 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlickr1024
Papers and Code
ASteISR: Adapting Single Image Super-resolution Pre-trained Model for Efficient Stereo Image Super-resolution
Jul 04, 2024Despite advances in the paradigm of pre-training then fine-tuning in low-level vision tasks, significant challenges persist particularly regarding the increased size of pre-trained models such as memory usage and training time. Another concern often encountered is the unsatisfying results yielded when directly applying pre-trained single-image models to multi-image domain. In this paper, we propose a efficient method for transferring a pre-trained single-image super-resolution (SISR) transformer network to the domain of stereo image super-resolution (SteISR) through a parameter-efficient fine-tuning (PEFT) method. Specifically, we introduce the concept of stereo adapters and spatial adapters which are incorporated into the pre-trained SISR transformer network. Subsequently, the pre-trained SISR model is frozen, enabling us to fine-tune the adapters using stereo datasets along. By adopting this training method, we enhance the ability of the SISR model to accurately infer stereo images by 0.79dB on the Flickr1024 dataset. This method allows us to train only 4.8% of the original model parameters, achieving state-of-the-art performance on four commonly used SteISR benchmarks. Compared to the more complicated full fine-tuning approach, our method reduces training time and memory consumption by 57% and 15%, respectively.
Decoupled Cross-Scale Cross-View Interaction for Stereo Image Enhancement in The Dark
Nov 12, 2022Low-light stereo image enhancement (LLSIE) is a relatively new task to enhance the quality of visually unpleasant stereo images captured in dark condition. However, current methods achieve inferior performance on detail recovery and illumination adjustment. We find it is because: 1) the insufficient single-scale inter-view interaction makes the cross-view cues unable to be fully exploited; 2) lacking long-range dependency leads to the inability to deal with the spatial long-range effects caused by illumination degradation. To alleviate such limitations, we propose a LLSIE model termed Decoupled Cross-scale Cross-view Interaction Network (DCI-Net). Specifically, we present a decoupled interaction module (DIM) that aims for sufficient dual-view information interaction. DIM decouples the dual-view information exchange into discovering multi-scale cross-view correlations and further exploring cross-scale information flow. Besides, we present a spatial-channel information mining block (SIMB) for intra-view feature extraction, and the benefits are twofold. One is the long-range dependency capture to build spatial long-range relationship, and the other is expanded channel information refinement that enhances information flow in channel dimension. Extensive experiments on Flickr1024, KITTI 2012, KITTI 2015 and Middlebury datasets show that our method obtains better illumination adjustment and detail recovery, and achieves SOTA performance compared to other related methods. Our codes, datasets and models will be publicly available.
