 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOral Cancer Classification
Papers and Code
Multimodal RGB-HSI Feature Fusion with Patient-Aware Incremental Heuristic Meta-Learning for Oral Lesion Classification
Nov 15, 2025


Early detection of oral cancer and potentially malignant disorders is challenging in low-resource settings due to limited annotated data. We present a unified four-class oral lesion classifier that integrates deep RGB embeddings, hyperspectral reconstruction, handcrafted spectral-textural descriptors, and demographic metadata. A pathologist-verified subset of oral cavity images was curated and processed using a fine-tuned ConvNeXt-v2 encoder, followed by RGB-to-HSI reconstruction into 31-band hyperspectral cubes. Haemoglobin-sensitive indices, texture features, and spectral-shape measures were extracted and fused with deep and clinical features. Multiple machine-learning models were assessed with patient-wise validation. We further introduce an incremental heuristic meta-learner (IHML) that combines calibrated base classifiers through probabilistic stacking and patient-level posterior smoothing. On an unseen patient split, the proposed framework achieved a macro F1 of 66.23% and an accuracy of 64.56%. Results demonstrate that hyperspectral reconstruction and uncertainty-aware meta-learning substantially improve robustness for real-world oral lesion screening.
Robust Classification of Oral Cancer with Limited Training Data
Oct 02, 2025Oral cancer ranks among the most prevalent cancers globally, with a particularly high mortality rate in regions lacking adequate healthcare access. Early diagnosis is crucial for reducing mortality; however, challenges persist due to limited oral health programs, inadequate infrastructure, and a shortage of healthcare practitioners. Conventional deep learning models, while promising, often rely on point estimates, leading to overconfidence and reduced reliability. Critically, these models require large datasets to mitigate overfitting and ensure generalizability, an unrealistic demand in settings with limited training data. To address these issues, we propose a hybrid model that combines a convolutional neural network (CNN) with Bayesian deep learning for oral cancer classification using small training sets. This approach employs variational inference to enhance reliability through uncertainty quantification. The model was trained on photographic color images captured by smartphones and evaluated on three distinct test datasets. The proposed method achieved 94% accuracy on a test dataset with a distribution similar to that of the training data, comparable to traditional CNN performance. Notably, for real-world photographic image data, despite limitations and variations differing from the training dataset, the proposed model demonstrated superior generalizability, achieving 88% accuracy on diverse datasets compared to 72.94% for traditional CNNs, even with a smaller dataset. Confidence analysis revealed that the model exhibits low uncertainty (high confidence) for correctly classified samples and high uncertainty (low confidence) for misclassified samples. These results underscore the effectiveness of Bayesian inference in data-scarce environments in enhancing early oral cancer diagnosis by improving model reliability and generalizability.
Improving Diagnostic Accuracy for Oral Cancer with inpainting Synthesis Lesions Generated Using Diffusion Models
Aug 08, 2025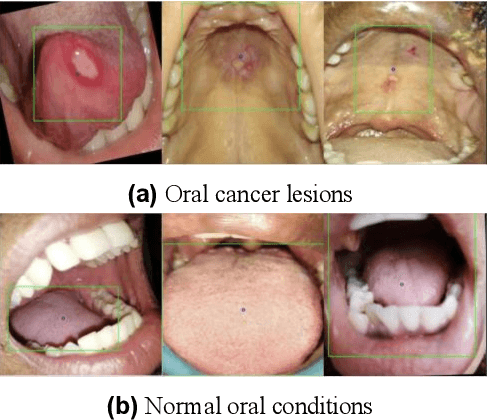
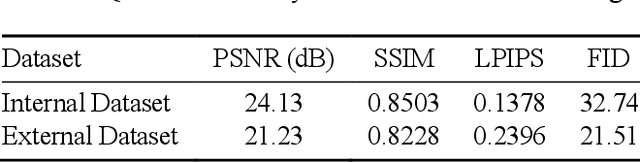
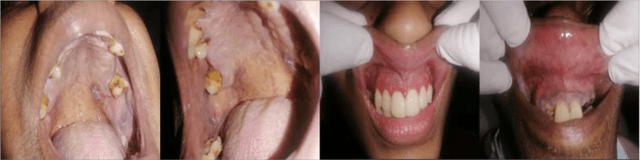
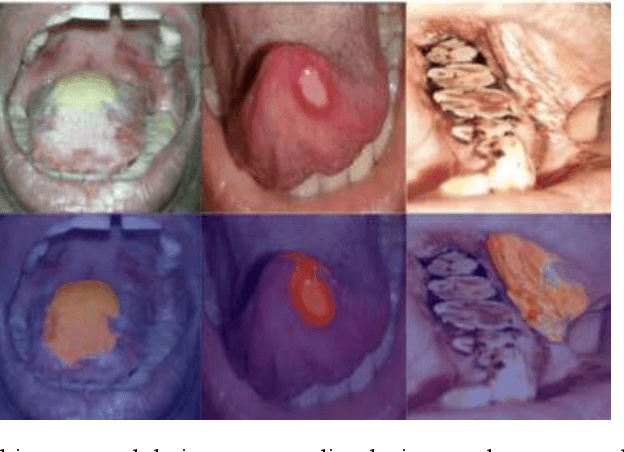
In oral cancer diagnostics, the limited availability of annotated datasets frequently constrains the performance of diagnostic models, particularly due to the variability and insufficiency of training data. To address these challenges, this study proposed a novel approach to enhance diagnostic accuracy by synthesizing realistic oral cancer lesions using an inpainting technique with a fine-tuned diffusion model. We compiled a comprehensive dataset from multiple sources, featuring a variety of oral cancer images. Our method generated synthetic lesions that exhibit a high degree of visual fidelity to actual lesions, thereby significantly enhancing the performance of diagnostic algorithms. The results show that our classification model achieved a diagnostic accuracy of 0.97 in differentiating between cancerous and non-cancerous tissues, while our detection model accurately identified lesion locations with 0.85 accuracy. This method validates the potential for synthetic image generation in medical diagnostics and paves the way for further research into extending these methods to other types of cancer diagnostics.
