 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaptcha Detection
Papers and Code
Non-Intrusive Graph-Based Bot Detection for E-Commerce Using Inductive Graph Neural Networks
Jan 30, 2026Malicious bots pose a growing threat to e-commerce platforms by scraping data, hoarding inventory, and perpetrating fraud. Traditional bot mitigation techniques, including IP blacklists and CAPTCHA-based challenges, are increasingly ineffective or intrusive, as modern bots leverage proxies, botnets, and AI-assisted evasion strategies. This work proposes a non-intrusive graph-based bot detection framework for e-commerce that models user session behavior through a graph representation and applies an inductive graph neural network for classification. The approach captures both relational structure and behavioral semantics, enabling accurate identification of subtle automated activity that evades feature-based methods. Experiments on real-world e-commerce traffic demonstrate that the proposed inductive graph model outperforms a strong session-level multilayer perceptron baseline in terms of AUC and F1 score. Additional adversarial perturbation and cold-start simulations show that the model remains robust under moderate graph modifications and generalizes effectively to previously unseen sessions and URLs. The proposed framework is deployment-friendly, integrates with existing systems without client-side instrumentation, and supports real-time inference and incremental updates, making it suitable for practical e-commerce security deployments.
Theoretical Analysis of Power-law Transformation on Images for Text Polarity Detection
Nov 11, 2025Several computer vision applications like vehicle license plate recognition, captcha recognition, printed or handwriting character recognition from images etc., text polarity detection and binarization are the important preprocessing tasks. To analyze any image, it has to be converted to a simple binary image. This binarization process requires the knowledge of polarity of text in the images. Text polarity is defined as the contrast of text with respect to background. That means, text is darker than the background (dark text on bright background) or vice-versa. The binarization process uses this polarity information to convert the original colour or gray scale image into a binary image. In the literature, there is an intuitive approach based on power-law transformation on the original images. In this approach, the authors have illustrated an interesting phenomenon from the histogram statistics of the transformed images. Considering text and background as two classes, they have observed that maximum between-class variance between two classes is increasing (decreasing) for dark (bright) text on bright (dark) background. The corresponding empirical results have been presented. In this paper, we present a theoretical analysis of the above phenomenon.
Benchmarking of Different YOLO Models for CAPTCHAs Detection and Classification
Feb 19, 2025



This paper provides an analysis and comparison of the YOLOv5, YOLOv8 and YOLOv10 models for webpage CAPTCHAs detection using the datasets collected from the web and darknet as well as synthetized data of webpages. The study examines the nano (n), small (s), and medium (m) variants of YOLO architectures and use metrics such as Precision, Recall, F1 score, mAP@50 and inference speed to determine the real-life utility. Additionally, the possibility of tuning the trained model to detect new CAPTCHA patterns efficiently was examined as it is a crucial part of real-life applications. The image slicing method was proposed as a way to improve the metrics of detection on oversized input images which can be a common scenario in webpages analysis. Models in version nano achieved the best results in terms of speed, while more complexed architectures scored better in terms of other metrics.
Predictive Response Optimization: Using Reinforcement Learning to Fight Online Social Network Abuse
Feb 24, 2025



Detecting phishing, spam, fake accounts, data scraping, and other malicious activity in online social networks (OSNs) is a problem that has been studied for well over a decade, with a number of important results. Nearly all existing works on abuse detection have as their goal producing the best possible binary classifier; i.e., one that labels unseen examples as "benign" or "malicious" with high precision and recall. However, no prior published work considers what comes next: what does the service actually do after it detects abuse? In this paper, we argue that detection as described in previous work is not the goal of those who are fighting OSN abuse. Rather, we believe the goal to be selecting actions (e.g., ban the user, block the request, show a CAPTCHA, or "collect more evidence") that optimize a tradeoff between harm caused by abuse and impact on benign users. With this framing, we see that enlarging the set of possible actions allows us to move the Pareto frontier in a way that is unattainable by simply tuning the threshold of a binary classifier. To demonstrate the potential of our approach, we present Predictive Response Optimization (PRO), a system based on reinforcement learning that utilizes available contextual information to predict future abuse and user-experience metrics conditioned on each possible action, and select actions that optimize a multi-dimensional tradeoff between abuse/harm and impact on user experience. We deployed versions of PRO targeted at stopping automated activity on Instagram and Facebook. In both cases our experiments showed that PRO outperforms a baseline classification system, reducing abuse volume by 59% and 4.5% (respectively) with no negative impact to users. We also present several case studies that demonstrate how PRO can quickly and automatically adapt to changes in business constraints, system behavior, and/or adversarial tactics.
D-CAPTCHA++: A Study of Resilience of Deepfake CAPTCHA under Transferable Imperceptible Adversarial Attack
Sep 11, 2024



