 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph2seq
Papers and Code
A Graph is Worth $K$ Words: Euclideanizing Graph using Pure Transformer
Feb 04, 2024



Can we model non-Euclidean graphs as pure language or even Euclidean vectors while retaining their inherent information? The non-Euclidean property have posed a long term challenge in graph modeling. Despite recent GNN and Graphformer efforts encoding graphs as Euclidean vectors, recovering original graph from the vectors remains a challenge. We introduce GraphsGPT, featuring a Graph2Seq encoder that transforms non-Euclidean graphs into learnable graph words in a Euclidean space, along with a GraphGPT decoder that reconstructs the original graph from graph words to ensure information equivalence. We pretrain GraphsGPT on 100M molecules and yield some interesting findings: (1) Pretrained Graph2Seq excels in graph representation learning, achieving state-of-the-art results on 8/9 graph classification and regression tasks. (2) Pretrained GraphGPT serves as a strong graph generator, demonstrated by its ability to perform both unconditional and conditional graph generation. (3) Graph2Seq+GraphGPT enables effective graph mixup in the Euclidean space, overcoming previously known non-Euclidean challenge. (4) Our proposed novel edge-centric GPT pretraining task is effective in graph fields, underscoring its success in both representation and generation.
Compositionality-Aware Graph2Seq Learning
Jan 28, 2022

Graphs are a highly expressive data structure, but it is often difficult for humans to find patterns from a complex graph. Hence, generating human-interpretable sequences from graphs have gained interest, called graph2seq learning. It is expected that the compositionality in a graph can be associated to the compositionality in the output sequence in many graph2seq tasks. Therefore, applying compositionality-aware GNN architecture would improve the model performance. In this study, we adopt the multi-level attention pooling (MLAP) architecture, that can aggregate graph representations from multiple levels of information localities. As a real-world example, we take up the extreme source code summarization task, where a model estimate the name of a program function from its source code. We demonstrate that the model having the MLAP architecture outperform the previous state-of-the-art model with more than seven times fewer parameters than it.
HAConvGNN: Hierarchical Attention Based Convolutional Graph Neural Network for Code Documentation Generation in Jupyter Notebooks
Mar 31, 2021

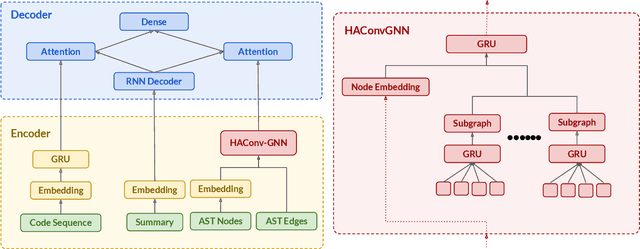
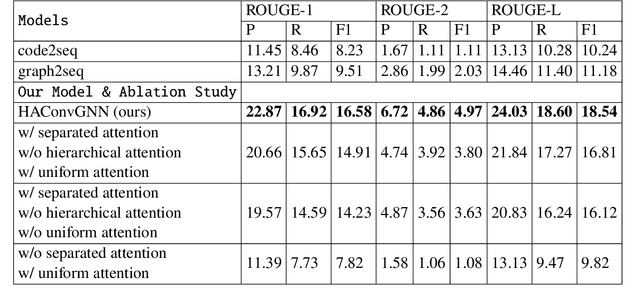
Many data scientists use Jupyter notebook to experiment code, visualize results, and document rationales or interpretations. The code documentation generation CDG task in notebooks is related but different from the code summarization task in software engineering, as one documentation (markdown cell) may consist of a text (informative summary or indicative rationale) for multiple code cells. Our work aims to solve the CDG task by encoding the multiple code cells as separated AST graph structures, for which we propose a hierarchical attention-based ConvGNN component to augment the Seq2Seq network. We build a dataset with publicly available Kaggle notebooks and evaluate our model (HAConvGNN) against baseline models (e.g., Code2Seq or Graph2Seq).
