 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoveabox
Papers and Code
Class Imbalance Correction for Improved Universal Lesion Detection and Tagging in CT
Apr 08, 2025Radiologists routinely detect and size lesions in CT to stage cancer and assess tumor burden. To potentially aid their efforts, multiple lesion detection algorithms have been developed with a large public dataset called DeepLesion (32,735 lesions, 32,120 CT slices, 10,594 studies, 4,427 patients, 8 body part labels). However, this dataset contains missing measurements and lesion tags, and exhibits a severe imbalance in the number of lesions per label category. In this work, we utilize a limited subset of DeepLesion (6\%, 1331 lesions, 1309 slices) containing lesion annotations and body part label tags to train a VFNet model to detect lesions and tag them. We address the class imbalance by conducting three experiments: 1) Balancing data by the body part labels, 2) Balancing data by the number of lesions per patient, and 3) Balancing data by the lesion size. In contrast to a randomly sampled (unbalanced) data subset, our results indicated that balancing the body part labels always increased sensitivity for lesions >= 1cm for classes with low data quantities (Bone: 80\% vs. 46\%, Kidney: 77\% vs. 61\%, Soft Tissue: 70\% vs. 60\%, Pelvis: 83\% vs. 76\%). Similar trends were seen for three other models tested (FasterRCNN, RetinaNet, FoveaBox). Balancing data by lesion size also helped the VFNet model improve recalls for all classes in contrast to an unbalanced dataset. We also provide a structured reporting guideline for a ``Lesions'' subsection to be entered into the ``Findings'' section of a radiology report. To our knowledge, we are the first to report the class imbalance in DeepLesion, and have taken data-driven steps to address it in the context of joint lesion detection and tagging.
Aedes aegypti Egg Counting with Neural Networks for Object Detection
Mar 12, 2024



Aedes aegypti is still one of the main concerns when it comes to disease vectors. Among the many ways to deal with it, there are important protocols that make use of egg numbers in ovitraps to calculate indices, such as the LIRAa and the Breteau Index, which can provide information on predictable outbursts and epidemics. Also, there are many research lines that require egg numbers, specially when mass production of mosquitoes is needed. Egg counting is a laborious and error-prone task that can be automated via computer vision-based techniques, specially deep learning-based counting with object detection. In this work, we propose a new dataset comprising field and laboratory eggs, along with test results of three neural networks applied to the task: Faster R-CNN, Side-Aware Boundary Localization and FoveaBox.
Universal Lymph Node Detection in T2 MRI using Neural Networks
Mar 31, 2022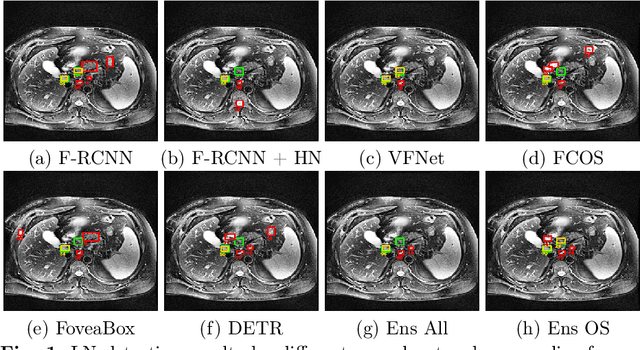
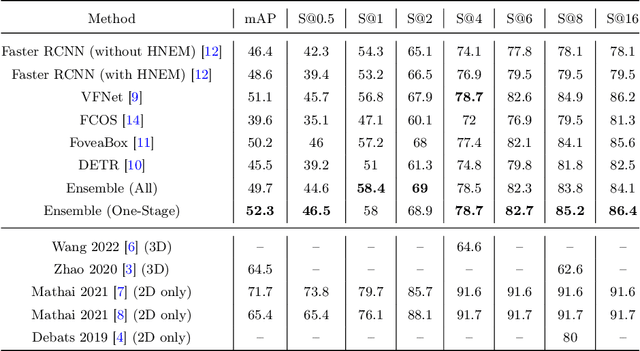
Purpose: Identification of abdominal Lymph Nodes (LN) that are suspicious for metastasis in T2 Magnetic Resonance Imaging (MRI) scans is critical for staging of lymphoproliferative diseases. Prior work on LN detection has been limited to specific anatomical regions of the body (pelvis, rectum) in single MR slices. Therefore, the development of a universal approach to detect LN in full T2 MRI volumes is highly desirable. Methods: In this study, a Computer Aided Detection (CAD) pipeline to universally identify abdominal LN in volumetric T2 MRI using neural networks is proposed. First, we trained various neural network models for detecting LN: Faster RCNN with and without Hard Negative Example Mining (HNEM), FCOS, FoveaBox, VFNet, and Detection Transformer (DETR). Next, we show that the state-of-the-art (SOTA) VFNet model with Adaptive Training Sample Selection (ATSS) outperforms Faster RCNN with HNEM. Finally, we ensembled models that surpassed a 45% mAP threshold. We found that the VFNet model and one-stage model ensemble can be interchangeably used in the CAD pipeline. Results: Experiments on 122 test T2 MRI volumes revealed that VFNet achieved a 51.1% mAP and 78.7% recall at 4 false positives (FP) per volume, while the one-stage model ensemble achieved a mAP of 52.3% and sensitivity of 78.7% at 4FP. Conclusion: Our contribution is a CAD pipeline that detects LN in T2 MRI volumes, resulting in a sensitivity improvement of $\sim$14 points over the current SOTA method for LN detection (sensitivity of 78.7% at 4 FP vs. 64.6% at 5 FP per volume).
AGSFCOS: Based on attention mechanism and Scale-Equalizing pyramid network of object detection
May 20, 2021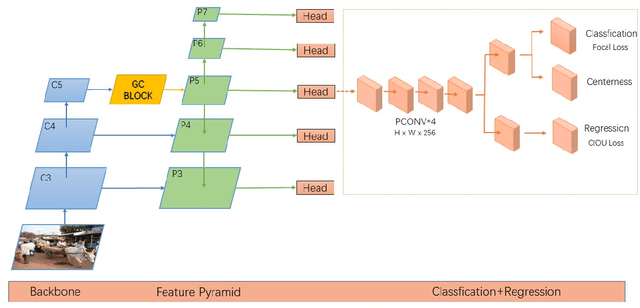

