 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIkea Object State Dataset
Papers and Code
Simultaneous Detection and Interaction Reasoning for Object-Centric Action Recognition
Apr 18, 2024



The interactions between human and objects are important for recognizing object-centric actions. Existing methods usually adopt a two-stage pipeline, where object proposals are first detected using a pretrained detector, and then are fed to an action recognition model for extracting video features and learning the object relations for action recognition. However, since the action prior is unknown in the object detection stage, important objects could be easily overlooked, leading to inferior action recognition performance. In this paper, we propose an end-to-end object-centric action recognition framework that simultaneously performs Detection And Interaction Reasoning in one stage. Particularly, after extracting video features with a base network, we create three modules for concurrent object detection and interaction reasoning. First, a Patch-based Object Decoder generates proposals from video patch tokens. Then, an Interactive Object Refining and Aggregation identifies important objects for action recognition, adjusts proposal scores based on position and appearance, and aggregates object-level info into a global video representation. Lastly, an Object Relation Modeling module encodes object relations. These three modules together with the video feature extractor can be trained jointly in an end-to-end fashion, thus avoiding the heavy reliance on an off-the-shelf object detector, and reducing the multi-stage training burden. We conduct experiments on two datasets, Something-Else and Ikea-Assembly, to evaluate the performance of our proposed approach on conventional, compositional, and few-shot action recognition tasks. Through in-depth experimental analysis, we show the crucial role of interactive objects in learning for action recognition, and we can outperform state-of-the-art methods on both datasets.
How Object Information Improves Skeleton-based Human Action Recognition in Assembly Tasks
Jun 09, 2023As the use of collaborative robots (cobots) in industrial manufacturing continues to grow, human action recognition for effective human-robot collaboration becomes increasingly important. This ability is crucial for cobots to act autonomously and assist in assembly tasks. Recently, skeleton-based approaches are often used as they tend to generalize better to different people and environments. However, when processing skeletons alone, information about the objects a human interacts with is lost. Therefore, we present a novel approach of integrating object information into skeleton-based action recognition. We enhance two state-of-the-art methods by treating object centers as further skeleton joints. Our experiments on the assembly dataset IKEA ASM show that our approach improves the performance of these state-of-the-art methods to a large extent when combining skeleton joints with objects predicted by a state-of-the-art instance segmentation model. Our research sheds light on the benefits of combining skeleton joints with object information for human action recognition in assembly tasks. We analyze the effect of the object detector on the combination for action classification and discuss the important factors that must be taken into account.
IKEA Object State Dataset: A 6DoF object pose estimation dataset and benchmark for multi-state assembly objects
Nov 16, 2021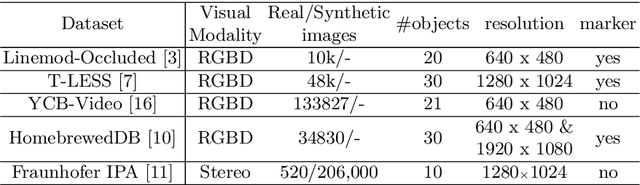


Utilizing 6DoF(Degrees of Freedom) pose information of an object and its components is critical for object state detection tasks. We present IKEA Object State Dataset, a new dataset that contains IKEA furniture 3D models, RGBD video of the assembly process, the 6DoF pose of furniture parts and their bounding box. The proposed dataset will be available at https://github.com/mxllmx/IKEAObjectStateDataset.
Motion Guided Attention Fusion to Recognize Interactions from Videos
Apr 01, 2021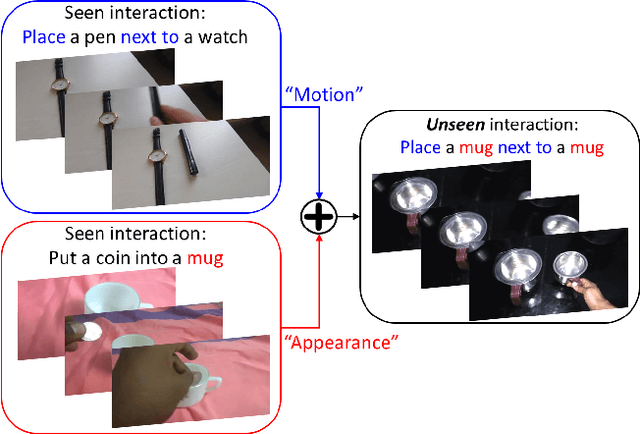
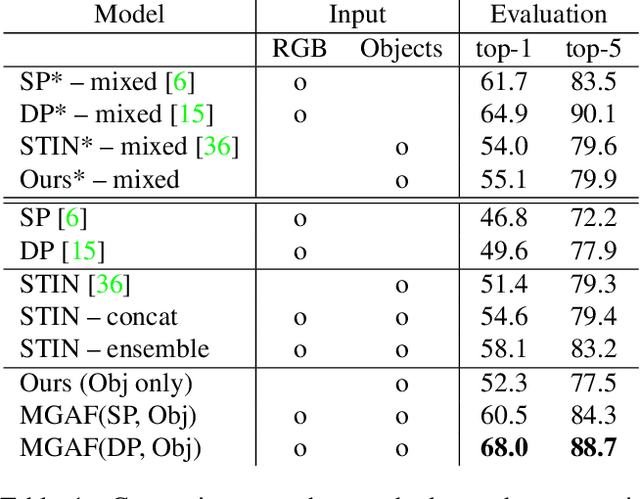
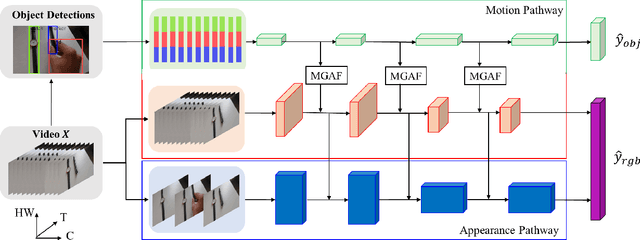
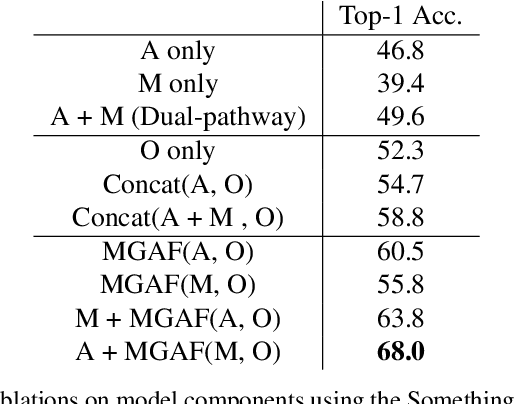
We present a dual-pathway approach for recognizing fine-grained interactions from videos. We build on the success of prior dual-stream approaches, but make a distinction between the static and dynamic representations of objects and their interactions explicit by introducing separate motion and object detection pathways. Then, using our new Motion-Guided Attention Fusion module, we fuse the bottom-up features in the motion pathway with features captured from object detections to learn the temporal aspects of an action. We show that our approach can generalize across appearance effectively and recognize actions where an actor interacts with previously unseen objects. We validate our approach using the compositional action recognition task from the Something-Something-v2 dataset where we outperform existing state-of-the-art methods. We also show that our method can generalize well to real world tasks by showing state-of-the-art performance on recognizing humans assembling various IKEA furniture on the IKEA-ASM dataset.