Toward Subgraph Guided Knowledge Graph Question Generation with Graph Neural Networks
Apr 13, 2020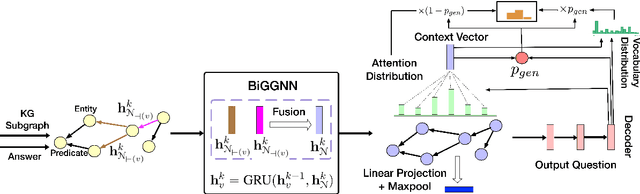

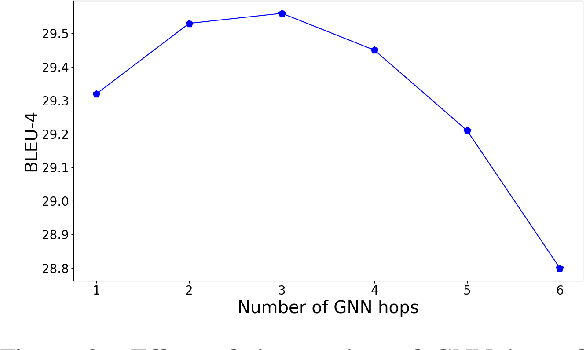
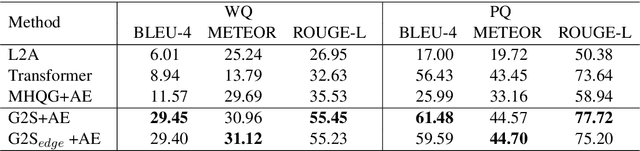
Knowledge graph question generation (QG) aims to generate natural language questions from KG and target answers. Most previous works mainly focusing on the simple setting are to generate questions from a single KG triple. In this work, we focus on a more realistic setting, where we aim to generate questions from a KG subgraph and target answers. In addition, most of previous works built on either RNN-based or Transformer-based models to encode a KG sugraph, which totally discard the explicit structure information contained in a KG subgraph. To address this issue, we propose to apply a bidirectional Graph2Seq model to encode the KG subgraph. In addition, we enhance our RNN decoder with node-level copying mechanism to allow directly copying node attributes from the input graph to the output question. We also explore different ways of initializing node/edge embeddings and handling multi-relational graphs. Our model is end-to-end trainable and achieves new state-of-the-art scores, outperforming existing methods by a significant margin on the two benchmarks.
Natural Question Generation with Reinforcement Learning Based Graph-to-Sequence Model
Oct 19, 2019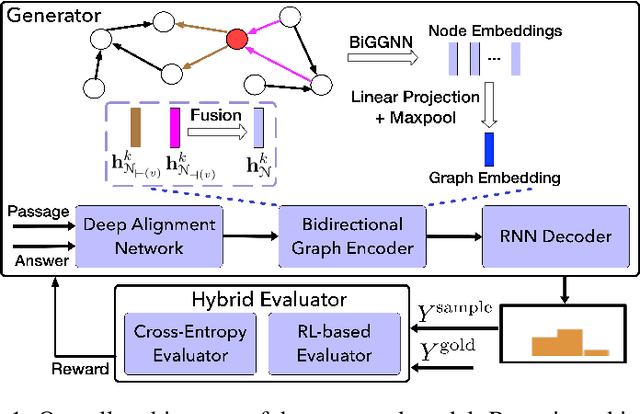
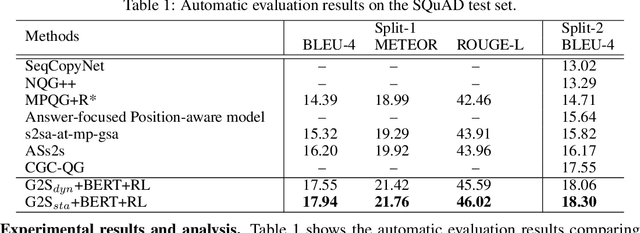
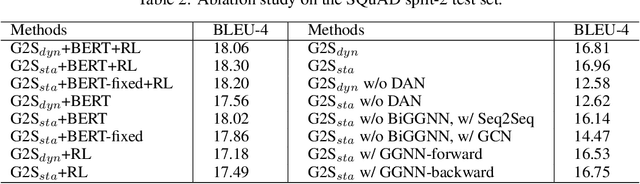
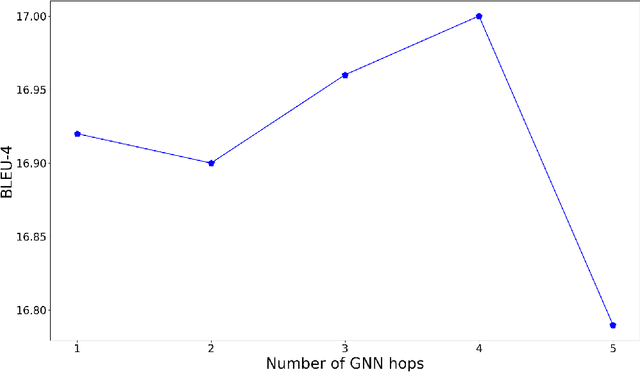
Natural question generation (QG) aims to generate questions from a passage and an answer. In this paper, we propose a novel reinforcement learning (RL) based graph-to-sequence (Graph2Seq) model for QG. Our model consists of a Graph2Seq generator where a novel Bidirectional Gated Graph Neural Network is proposed to embed the passage, and a hybrid evaluator with a mixed objective combining both cross-entropy and RL losses to ensure the generation of syntactically and semantically valid text. The proposed model outperforms previous state-of-the-art methods by a large margin on the SQuAD dataset.