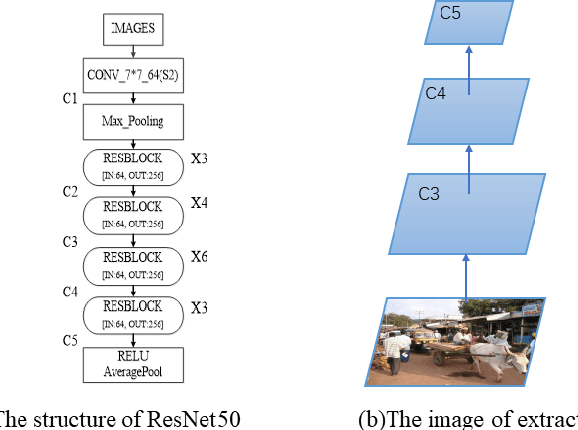
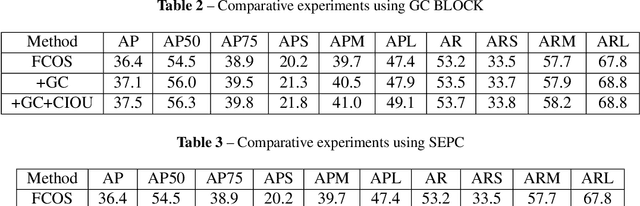
Recently, the anchor-free object detection model has shown great potential for accuracy and speed to exceed anchor-based object detection. Therefore, two issues are mainly studied in this article: (1) How to let the backbone network in the anchor-free object detection model learn feature extraction? (2) How to make better use of the feature pyramid network? In order to solve the above problems, Experiments show that our model has a certain improvement in accuracy compared with the current popular detection models on the COCO dataset, the designed attention mechanism module can capture contextual information well, improve detection accuracy, and use sepc network to help balance abstract and detailed information, and reduce the problem of semantic gap in the feature pyramid network. Whether it is anchor-based network model YOLOv3, Faster RCNN, or anchor-free network model Foveabox, FSAF, FCOS. Our optimal model can get 39.5% COCO AP under the background of ResNet50.
FoveaBox: Beyond Anchor-based Object Detector
Apr 08, 2019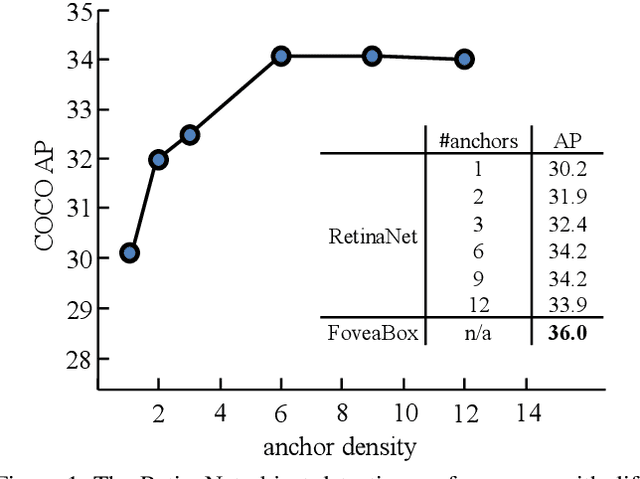

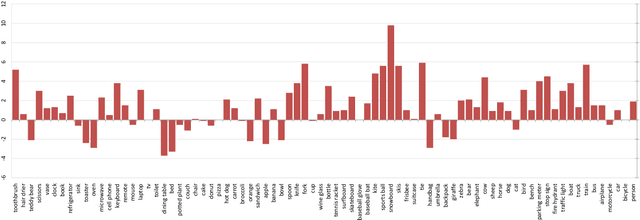
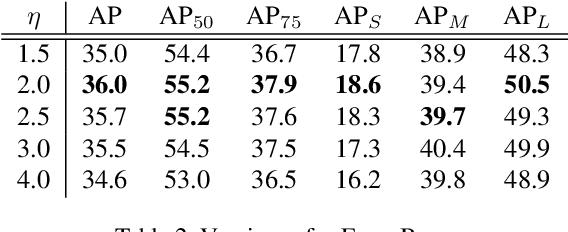
We present FoveaBox, an accurate, flexible and completely anchor-free framework for object detection. While almost all state-of-the-art object detectors utilize the predefined anchors to enumerate possible locations, scales and aspect ratios for the search of the objects, their performance and generalization ability are also limited to the design of anchors. Instead, FoveaBox directly learns the object existing possibility and the bounding box coordinates without anchor reference. This is achieved by: (a) predicting category-sensitive semantic maps for the object existing possibility, and (b) producing category-agnostic bounding box for each position that potentially contains an object. The scales of target boxes are naturally associated with feature pyramid representations for each input image. Without bells and whistles, FoveaBox achieves state-of-the-art single model performance of 42.1 AP on the standard COCO detection benchmark. Specially for the objects with arbitrary aspect ratios, FoveaBox brings in significant improvement compared to the anchor-based detectors. More surprisingly, when it is challenged by the stretched testing images, FoveaBox shows great robustness and generalization ability to the changed distribution of bounding box shapes. The code will be made publicly available.