 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Distillation Mixup Training for Non-autoregressive Neural Machine Translation
Paper and Code
Dec 22, 2021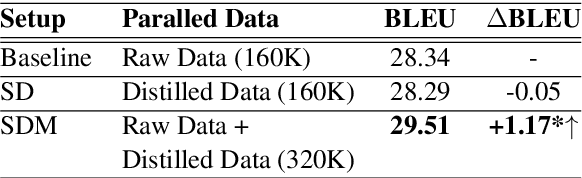
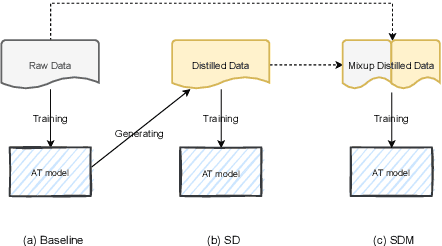
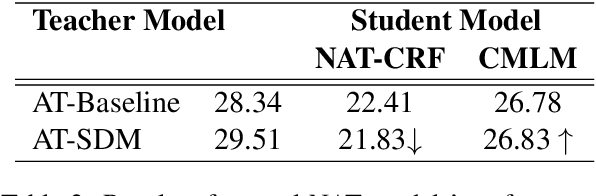
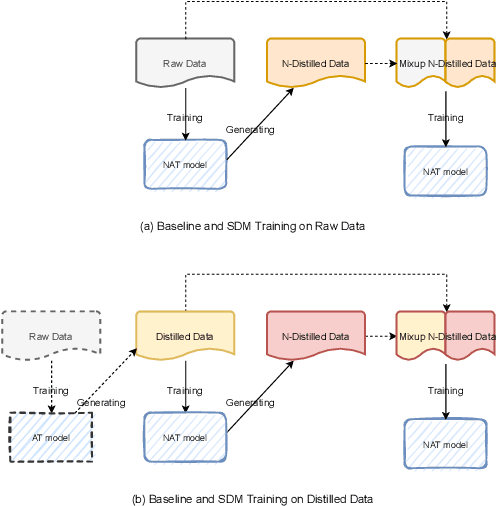
Recently, non-autoregressive (NAT) models predict outputs in parallel, achieving substantial improvements in generation speed compared to autoregressive (AT) models. While performing worse on raw data, most NAT models are trained as student models on distilled data generated by AT teacher models, which is known as sequence-level Knowledge Distillation. An effective training strategy to improve the performance of AT models is Self-Distillation Mixup (SDM) Training, which pre-trains a model on raw data, generates distilled data by the pre-trained model itself and finally re-trains a model on the combination of raw data and distilled data. In this work, we aim to view SDM for NAT models, but find directly adopting SDM to NAT models gains no improvements in terms of translation quality. Through careful analysis, we observe the invalidation is correlated to Modeling Diversity and Confirmation Bias between the AT teacher model and the NAT student models. Based on these findings, we propose an enhanced strategy named SDMRT by adding two stages to classic SDM: one is Pre-Rerank on self-distilled data, the other is Fine-Tune on Filtered teacher-distilled data. Our results outperform baselines by 0.6 to 1.2 BLEU on multiple NAT models. As another bonus, for Iterative Refinement NAT models, our methods can outperform baselines within half iteration number, which means 2X acceleration.