Improving Oral Cancer Outcomes Through Machine Learning and Dimensionality Reduction
Jun 11, 2025Oral cancer presents a formidable challenge in oncology, necessitating early diagnosis and accurate prognosis to enhance patient survival rates. Recent advancements in machine learning and data mining have revolutionized traditional diagnostic methodologies, providing sophisticated and automated tools for differentiating between benign and malignant oral lesions. This study presents a comprehensive review of cutting-edge data mining methodologies, including Neural Networks, K-Nearest Neighbors (KNN), Support Vector Machines (SVM), and ensemble learning techniques, specifically applied to the diagnosis and prognosis of oral cancer. Through a rigorous comparative analysis, our findings reveal that Neural Networks surpass other models, achieving an impressive classification accuracy of 93,6 % in predicting oral cancer. Furthermore, we underscore the potential benefits of integrating feature selection and dimensionality reduction techniques to enhance model performance. These insights underscore the significant promise of advanced data mining techniques in bolstering early detection, optimizing treatment strategies, and ultimately improving patient outcomes in the realm of oral oncology.
Devising a solution to the problems of Cancer awareness in Telangana
Jun 26, 2025According to the data, the percent of women who underwent screening for cervical cancer, breast and oral cancer in Telangana in the year 2020 was 3.3 percent, 0.3 percent and 2.3 percent respectively. Although early detection is the only way to reduce morbidity and mortality, people have very low awareness about cervical and breast cancer signs and symptoms and screening practices. We developed an ML classification model to predict if a person is susceptible to breast or cervical cancer based on demographic factors. We devised a system to provide suggestions for the nearest hospital or Cancer treatment centres based on the users location or address. In addition to this, we can integrate the health card to maintain medical records of all individuals and conduct awareness drives and campaigns. For ML classification models, we used decision tree classification and support vector classification algorithms for cervical cancer susceptibility and breast cancer susceptibility respectively. Thus, by devising this solution we come one step closer to our goal which is spreading cancer awareness, thereby, decreasing the cancer mortality and increasing cancer literacy among the people of Telangana.
A Cytology Dataset for Early Detection of Oral Squamous Cell Carcinoma
Jun 11, 2025Oral squamous cell carcinoma OSCC is a major global health burden, particularly in several regions across Asia, Africa, and South America, where it accounts for a significant proportion of cancer cases. Early detection dramatically improves outcomes, with stage I cancers achieving up to 90 percent survival. However, traditional diagnosis based on histopathology has limited accessibility in low-resource settings because it is invasive, resource-intensive, and reliant on expert pathologists. On the other hand, oral cytology of brush biopsy offers a minimally invasive and lower cost alternative, provided that the remaining challenges, inter observer variability and unavailability of expert pathologists can be addressed using artificial intelligence. Development and validation of robust AI solutions requires access to large, labeled, and multi-source datasets to train high capacity models that generalize across domain shifts. We introduce the first large and multicenter oral cytology dataset, comprising annotated slides stained with Papanicolaou(PAP) and May-Grunwald-Giemsa(MGG) protocols, collected from ten tertiary medical centers in India. The dataset is labeled and annotated by expert pathologists for cellular anomaly classification and detection, is designed to advance AI driven diagnostic methods. By filling the gap in publicly available oral cytology datasets, this resource aims to enhance automated detection, reduce diagnostic errors, and improve early OSCC diagnosis in resource-constrained settings, ultimately contributing to reduced mortality and better patient outcomes worldwide.
