 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMvit
Papers and Code
Cross-View Cross-Modal Unsupervised Domain Adaptation for Driver Monitoring System
Nov 15, 2025


Driver distraction remains a leading cause of road traffic accidents, contributing to thousands of fatalities annually across the globe. While deep learning-based driver activity recognition methods have shown promise in detecting such distractions, their effectiveness in real-world deployments is hindered by two critical challenges: variations in camera viewpoints (cross-view) and domain shifts such as change in sensor modality or environment. Existing methods typically address either cross-view generalization or unsupervised domain adaptation in isolation, leaving a gap in the robust and scalable deployment of models across diverse vehicle configurations. In this work, we propose a novel two-phase cross-view, cross-modal unsupervised domain adaptation framework that addresses these challenges jointly on real-time driver monitoring data. In the first phase, we learn view-invariant and action-discriminative features within a single modality using contrastive learning on multi-view data. In the second phase, we perform domain adaptation to a new modality using information bottleneck loss without requiring any labeled data from the new domain. We evaluate our approach using state-of-the art video transformers (Video Swin, MViT) and multi modal driver activity dataset called Drive&Act, demonstrating that our joint framework improves top-1 accuracy on RGB video data by almost 50% compared to a supervised contrastive learning-based cross-view method, and outperforms unsupervised domain adaptation-only methods by up to 5%, using the same video transformer backbone.
Domain Generalization for Improved Human Activity Recognition in Office Space Videos Using Adaptive Pre-processing
Mar 16, 2025



Automatic video activity recognition is crucial across numerous domains like surveillance, healthcare, and robotics. However, recognizing human activities from video data becomes challenging when training and test data stem from diverse domains. Domain generalization, adapting to unforeseen domains, is thus essential. This paper focuses on office activity recognition amidst environmental variability. We propose three pre-processing techniques applicable to any video encoder, enhancing robustness against environmental variations. Our study showcases the efficacy of MViT, a leading state-of-the-art video classification model, and other video encoders combined with our techniques, outperforming state-of-the-art domain adaptation methods. Our approach significantly boosts accuracy, precision, recall and F1 score on unseen domains, emphasizing its adaptability in real-world scenarios with diverse video data sources. This method lays a foundation for more reliable video activity recognition systems across heterogeneous data domains.
Multi-Class Abnormality Classification Task in Video Capsule Endoscopy
Oct 25, 2024


In this work we addressed the challenge of multi-class anomaly classification in Video Capsule Endoscopy (VCE)[1] with a variety of deep learning models, ranging from custom CNNs to advanced transformer architectures. The purpose is to correctly classify diverse gastrointestinal disorders, which is critical for increasing diagnostic efficiency in clinical settings. We started with a proprietary CNN and improved performance with ResNet[7] for better feature extraction, followed by Vision Transformer (ViT)[2] to capture global dependencies. Multiscale Vision Transformer (MViT)[6] improved hierarchical feature extraction, while Dual Attention Vision Transformer (DaViT)[4] delivered cutting-edge results by combining spatial and channel attention methods. This methodology enabled us to improve model accuracy across a wide range of criteria, greatly surpassing older methods.
Use of a Multiscale Vision Transformer to predict Nursing Activities Score from Low Resolution Thermal Videos in an Intensive Care Unit
May 30, 2024


Excessive caregiver workload in hospital nurses has been implicated in poorer patient care and increased worker burnout. Measurement of this workload in the Intensive Care Unit (ICU) is often done using the Nursing Activities Score (NAS), but this is usually recorded manually and sporadically. Previous work has made use of Ambient Intelligence (AmI) by using computer vision to passively derive caregiver-patient interaction times to monitor staff workload. In this letter, we propose using a Multiscale Vision Transformer (MViT) to passively predict the NAS from low-resolution thermal videos recorded in an ICU. 458 videos were obtained from an ICU in Melbourne, Australia and used to train a MViTv2 model using an indirect prediction and a direct prediction method. The indirect method predicted 1 of 8 potentially identifiable NAS activities from the video before inferring the NAS. The direct method predicted the NAS score immediately from the video. The indirect method yielded an average 5-fold accuracy of 57.21%, an area under the receiver operating characteristic curve (ROC AUC) of 0.865, a F1 score of 0.570 and a mean squared error (MSE) of 28.16. The direct method yielded a MSE of 18.16. We also showed that the MViTv2 outperforms similar models such as R(2+1)D and ResNet50-LSTM under identical settings. This study shows the feasibility of using a MViTv2 to passively predict the NAS in an ICU and monitor staff workload automatically. Our results above also show an increased accuracy in predicting NAS directly versus predicting NAS indirectly. We hope that our study can provide a direction for future work and further improve the accuracy of passive NAS monitoring.
Multiscale Vision Transformers meet Bipartite Matching for efficient single-stage Action Localization
Dec 29, 2023



