielsantosrv/PraCegoVer.
Labeled Data Generation with Inexact Supervision
Jun 08, 2021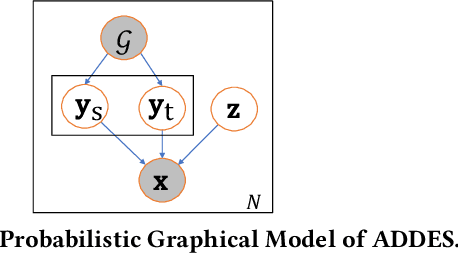
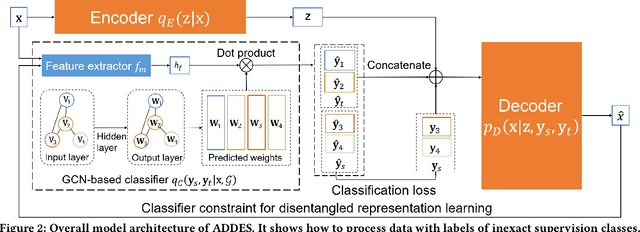
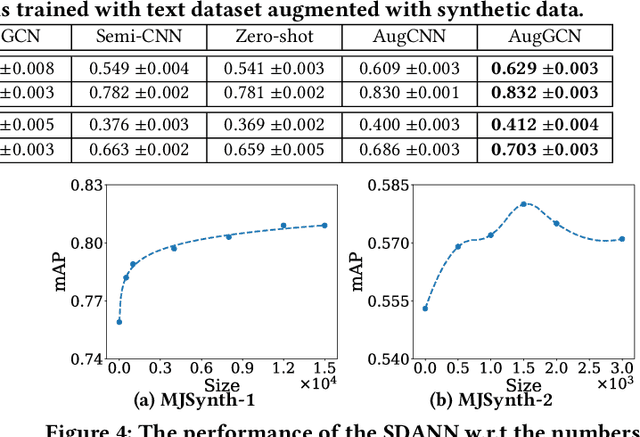
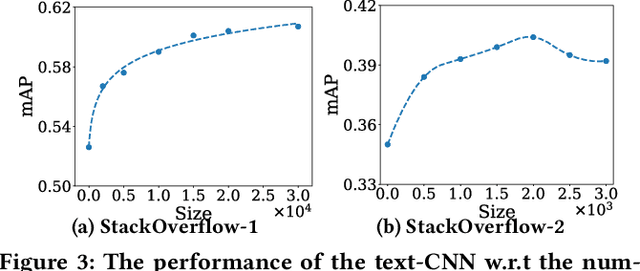
The recent advanced deep learning techniques have shown the promising results in various domains such as computer vision and natural language processing. The success of deep neural networks in supervised learning heavily relies on a large amount of labeled data. However, obtaining labeled data with target labels is often challenging due to various reasons such as cost of labeling and privacy issues, which challenges existing deep models. In spite of that, it is relatively easy to obtain data with \textit{inexact supervision}, i.e., having labels/tags related to the target task. For example, social media platforms are overwhelmed with billions of posts and images with self-customized tags, which are not the exact labels for target classification tasks but are usually related to the target labels. It is promising to leverage these tags (inexact supervision) and their relations with target classes to generate labeled data to facilitate the downstream classification tasks. However, the work on this is rather limited. Therefore, we study a novel problem of labeled data generation with inexact supervision. We propose a novel generative framework named as ADDES which can synthesize high-quality labeled data for target classification tasks by learning from data with inexact supervision and the relations between inexact supervision and target classes. Experimental results on image and text datasets demonstrate the effectiveness of the proposed ADDES for generating realistic labeled data from inexact supervision to facilitate the target classification task.