A Novel Approach using CapsNet and Deep Belief Network for Detection and Identification of Oral Leukopenia
Jan 01, 2025


Oral cancer constitutes a significant global health concern, resulting in 277,484 fatalities in 2023, with the highest prevalence observed in low- and middle-income nations. Facilitating automation in the detection of possibly malignant and malignant lesions in the oral cavity could result in cost-effective and early disease diagnosis. Establishing an extensive repository of meticulously annotated oral lesions is essential. In this research photos are being collected from global clinical experts, who have been equipped with an annotation tool to generate comprehensive labelling. This research presents a novel approach for integrating bounding box annotations from various doctors. Additionally, Deep Belief Network combined with CAPSNET is employed to develop automated systems that extracted intricate patterns to address this challenging problem. This study evaluated two deep learning-based computer vision methodologies for the automated detection and classification of oral lesions to facilitate the early detection of oral cancer: image classification utilizing CAPSNET. Image classification attained an F1 score of 94.23% for detecting photos with lesions 93.46% for identifying images necessitating referral. Object detection attained an F1 score of 89.34% for identifying lesions for referral. Subsequent performances are documented about classification based on the sort of referral decision. Our preliminary findings indicate that deep learning possesses the capability to address this complex problem.
Oral squamous cell detection using deep learning
Aug 16, 2024



Oral squamous cell carcinoma (OSCC) represents a significant global health concern, with increasing incidence rates and challenges in early diagnosis and treatment planning. Early detection is crucial for improving patient outcomes and survival rates. Deep learning, a subset of machine learning, has shown remarkable progress in extracting and analyzing crucial information from medical imaging data.EfficientNetB3, an advanced convolutional neural network architecture, has emerged as a leading model for image classification tasks, including medical imaging. Its superior performance, characterized by high accuracy, precision, and recall, makes it particularly promising for OSCC detection and diagnosis. EfficientNetB3 achieved an accuracy of 0.9833, precision of 0.9782, and recall of 0.9782 in our analysis. By leveraging EfficientNetB3 and other deep learning technologies, clinicians can potentially improve the accuracy and efficiency of OSCC diagnosis, leading to more timely interventions and better patient outcomes. This article also discusses the role of deep learning in advancing precision medicine for OSCC and provides insights into prospects and challenges in leveraging this technology for enhanced cancer care.
Let it shine: Autofluorescence of Papanicolaou-stain improves AI-based cytological oral cancer detection
Jul 02, 2024



Oral cancer is a global health challenge. It is treatable if detected early, but it is often fatal in late stages. There is a shift from the invasive and time-consuming tissue sampling and histological examination, toward non-invasive brush biopsies and cytological examination. Reliable computer-assisted methods are essential for cost-effective and accurate cytological analysis, but the lack of detailed cell-level annotations impairs model effectiveness. This study aims to improve AI-based oral cancer detection using multimodal imaging and deep fusion. We combine brightfield and fluorescence whole slide microscopy imaging to analyze Papanicolaou-stained liquid-based cytology slides of brush biopsies collected from both healthy and cancer patients. Due to limited cytological annotations, we utilize a weakly supervised deep learning approach using only patient-level labels. We evaluate various multimodal fusion strategies, including early, late, and three recent intermediate fusion methods. Our results show: (i) fluorescence imaging of Papanicolaou-stained samples provides substantial diagnostic information; (ii) multimodal fusion enhances classification and cancer detection accuracy over single-modality methods. Intermediate fusion is the leading method among the studied approaches. Specifically, the Co-Attention Fusion Network (CAFNet) model excels with an F1 score of 83.34% and accuracy of 91.79%, surpassing human performance on the task. Additional tests highlight the need for precise image registration to optimize multimodal analysis benefits. This study advances cytopathology by combining deep learning and multimodal imaging to enhance early, non-invasive detection of oral cancer, improving diagnostic accuracy and streamlining clinical workflows. The developed pipeline is also applicable in other cytological settings. Our codes and dataset are available online for further research.
Deep Learning for Size and Microscope Feature Extraction and Classification in Oral Cancer: Enhanced Convolution Neural Network
Aug 06, 2022Background and Aim: Over-fitting issue has been the reason behind deep learning technology not being successfully implemented in oral cancer images classification. The aims of this research were reducing overfitting for accurately producing the required dimension reduction feature map through Deep Learning algorithm using Convolutional Neural Network. Methodology: The proposed system consists of Enhanced Convolutional Neural Network that uses an autoencoder technique to increase the efficiency of the feature extraction process and compresses information. In this technique, unpooling and deconvolution is done to generate the input data to minimize the difference between input and output data. Moreover, it extracts characteristic features from the input data set to regenerate input data from those features by learning a network to reduce overfitting. Results: Different accuracy and processing time value is achieved while using different sample image group of Confocal Laser Endomicroscopy (CLE) images. The results showed that the proposed solution is better than the current system. Moreover, the proposed system has improved the classification accuracy by 5~ 5.5% on average and reduced the average processing time by 20 ~ 30 milliseconds. Conclusion: The proposed system focuses on the accurate classification of oral cancer cells of different anatomical locations from the CLE images. Finally, this study enhances the accuracy and processing time using the autoencoder method that solves the overfitting problem.
* 21 pages