Action Localization is a challenging problem that combines detection and recognition tasks, which are often addressed separately. State-of-the-art methods rely on off-the-shelf bounding box detections pre-computed at high resolution and propose transformer models that focus on the classification task alone. Such two-stage solutions are prohibitive for real-time deployment. On the other hand, single-stage methods target both tasks by devoting part of the network (generally the backbone) to sharing the majority of the workload, compromising performance for speed. These methods build on adding a DETR head with learnable queries that, after cross- and self-attention can be sent to corresponding MLPs for detecting a person's bounding box and action. However, DETR-like architectures are challenging to train and can incur in big complexity. In this paper, we observe that a straight bipartite matching loss can be applied to the output tokens of a vision transformer. This results in a backbone + MLP architecture that can do both tasks without the need of an extra encoder-decoder head and learnable queries. We show that a single MViT-S architecture trained with bipartite matching to perform both tasks surpasses the same MViT-S when trained with RoI align on pre-computed bounding boxes. With a careful design of token pooling and the proposed training pipeline, our MViTv2-S model achieves +3 mAP on AVA2.2. w.r.t. the two-stage counterpart. Code and models will be released after paper revision.
ROI-Aware Multiscale Cross-Attention Vision Transformer for Pest Image Identification
Dec 28, 2023The pests captured with imaging devices may be relatively small in size compared to the entire images, and complex backgrounds have colors and textures similar to those of the pests, which hinders accurate feature extraction and makes pest identification challenging. The key to pest identification is to create a model capable of detecting regions of interest (ROIs) and transforming them into better ones for attention and discriminative learning. To address these problems, we will study how to generate and update the ROIs via multiscale cross-attention fusion as well as how to be highly robust to complex backgrounds and scale problems. Therefore, we propose a novel ROI-aware multiscale cross-attention vision transformer (ROI-ViT). The proposed ROI-ViT is designed using dual branches, called Pest and ROI branches, which take different types of maps as input: Pest images and ROI maps. To render such ROI maps, ROI generators are built using soft segmentation and a class activation map and then integrated into the ROI-ViT backbone. Additionally, in the dual branch, complementary feature fusion and multiscale hierarchies are implemented via a novel multiscale cross-attention fusion. The class token from the Pest branch is exchanged with the patch tokens from the ROI branch, and vice versa. The experimental results show that the proposed ROI-ViT achieves 81.81%, 99.64%, and 84.66% for IP102, D0, and SauTeg pest datasets, respectively, outperforming state-of-the-art (SOTA) models, such as MViT, PVT, DeiT, Swin-ViT, and EfficientNet. More importantly, for the new challenging dataset IP102(CBSS) that contains only pest images with complex backgrounds and small sizes, the proposed model can maintain high recognition accuracy, whereas that of other SOTA models decrease sharply, demonstrating that our model is more robust to complex background and scale problems.
Distilling Knowledge from CNN-Transformer Models for Enhanced Human Action Recognition
Nov 02, 2023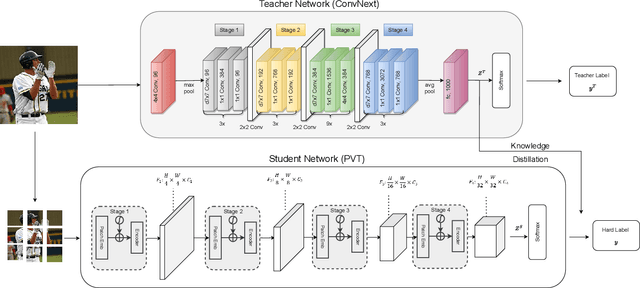
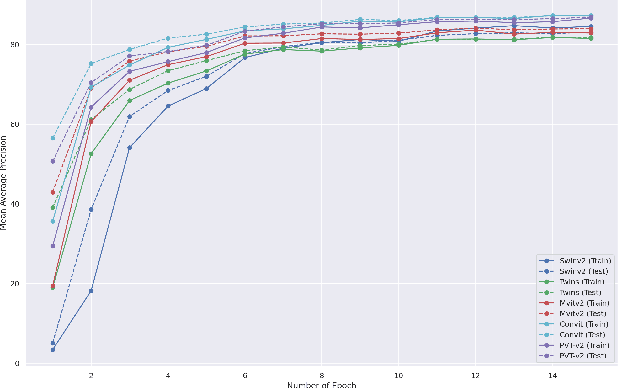
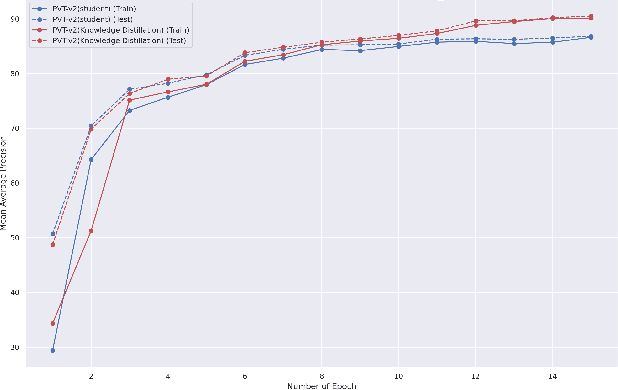
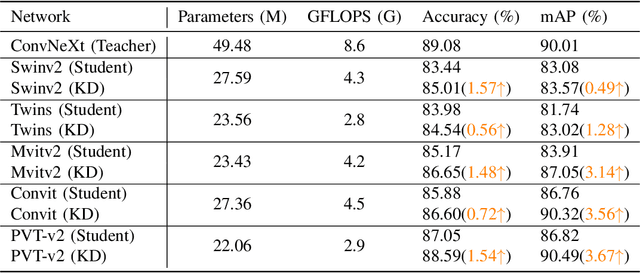
This paper presents a study on improving human action recognition through the utilization of knowledge distillation, and the combination of CNN and ViT models. The research aims to enhance the performance and efficiency of smaller student models by transferring knowledge from larger teacher models. The proposed method employs a Transformer vision network as the student model, while a convolutional network serves as the teacher model. The teacher model extracts local image features, whereas the student model focuses on global features using an attention mechanism. The Vision Transformer (ViT) architecture is introduced as a robust framework for capturing global dependencies in images. Additionally, advanced variants of ViT, namely PVT, Convit, MVIT, Swin Transformer, and Twins, are discussed, highlighting their contributions to computer vision tasks. The ConvNeXt model is introduced as a teacher model, known for its efficiency and effectiveness in computer vision. The paper presents performance results for human action recognition on the Stanford 40 dataset, comparing the accuracy and mAP of student models trained with and without knowledge distillation. The findings illustrate that the suggested approach significantly improves the accuracy and mAP when compared to training networks under regular settings. These findings emphasize the potential of combining local and global features in action recognition tasks.
Study of Vision Transformers for Covid-19 Detection from Chest X-rays
Jul 17, 2023The COVID-19 pandemic has led to a global health crisis, highlighting the need for rapid and accurate virus detection. This research paper examines transfer learning with vision transformers for COVID-19 detection, known for its excellent performance in image recognition tasks. We leverage the capability of Vision Transformers to capture global context and learn complex patterns from chest X-ray images. In this work, we explored the recent state-of-art transformer models to detect Covid-19 using CXR images such as vision transformer (ViT), Swin-transformer, Max vision transformer (MViT), and Pyramid Vision transformer (PVT). Through the utilization of transfer learning with IMAGENET weights, the models achieved an impressive accuracy range of 98.75% to 99.5%. Our experiments demonstrate that Vision Transformers achieve state-of-the-art performance in COVID-19 detection, outperforming traditional methods and even Convolutional Neural Networks (CNNs). The results highlight the potential of Vision Transformers as a powerful tool for COVID-19 detection, with implications for improving the efficiency and accuracy of screening and diagnosis in clinical settings.
Origin-Destination Travel Time Oracle for Map-based Services
Jul 06, 2023