ExpertNet: Adversarial Learning and Recovery Against Noisy Labels
Jul 13, 2020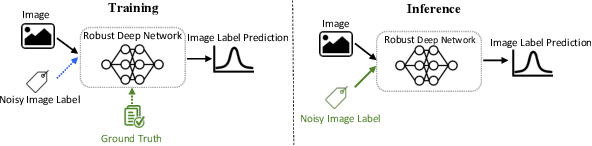
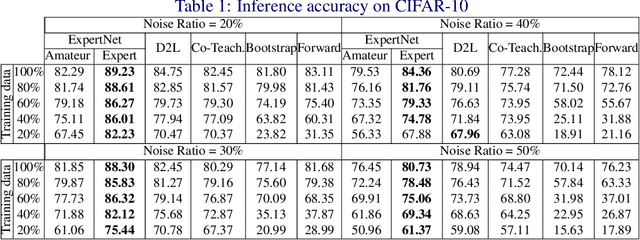
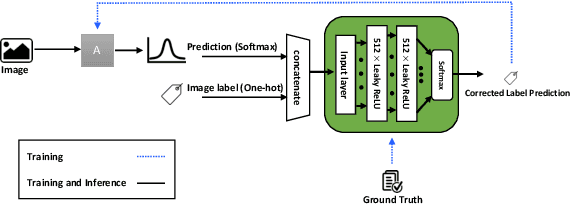
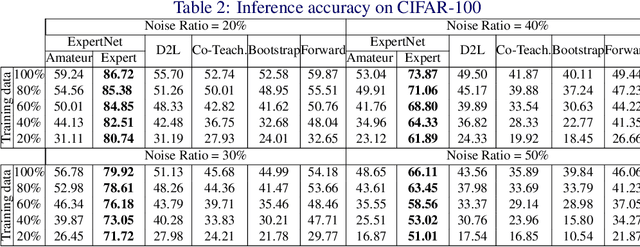
Today's available datasets in the wild, e.g., from social media and open platforms, present tremendous opportunities and challenges for deep learning, as there is a significant portion of tagged images, but often with noisy, i.e. erroneous, labels. Recent studies improve the robustness of deep models against noisy labels without the knowledge of true labels. In this paper, we advocate to derive a stronger classifier which proactively makes use of the noisy labels in addition to the original images - turning noisy labels into learning features. To such an end, we propose a novel framework, ExpertNet, composed of Amateur and Expert, which iteratively learn from each other. Amateur is a regular image classifier trained by the feedback of Expert, which imitates how human experts would correct the predicted labels from Amateur using the noise pattern learnt from the knowledge of both the noisy and ground truth labels. The trained Amateur and Expert proactively leverage the images and their noisy labels to infer image classes. Our empirical evaluations on noisy versions of CIFAR-10, CIFAR-100 and real-world data of Clothing1M show that the proposed model can achieve robust classification against a wide range of noise ratios and with as little as 20-50% training data, compared to state-of-the-art deep models that solely focus on distilling the impact of noisy labels.
Threat of Adversarial Attacks on Face Recognition: A Comprehensive Survey
Jul 22, 2020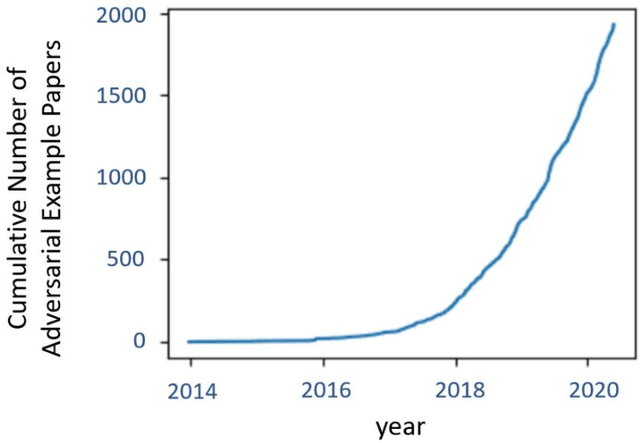
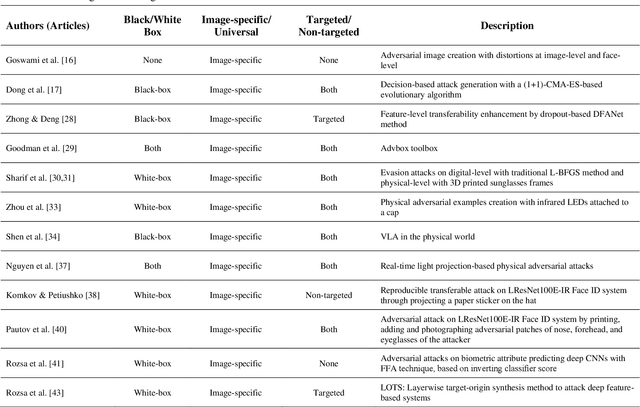

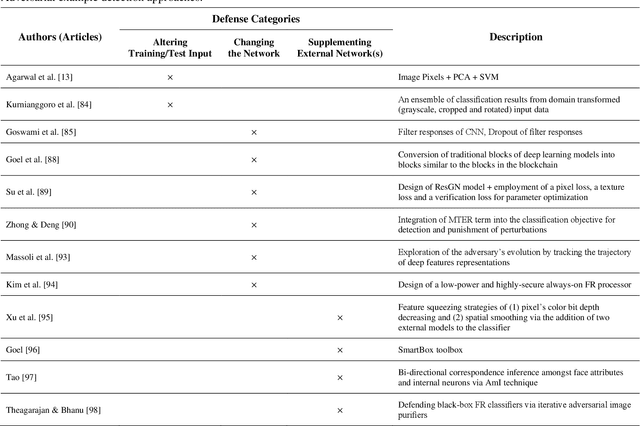
Face recognition (FR) systems have demonstrated outstanding verification performance, suggesting suitability for real-world applications, ranging from photo tagging in social media to automated border control (ABC). In an advanced FR system with deep learning-based architecture, however, promoting the recognition efficiency alone is not sufficient and the system should also withstand potential kinds of attacks designed to target its proficiency. Recent studies show that (deep) FR systems exhibit an intriguing vulnerability to imperceptible or perceptible but natural-looking adversarial input images that drive the model to incorrect output predictions. In this article, we present a comprehensive survey on adversarial attacks against FR systems and elaborate on the competence of new countermeasures against them. Further, we propose a taxonomy of existing attack and defense strategies according to different criteria. Finally, we compare the presented approaches according to techniques' characteristics.