The advancements in generative AI have enabled the improvement of audio synthesis models, including text-to-speech and voice conversion. This raises concerns about its potential misuse in social manipulation and political interference, as synthetic speech has become indistinguishable from natural human speech. Several speech-generation programs are utilized for malicious purposes, especially impersonating individuals through phone calls. Therefore, detecting fake audio is crucial to maintain social security and safeguard the integrity of information. Recent research has proposed a D-CAPTCHA system based on the challenge-response protocol to differentiate fake phone calls from real ones. In this work, we study the resilience of this system and introduce a more robust version, D-CAPTCHA++, to defend against fake calls. Specifically, we first expose the vulnerability of the D-CAPTCHA system under transferable imperceptible adversarial attack. Secondly, we mitigate such vulnerability by improving the robustness of the system by using adversarial training in D-CAPTCHA deepfake detectors and task classifiers.
Two-Stage Human Verification using HandCAPTCHA and Anti-Spoofed Finger Biometrics with Feature Selection
Oct 13, 2024



This paper presents a human verification scheme in two independent stages to overcome the vulnerabilities of attacks and to enhance security. At the first stage, a hand image-based CAPTCHA (HandCAPTCHA) is tested to avert automated bot-attacks on the subsequent biometric stage. In the next stage, finger biometric verification of a legitimate user is performed with presentation attack detection (PAD) using the real hand images of the person who has passed a random HandCAPTCHA challenge. The electronic screen-based PAD is tested using image quality metrics. After this spoofing detection, geometric features are extracted from the four fingers (excluding the thumb) of real users. A modified forward-backward (M-FoBa) algorithm is devised to select relevant features for biometric authentication. The experiments are performed on the Bogazici University (BU) and the IIT-Delhi (IITD) hand databases using the k-nearest neighbor and random forest classifiers. The average accuracy of the correct HandCAPTCHA solution is 98.5%, and the false accept rate of a bot is 1.23%. The PAD is tested on 255 subjects of BU, and the best average error is 0%. The finger biometric identification accuracy of 98% and an equal error rate (EER) of 6.5% have been achieved for 500 subjects of the BU. For 200 subjects of the IITD, 99.5% identification accuracy, and 5.18% EER are obtained.
Segmentation-free Connectionist Temporal Classification loss based OCR Model for Text Captcha Classification
Feb 08, 2024Captcha are widely used to secure systems from automatic responses by distinguishing computer responses from human responses. Text, audio, video, picture picture-based Optical Character Recognition (OCR) are used for creating captcha. Text-based OCR captcha are the most often used captcha which faces issues namely, complex and distorted contents. There are attempts to build captcha detection and classification-based systems using machine learning and neural networks, which need to be tuned for accuracy. The existing systems face challenges in the recognition of distorted characters, handling variable-length captcha and finding sequential dependencies in captcha. In this work, we propose a segmentation-free OCR model for text captcha classification based on the connectionist temporal classification loss technique. The proposed model is trained and tested on a publicly available captcha dataset. The proposed model gives 99.80\% character level accuracy, while 95\% word level accuracy. The accuracy of the proposed model is compared with the state-of-the-art models and proves to be effective. The variable length complex captcha can be thus processed with the segmentation-free connectionist temporal classification loss technique with dependencies which will be massively used in securing the software systems.
EnSolver: Uncertainty-Aware CAPTCHA Solver Using Deep Ensembles
Jul 27, 2023



