 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation for Object Detection via Rank Mimicking and Prediction-guided Feature Imitation
Paper and Code
Dec 09, 2021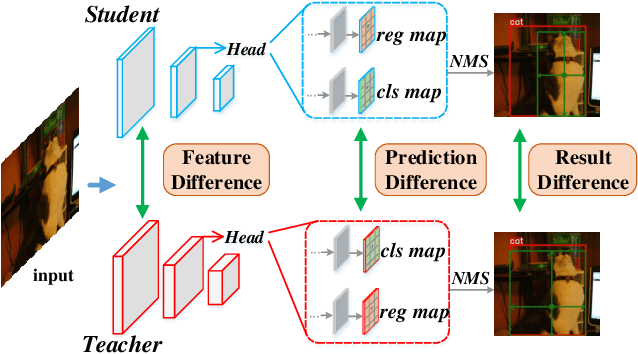
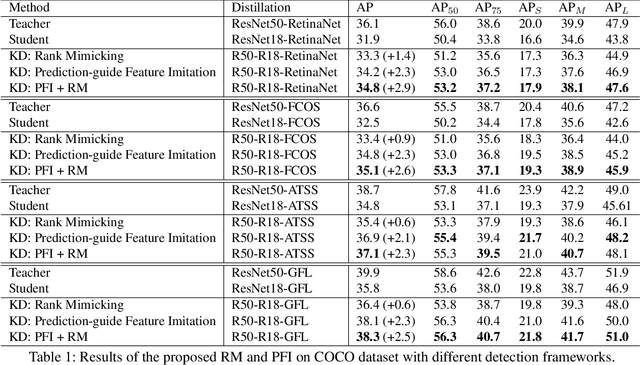
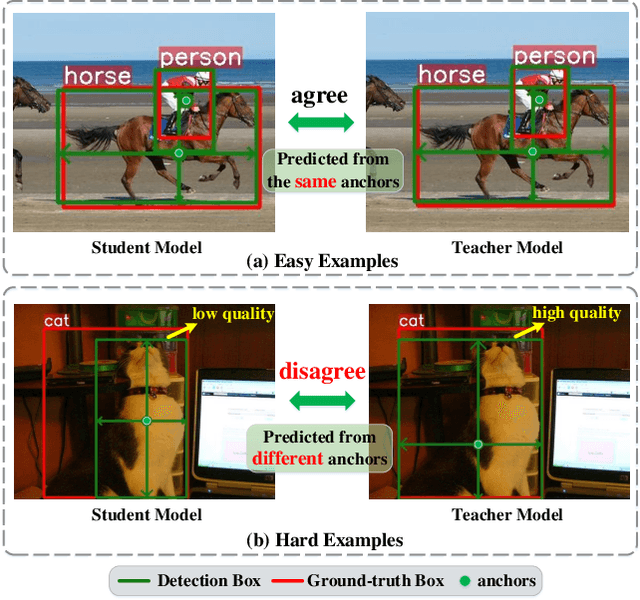
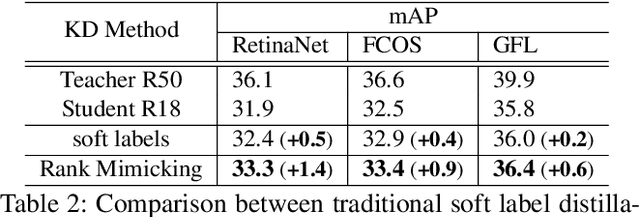
Knowledge Distillation (KD) is a widely-used technology to inherit information from cumbersome teacher models to compact student models, consequently realizing model compression and acceleration. Compared with image classification, object detection is a more complex task, and designing specific KD methods for object detection is non-trivial. In this work, we elaborately study the behaviour difference between the teacher and student detection models, and obtain two intriguing observations: First, the teacher and student rank their detected candidate boxes quite differently, which results in their precision discrepancy. Second, there is a considerable gap between the feature response differences and prediction differences between teacher and student, indicating that equally imitating all the feature maps of the teacher is the sub-optimal choice for improving the student's accuracy. Based on the two observations, we propose Rank Mimicking (RM) and Prediction-guided Feature Imitation (PFI) for distilling one-stage detectors, respectively. RM takes the rank of candidate boxes from teachers as a new form of knowledge to distill, which consistently outperforms the traditional soft label distillation. PFI attempts to correlate feature differences with prediction differences, making feature imitation directly help to improve the student's accuracy. On MS COCO and PASCAL VOC benchmarks, extensive experiments are conducted on various detectors with different backbones to validate the effectiveness of our method. Specifically, RetinaNet with ResNet50 achieves 40.4% mAP in MS COCO, which is 3.5% higher than its baseline, and also outperforms previous KD methods.