 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDensepose Track
Papers and Code
BodyMap: Learning Full-Body Dense Correspondence Map
May 18, 2022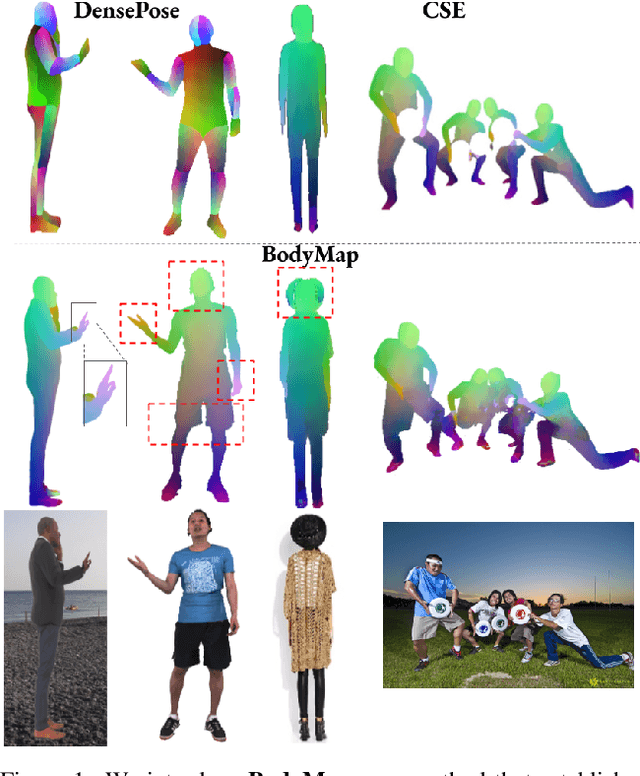
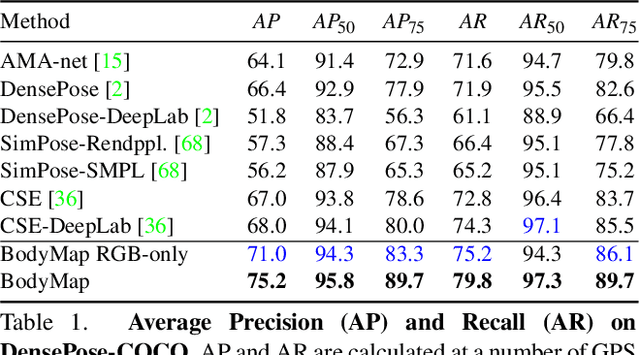
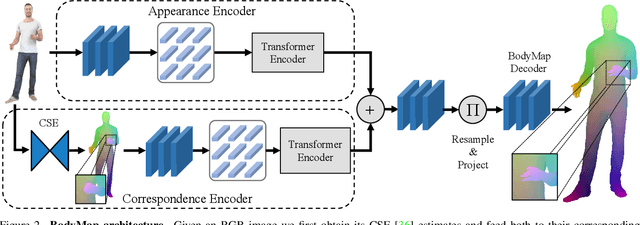
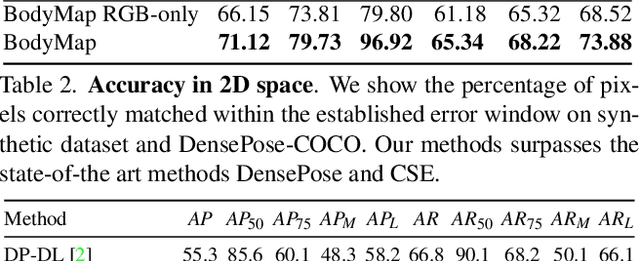
Dense correspondence between humans carries powerful semantic information that can be utilized to solve fundamental problems for full-body understanding such as in-the-wild surface matching, tracking and reconstruction. In this paper we present BodyMap, a new framework for obtaining high-definition full-body and continuous dense correspondence between in-the-wild images of clothed humans and the surface of a 3D template model. The correspondences cover fine details such as hands and hair, while capturing regions far from the body surface, such as loose clothing. Prior methods for estimating such dense surface correspondence i) cut a 3D body into parts which are unwrapped to a 2D UV space, producing discontinuities along part seams, or ii) use a single surface for representing the whole body, but none handled body details. Here, we introduce a novel network architecture with Vision Transformers that learn fine-level features on a continuous body surface. BodyMap outperforms prior work on various metrics and datasets, including DensePose-COCO by a large margin. Furthermore, we show various applications ranging from multi-layer dense cloth correspondence, neural rendering with novel-view synthesis and appearance swapping.
