 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLAD-VSA: Cross-Domain Face Presentation Attack Detection with Vocabulary Separation and Adaptation
Paper and Code
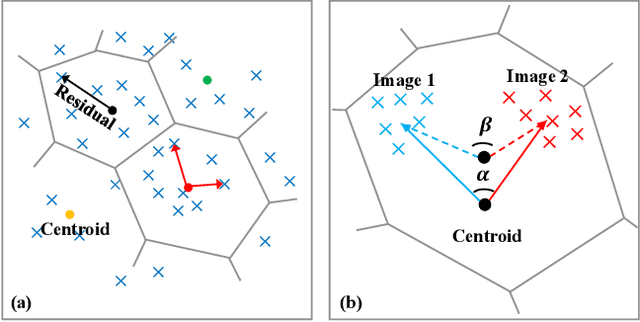
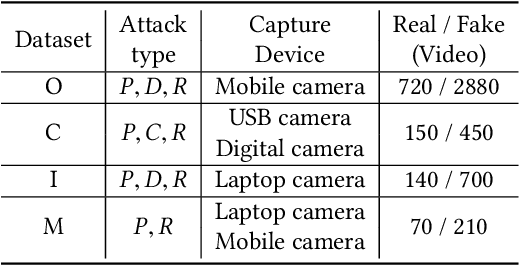
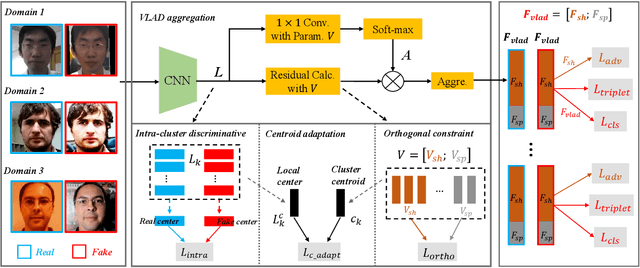
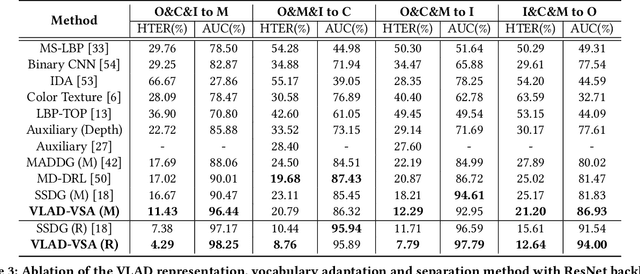
For face presentation attack detection (PAD), most of the spoofing cues are subtle, local image patterns (e.g., local image distortion, 3D mask edge and cut photo edges). The representations of existing PAD works with simple global pooling method, however, lose the local feature discriminability. In this paper, the VLAD aggregation method is adopted to quantize local features with visual vocabulary locally partitioning the feature space, and hence preserve the local discriminability. We further propose the vocabulary separation and adaptation method to modify VLAD for cross-domain PADtask. The proposed vocabulary separation method divides vocabulary into domain-shared and domain-specific visual words to cope with the diversity of live and attack faces under the cross-domain scenario. The proposed vocabulary adaptation method imitates the maximization step of the k-means algorithm in the end-to-end training, which guarantees the visual words be close to the center of assigned local features and thus brings robust similarity measurement. We give illustrations and extensive experiments to demonstrate the effectiveness of VLAD with the proposed vocabulary separation and adaptation method on standard cross-domain PAD benchmarks. The codes are available at https://github.com/Liubinggunzu/VLAD-VSA.