 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTip-Adapter: Training-free CLIP-Adapter for Better Vision-Language Modeling
Paper and Code
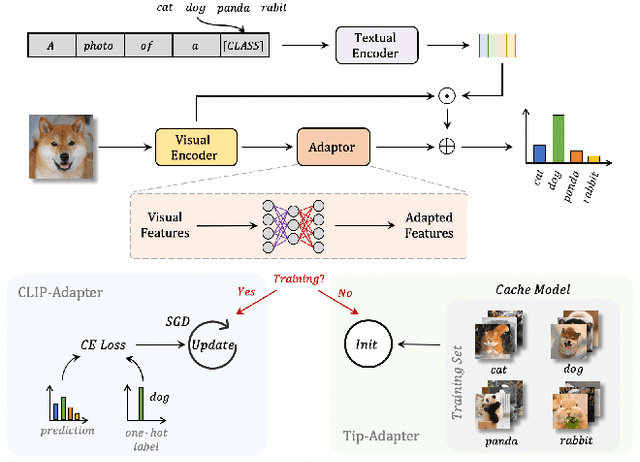

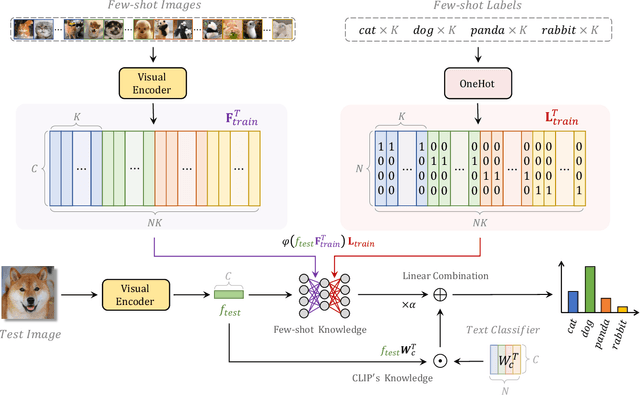

Contrastive Vision-Language Pre-training, known as CLIP, has provided a new paradigm for learning visual representations by using large-scale contrastive image-text pairs. It shows impressive performance on zero-shot knowledge transfer to downstream tasks. To further enhance CLIP's few-shot capability, CLIP-Adapter proposed to fine-tune a lightweight residual feature adapter and significantly improves the performance for few-shot classification. However, such a process still needs extra training and computational resources. In this paper, we propose \textbf{T}raining-Free CL\textbf{IP}-\textbf{Adapter} (\textbf{Tip-Adapter}), which not only inherits CLIP's training-free advantage but also performs comparably or even better than CLIP-Adapter. Tip-Adapter does not require any back propagation for training the adapter, but creates the weights by a key-value cache model constructed from the few-shot training set. In this non-parametric manner, Tip-Adapter acquires well-performed adapter weights without any training, which is both efficient and effective. Moreover, the performance of Tip-Adapter can be further boosted by fine-tuning such properly initialized adapter for only a few epochs with super-fast convergence speed. We conduct extensive experiments of few-shot classification on ImageNet and other 10 datasets to demonstrate the superiority of proposed Tip-Adapter. The code will be released at \url{https://github.com/gaopengcuhk/Tip-Adapter}.