Given an origin (O), a destination (D), and a departure time (T), an Origin-Destination (OD) travel time oracle~(ODT-Oracle) returns an estimate of the time it takes to travel from O to D when departing at T. ODT-Oracles serve important purposes in map-based services. To enable the construction of such oracles, we provide a travel-time estimation (TTE) solution that leverages historical trajectories to estimate time-varying travel times for OD pairs. The problem is complicated by the fact that multiple historical trajectories with different travel times may connect an OD pair, while trajectories may vary from one another. To solve the problem, it is crucial to remove outlier trajectories when doing travel time estimation for future queries. We propose a novel, two-stage framework called Diffusion-based Origin-destination Travel Time Estimation (DOT), that solves the problem. First, DOT employs a conditioned Pixelated Trajectories (PiT) denoiser that enables building a diffusion-based PiT inference process by learning correlations between OD pairs and historical trajectories. Specifically, given an OD pair and a departure time, we aim to infer a PiT. Next, DOT encompasses a Masked Vision Transformer~(MViT) that effectively and efficiently estimates a travel time based on the inferred PiT. We report on extensive experiments on two real-world datasets that offer evidence that DOT is capable of outperforming baseline methods in terms of accuracy, scalability, and explainability.
PaReprop: Fast Parallelized Reversible Backpropagation
Jun 15, 2023



The growing size of datasets and deep learning models has made faster and memory-efficient training crucial. Reversible transformers have recently been introduced as an exciting new method for extremely memory-efficient training, but they come with an additional computation overhead of activation re-computation in the backpropagation phase. We present PaReprop, a fast Parallelized Reversible Backpropagation algorithm that parallelizes the additional activation re-computation overhead in reversible training with the gradient computation itself in backpropagation phase. We demonstrate the effectiveness of the proposed PaReprop algorithm through extensive benchmarking across model families (ViT, MViT, Swin and RoBERTa), data modalities (Vision & NLP), model sizes (from small to giant), and training batch sizes. Our empirical results show that PaReprop achieves up to 20% higher training throughput than vanilla reversible training, largely mitigating the theoretical overhead of 25% lower throughput from activation recomputation in reversible training. Project page: https://tylerzhu.com/pareprop.