Reinforcement Learning Based Graph-to-Sequence Model for Natural Question Generation
Aug 14, 2019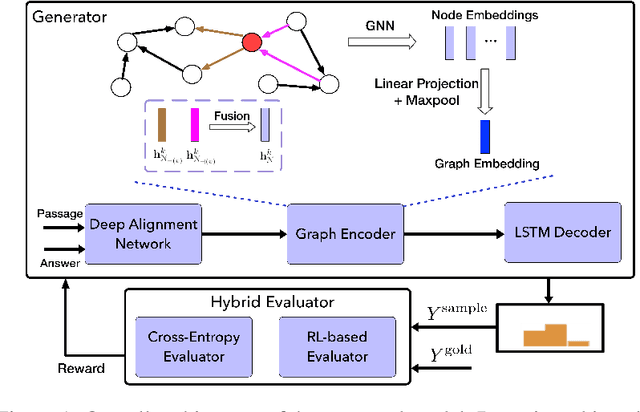
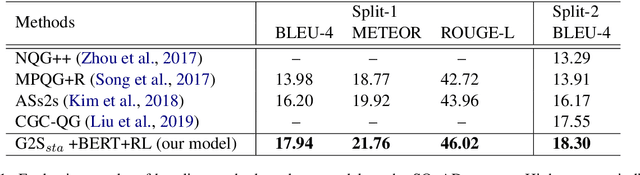

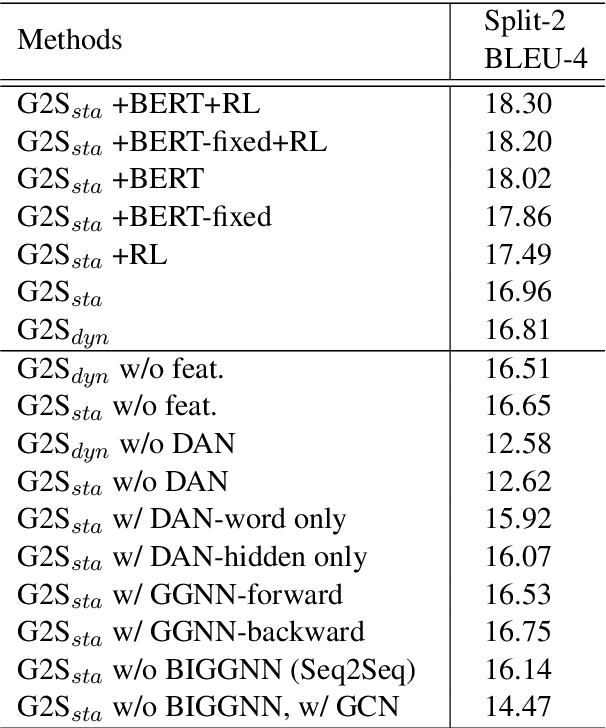
Natural question generation (QG) is a challenging yet rewarding task, that aims to generate questions given an input passage and a target answer. Previous works on QG, however, either (i) ignore the rich structure information hidden in the word sequence, (ii) fail to fully exploit the target answer, or (iii) solely rely on cross-entropy loss that leads to issues like exposure bias and evaluation discrepancy between training and testing. To address the above limitations, in this paper, we propose a reinforcement learning (RL) based graph-to-sequence (Graph2Seq) architecture for the QG task. Our model consists of a Graph2Seq generator where a novel bidirectional graph neural network (GNN) based encoder is applied to embed the input passage incorporating the answer information via a simple yet effective Deep Alignment Network, and an evaluator where a mixed objective function combining both cross-entropy loss and RL loss is designed for ensuring the generation of semantically and syntactically valid text. The proposed model is end-to-end trainable, and achieves new state-of-the-art scores and outperforms all previous methods by a great margin on the SQuAD benchmark.