Modeling Food Popularity Dependencies using Social Media data
Jun 26, 2019The rise in popularity of major social media platforms have enabled people to share photos and textual information about their daily life. One of the popular topics about which information is shared is food. Since a lot of media about food are attributed to particular locations and restaurants, information like popularity of spatio-temporal popularity of various cuisines can be analysed. Tracking the popularity of food types and retail locations across space and time can also be useful for business owners and restaurant investors. In this work, we present an approach using off-the shelf machine learning techniques to identify trends and popularity of cuisine types in an area using geo-tagged data from social media, Google images and Yelp. After adjusting for time, we use the Kernel Density Estimation to get hot spots across the location and model the dependencies among food cuisines popularity using Bayesian Networks. We consider the Manhattan borough of New York City as the location for our analyses but the approach can be used for any area with social media data and information about retail businesses.
VISIR: Visual and Semantic Image Label Refinement
Sep 02, 2019

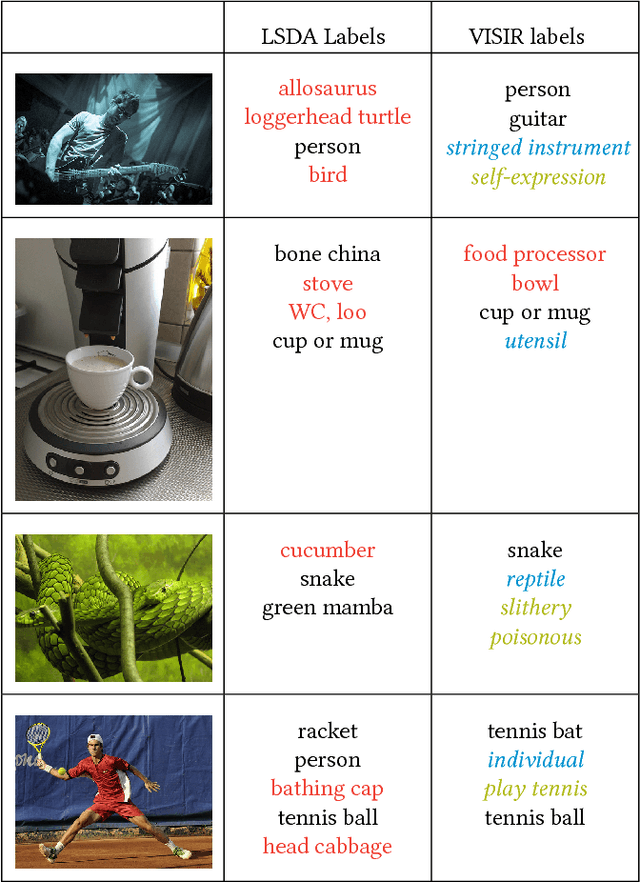
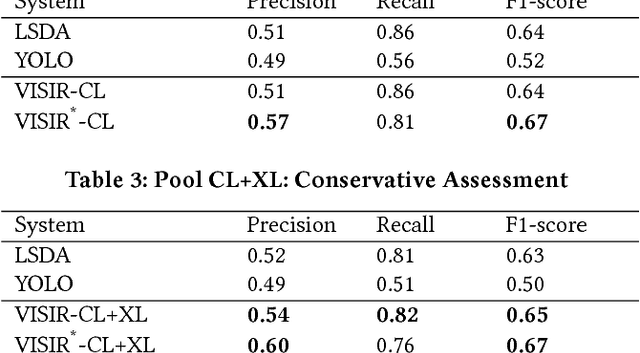
The social media explosion has populated the Internet with a wealth of images. There are two existing paradigms for image retrieval: 1) content-based image retrieval (CBIR), which has traditionally used visual features for similarity search (e.g., SIFT features), and 2) tag-based image retrieval (TBIR), which has relied on user tagging (e.g., Flickr tags). CBIR now gains semantic expressiveness by advances in deep-learning-based detection of visual labels. TBIR benefits from query-and-click logs to automatically infer more informative labels. However, learning-based tagging still yields noisy labels and is restricted to concrete objects, missing out on generalizations and abstractions. Click-based tagging is limited to terms that appear in the textual context of an image or in queries that lead to a click. This paper addresses the above limitations by semantically refining and expanding the labels suggested by learning-based object detection. We consider the semantic coherence between the labels for different objects, leverage lexical and commonsense knowledge, and cast the label assignment into a constrained optimization problem solved by an integer linear program. Experiments show that our method, called VISIR, improves the quality of the state-of-the-art visual labeling tools like LSDA and YOLO.
* Published in WSDM 2018