 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCloning one's voice using very limited data in the wild
Paper and Code
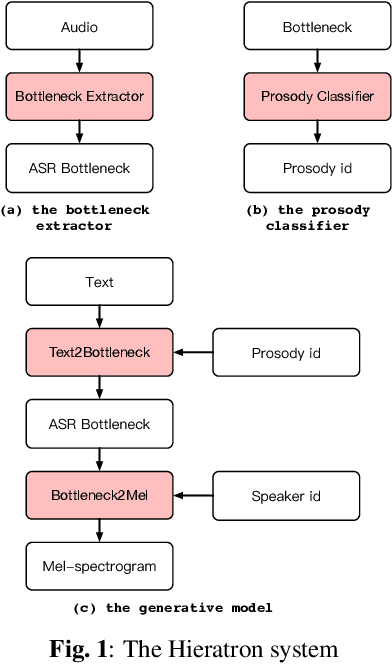
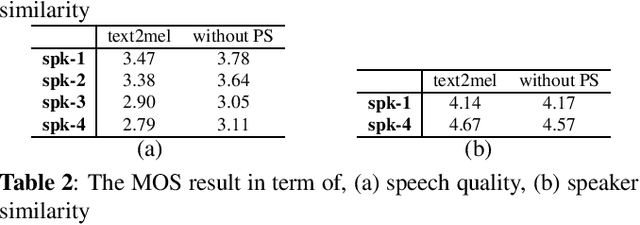
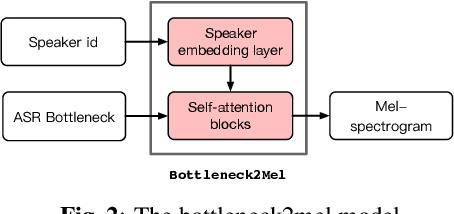
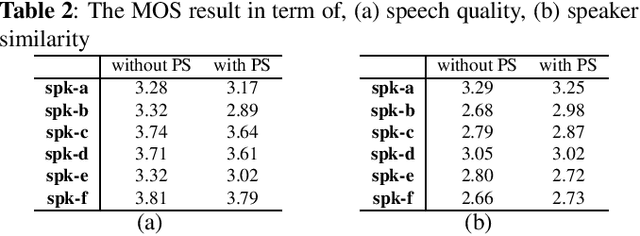
With the increasing popularity of speech synthesis products, the industry has put forward more requirements for personalized speech synthesis: (1) How to use low-resource, easily accessible data to clone a person's voice. (2) How to clone a person's voice while controlling the style and prosody. To solve the above two problems, we proposed the Hieratron model framework in which the prosody and timbre are modeled separately using two modules, therefore, the independent control of timbre and the other characteristics of audio can be achieved while generating speech. The practice shows that, for very limited target speaker data in the wild, Hieratron has obvious advantages over the traditional method, in addition to controlling the style and language of the generated speech, the mean opinion score on speech quality of the generated speech has also been improved by more than 0.2 points.