Quality-Aware Network for Human Parsing
Mar 10, 2021
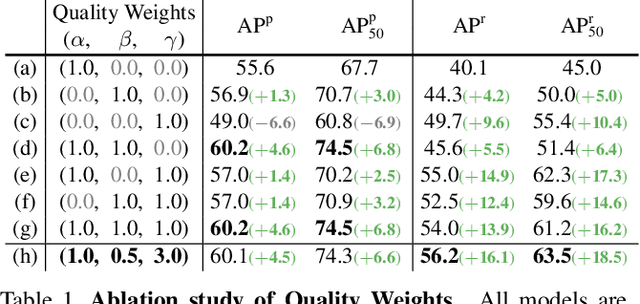
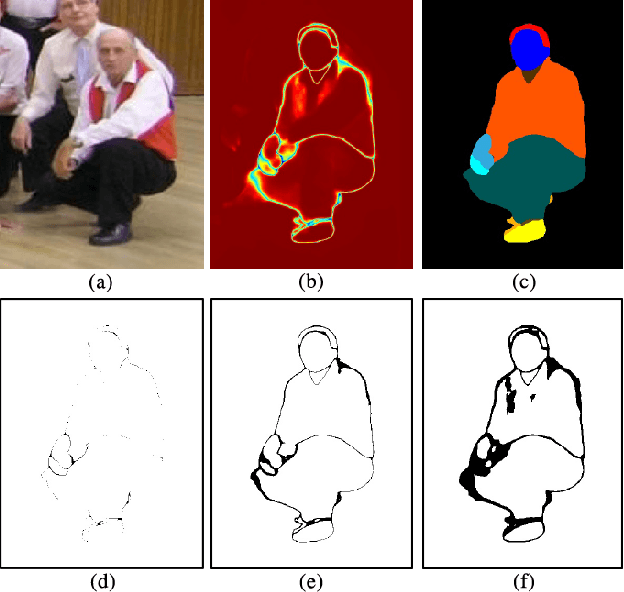
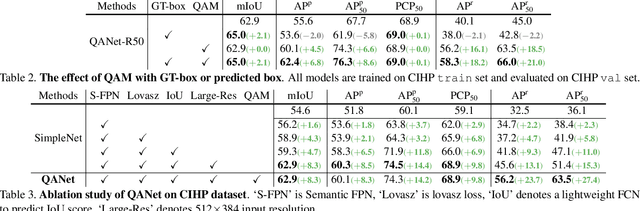
How to estimate the quality of the network output is an important issue, and currently there is no effective solution in the field of human parsing. In order to solve this problem, this work proposes a statistical method based on the output probability map to calculate the pixel quality information, which is called pixel score. In addition, the Quality-Aware Module (QAM) is proposed to fuse the different quality information, the purpose of which is to estimate the quality of human parsing results. We combine QAM with a concise and effective network design to propose Quality-Aware Network (QANet) for human parsing. Benefiting from the superiority of QAM and QANet, we achieve the best performance on three multiple and one single human parsing benchmarks, including CIHP, MHP-v2, Pascal-Person-Part and LIP. Without increasing the training and inference time, QAM improves the AP$^\text{r}$ criterion by more than 10 points in the multiple human parsing task. QAM can be extended to other tasks with good quality estimation, e.g. instance segmentation. Specifically, QAM improves Mask R-CNN by ~1% mAP on COCO and LVISv1.0 datasets. Based on the proposed QAM and QANet, our overall system wins 1st place in CVPR2019 COCO DensePose Challenge, and 1st place in Track 1 & 2 of CVPR2020 LIP Challenge. Code and models are available at https://github.com/soeaver/QANet.
Slim DensePose: Thrifty Learning from Sparse Annotations and Motion Cues
Jun 13, 2019
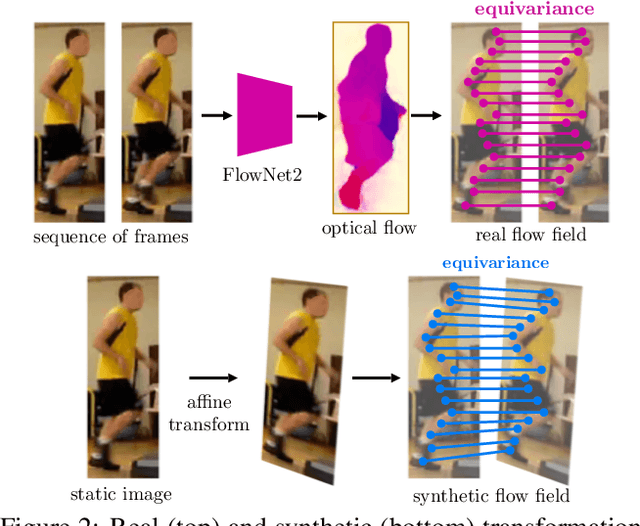

DensePose supersedes traditional landmark detectors by densely mapping image pixels to body surface coordinates. This power, however, comes at a greatly increased annotation time, as supervising the model requires to manually label hundreds of points per pose instance. In this work, we thus seek methods to significantly slim down the DensePose annotations, proposing more efficient data collection strategies. In particular, we demonstrate that if annotations are collected in video frames, their efficacy can be multiplied for free by using motion cues. To explore this idea, we introduce DensePose-Track, a dataset of videos where selected frames are annotated in the traditional DensePose manner. Then, building on geometric properties of the DensePose mapping, we use the video dynamic to propagate ground-truth annotations in time as well as to learn from Siamese equivariance constraints. Having performed exhaustive empirical evaluation of various data annotation and learning strategies, we demonstrate that doing so can deliver significantly improved pose estimation results over strong baselines. However, despite what is suggested by some recent works, we show that merely synthesizing motion patterns by applying geometric transformations to isolated frames is significantly less effective, and that motion cues help much more when they are extracted from videos.