Graph2Seq: Scalable Learning Dynamics for Graphs
Oct 09, 2018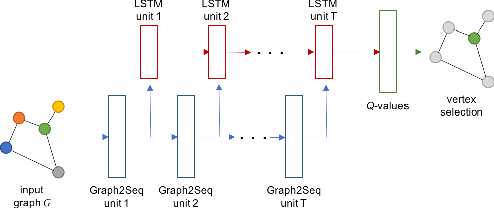
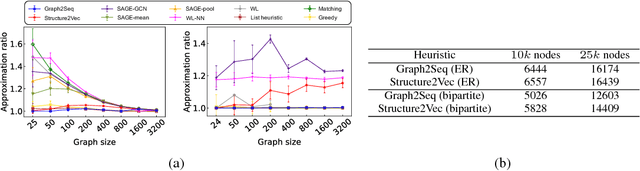
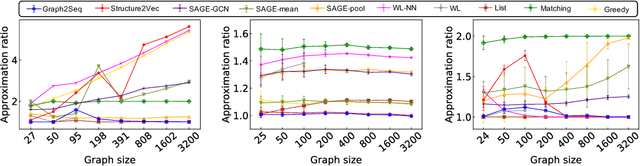
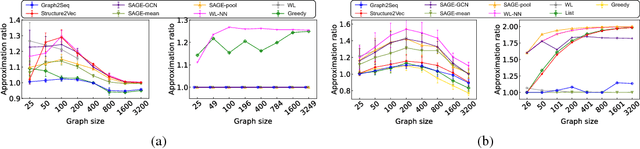
Neural networks have been shown to be an effective tool for learning algorithms over graph-structured data. However, graph representation techniques---that convert graphs to real-valued vectors for use with neural networks---are still in their infancy. Recent works have proposed several approaches (e.g., graph convolutional networks), but these methods have difficulty scaling and generalizing to graphs with different sizes and shapes. We present Graph2Seq, a new technique that represents vertices of graphs as infinite time-series. By not limiting the representation to a fixed dimension, Graph2Seq scales naturally to graphs of arbitrary sizes and shapes. Graph2Seq is also reversible, allowing full recovery of the graph structure from the sequences. By analyzing a formal computational model for graph representation, we show that an unbounded sequence is necessary for scalability. Our experimental results with Graph2Seq show strong generalization and new state-of-the-art performance on a variety of graph combinatorial optimization problems.
Graph2Seq: Graph to Sequence Learning with Attention-based Neural Networks
May 25, 2018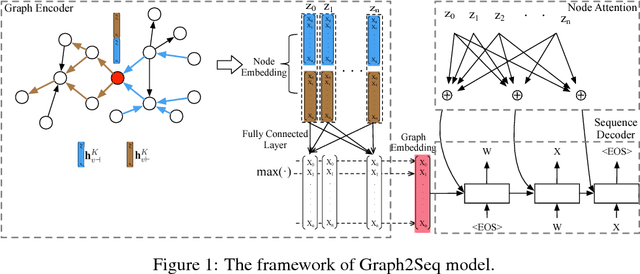
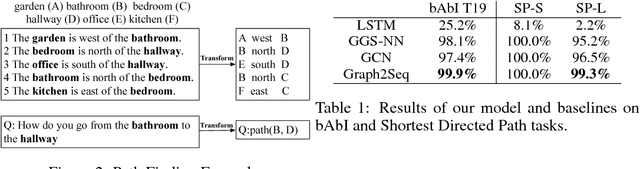
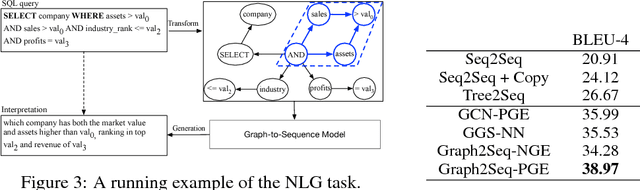
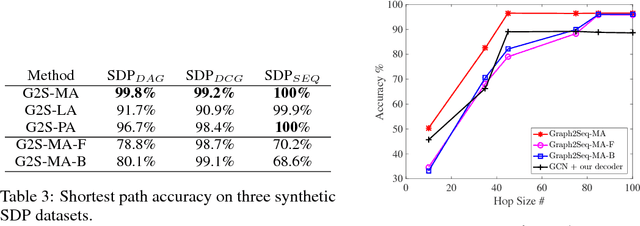
The celebrated \emph{Sequence to Sequence learning (Seq2Seq)} technique and its numerous variants achieve excellent performance on many tasks. However, many machine learning tasks have inputs naturally represented as graphs; existing Seq2Seq models face a significant challenge in achieving accurate conversion from graph form to the appropriate sequence. To address this challenge, we introduce a general end-to-end graph-to-sequence neural encoder-decoder architecture that maps an input graph to a sequence of vectors and uses an attention-based LSTM method to decode the target sequence from these vectors. Our method first generates the node and graph embeddings using an improved graph-based neural network with a novel aggregation strategy to incorporate edge direction information in the node embeddings. We further introduce an attention mechanism that aligns node embeddings and the decoding sequence to better cope with large graphs. Experimental results on bAbI, Shortest Path, and Natural Language Generation tasks demonstrate that our model achieves state-of-the-art performance and significantly outperforms baseline systems; using the proposed aggregation strategy, the model can converge rapidly to the optimal performance.