 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeople Snapshot Dataset
Papers and Code
SplatArmor: Articulated Gaussian splatting for animatable humans from monocular RGB videos
Nov 17, 2023



We propose SplatArmor, a novel approach for recovering detailed and animatable human models by `armoring' a parameterized body model with 3D Gaussians. Our approach represents the human as a set of 3D Gaussians within a canonical space, whose articulation is defined by extending the skinning of the underlying SMPL geometry to arbitrary locations in the canonical space. To account for pose-dependent effects, we introduce a SE(3) field, which allows us to capture both the location and anisotropy of the Gaussians. Furthermore, we propose the use of a neural color field to provide color regularization and 3D supervision for the precise positioning of these Gaussians. We show that Gaussian splatting provides an interesting alternative to neural rendering based methods by leverging a rasterization primitive without facing any of the non-differentiability and optimization challenges typically faced in such approaches. The rasterization paradigms allows us to leverage forward skinning, and does not suffer from the ambiguities associated with inverse skinning and warping. We show compelling results on the ZJU MoCap and People Snapshot datasets, which underscore the effectiveness of our method for controllable human synthesis.
GHuNeRF: Generalizable Human NeRF from a Monocular Video
Sep 03, 2023



In this paper, we tackle the challenging task of learning a generalizable human NeRF model from a monocular video. Although existing generalizable human NeRFs have achieved impressive results, they require muti-view images or videos which might not be always available. On the other hand, some works on free-viewpoint rendering of human from monocular videos cannot be generalized to unseen identities. In view of these limitations, we propose GHuNeRF to learn a generalizable human NeRF model from a monocular video of the human performer. We first introduce a visibility-aware aggregation scheme to compute vertex-wise features, which is used to construct a 3D feature volume. The feature volume can only represent the overall geometry of the human performer with insufficient accuracy due to the limited resolution. To solve this, we further enhance the volume feature with temporally aligned point-wise features using an attention mechanism. Finally, the enhanced feature is used for predicting density and color for each sampled point. A surface-guided sampling strategy is also introduced to improve the efficiency for both training and inference. We validate our approach on the widely-used ZJU-MoCap dataset, where we achieve comparable performance with existing multi-view video based approaches. We also test on the monocular People-Snapshot dataset and achieve better performance than existing works when only monocular video is used.
Neural Body: Implicit Neural Representations with Structured Latent Codes for Novel View Synthesis of Dynamic Humans
Dec 31, 2020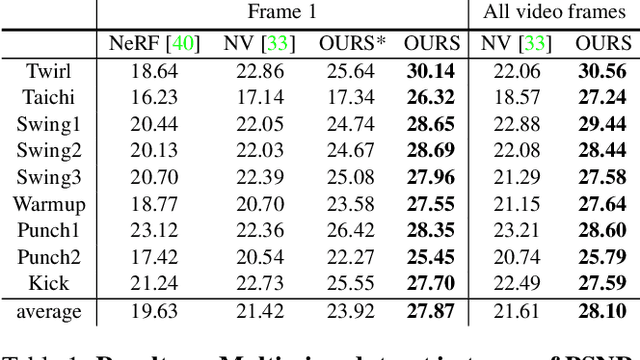
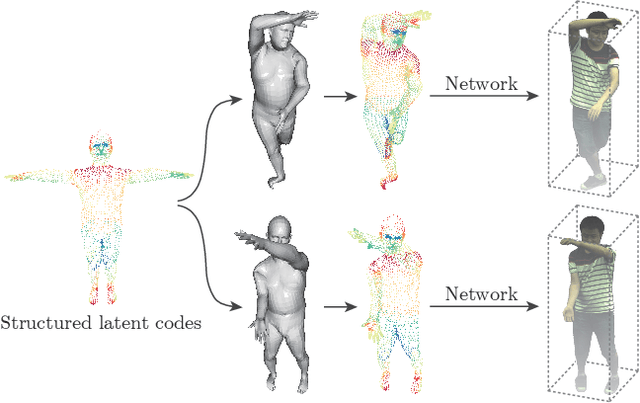
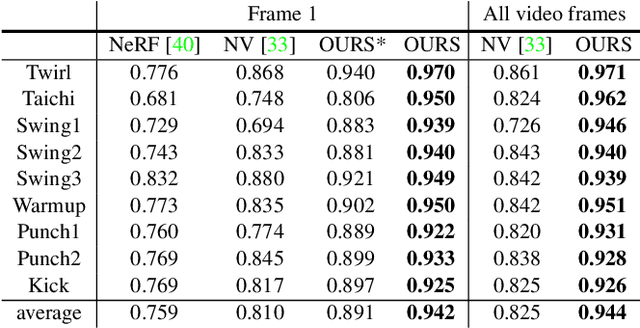
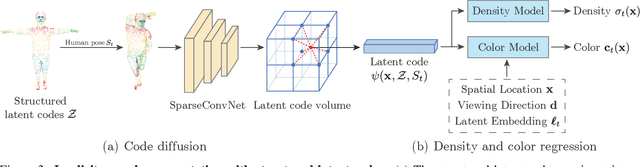
This paper addresses the challenge of novel view synthesis for a human performer from a very sparse set of camera views. Some recent works have shown that learning implicit neural representations of 3D scenes achieves remarkable view synthesis quality given dense input views. However, the representation learning will be ill-posed if the views are highly sparse. To solve this ill-posed problem, our key idea is to integrate observations over video frames. To this end, we propose Neural Body, a new human body representation which assumes that the learned neural representations at different frames share the same set of latent codes anchored to a deformable mesh, so that the observations across frames can be naturally integrated. The deformable mesh also provides geometric guidance for the network to learn 3D representations more efficiently. Experiments on a newly collected multi-view dataset show that our approach outperforms prior works by a large margin in terms of the view synthesis quality. We also demonstrate the capability of our approach to reconstruct a moving person from a monocular video on the People-Snapshot dataset. The code and dataset will be available at https://zju3dv.github.io/neuralbody/.