 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMTurk: Few-Shot Learners as Crowdsourcing Workers
Paper and Code
Dec 14, 2021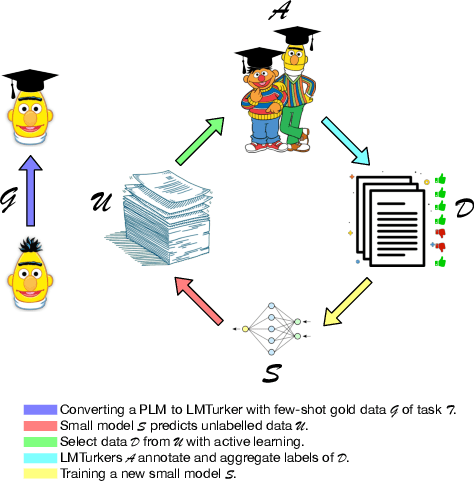
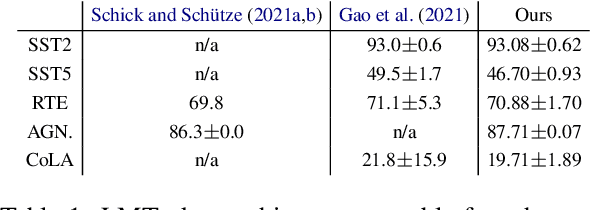
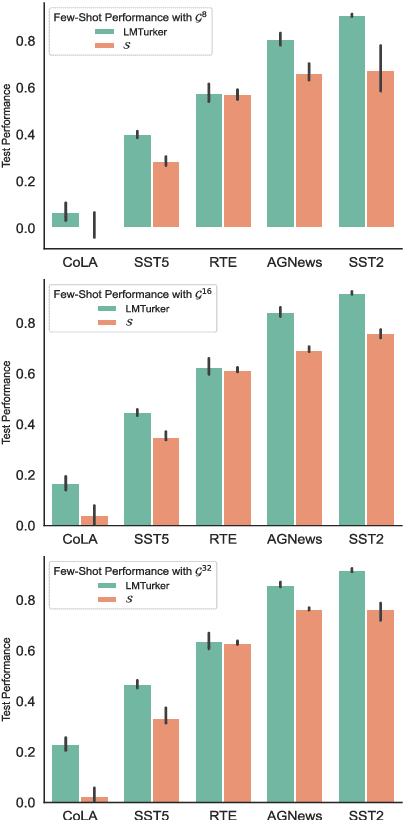
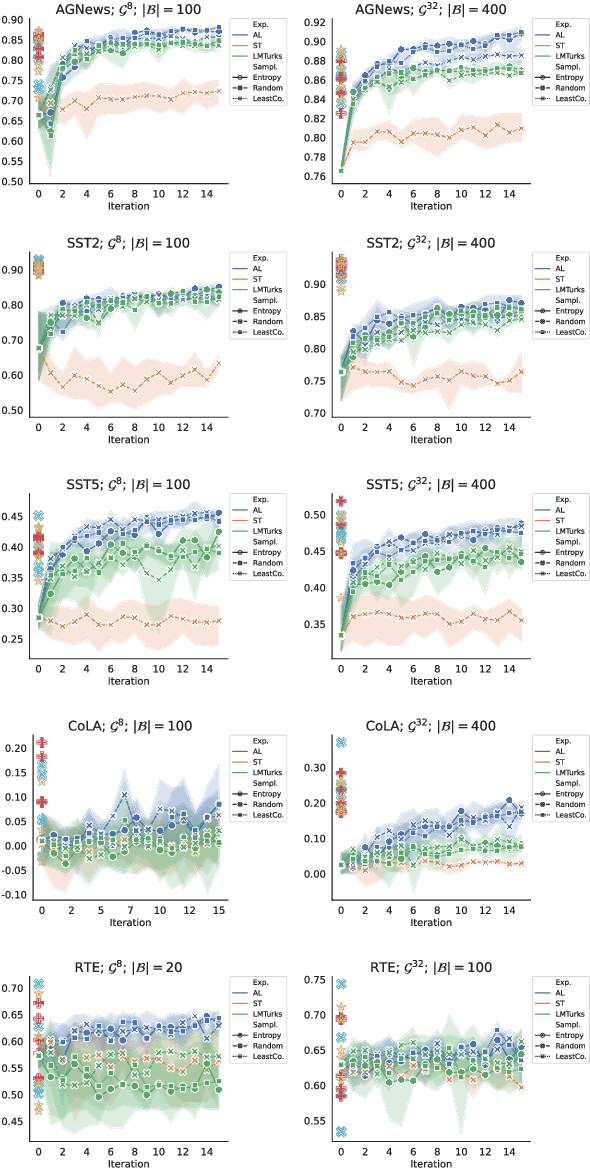
Vast efforts have been devoted to creating high-performance few-shot learners, i.e., models that perform well with little training data. Training large-scale pretrained language models (PLMs) has incurred significant cost, but utilizing PLM-based few-shot learners is still challenging due to their enormous size. This work focuses on a crucial question: How to make effective use of these few-shot learners? We propose LMTurk, a novel approach that treats few-shot learners as crowdsourcing workers. The rationale is that crowdsourcing workers are in fact few-shot learners: They are shown a few illustrative examples to learn about a task and then start annotating. LMTurk employs few-shot learners built upon PLMs as workers. We show that the resulting annotations can be utilized to train models that solve the task well and are small enough to be deployable in practical scenarios. Altogether, LMTurk is an important step towards making effective use of current PLM-based few-shot learners.