Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Learning Inference Scheme Based on Pipelined Matrix Multiplication Acceleration Design and Non-uniform Quantization
Paper and Code
Oct 10, 2021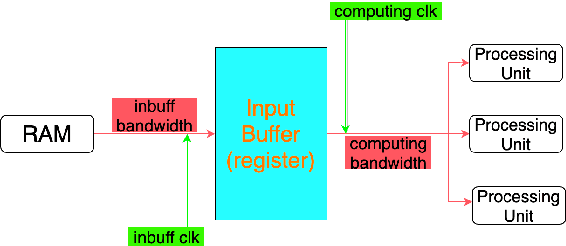
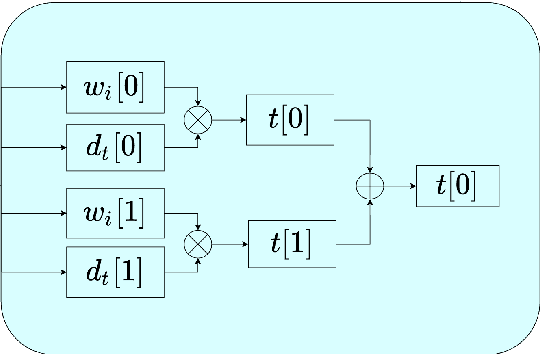
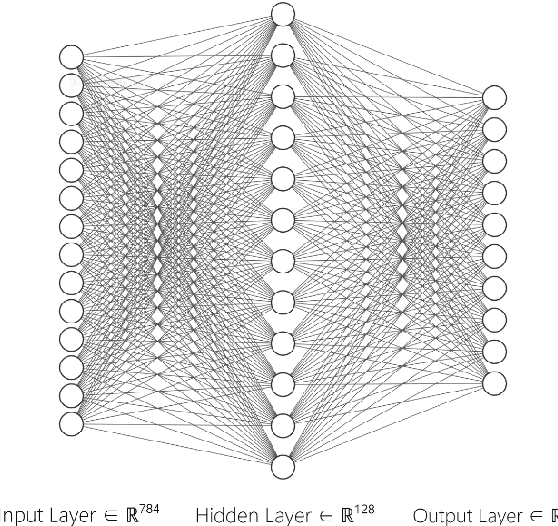
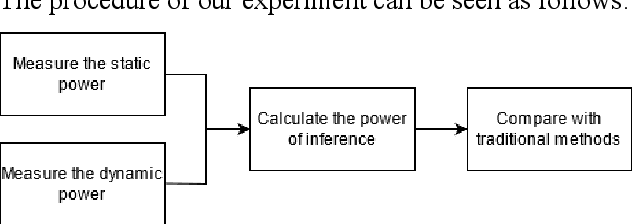
Matrix multiplication is the bedrock in Deep Learning inference application. When it comes to hardware acceleration on edge computing devices, matrix multiplication often takes up a great majority of the time. To achieve better performance in edge computing, we introduce a low-power Multi-layer Perceptron (MLP) accelerator based on a pipelined matrix multiplication scheme and a nonuniform quantization methodology. The implementation is running on Field-programmable Gate Array (FPGA) devices and tested its performance on handwritten digit classification and Q-learning tasks. Results show that our method can achieve better performance with fewer power consumption.
View paper on