NAFSSR: Stereo Image Super-Resolution Using NAFNet
Apr 26, 2022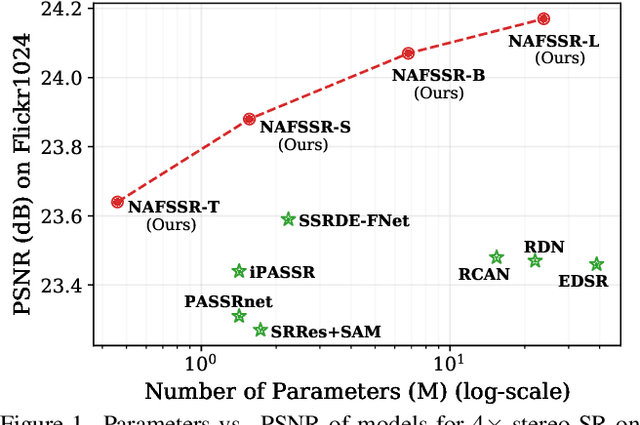
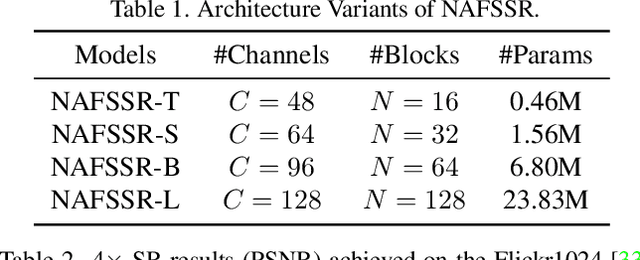
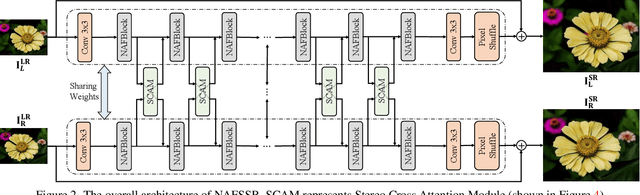
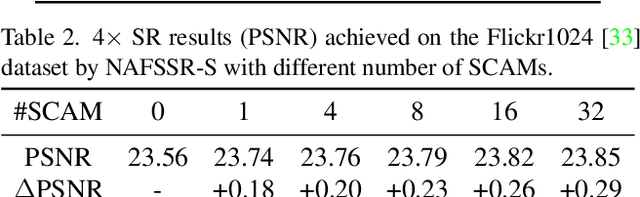
Stereo image super-resolution aims at enhancing the quality of super-resolution results by utilizing the complementary information provided by binocular systems. To obtain reasonable performance, most methods focus on finely designing modules, loss functions, and etc. to exploit information from another viewpoint. This has the side effect of increasing system complexity, making it difficult for researchers to evaluate new ideas and compare methods. This paper inherits a strong and simple image restoration model, NAFNet, for single-view feature extraction and extends it by adding cross attention modules to fuse features between views to adapt to binocular scenarios. The proposed baseline for stereo image super-resolution is noted as NAFSSR. Furthermore, training/testing strategies are proposed to fully exploit the performance of NAFSSR. Extensive experiments demonstrate the effectiveness of our method. In particular, NAFSSR outperforms the state-of-the-art methods on the KITTI 2012, KITTI 2015, Middlebury, and Flickr1024 datasets. With NAFSSR, we won 1st place in the NTIRE 2022 Stereo Image Super-resolution Challenge. Codes and models will be released at https://github.com/megvii-research/NAFNet.
Parallax Attention for Unsupervised Stereo Correspondence Learning
Sep 16, 2020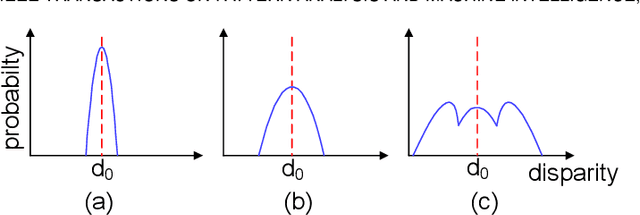
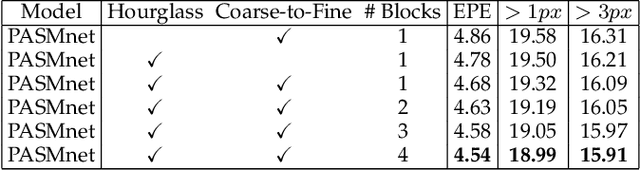
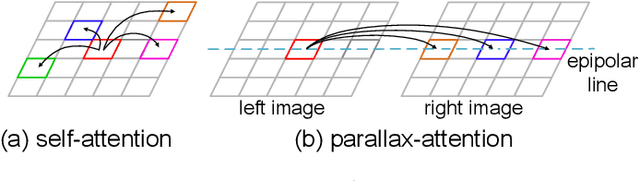

Stereo image pairs encode 3D scene cues into stereo correspondences between the left and right images. To exploit 3D cues within stereo images, recent CNN based methods commonly use cost volume techniques to capture stereo correspondence over large disparities. However, since disparities can vary significantly for stereo cameras with different baselines, focal lengths and resolutions, the fixed maximum disparity used in cost volume techniques hinders them to handle different stereo image pairs with large disparity variations. In this paper, we propose a generic parallax-attention mechanism (PAM) to capture stereo correspondence regardless of disparity variations. Our PAM integrates epipolar constraints with attention mechanism to calculate feature similarities along the epipolar line to capture stereo correspondence. Based on our PAM, we propose a parallax-attention stereo matching network (PASMnet) and a parallax-attention stereo image super-resolution network (PASSRnet) for stereo matching and stereo image super-resolution tasks. Moreover, we introduce a new and large-scale dataset named Flickr1024 for stereo image super-resolution. Experimental results show that our PAM is generic and can effectively learn stereo correspondence under large disparity variations in an unsupervised manner. Comparative results show that our PASMnet and PASSRnet achieve the state-of-the-art performance.
