 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWinner Team Mia at TextVQA Challenge 2021: Vision-and-Language Representation Learning with Pre-trained Sequence-to-Sequence Model
Paper and Code
Jun 24, 2021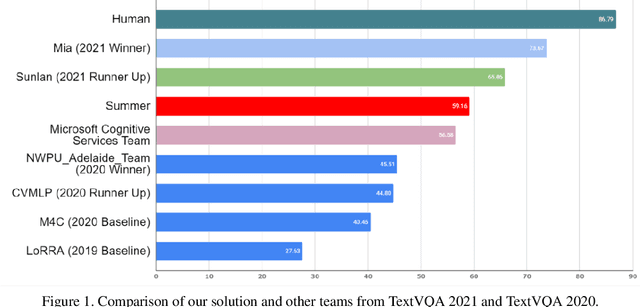
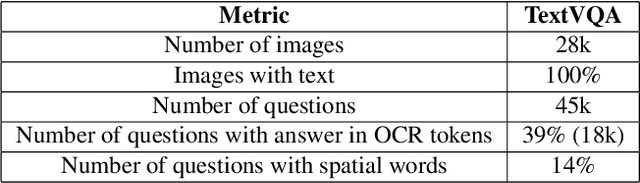
TextVQA requires models to read and reason about text in images to answer questions about them. Specifically, models need to incorporate a new modality of text present in the images and reason over it to answer TextVQA questions. In this challenge, we use generative model T5 for TextVQA task. Based on pre-trained checkpoint T5-3B from HuggingFace repository, two other pre-training tasks including masked language modeling(MLM) and relative position prediction(RPP) are designed to better align object feature and scene text. In the stage of pre-training, encoder is dedicate to handle the fusion among multiple modalities: question text, object text labels, scene text labels, object visual features, scene visual features. After that decoder generates the text sequence step-by-step, cross entropy loss is required by default. We use a large-scale scene text dataset in pre-training and then fine-tune the T5-3B with the TextVQA dataset only.