The popularity of text-based CAPTCHA as a security mechanism to protect websites from automated bots has prompted researches in CAPTCHA solvers, with the aim of understanding its failure cases and subsequently making CAPTCHAs more secure. Recently proposed solvers, built on advances in deep learning, are able to crack even the very challenging CAPTCHAs with high accuracy. However, these solvers often perform poorly on out-of-distribution samples that contain visual features different from those in the training set. Furthermore, they lack the ability to detect and avoid such samples, making them susceptible to being locked out by defense systems after a certain number of failed attempts. In this paper, we propose EnSolver, a novel CAPTCHA solver that utilizes deep ensemble uncertainty estimation to detect and skip out-of-distribution CAPTCHAs, making it harder to be detected. We demonstrate the use of our solver with object detection models and show empirically that it performs well on both in-distribution and out-of-distribution data, achieving up to 98.1% accuracy when detecting out-of-distribution data and up to 93% success rate when solving in-distribution CAPTCHAs.
Deepfake CAPTCHA: A Method for Preventing Fake Calls
Jan 08, 2023Deep learning technology has made it possible to generate realistic content of specific individuals. These `deepfakes' can now be generated in real-time which enables attackers to impersonate people over audio and video calls. Moreover, some methods only need a few images or seconds of audio to steal an identity. Existing defenses perform passive analysis to detect fake content. However, with the rapid progress of deepfake quality, this may be a losing game. In this paper, we propose D-CAPTCHA: an active defense against real-time deepfakes. The approach is to force the adversary into the spotlight by challenging the deepfake model to generate content which exceeds its capabilities. By doing so, passive detection becomes easier since the content will be distorted. In contrast to existing CAPTCHAs, we challenge the AI's ability to create content as opposed to its ability to classify content. In this work we focus on real-time audio deepfakes and present preliminary results on video. In our evaluation we found that D-CAPTCHA outperforms state-of-the-art audio deepfake detectors with an accuracy of 91-100% depending on the challenge (compared to 71% without challenges). We also performed a study on 41 volunteers to understand how threatening current real-time deepfake attacks are. We found that the majority of the volunteers could not tell the difference between real and fake audio.
Attacks as Defenses: Designing Robust Audio CAPTCHAs Using Attacks on Automatic Speech Recognition Systems
Mar 10, 2022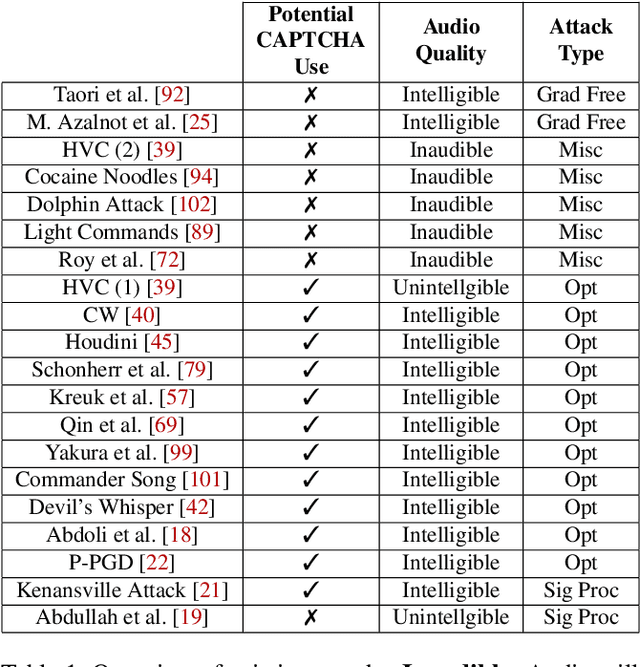
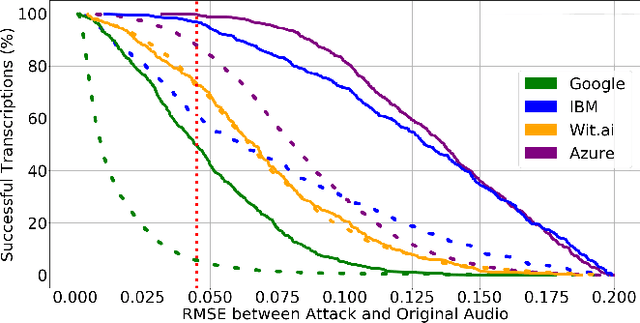
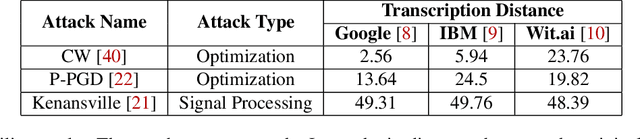
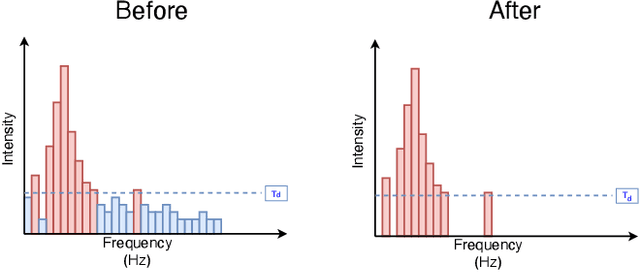
Audio CAPTCHAs are supposed to provide a strong defense for online resources; however, advances in speech-to-text mechanisms have rendered these defenses ineffective. Audio CAPTCHAs cannot simply be abandoned, as they are specifically named by the W3C as important enablers of accessibility. Accordingly, demonstrably more robust audio CAPTCHAs are important to the future of a secure and accessible Web. We look to recent literature on attacks on speech-to-text systems for inspiration for the construction of robust, principle-driven audio defenses. We begin by comparing 20 recent attack papers, classifying and measuring their suitability to serve as the basis of new "robust to transcription" but "easy for humans to understand" CAPTCHAs. After showing that none of these attacks alone are sufficient, we propose a new mechanism that is both comparatively intelligible (evaluated through a user study) and hard to automatically transcribe (i.e., $P({\rm transcription}) = 4 \times 10^{-5}$). Finally, we demonstrate that our audio samples have a high probability of being detected as CAPTCHAs when given to speech-to-text systems ($P({\rm evasion}) = 1.77 \times 10^{-4}$). In so doing, we not only demonstrate a CAPTCHA that is approximately four orders of magnitude more difficult to crack, but that such systems can be designed based on the insights gained from attack papers using the differences between the ways that humans and computers process audio.