Learning Parallax Attention for Stereo Image Super-Resolution
Mar 19, 2019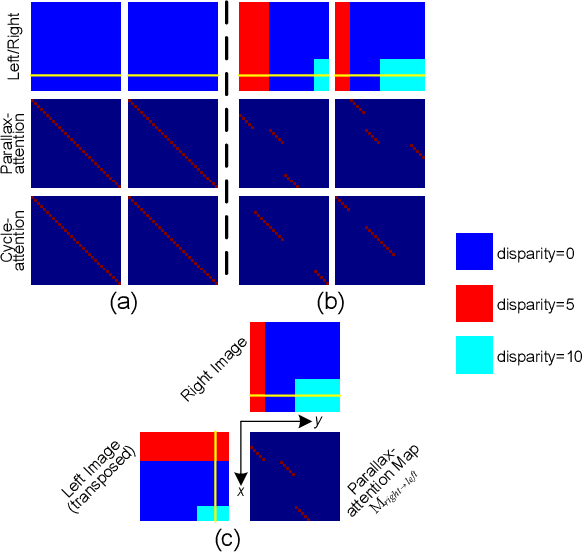
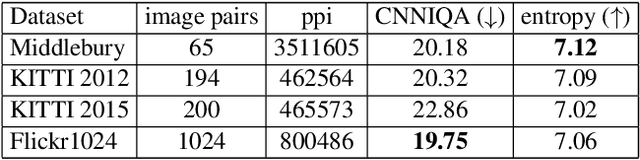
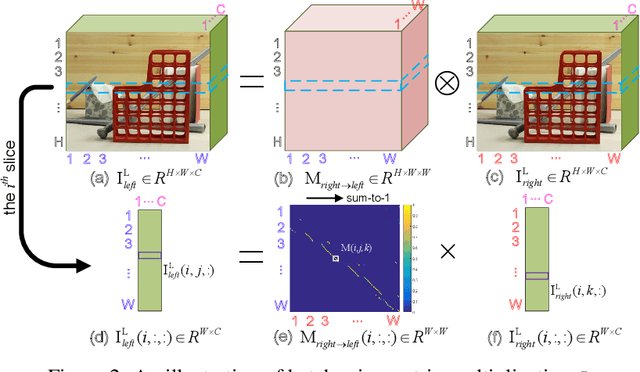
Stereo image pairs can be used to improve the performance of super-resolution (SR) since additional information is provided from a second viewpoint. However, it is challenging to incorporate this information for SR since disparities between stereo images vary significantly. In this paper, we propose a parallax-attention stereo superresolution network (PASSRnet) to integrate the information from a stereo image pair for SR. Specifically, we introduce a parallax-attention mechanism with a global receptive field along the epipolar line to handle different stereo images with large disparity variations. We also propose a new and the largest dataset for stereo image SR (namely, Flickr1024). Extensive experiments demonstrate that the parallax-attention mechanism can capture correspondence between stereo images to improve SR performance with a small computational and memory cost. Comparative results show that our PASSRnet achieves the state-of-the-art performance on the Middlebury, KITTI 2012 and KITTI 2015 datasets.
Flickr1024: A Dataset for Stereo Image Super-Resolution
Mar 15, 2019
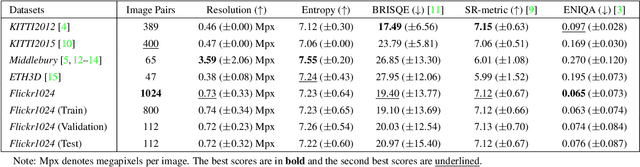


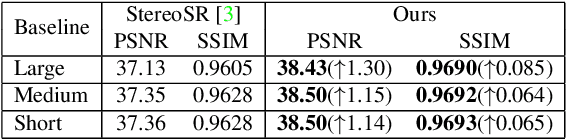
With the popularity of dual cameras in recently released smart phones, a growing number of super-resolution (SR) methods have been proposed to enhance the resolution of stereo image pairs. However, the lack of high-quality stereo datasets has limited the research in this area. To facilitate the training and evaluation of novel stereo SR algorithms, in this paper, we propose a large-scale stereo dataset named Flickr1024. Compared to the existing stereo datasets, the proposed dataset contains much more high-quality images and covers diverse scenarios. We train two state-of-the-art stereo SR methods (i.e., StereoSR and PASSRnet) on the KITTI2015, Middlebury, and Flickr1024 datasets. Experimental results demonstrate that our dataset can improve the performance of stereo SR algorithms. The Flickr1024 dataset is available online at: https://yingqianwang.github.io/Flickr1024.