 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo We Need to Penalize Variance of Losses for Learning with Label Noise?
Paper and Code
Jan 30, 2022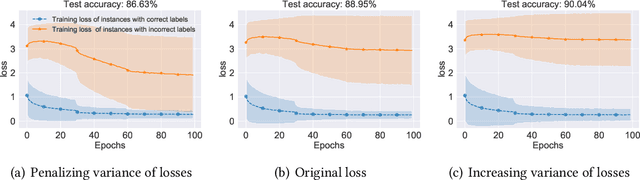
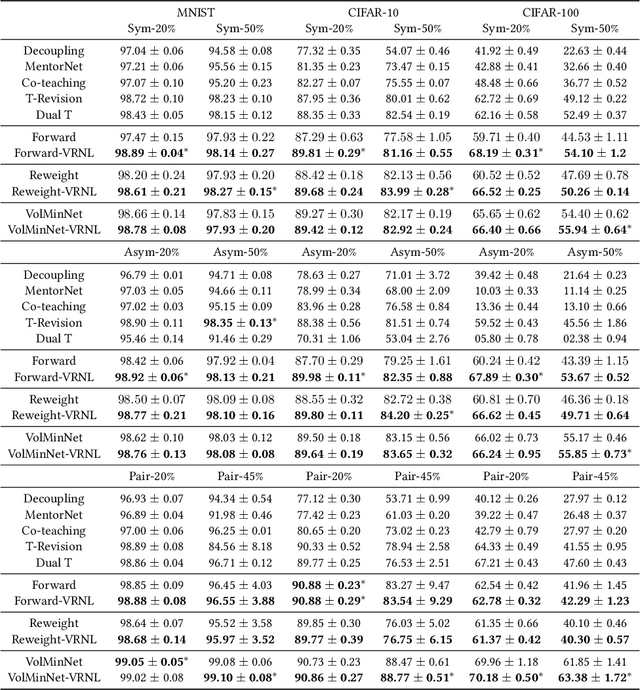
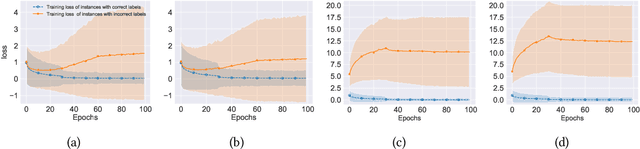

Algorithms which minimize the averaged loss have been widely designed for dealing with noisy labels. Intuitively, when there is a finite training sample, penalizing the variance of losses will improve the stability and generalization of the algorithms. Interestingly, we found that the variance should be increased for the problem of learning with noisy labels. Specifically, increasing the variance will boost the memorization effects and reduce the harmfulness of incorrect labels. By exploiting the label noise transition matrix, regularizers can be easily designed to reduce the variance of losses and be plugged in many existing algorithms. Empirically, the proposed method by increasing the variance of losses significantly improves the generalization ability of baselines on both synthetic and real-world datasets.